A few highlights from @nlpnoah's talk at insights-workshop.github.io:
@nlpnoah: NLP research and practice ask fundamentally different questions
/1
@nlpnoah: NLP research and practice ask fundamentally different questions
/1

@nlpnoah: NLP practice asks whether X improves the outcome. NLP research tries to fill in the gaps in the knowledge map.
/2
/2


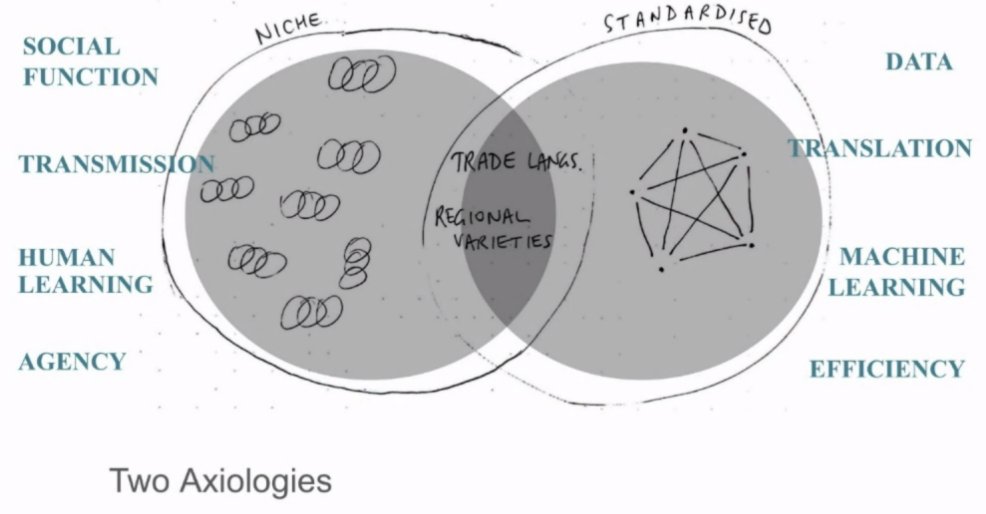
@nlpnoah: Leaderboards are the dominant frame for presenting research findings. That frame by its very nature puts the winner at the top, and un-focuses all of this:
/3
/3



@nlpnoah The very notion of "negative results" presupposes that very same sports-like frame! Useful as the leaderboards are, they are not the only thing we need.
(with follow-up comment from Margot Mieskes: the Insights workshop should be renamed!)
/6
(with follow-up comment from Margot Mieskes: the Insights workshop should be renamed!)
/6

@nlpnoah: a bonus from focusing on gaining knowledge and not on sota-ing is improved mental health. If you're trying to answer a question, whatever answer you get is a result.
/8
/8

Question: in an exploding field the simple leaderboard frame is partly a coping mechanism for the authors to try to reach a broader audience.
@nlpnoah: NLP community is not all that homogeneous. Let's be brave, non-mainstream papers may find a wider audience than we think.
/9
@nlpnoah: NLP community is not all that homogeneous. Let's be brave, non-mainstream papers may find a wider audience than we think.
/9
Question: one reason for leaderboards is to enable people to easily compare with prior work. How about we just publish multiple metrics, for maximal reach to future work?
@nlpnoah: Might work. We could also release raw system outputs.
/10
@nlpnoah: Might work. We could also release raw system outputs.
/10
• • •
Missing some Tweet in this thread? You can try to
force a refresh