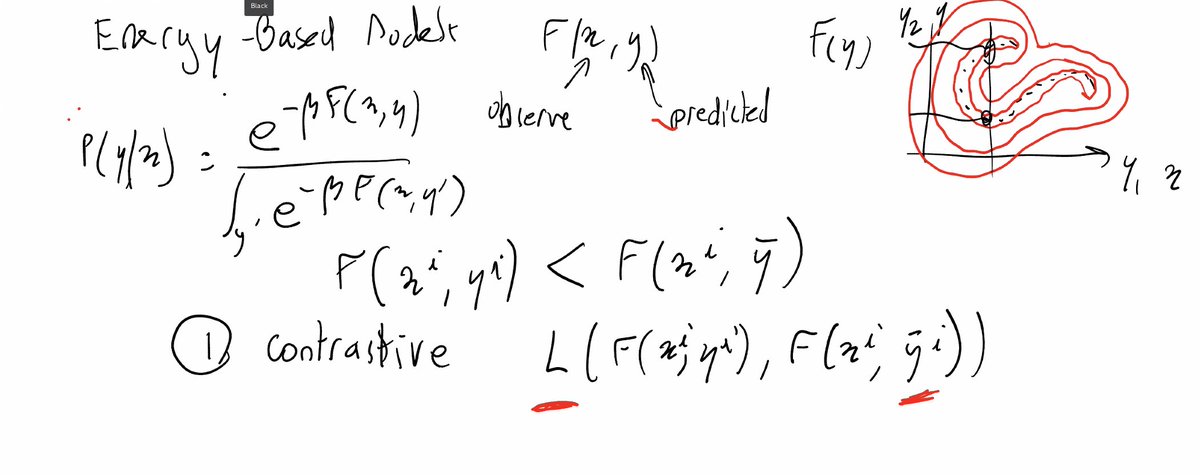
In his @NVIDIAGTC keynote Jensen Huang demonstrates @NVIDIAAI leading position in powering the AI ecosystem in R&D, enterprise and edge computing, with a zillion new announcements. Here's a few notable ones.
Graph Neural Network acceleration with CUDA-X. 

Nemo Megatron allows training GPT-3 scale Large Language Models on distributed hardware.

Distributed Inferencing of very large models with a new version of Triton.


Here's a schematic overview of all the @NVIDIAGTC announcements.

• • •
Missing some Tweet in this thread? You can try to
force a refresh