
Language models are some of the most interesting and most promising research topics in AI. After all, being able to communicate with humans naturally has long been considered *the* ultimate goal for AI (Turing test).
arxiv.org/abs/2111.09509
#NLP #AI #ML #DS 1/3
arxiv.org/abs/2111.09509
#NLP #AI #ML #DS 1/3
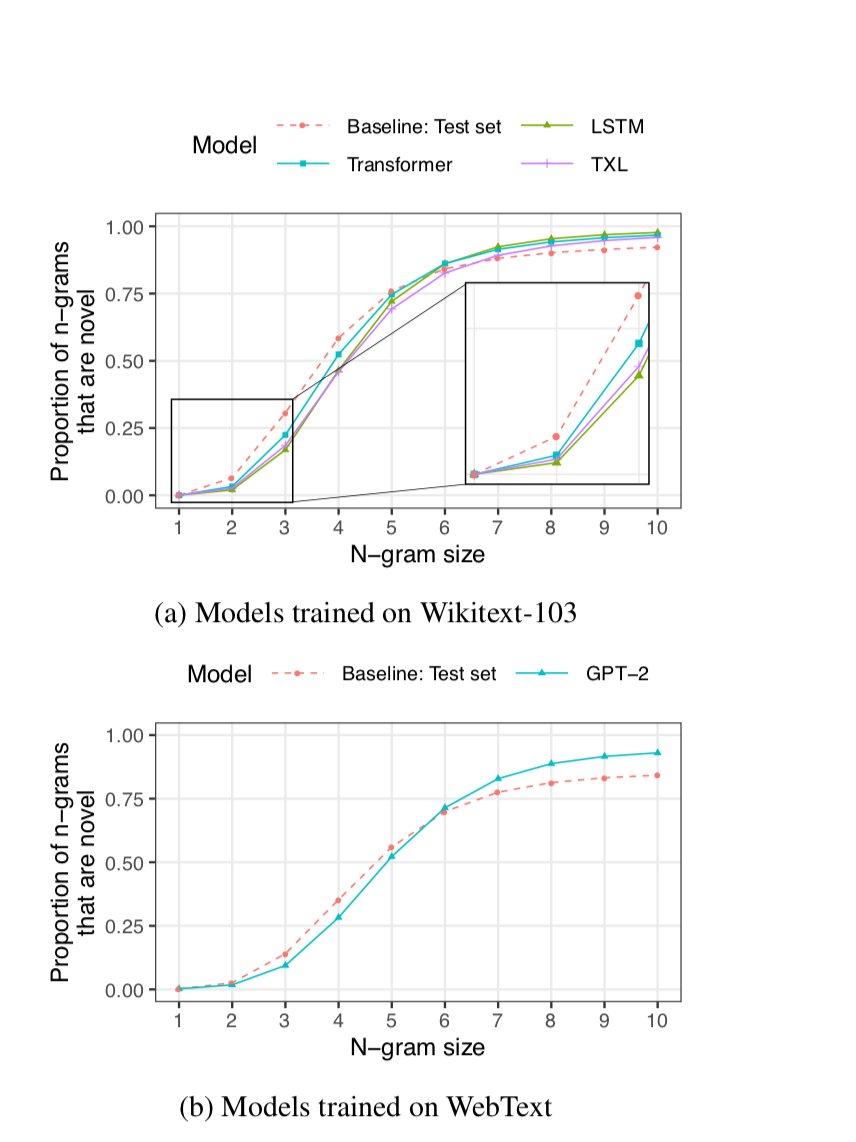
However, even though large language models in particular are very powerful at generating new text, it is still an ongoing source of debate of how much of that ability is just "rote memorization", and how much is rooted in genuinely fundamental language understanding. 2/3
The interesting paper above tries to answer some of those questions. It would seem that the language models are quite capable of coming up with genuinely novel texts, especially for larger paragraphs, but they still seem to lack the basic semantic understanding of language. 3/3
• • •
Missing some Tweet in this thread? You can try to
force a refresh



