
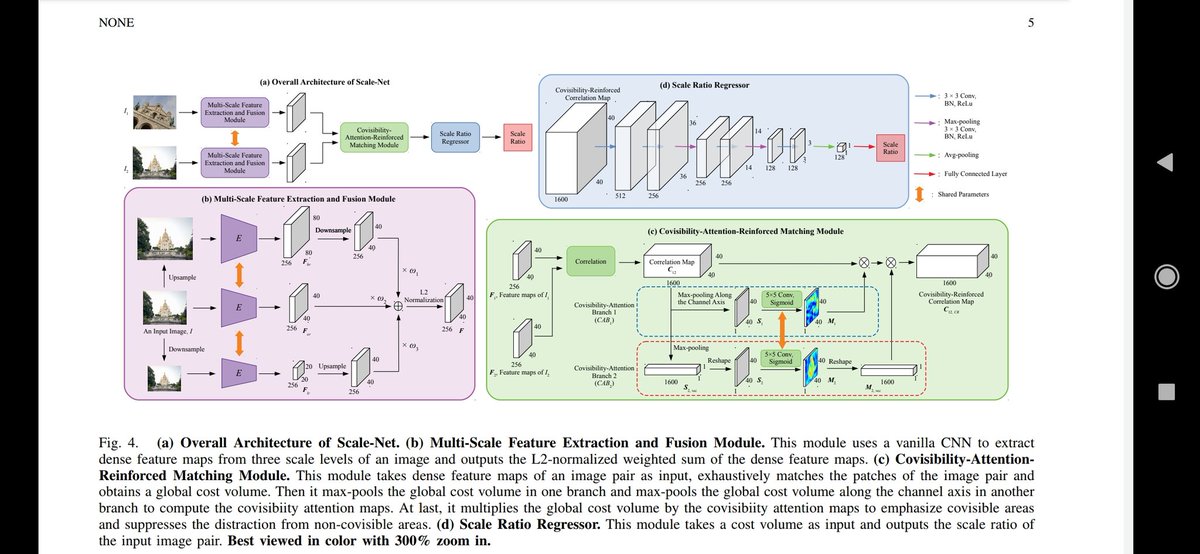
Scale-Net: Learning to Reduce Scale Differences for Large-Scale Invariant Image Matching
tl;dr: same idea as with other ScaleNet: estimate scale difference in 2 images-> resize them. Eval on their version of Scale IMC
1/2 (check 2nd)
Yujie Fu, Yihong Wu
arxiv.org/abs/2112.10485
tl;dr: same idea as with other ScaleNet: estimate scale difference in 2 images-> resize them. Eval on their version of Scale IMC
1/2 (check 2nd)
Yujie Fu, Yihong Wu
arxiv.org/abs/2112.10485



In order to prove priority and originality of the idea w.r.t. @axelbarrosotw ScaleNet, authors included #ICCV2021 submission screenshot as a proof.
Weird, however that current paper has less authors.
2/2
Weird, however that current paper has less authors.
2/2


This is other ScaleNet
https://twitter.com/ducha_aiki/status/1470744571894288385?t=BDNgJrtSN1pw9aYW-0qVpA&s=19
• • •
Missing some Tweet in this thread? You can try to
force a refresh

















