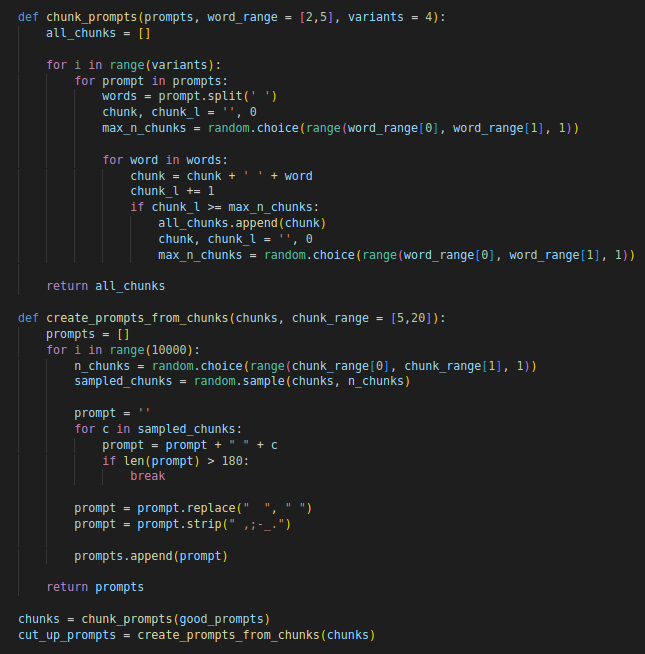
Inspired by the amazing work of @HvnsLstAngel I've been experimenting with a "color-quantized VQGAN"
Essentially, I introduced a codebook of possible colors and apply quantization in rgb space.
It's always fascinating how removing entropy can make samples more interesting...
Essentially, I introduced a codebook of possible colors and apply quantization in rgb space.
It's always fascinating how removing entropy can make samples more interesting...

"Inception"


"The ancient temple of time"


"Daydreaming"

I'm using some of the default colormaps from Matplotlib here, any pointers to more esthetically pleasing colormaps would def be appreciated 😋🙏
"Garden of Eden, the new fragrance"
"Garden of Eden, the new fragrance"


• • •
Missing some Tweet in this thread? You can try to
force a refresh