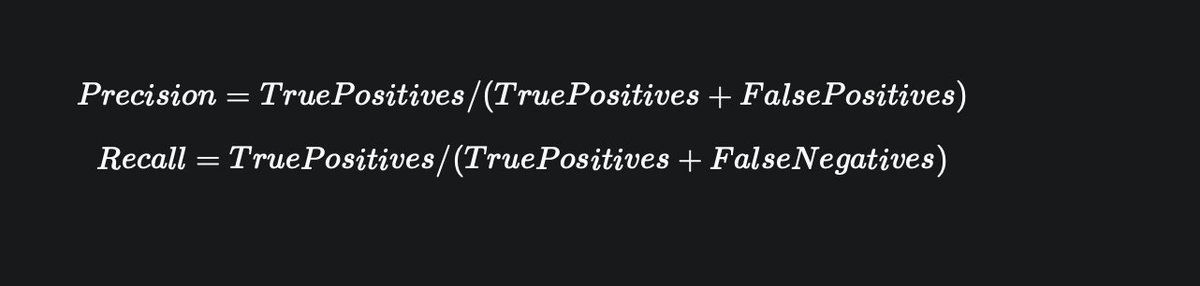Why is so hard to train neural networks?
Neural networks are hard to train. The more they go deep, the more they are likely to suffer from unstable gradients.
A thread 🧵🧵
Neural networks are hard to train. The more they go deep, the more they are likely to suffer from unstable gradients.
A thread 🧵🧵
Gradients can either explode or vanish, and neither of those is a good thing for the training of our network.
The vanishing gradients problem results in the network taking too long to train(learning will be very slow), and the exploding gradients cause the gradients to be very large.
Although those problems are nearly inevitable, the choice of activation function can reduce their effects.
Using ReLU activation in the first layers can help avoid vanishing gradients.
Using ReLU activation in the first layers can help avoid vanishing gradients.
That is also the reason why we do not like to see sigmoid activation being used in the first layers of the network because it can cause the gradients to vanish quickly.
Careful weight initialization can also help, but ReLU is by far the good fix.
This short thread was only about the high-level understanding of the issue. If you would like to learn more, you can read this stats discussion
stats.stackexchange.com/questions/2627…
stats.stackexchange.com/questions/2627…
Or read chapter 5 of the book Neural networks and Deep Learning by Michael Nielsen.
neuralnetworksanddeeplearning.com/chap5.html#the…
neuralnetworksanddeeplearning.com/chap5.html#the…
Thanks for reading.
If you found the thread helpful, you can retweet or share it with your friends.
Follow @Jeande_d for more machine learning content.
If you found the thread helpful, you can retweet or share it with your friends.
Follow @Jeande_d for more machine learning content.
• • •
Missing some Tweet in this thread? You can try to
force a refresh