
Deep RL is hard: lots of hparam tuning, instability. Perhaps there is a reason for this? Turns out the same thing that makes supervised deep learning work well makes deep RL work poorly, leading to feature vectors that grow out of control: arxiv.org/abs/2112.04716
Let me explain:
Let me explain:
Simple test: compare offline SARSA vs offline TD. TD uses the behavior policy, so same policy is used for the backup, but SARSA uses dataset actions, while TD samples *new* actions (from the same distr.!). Top plot is phi(s,a)*phi(s',a'): dot prod of current & next features. 

Well, that's weird. Why do TD feature dot products grow and grow until the method gets unstable, while SARSA stays flat? To understand this, we must understand implicit regularization, which makes overparam models like deep nets avoid overfitting.
When training with SGD, deep nets don't find just *any* solution, but a well regularized solution. SGD finds lower-norm solutions that then generalize well (see derived reg below). We might think that the same thing happens when training with RL, and hence deep RL will work well.

But if we apply similar logic to deep RL as supervised learning, we can derive what the "implicit regularizer" for deep RL looks like. And it's not pretty. First term looks like the supervised one, but the second one blows up feature dot products, just like we see in practice!

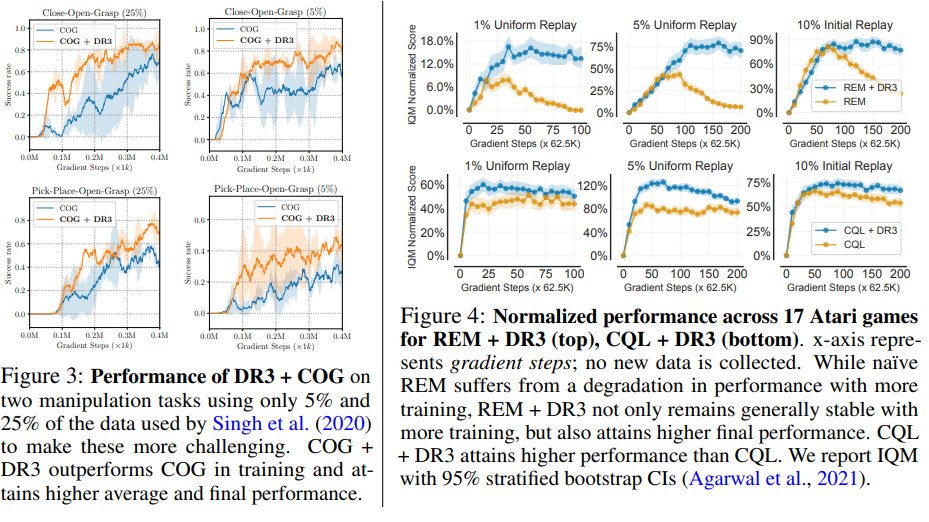
In practice, we can simply add some *explicit* regularization on the features to counteract this nasty implicit regularizer. We call this DR3. It simply minimizes these feature dot products. Unlike normal regularizers, DR3 actually *increases* model capacity!

We can simply add DR3 to standard offline RL algorithms and boost their performance, basically without any other modification. We hope that further research on overparameterization in deep RL can shed more light about why deep RL is unstable and how we can fix it!
This work was presented as a full-length oral at the NeurIPS Deep RL workshop: sites.google.com/view/deep-rl-w…
Paper: arxiv.org/abs/2112.04716
Work led by @aviral_kumar2, with @agarwl_, @tengyuma , @AaronCourville, @georgejtucker
Paper: arxiv.org/abs/2112.04716
Work led by @aviral_kumar2, with @agarwl_, @tengyuma , @AaronCourville, @georgejtucker
• • •
Missing some Tweet in this thread? You can try to
force a refresh
















