Je vous propose un petit thread sur notre atelier de médiation scientifique sur l'#IA réalisé lors de la Nuit Blanche des Chercheurs #nbc à la @Halle6Ouest. Un projet évolutif auquel nous vous invitons à contribuer avec @Chaire_RELIA @classcode_fr et @LaboLS2N @NantesUniv 🧐👇 

Cet atelier se base sur une interpretation de l'oeuvre "1000" créé par le collectif d'artistes/chercheurs Exsitu: exsitu.xyz/home Une structure d'1m de haut présentant une collection de 1000 objets ramassés sur la route dans 23 pays lors d'un tour du monde à vélo.

Chacun de ces objets à été encapsulé dans un tube en verre, et peut être éclairé indépendamment par des leds. Le tout étant monté en circuit linéaire, comme une guirlande, sur 10 étages de 100 objets. Contrôlé par un #raspberrypi, il est associé à un système audio et vidéo.

Le sujet qui nous intéresse ici est que cette récolte d'objets physiques s'est accompagnée d'une liste de métadonnées mise en forme dans un csv: taille, couleur, poids, pays, coordonnées GPS, matière... des dizaines de données associées à chaque objet. #data

Le tout formant une sorte de dataset physique permettant d'interagir avec l'oeuvre, en illuminant certains objets en fonction de critères et de diffuser images et sons. Par exemple le parcours par km, les objets trouvés en Afrique ou tous les objets en plastique et vert par ex.


Le travail de la @Chaire_RELIA commence ici. Notre défi était de créer un algorithme capable de trouver n'importe quel objet parmi les 1000, choisi par un spectateur dans le public. L'algo devant être capable de "deviner" l'objet en posant des questions exploitant les données.

Les participants choisissent un objet dans l'oeuvre et nous leur fournissons une fiche d'identité de l'objet sur un support externe (une petite mallette écran) afin qu'ils puissent avoir toutes les données liées aux objets non déductibles de leur simple apparence.

Les participants répondent ensuite aux questions posées par l'algo. Celui-ci va opérer des déductions et orienter ses questions à la manière d'un @Akinator_FR. C'est alors la même logique qu'un jeu du "Qui est-ce ?" mais avec 1000 objets potentiels...

L'algo fonctionne sur une base logique extrêmement simple: Trouver l'objet avec le moins de question possible, et donc tenter de diviser la liste d'objets restants par 2 à chaque question posée. On parvient ainsi à trouver chaque objet en 10 questions en moyenne. (Mini 6 maxi 14)
On met a disposition de l'algo une liste de questions écrites (seulement 17 dans notre cas). Son rôle est d'évaluer le coefficient discriminant de chaque question pour chaque étape. Si on a un coeff de 0,50 par exemple, cela signifie que la question permettrait d'en éliminer 50%.
Notre algo peut donc se résumer à un algo glouton qui ne se pose qu'une question"Qu'elle est la question à ma disposition dont le coeff est le plus proche de 0,50 ?" Et qui permettrait donc de diviser le nombre d'objets restants par 2.On répète l'opération jusqu'à trouver l'objet
En soit n'importe quelle question peut être candidate en fonction de l'ensemble d'objet restants. On pourrait donc intégrer n'importe quelle question, même semblant hors de propos. On a d'ailleurs mis à disposition du public une boite à question pour les intégrer plus tard.
Au final, nous avons donc un algo qui fonctionne, trouve n'importe quel objet en 10 questions, en exploitant des données. Mais est-ce bien de l'#IA ? D'où provient l'intelligence ? Celle mise dans la rédaction des questions et des règles utilisées ? Est-ce optimal ?
Ce sont ces questions qui servent de base à la suite de l'atelier. Permettant de s'interroger sur l'intelligence, la méthode, la "triche statistique" et sur les architectures potentielles pour résoudre un même problème.
On a par ex pu intégrer des fonctions exploitant l'ingénierie sociale, en créant une liste d'objets plus susceptibles d'être choisis (1ère couche contrairement au centre). Ou créé des questions "parfaites" en prenant la médiane des poids ou tailles pour avoir un coeff de 0,50...
...et ce quel que soit les objets restants dans la liste. Nous avons aussi aussi augmenté l'impression de "divination" en créant des déductions hors contexte (par ex en déduisant que l'objet à été trouvé un mardi puisqu'il est en plastique).
Le traitement des données par un algo simple, proche de la pensée humaine, était ici un parti pris. Nous souhaitons maintenant explorer des méthodes plus complexes (arbre de décision, clustering, ML et DL) afin de montrer d'autres architectures.
Notre prochain enjeu sera la création de "faux souvenirs" des objets créés par une #IA (fiche d'identité des données et photo de l'objet) en utilisant un #GAN pour les photos. Et de voir si on arrive à différencier un faux objet d'un vrai. ia-human.univ-nantes.fr

Toutes les données sont en accès libres sur un Github. Vous pouvez donc tenter votre propre exploitation de celles-ci. A l'avenir nous aimerions que vous puissiez même interagir avec l'oeuvre 1000 physiquement à distance et dans une expo virtuelle.
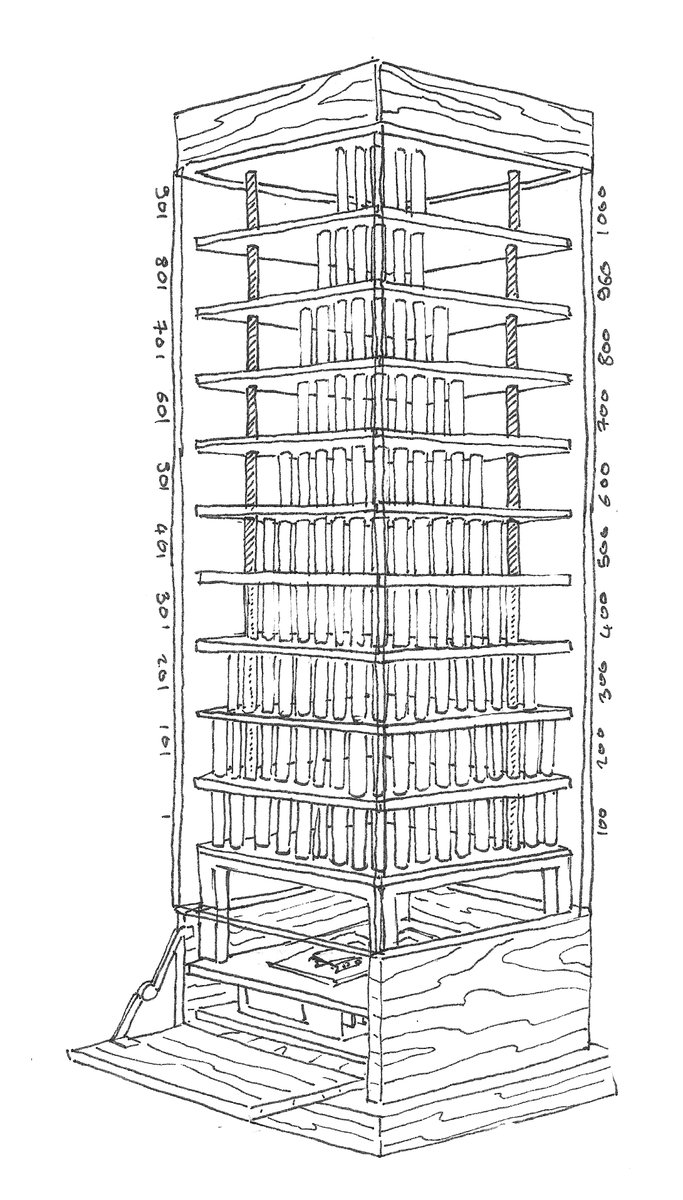
L'oeuvre est visible à la @Halle6Ouest tout le mois de février et vous pouvez me contacter pour en savoir plus. Documentation et sources: exsitu.xyz/prod/creation/…
• • •
Missing some Tweet in this thread? You can try to
force a refresh