
📚 Cloud 1x1 - 𝗦𝗲𝗿𝘃𝗲𝗿𝗹𝗲𝘀𝘀 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗮𝗹 𝗣𝗮𝘁𝘁𝗲𝗿𝗻𝘀
You don't need to re-invent the wheel.
You can rely on field-tested patterns.
Let's explore some common ones ↓
You don't need to re-invent the wheel.
You can rely on field-tested patterns.
Let's explore some common ones ↓
𝗣𝗮𝘁𝘁𝗲𝗿𝗻 𝗢𝘃𝗲𝗿𝘃𝗶𝗲𝘄
• Fan-in & Fan-out
• Simple Web Service
• Publish/Subscribe
• Strangler
• Aggregator
{ 1/7 }
• Fan-in & Fan-out
• Simple Web Service
• Publish/Subscribe
• Strangler
• Aggregator
{ 1/7 }
𝗙𝗮𝗻-𝗶𝗻 & 𝗙𝗮𝗻-𝗼𝘂𝘁
Common problem: large tasks that are exceeding Lambda's execution time limit
With Fan-out, you're splitting those large tasks into small ones and delegating those to Lambda workers.
Afterward, results are aggregated (= Fan-in).
{ 2/7 }
Common problem: large tasks that are exceeding Lambda's execution time limit
With Fan-out, you're splitting those large tasks into small ones and delegating those to Lambda workers.
Afterward, results are aggregated (= Fan-in).
{ 2/7 }

𝗦𝗶𝗺𝗽𝗹𝗲 𝗪𝗲𝗯 𝗦𝗲𝗿𝘃𝗶𝗰𝗲
It's the standard pattern where you need to expose functionality via an internal or public interface. Lambda acts as your backend service.
• public exposure: via API Gateway and HTTPs
• internal: invoke Lambda via AWS SDK
{ 3/7 }
It's the standard pattern where you need to expose functionality via an internal or public interface. Lambda acts as your backend service.
• public exposure: via API Gateway and HTTPs
• internal: invoke Lambda via AWS SDK
{ 3/7 }

𝗣𝘂𝗯𝗹𝗶𝘀𝗵/𝗦𝘂𝗯𝘀𝗰𝗿𝗶𝗯𝗲
Mostly you don't want to couple services via synchronous calls, but rather let them interact via events.
If an event gets published, other services can respond.
The initiating system & the consuming ones can grow independently.
{ 4/7 }
Mostly you don't want to couple services via synchronous calls, but rather let them interact via events.
If an event gets published, other services can respond.
The initiating system & the consuming ones can grow independently.
{ 4/7 }

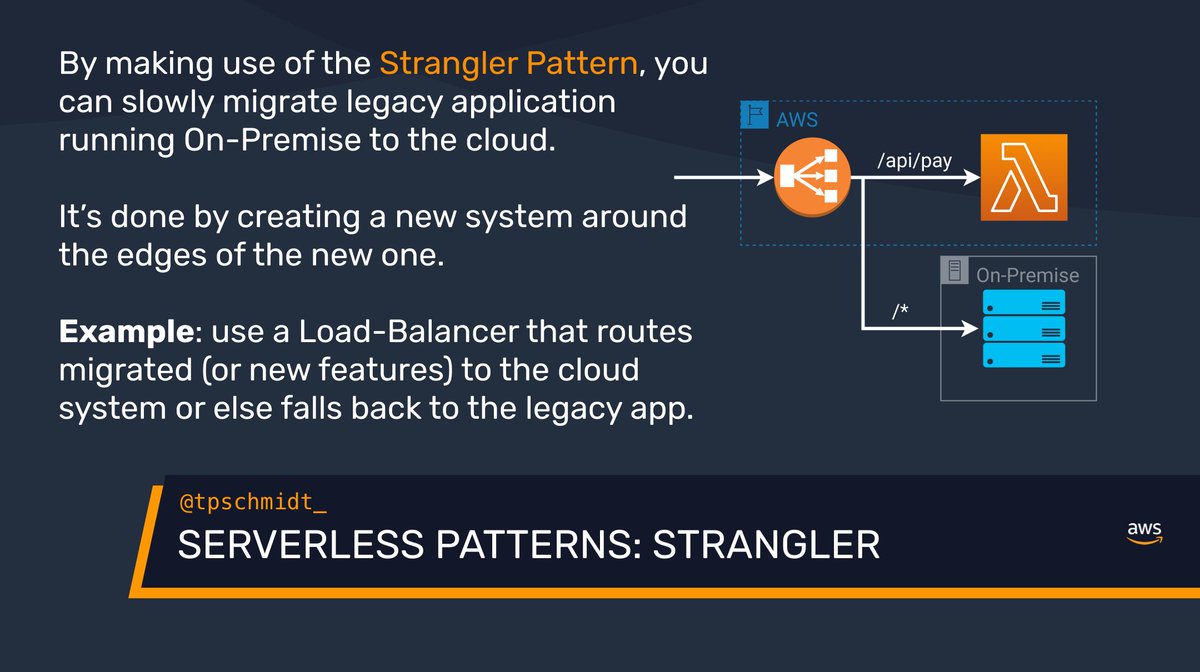
𝗦𝘁𝗿𝗮𝗻𝗴𝗹𝗲𝗿
Migrating legacy systems is a difficult task - generally, you can just switch everything in one step, but slowly move to the new system.
That's why you can rely on a facade that decides where to route to - the legacy app & the new one.
{ 5/7 }
Migrating legacy systems is a difficult task - generally, you can just switch everything in one step, but slowly move to the new system.
That's why you can rely on a facade that decides where to route to - the legacy app & the new one.
{ 5/7 }
𝗔𝗴𝗴𝗿𝗲𝗴𝗮𝘁𝗼𝗿
If an operation needs to fulfill a set of subtasks - often there are also a lot of 3rd parties involved.
As latencies of external calls significantly impact the operations performance, it's advisable to build a centralized aggregator service.
{ 6/7 }
If an operation needs to fulfill a set of subtasks - often there are also a lot of 3rd parties involved.
As latencies of external calls significantly impact the operations performance, it's advisable to build a centralized aggregator service.
{ 6/7 }

It will split up necessities and process all requests to downstream third parties.
It will also collect and temporarily store results and finally aggregate them to return them in a single final response.
{ 7/7 }
It will also collect and temporarily store results and finally aggregate them to return them in a single final response.
{ 7/7 }
There are a lot more patterns to explore - mostly someone that helps you to achieve your goals more easily!
All of them are field-tested and will do well against most DIY approaches 👋
𝗪𝗵𝗮𝘁 𝗮𝗿𝗲 𝘆𝗼𝘂𝗿 𝗳𝗮𝘃𝗼𝗿𝗶𝘁𝗲 𝗼𝗿 𝗺𝗼𝘀𝘁 𝘂𝘀𝗲𝗱 𝗽𝗮𝘁𝘁𝗲𝗿𝗻𝘀? 🏗
All of them are field-tested and will do well against most DIY approaches 👋
𝗪𝗵𝗮𝘁 𝗮𝗿𝗲 𝘆𝗼𝘂𝗿 𝗳𝗮𝘃𝗼𝗿𝗶𝘁𝗲 𝗼𝗿 𝗺𝗼𝘀𝘁 𝘂𝘀𝗲𝗱 𝗽𝗮𝘁𝘁𝗲𝗿𝗻𝘀? 🏗
𝗕𝗼𝗻𝘂𝘀 𝗧𝗶𝗽
Check out if there are weak points in your architecture with Dashbird's Well-Architected Lens 🔎
It analyses the 𝘀𝗲𝗰𝘂𝗿𝗶𝘁𝘆, 𝗲𝗳𝗳𝗶𝗰𝗶𝗲𝗻𝗰𝘆 & 𝗿𝗲𝗹𝗶𝗮𝗯𝗶𝗹𝗶𝘁𝘆 of your serverless apps.
... and there's a free trial 👋
dashbird.io/serverless-wel…
Check out if there are weak points in your architecture with Dashbird's Well-Architected Lens 🔎
It analyses the 𝘀𝗲𝗰𝘂𝗿𝗶𝘁𝘆, 𝗲𝗳𝗳𝗶𝗰𝗶𝗲𝗻𝗰𝘆 & 𝗿𝗲𝗹𝗶𝗮𝗯𝗶𝗹𝗶𝘁𝘆 of your serverless apps.
... and there's a free trial 👋
dashbird.io/serverless-wel…
𝗣𝗿𝗮𝗶𝘀𝗲 & 𝗰𝗿𝗲𝗱𝗶𝘁𝘀 👏
If you want to read more about the shown and more great patterns, you have to read 𝗦𝗲𝗿𝘃𝗲𝗿𝗹𝗲𝘀𝘀 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗮𝗹 𝗣𝗮𝘁𝘁𝗲𝗿𝗻𝘀 by Eduardo Romero (@foxteck) on Medium.
Thank you, Eduardo! 🎉
medium.com/@eduardoromero…
If you want to read more about the shown and more great patterns, you have to read 𝗦𝗲𝗿𝘃𝗲𝗿𝗹𝗲𝘀𝘀 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗮𝗹 𝗣𝗮𝘁𝘁𝗲𝗿𝗻𝘀 by Eduardo Romero (@foxteck) on Medium.
Thank you, Eduardo! 🎉
medium.com/@eduardoromero…
• • •
Missing some Tweet in this thread? You can try to
force a refresh



