StyleGAN3 is out and results are 🤯!
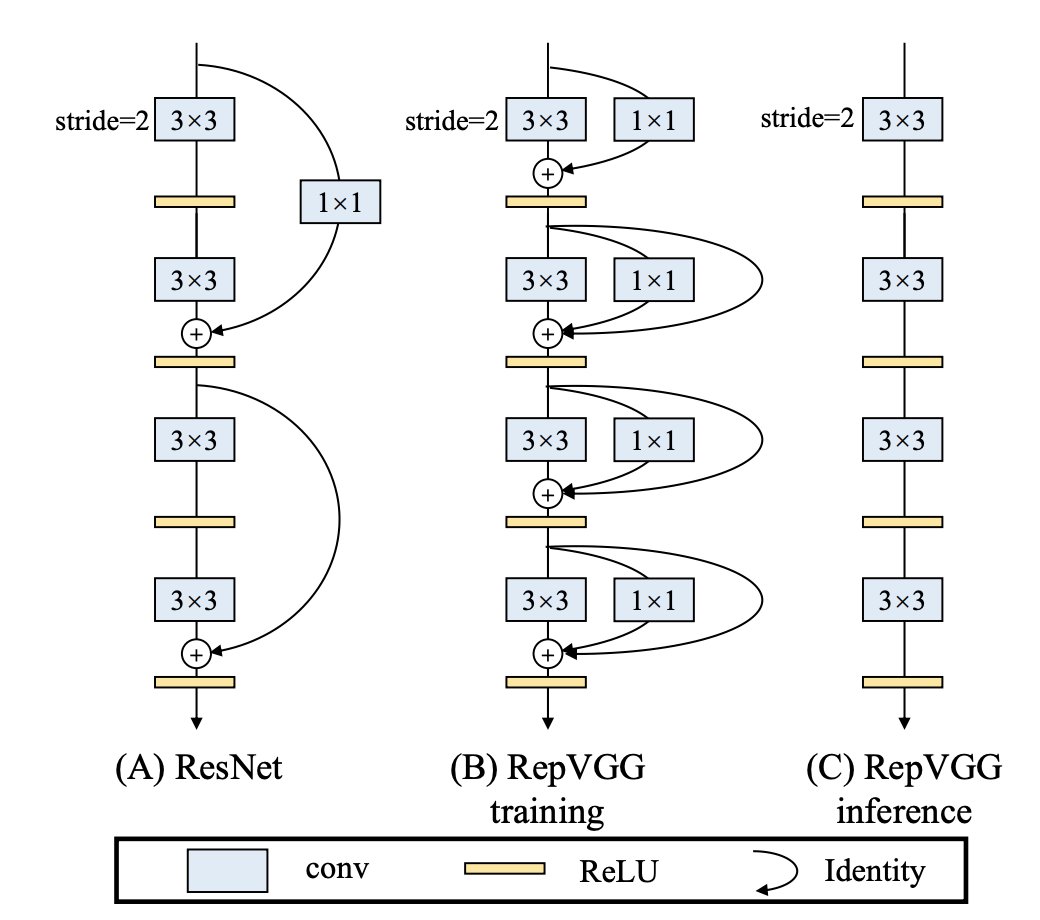
It proposes architectural changes that suppress aliasing and forces the model to implement more natural hierarchical refinement which improves its ability to generate video and animation.
paperswithcode.com/paper/alias-fr…
1/8
It proposes architectural changes that suppress aliasing and forces the model to implement more natural hierarchical refinement which improves its ability to generate video and animation.
paperswithcode.com/paper/alias-fr…
1/8
In the cinemagraph below, we can see that in StyleGAN2 the texture (e.g., wrinkles and hairs) appears to stick to the screen coordinates. In comparison, StyleGAN3 (right) transforms details coherently:
2/8
2/8
The following example shows the same issue with StyleGAN2: textural details appear fixed. As for alias-free StyleGAN3, smooth transformations with the rest of the screen can be seen.
3/8
3/8
In the interpolation example below, it appears that StyleGAN3 even learns to mimic camera motion:
4/8
4/8
Results show improvements on FFHQ-U when applying the proposed ideas by converting the StyleGAN2 generator to be fully equivariant to translation and rotation. Configs T and R correspond to the alias-free generator. Discriminator remains unchanged.
paperswithcode.com/sota/image-gen…
5/8
paperswithcode.com/sota/image-gen…
5/8

The following are results for six datasets using StyleGAN2 and the proposed alias-free generators (configs T and R).
6/8
6/8

The animation below demonstrates the internal representations of both StyleGAN2 and StyleGAN3. It appears that StyleGAN2 builds the image in a different manner: "multi-scale phase signals that follow the features seen in the final image":
7/8
7/8
Useful links:
Paper & Result: paperswithcode.com/paper/alias-fr…
Code: github.com/NVlabs/stylega…
Project website: nvlabs.github.io/stylegan3/
8/8
Paper & Result: paperswithcode.com/paper/alias-fr…
Code: github.com/NVlabs/stylega…
Project website: nvlabs.github.io/stylegan3/
8/8
• • •
Missing some Tweet in this thread? You can try to
force a refresh