
So #HFXBurgerWeek is starting tomorrow, and I haven't gotten around to making my unofficial fast-find burger listing web page yet. Well, I've got some time now and I should be able to punk rock this thing together in about an hour. Follow along in this thread! (Or mute me)
Here's the burger lineup in the official site:
burgerweek.co/burger-lineup/
Big delicious pictures, some search tools - but if you just want to find a burger quickly on your phone, it's a bit clunky. You have to tap to see details. Devtools says it's 176 files and nearly 8 megabytes
burgerweek.co/burger-lineup/
Big delicious pictures, some search tools - but if you just want to find a burger quickly on your phone, it's a bit clunky. You have to tap to see details. Devtools says it's 176 files and nearly 8 megabytes

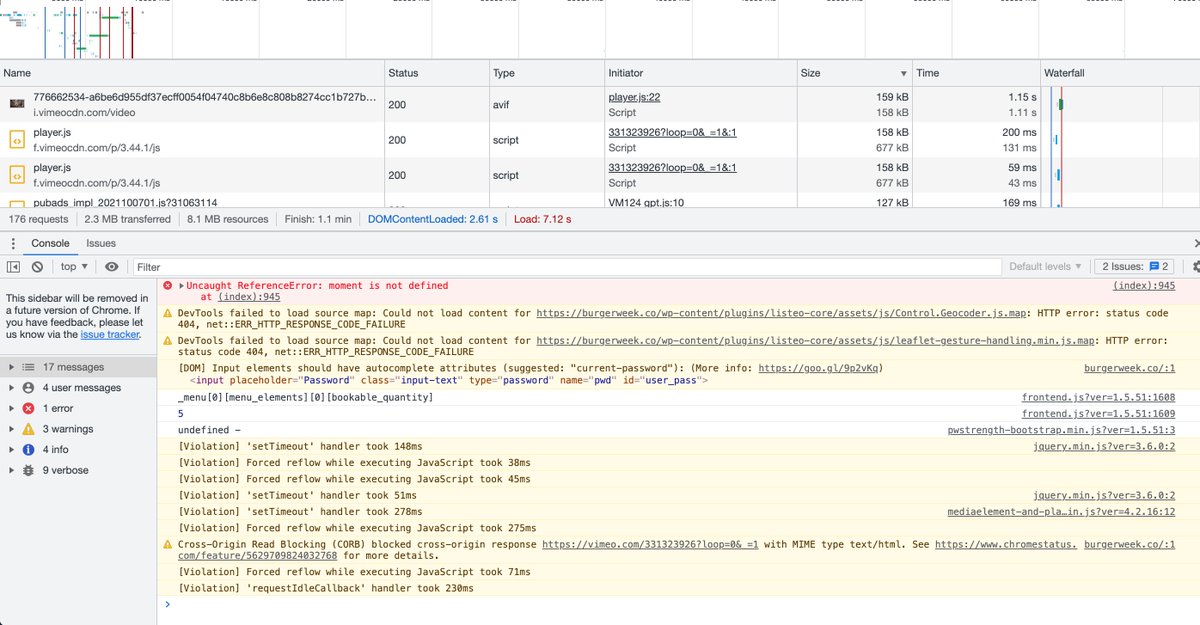
I'm not blaming The Coast for their website - it has many jobs to do for many different stakeholders - but I like fast simple lookup tools over big splashy sites. In fact this year's version seems a bit more svelte than before. Still, I'm going to make my own much lighter version
I'm going to reuse a lot of the things I've already set up from previous years, so the main challenge is: how do I get the current burger data in a useful format? Two years ago they actually sent me a spreadsheet, but it's too late now for that. So I'm going to SCRAPE the SITE.
I have no guarantees that this will work this year, but it's been good in previous years and it doesn't look like it's changed that much.
To do this, I'm going to write a script in Ruby using the Nokogiri parsing library - in terminal EMACS, because I'm an Old.
To do this, I'm going to write a script in Ruby using the Nokogiri parsing library - in terminal EMACS, because I'm an Old.

The first thing to do is read in the main listing page. To do this I set up Nokogiri and tell it to load up the page.
There was some weird SSL issue, but it turns out I can access the site just fine from regular http:// as well as https://
Just outputting what it loaded for now
There was some weird SSL issue, but it turns out I can access the site just fine from regular http:// as well as https://
Just outputting what it loaded for now

Just like your browser reads a page and then displays it in a window, Nokogiri reads a page and then stores it as a data structure in memory so you can do stuff to it with your code, like find and extract data.
The site has a separate page for each burger, with all the details we need on it. What I want to do is get the address for each page from this main listing page.
My browser's inspector shows that each entry has a link of class "listing-item-container" - let's see if that works
My browser's inspector shows that each entry has a link of class "listing-item-container" - let's see if that works

Pretty good!
One nice thing about Nokogiri is you can find stuff on a page using more or less the same syntax as CSS or JQuery selectors. So to find everything with class "listing-item-container" I just ask it for .css('.listing-item-container') - and it give me 142 matches.
One nice thing about Nokogiri is you can find stuff on a page using more or less the same syntax as CSS or JQuery selectors. So to find everything with class "listing-item-container" I just ask it for .css('.listing-item-container') - and it give me 142 matches.

Then I can just loop through those matches and ask it for the 'href' attribute.
Now I have a list of all of the separate burger page addresses!
Now I have a list of all of the separate burger page addresses!

Now some Ruby people will say I'm being too verbose here breaking things out into all those lines. After all these years though I've learned that a bit of extra explicitness can really help clarity. But yes I could golf all of this down to one line if I wanted to:

Just because you CAN doesn't mean you SHOULD though. So back to the clunkier but more readable code.
[Jurassic Park gif]
[Jurassic Park gif]
This time instead of just outputting the entries, I'm mapping them into an array.
That .map{|x| ... } thing is one of the reasons I still love working with Ruby so much and also kind of resent all the extra brackets and arrows etc that JavaScript requires for the same thing.
That .map{|x| ... } thing is one of the reasons I still love working with Ruby so much and also kind of resent all the extra brackets and arrows etc that JavaScript requires for the same thing.

Now I have a list of all the burger pages, I can loop through it, load each up with Nokogiri, and extract the necessary information.
Easy as ... oh drat. If you look back at the previous screenshot you'll see all the links are https:// and for some reason that's breaking here.
Easy as ... oh drat. If you look back at the previous screenshot you'll see all the links are https:// and for some reason that's breaking here.

So I just do a quick substitution and boom now I'm going through every page!
However, this takes a while to run, like over a minute to hit all 143 or so pages. I also find it impolite to hit a site over and over again with a scraper like that, even if it's just getting the HTML.
However, this takes a while to run, like over a minute to hit all 143 or so pages. I also find it impolite to hit a site over and over again with a scraper like that, even if it's just getting the HTML.

So I'm temporarily adding [0..2] to the end of the fetch, which just uses the first three elements of the array. This loads much more quickly - and I should be able to figure out most of the rest just from here.

Here's one of the pages - as you can see most of the information we'll need is up at the top. There is also conveniently a map. Let's poke around the HTML to see if we can find useful selectors to point Nokogiri to.


Here's the HTML for the top part of the page. Annoyingly both the name of the burger and the name of the restaurant are H2s at the same level - but at least one has a different class. And they should both be in the same order. Price and FeedNS donation have their own classes.

Description looks like it's inside a "#listing-overview"
And - hooray! - the GPS coordinates are attributes in the map container tag - and also parameters in the Google Maps Directions link below, if necessary.
Last year everything was in a GIS component and un-extractable.
And - hooray! - the GPS coordinates are attributes in the map container tag - and also parameters in the Google Maps Directions link below, if necessary.
Last year everything was in a GIS component and un-extractable.


Okay - so I'm going to try getting the restaurant name and the burger.
Hmmm. They're both H2s, and the burger is mixed in with the price and other details. Kind of messy. This happens with stuff coming from CMSes. You can see on the right how it's coming out of Nokogiri.
Hmmm. They're both H2s, and the burger is mixed in with the price and other details. Kind of messy. This happens with stuff coming from CMSes. You can see on the right how it's coming out of Nokogiri.

Okay I've hacked together a janky solution - but at least it works!
This gets all the H2s in the titlebar section. The content of the 1st is the restaurant. The content of the 2nd is the burger and some pricing. "split('$').first" is a quick way of getting everything up to the $
This gets all the H2s in the titlebar section. The content of the 1st is the restaurant. The content of the 2nd is the burger and some pricing. "split('$').first" is a quick way of getting everything up to the $

If the tags-free second h2 text is:
"YOLO$18 $1 to Feed NS"
Then split('$') turns it into an array broken on $:
["YOLO", "18 ", "1 to Feed NS"]
And the burger name will always be the 1st element
So:
h2s.last.text.split('$').first
Sometimes Ruby feels like poetry.
"YOLO$18 $1 to Feed NS"
Then split('$') turns it into an array broken on $:
["YOLO", "18 ", "1 to Feed NS"]
And the burger name will always be the 1st element
So:
h2s.last.text.split('$').first
Sometimes Ruby feels like poetry.

The next ones are easier: price and FeedNS amount each have their own <span>s with dedicated classes and we can just do selectors for them
To keep track of things I'm outputting all the results to the console. The "#{...}" lets me stick variables in strings. Results on the right
To keep track of things I'm outputting all the results to the console. The "#{...}" lets me stick variables in strings. Results on the right

The rest of the details on this page are coming in pretty easily.
"Tags" end up with lots of extra space around them, so I call ".strip" to remove all that.
The "Description" is in an area with an ID ('#listing-overview') but I needed to pull out just the stuff in <p> tags.
"Tags" end up with lots of extra space around them, so I call ".strip" to remove all that.
The "Description" is in an area with an ID ('#listing-overview') but I needed to pull out just the stuff in <p> tags.

We got latitude and longitude from the map container tag - and now we have everything we need!
Now to try it on all the pages. Ideally the content will be formatted consistently.
Ideally.
Now to try it on all the pages. Ideally the content will be formatted consistently.
Ideally.

Hey it went through all of them without crashing on missing data, or even any mis-formatting!
I've been doing this for decades and I'm still suspicious when this kind of thing works the first time. But I'll take it.
Hungry yet?
I've been doing this for decades and I'm still suspicious when this kind of thing works the first time. But I'll take it.
Hungry yet?

But what do we DO with this data now that we know we can get it?
We're going to turn it into JavaScript.
Then we're going to write that JS to a file.
Then we're going to load that file on a page where more JavaScript can write out the data in useful ways.
Anyone still here?
We're going to turn it into JavaScript.
Then we're going to write that JS to a file.
Then we're going to load that file on a page where more JavaScript can write out the data in useful ways.
Anyone still here?
Instead of outputting the results, we're going to put them into a data structure - Ruby calls these Hashes, but they're sometimes called Dictionaries or Objects. They're just collections of keys and values, wrapped in { ... }.
I'm using an older style because I'm an Old.
I'm using an older style because I'm an Old.

Our final result is going to be an array - an ordered list - of these burger hashes.
I set up an array before the main loop with:
burgers = []
And after we make each new burger entry we add it to the array:
burgers << next_entry
At the end we have a nice collection of data.
I set up an array before the main loop with:
burgers = []
And after we make each new burger entry we add it to the array:
burgers << next_entry
At the end we have a nice collection of data.
Now we have this data we want to turn it into JavaScript, because that's the only language web browsers understand.
Thankfully this is pretty easy by simply calling ".to_json" on our array.
Here we're sorting them by restaurant first, and then adding a name before the json.
Thankfully this is pretty easy by simply calling ".to_json" on our array.
Here we're sorting them by restaurant first, and then adding a name before the json.

"JSON" stands for "JavaScript Object Notation". It's basically data formatted as JavaScript. Having spent much of my early career wrestling with XML, this is much nicer to work with.
You can see it on the right. It looks quite a bit like the raw Ruby output from earlier.
You can see it on the right. It looks quite a bit like the raw Ruby output from earlier.

One last test: I set it to fetch all the burgers from all the pages and then write everything out as JSON. It churns for a while - but everything is looking good!

Next we do a bit of UNIX command-line magic: instead of having our script write out to the screen, we can tell it instead to write out to a file! We just use ">" and give it a name to use.
ruby scraper_2021.rb > burgers_2021.js
And now we have a 60kb file of burger data!
ruby scraper_2021.rb > burgers_2021.js
And now we have a 60kb file of burger data!
Oops - I realized that I forgot to get the restaurant address! It's just an extra data element that we can pull from ''.listing-address' on the page and put into our array of hashes.
BRB
BRB
Okay now we have our burger data, we can start figuring out how to show it on our page.
I'm mostly using the same HTML page as last year. Here it is:
That's it.
That's the site.
I'm mostly using the same HTML page as last year. Here it is:
That's it.
That's the site.

It's mostly framing stuff, linking in some CSS and JS (including the burgers_2021.js file we just made) and Google Analytics so I can see stuff about my visits.
All the real action happens near the middle, right here:
<div id="burgerlist"></div>
All the real action happens near the middle, right here:
<div id="burgerlist"></div>

The main part is this JavaScript function. The JS file we created earlier gives us all the burger info in a "burgerData" variable, which we loop through to build a bunch of HTML - which is then put in the "burgerlist" element on the page.
It's a vintage approach - but it works!
It's a vintage approach - but it works!

I don't know if anyone has been following along through all this - or if you all just muted me hours ago - but I've got to step away for a while. I'll probably be back at this later on. I'll probably turn it all into a blog post eventually too.
... and I'm back.
The original versions of this project used JQuery to the JavaScript easier to work with. Then I realized I was bringing in a lot of library code just to do a handful of relatively simple things. So I did some research on how to do JQuery stuff in plain old JS.
The original versions of this project used JQuery to the JavaScript easier to work with. Then I realized I was bringing in a lot of library code just to do a handful of relatively simple things. So I did some research on how to do JQuery stuff in plain old JS.
The first big advantage of JQuery is a streamlined way to not run anything until after the page is fully loaded. Turns out this code does the same thing.
To be honest I just copy-pasted it from StackOverflow. It does the trick though.
To be honest I just copy-pasted it from StackOverflow. It does the trick though.

Anyhow, when the page finishes loading, it runs the loadBurgers() function I showed earlier. It goes through the whole data set, builds a pile of HTML with it, and then dumps it all into that burgerlist div - using the non-JQuery plain JS method.

Yeah during my regular work I'm transpiling ECMAScript and have to reconfigure my file system to support the sheer scale of my node_modules folders - but part of this "punk rock" project is to do as much as possible with as little as possible.
It's. Just. Plain. JavaScript.
It's. Just. Plain. JavaScript.
The fanciest part is sortByDistance(), which gets the current GPS position and when it's done that it calls updateListing(). This does some ugly juggling but eventually assigns a "distance" value to each burger, and then re-sorts the list by distance and then redraws it.

The distance algorithm does some spherical trigonometry stuff I don't really understand. I copied it from StackOverflow as well - but it works!
The last bit is a quick and dirty "search" function that simply hides all the burger entries and only shows ones that have text that matches what was typed into the field. I'm not going to apologize for using a regular expression. It's a simple one at least!

The CSS is pretty straightforward. I used to have all of Bootstrap set up for this, along with custom fonts. Now it's just a page or so of straightforward stuff and nice fonts if you have them but sanserif if you don't NBD

Okay let's fire this up! Looking pretty good! Except for all those "Undefined" burgers. Must be the new trend this year, like kimchi was in 2018. No probably just used the wrong name somewhere. It's my most common mistake.

Ah - the code was looking for "name" but the data file had "burgername".
Naming is one of the trickiest things in software, believe it or not. This is one of the ways my English degree has actually helped my software career a lot.
Anyhow, it looks better now!
Naming is one of the trickiest things in software, believe it or not. This is one of the ways my English degree has actually helped my software career a lot.
Anyhow, it looks better now!

Tried the filter - it seems to work! However, it revealed a problem I should have caught earlier: special characters in the content. "mac ‘n’ cheeze" ugh. Need to do some search/replace. This is actually where I fire up VSCode since it's better at that than terminal emacs

It's mostly smart quotes and em-dashes and things like that. Perennial headaches for this kind of parsing stuff. I just swap them with dumb quotes and regular dashes etc. Close enough for rock.

I'm in California right now so the "show me the closest burger" function is going to be a bit weird - though for security reasons it doesn't work when just looking at the file on my computer. I need to get it published!
When I first set this up several years ago, I had actually planned a full database-backed Ruby on Rails app - then I realized I could do the whole thing with a few flat files with absolutely nothing underneath.
The cool kids call this JAMStack. I call it keeping things ~1997.
The cool kids call this JAMStack. I call it keeping things ~1997.
Since it's just flat files, I could put this on nearly any host anywhere. I like @websavers for plesk/php hosting here in Nova Scotia. I could probably use Netlify for this since it's "serverless". Or Github, or Amazon. But it's already on @heroku so I'll stay there for now.
So first I commit all my changes into Git version control. Since I've been in EMACS I'm using "magit" which is really nice, even for the limited stuff I use it for.
(I rename the files every year so browsers don't use the old cached ones. Once-a-year-timestamping)
(I rename the files every year so browsers don't use the old cached ones. Once-a-year-timestamping)

It's overkill to use Heroku to host simple flat files, but I picked it because I already used it for lots of stuff and the base level is free.
However, to be able to use SSL I have to move to a paid level, and without SSL the GPS won't work.
So I might move things.
Tomorrow.
However, to be able to use SSL I have to move to a paid level, and without SSL the GPS won't work.
So I might move things.
Tomorrow.
Anyhow, for the time being you can check out the updated "punk rock" Burger Week burgers listing at burgerweek.shindigital.com and feel free to "View Source" and see how it all fits together.
GPS won't work though.
Soon!
GPS won't work though.
Soon!
So as I mentioned way upstream, the official site listing is 176 files and nearly 8 megabytes.
My version (which is arguably more useful in certain ways) is 7 files and 124kb.
My version (which is arguably more useful in certain ways) is 7 files and 124kb.

The sum total of JavaScript functionality, which includes dynamically updated page contents, search/filter logic, and GPS distance sorting, fits into one 3.34KB file. No extra libraries. No transpiling. No monstrous node_modules folder. 100 lines of code.
I enjoy doing this every year, even if I only have the stomach for maybe one or two of these burgers - or even if I'm out of town for all of it like now.
It's like the Ramones doing 90 second songs in an era of double-length prog rock albums.
It's like the Ramones doing 90 second songs in an era of double-length prog rock albums.
The first recorded use of "punk" to refer to music was in a review of the Stooges' first album: "it's the music of punks, it's about cruising for burgers in your car"
So burgers and punk go way back.
(Gratuitous Iggy Pop pic because speaking of free range organic beef)
So burgers and punk go way back.
(Gratuitous Iggy Pop pic because speaking of free range organic beef)

Oh Iggy Pop, putting the "performance" into the "this is what peak performance looks like" meme.

As a reward to all of those who made it this far with me on this punk burger odyssey, here's Henry Rollins sharing his failed attempts to out-rock Iggy Pop (audio only alas as the video has been taken down)
Morning update! I realized that since Burger Week is only, um, a week, it wouldn't break the bank to upgrade to a paid plan at Heroku so I can get SSL working. It's $7 / month which is $1.75 for the week.
Hosting is cheap. Especially if it's just flat files for a limited time!
Hosting is cheap. Especially if it's just flat files for a limited time!
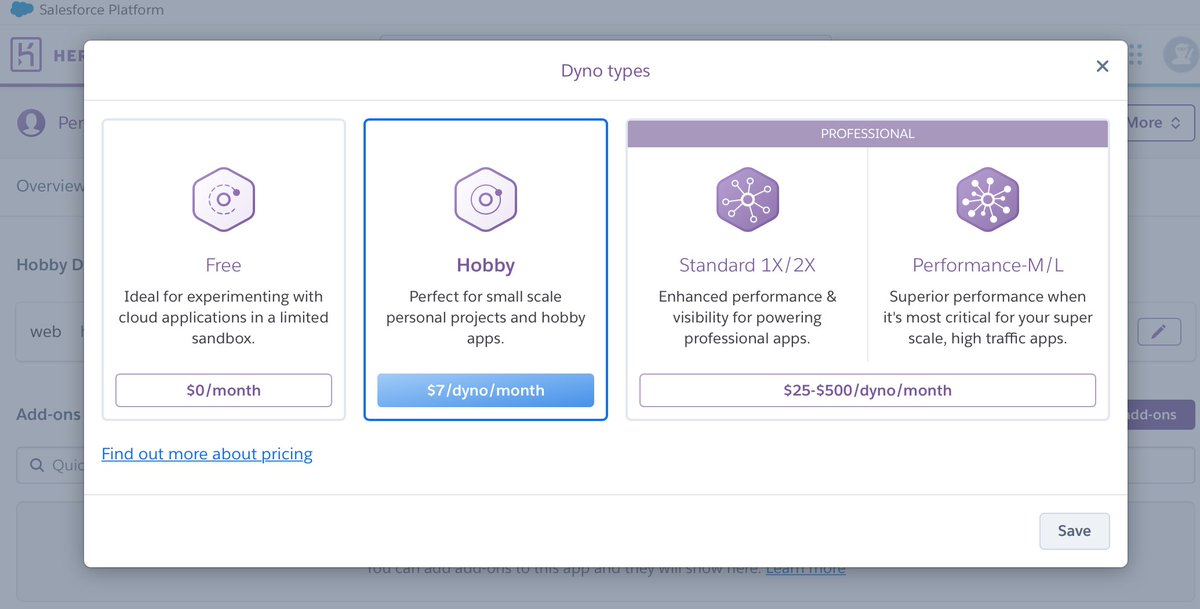
Upgrading a server used to take months and cost thousands of $. Now it's a click of a button and you only pay for time used.
Setting up SSL/https used to take all day. Now it's one command-line call. Thank you letsencrypt!
Setting up SSL/https used to take all day. Now it's one command-line call. Thank you letsencrypt!

So now we can hit burgerweek.shindigital.com and it's secure! There's no forms to fill out or anything so it doesn't really NEED to be secure, but in 2021 many browsers won't let you get GPS coordinates without SSL, and search engines will rank you lower if you don't have it.

... but there's now 2 problems: 1) you can still get to the old unsecured address and 2) the location sorting still doesn't seem to be working.
I think I know what to do about both of these. Light debugging goes well with morning coffee!
I think I know what to do about both of these. Light debugging goes well with morning coffee!
So @halifaxbeard suggested I submit a petition to Google to get the site added to an exclusive list of sites built into Chrome that will always be redirected to https.
Maybe not this early in the day!
Instead I just slapped some JS in at the top of the page that redirects.
Maybe not this early in the day!
Instead I just slapped some JS in at the top of the page that redirects.


Next up is the distance calculations not working. As I guessed, it was once again about Naming Things.
For 2020 I used much shorter lookup keys in the burgers list - e.g. 'lt' instead of 'latitude' - to make the file as small as possible.
I just forgot to update the function!
For 2020 I used much shorter lookup keys in the burgers list - e.g. 'lt' instead of 'latitude' - to make the file as small as possible.
I just forgot to update the function!
Labels are now updated, but I wanted to just make sure things are working properly, so I added every web programmer's oldest and best friend: console.log. This writes out to a behind-the-scenes browser panel, so you can see what's going on. I'm just showing the calculated results

Quick git commit and deployment and - boom! - we're in business!
(I'm in California right now so the distances are extra large - but it's working)
Closest burger week burger to me is at Peggys Cove, a mere 4832km away.
(I'm in California right now so the distances are extra large - but it's working)
Closest burger week burger to me is at Peggys Cove, a mere 4832km away.
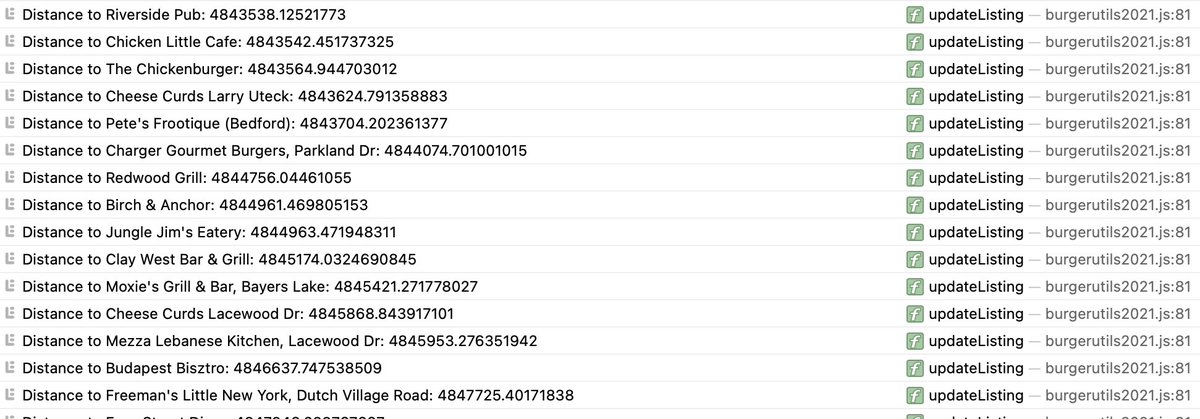

That last final step is of course to REMOVE the console.log call from the code and redeploy.
I, um, may sometimes forget to do this step.
I know I'm not alone though!
Enable "Developer Tools" and check your favourite sites to see what gets left in there.
I, um, may sometimes forget to do this step.
I know I'm not alone though!
Enable "Developer Tools" and check your favourite sites to see what gets left in there.
Okay - someone pointed out that my site isn't picking up the search terms. Looks like they added extra tag criteria this year, in addition to the regular tags they've had before. This shouldn't be too difficult to extract though.

So let's look at the HTML and figure out the best way to get the tags. They're 'li' elements inside a 'listing-features' div.
So I add another Nokogiri selector, which returns an array of matches. I extract the text and merge it into a comma-separated string. Looking good!
So I add another Nokogiri selector, which returns an array of matches. I extract the text and merge it into a comma-separated string. Looking good!


To keep things simple, I'm just adding the "Features" values (if any) to the end of the existing Tags list.
Ruby has an "unless" operator which usually just makes things extra confusing - but it's handy for short things like this to check for blanks
Ruby has an "unless" operator which usually just makes things extra confusing - but it's handy for short things like this to check for blanks

Since we're just adding to the tags data, we don't have to update anything else - so git commit and publish and ... now you can find the gluten free burgers nearest you.
Total time: 20 minutes, including documentation and a pee break
Total time: 20 minutes, including documentation and a pee break

Anyhow, I hope at least someone out there enjoyed this dive into my punk-rock #HFXBurgerWeek side site.
Check it out if you need a fast way to find a burger near you:
burgerweek.shindigital.com
It's always fun to build and I'm glad I could share it with you.
Check it out if you need a fast way to find a burger near you:
burgerweek.shindigital.com
It's always fun to build and I'm glad I could share it with you.
@threadreaderapp unroll please
• • •
Missing some Tweet in this thread? You can try to
force a refresh


