My favorite Python 3.5 feature: the matrix multiplication operator @
👇Python features thread👇
👇Python features thread👇

Other Python 3.5 features I often use:
- subprocess.run()
- math.isclose()
Big 3.5 features I don't really use much:
- Coroutines with async and await
- Type hints
👇
- subprocess.run()
- math.isclose()
Big 3.5 features I don't really use much:
- Coroutines with async and await
- Type hints
👇
My favorite 3.6 feature: formatted string literals
👇
👇

Other 3.6 features I often use:
- Underscores in numeric literals like 1_000_000
- random.choices()
- math.tau to replace 2 * math.pi (obviously)
👇
- Underscores in numeric literals like 1_000_000
- random.choices()
- math.tau to replace 2 * math.pi (obviously)
👇
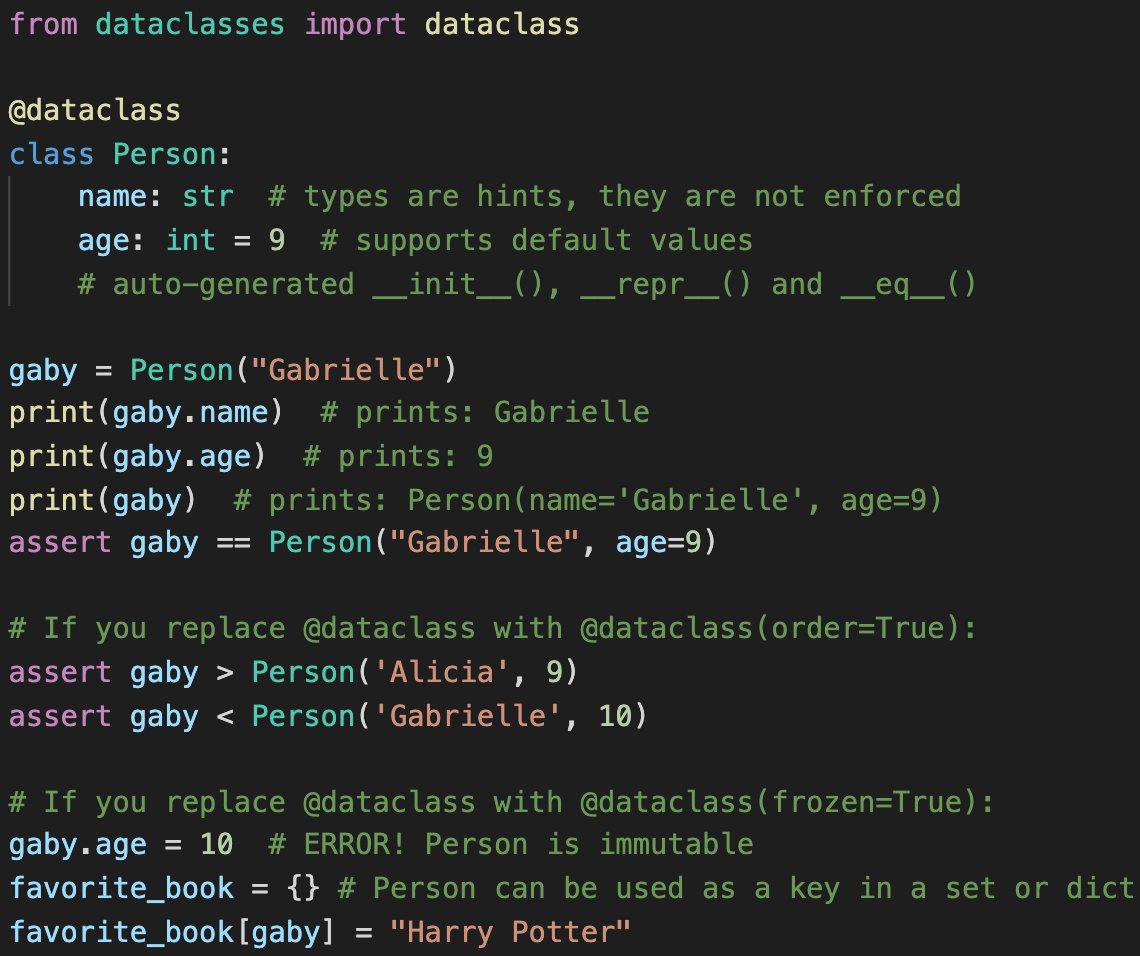
My favorite 3.7 feature: dataclasses
👇
👇
Other 3.7 feature I really like:
Legacy C locale coercion (PEP 538): locale-aware C extensions and child processes now use UTF-8 by default, rather than ASCII.
👇
Legacy C locale coercion (PEP 538): locale-aware C extensions and child processes now use UTF-8 by default, rather than ASCII.
👇
My favorite 3.8 feature: self-doc strings

Other 3.8 features I really like:
- from math import prod, dist, comb, perm
- functools.cached_property
I might start using the walrus operator as well:
👇
- from math import prod, dist, comb, perm
- functools.cached_property
I might start using the walrus operator as well:
👇

Not sure I'll often use positional-only arguments, but okay, why not:
👇
👇

My favorite 3.9 feature: removing prefixes and suffixes. I know it sounds silly, but this is needed so often!
And the new syntax to merge dicts is nice too.
👇
And the new syntax to merge dicts is nice too.
👇

My favorite 3.10 feature: better error messages, including more precise error line numbers.
👇
👇

I'm not sure I'll use the new match/case feature from 3.10, though:
👇
👇

Pros:
- it's elegant in some cases
Cons:
- more to learn, harder for beginners
- unusual semantics: case args act a bit like function args, but they outlive the match/case
- goes against the "one-way to do things" principle
👇
- it's elegant in some cases
Cons:
- more to learn, harder for beginners
- unusual semantics: case args act a bit like function args, but they outlive the match/case
- goes against the "one-way to do things" principle
👇
"If you don't like it, just don't use it" is not a valid argument unless you always work alone, and you never read anyone else's code.
👇
👇
So many great improvements, it's nice to see Python continue to improve! 🐍💕
<The End>
<The End>
• • •
Missing some Tweet in this thread? You can try to
force a refresh