📊 Robustness Reports on ImageNet!
We've indexed AugLy's robustness reports, which show model vulnerabilities to different manipulations. Check it out below:
paperswithcode.com/sota/image-cla…
1/4
We've indexed AugLy's robustness reports, which show model vulnerabilities to different manipulations. Check it out below:
paperswithcode.com/sota/image-cla…
1/4
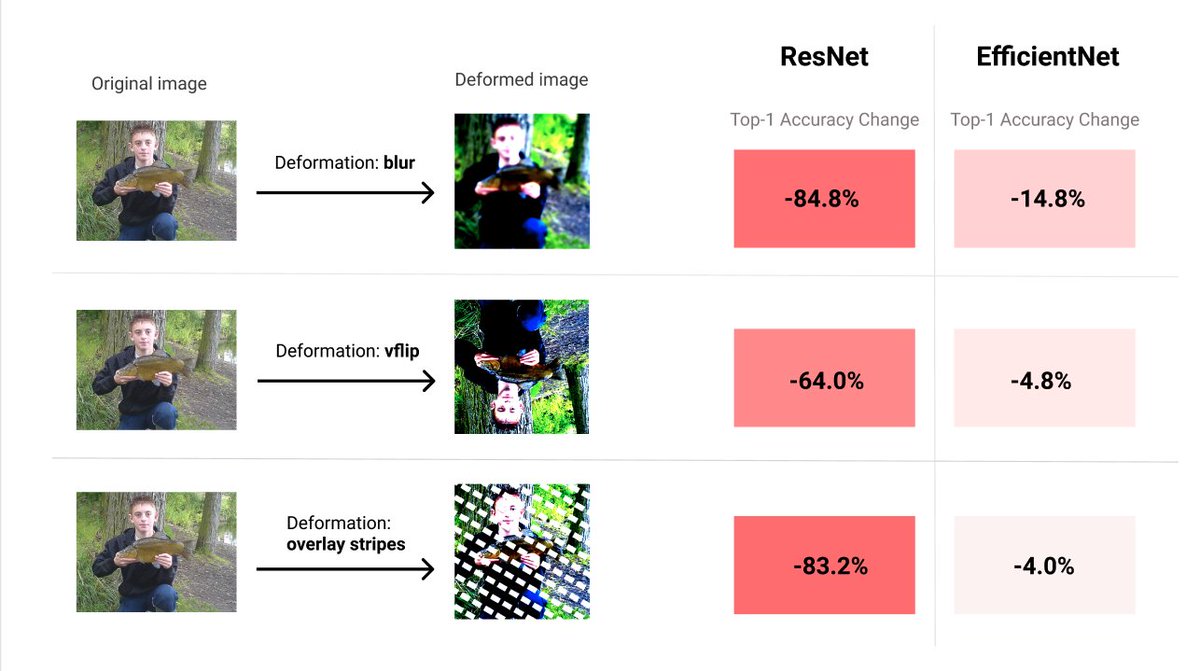
Reports shows that EfficientNet not only has higher accuracy on ImageNet, but is also significantly more robust than older models.
Accuracy is one measure of performance, but it doesn’t capture how robust the model is to simple manipulations such as noise and rotation...
2/4
Accuracy is one measure of performance, but it doesn’t capture how robust the model is to simple manipulations such as noise and rotation...
2/4
Using AugLy’s image augmentations it's possible to test each model’s vulnerability to different manipulations in the robustness reports.
You can also produce your own robustness reports for models using AugLy and add them to the Papers with Code leaderboards.
3/4
You can also produce your own robustness reports for models using AugLy and add them to the Papers with Code leaderboards.
3/4
Thanks to @zoe_papakipos & @adversarialjo, the team of Meta AI engineers behind AugLy (github.com/facebookresear…), for the collaboration.
4/4
4/4
• • •
Missing some Tweet in this thread? You can try to
force a refresh