
GLaM, l’outil d’apprentissage de google MuM ? (Generalist Language Model) #GLaM #AI
A thread ⬇️ lune.space/glam-loutil-da…
A thread ⬇️ lune.space/glam-loutil-da…
Aujourd'hui je vais vous parler encore de MuM et de la manière dont Google l'entraîne.
Vous savez certainement que l'avenir de Google qui a été présenté lors de l'événement Google IO 2021 est dans l'intelligence artificielle pour proposer des résultats qui vont aller au-delà de ce que l'on trouve actuellement dans son index.
Avec d'un côté MuM pour gérer la parrallélisation des recherches via des vases d'information expertes qu'ils appellent les MOE pour Mixture of Experts, et de l'autre LaMDA qui sera le moteur la partie moteur vocal text to speech (une evolution de ok google conversationnel en…
…quelque sorte)
J'avais fait passer cette info lors du seocamp actu en janvier, mais les levées de fond de la frenchtech l'avaient emporté et je n'avais pas eu le temps de faire un article ;-)
J'avais fait passer cette info lors du seocamp actu en janvier, mais les levées de fond de la frenchtech l'avaient emporté et je n'avais pas eu le temps de faire un article ;-)
Une partie de cet article a été écrit avec Jasper (bit.ly/jasper-boss) l'outil de rédaction AI (copywriting-ai.fr)basé sur l'intelligence artificielle GPT-3, pour lequel je vais proposer une formation.
https://t.co/HYznWyRhmY
https://t.co/HYznWyRhmY
Une autre partie a été traduite avec deepl parcque les infos brut sont plus efficaces, et vous trouverez la source chez google.
Qu'est-ce que GLaM ?
Il s'agit d'un article qui détaille comment google affine son machine learning avec GLaM en consommant moins de ressources et d'energies. Mais c'est intéressant de comprendre comment MuM va fonctionner également.
Il s'agit d'un article qui détaille comment google affine son machine learning avec GLaM en consommant moins de ressources et d'energies. Mais c'est intéressant de comprendre comment MuM va fonctionner également.
Cela nous indique également qu'en améliorant l'optimisation de ses process, on pourrait voir débarquer plus rapidement MuM de manière général dans le moteur de recherche.
Entre le moment ou google a annoncé BERT et son intégration effectif dans le moteur de recherche, il s'est passé 6 mois (ils avaient même fait un rollback parcque ça avait merdé).
Est-ce que MuM est implémenté dans le moteur de recherche google ?
Les premières utilisations de MuM sont sur la requête Covid-19. Mais MuM n'est pas officiellement implémenté.
Les premières utilisations de MuM sont sur la requête Covid-19. Mais MuM n'est pas officiellement implémenté.
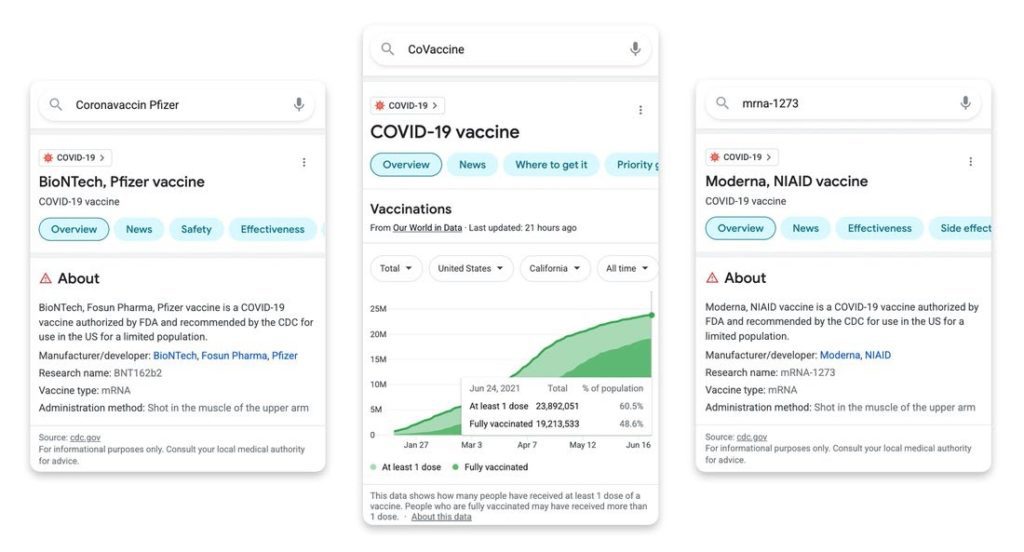
La communication sur Glam date de janvier. Cela veut dire qu'il nous reste encore une courbe d'apprentissage pour MuM qui va se concentrer sur des système expert.
Par exemple pour la recherche contre le cancer, il ira se connecter sur des bases de données de recherche plutôt que d'aller piocher sur votre MFA (adsense, amazon) pour soigner son cancer avec des feuille d'eucalyptus végan pique a un panda, cultivé au clair de lune.
Sa marge d'apprentissage malgrès ses optimisations devrait prendre du temps quand même. Il est en phase d'apprentissage donc il reste encore du spam quali à créer pour l'entraîner.
Comment fonctionne l'apprentissage NLP (natural language processing) ?
Les modèles de langage de grande taille (par exemple, GPT-3) ont de nombreuses capacités importantes, telles que l'apprentissage en quelques apprentissages courts dans un large éventail de tâches, y compris la compréhension de la lecture et la réponse à des questions avec très…
…peu ou pas d'exemples d'entraînement.
Bien que ces modèles puissent être plus performants en utilisant simplement plus de paramètres, l'apprentissage et l'utilisation de ces grands modèles peuvent être très gourmands en ressources informatiques.
Bien que ces modèles puissent être plus performants en utilisant simplement plus de paramètres, l'apprentissage et l'utilisation de ces grands modèles peuvent être très gourmands en ressources informatiques.
Est-il possible de former et d'utiliser ces modèles plus efficacement ? Dans certains cas, il est possible de former un modèle plus efficacement en utilisant un ensemble de données plus petit ou moins de couches.
Cependant, dans de nombreux cas, la meilleure façon de réduire le coût de calcul de la formation est d'utiliser une implémentation plus efficace du modèle, comme une implémentation GPU.
Performances de GLaM par rapport à GPT-3
Les performances de GLaM se comparent favorablement à celles d'un modèle de langage dense, GPT-3 (175B), dont l'efficacité d'apprentissage a été considérablement améliorée dans 29 repères publics de traitement de language naturel dans sept catégories, couvrant les tâches de…
…complétion de langage, de réponse à des questions dans un domaine ouvert et d'inférence en langage naturel.
La sparsité est un moyen de s'assurer qu'un modèle de langage utilise moins de mémoire et occupe moins d'espace sur un ordinateur. C'est important car cela signifie que le modèle peut être entraîné et utilisé plus efficacement.
GLaM, un nouveau modèle de langage présenté dans cet article, est capable d'atteindre des performances compétitives sur plusieurs tâches avec une efficacité d'apprentissage améliorée grâce à la sparsité.
Avec quoi est alimenté GLaM ?
Nous avons commencé à construire GLaM en créant une base de données qualitatives et représentatives de 1,6 trillion de tokens contenant des utilisations linguistiques pour une variété d'utilisations futures du modèle.
Les pages web constituent la quantité énorme de données dans ce corpus non marqué, mais leur qualité va du texte professionnel à des commentaires et forums mal rédigés.
Nous avons ensuite développé un filtre de qualité du texte qui a été entraîné sur une collection de textes tirés Wikipedia et de livres.
Model et Architecture de GlaM
GLaM est un modèle composé de différents sous-modèles (ou experts), mixture of experts (MoE), chacun d'entre eux étant spécialisé pour une entrée différente. Les experts sont contrôlés par un réseau de déclenchement, qui active les experts en fonction des données d'entrée.
Pour chaque jeton (généralement un mot ou une partie d'un mot), le réseau de déclenchement sélectionne les deux experts les plus appropriés pour traiter les données.
La version complète de GLaM a 1,2T de paramètres totaux à travers 64 experts par couche MoE avec 32 couches MoE au total, mais n'active qu'un sous-réseau de 97B (8% de 1,2T) paramètres par prédiction de token pendant l'inférence.
En résumé :
En résumé :
GLAM est un modèle composé de différentes parties, ou experts. Les experts sont activés par un réseau qui sélectionne les deux experts les plus appropriés pour chaque entrée. Ces modèles ont quelques paramètres, mais n'en activent que 8% lorsqu'ils prédisent des choses.
L'architecture du Transformer est composée d'un seul réseau feedforward (la couche la plus simple d'un réseau neuronal artificiel, "Feedforward ou FFN" dans les cases bleues), qui est remplacé par une couche MoE.
Cette couche MoE comporte plusieurs experts, chacun étant un réseau feedforward avec une architecture identique mais des paramètres de poids différents.
Bien que cette couche MoE ait beaucoup plus de paramètres, les experts sont activés de manière éparse, ce qui signifie que pour un jeton d'entrée donné, seuls deux experts sont utilisés.
Pendant l'apprentissage, le réseau de déclenchement de chaque couche MoE est entraîné à utiliser son entrée pour activer les deux meilleurs experts pour chaque jeton.
A retenir :
A retenir :
- L'architecture du transformer est composée d'un seul réseau à action directe (une couche très simple dans un réseau neuronal artificiel).
- Ce réseau à action directe est remplacé par une couche comportant de nombreux experts, chacun étant un réseau à action directe avec un ensemble différent de paramètres de poids.
- Bien que cette couche MoE ait beaucoup plus de paramètres, les experts sont activés de manière éparse, ce qui signifie que pour un jeton d'entrée donné, seuls deux experts sont utilisés.
- Pendant la formation, le réseau de déclenchement de chaque couche MoE est entraîné à utiliser son entrée pour activer les deux meilleurs experts pour chaque jeton.
La représentation finale d'un jeton sera la combinaison pondérée des sorties des deux experts. Cela permet à différents experts de s'activer sur différents types d'entrées.
Pour permettre la mise à l'échelle de modèles plus importants, chaque expert de l'architecture GLaM peut couvrir plusieurs dispositifs de calcul.
Nous utilisons le backend du compilateur GSPMD pour résoudre les défis liés à la mise à l'échelle des experts et entraînons plusieurs variantes (basées sur la taille et le nombre d'experts) de cette architecture afin de comprendre les effets de la mise à l'échelle des modèles…
…de langage activés de manière éparse.
Les résultats de l'évaluation montrent que le modèle donne de bons résultats sur une série de tâches en langage naturel, certaines tâches obtenant une précision nettement supérieure à d'autres.
En particulier, le modèle surpasse les autres modèles de pointe pour les tâches de cloze et de complétion, les réponses aux questions du domaine ouvert, les tâches de type Winograd, les tâches de raisonnement sensé et les tâches de compréhension de lecture en contexte.
En outre, les tâches SuperGLUE sont également bien exécutées par le modèle.
GLaM se résume à une architecture de modèle dense basique basée sur les Transformateurs lorsque chaque couche MoE n'a qu'un expert.
Dans toutes les expériences, nous adoptons la notation de (taille du modèle dense en paramètres) / (nombre d'experts par couche MoE) pour décrire le modèle GLaM.
Par exemple, 1B/64E représente l'architecture d'un modèle dense en paramètres de 1B avec chaque couche autre que la couche MoE rem
GLaM est un modèle de langage basé sur un transformateur dense qui donne de bons résultats dans un certain nombre de tâches. Il utilise beaucoup moins de calcul pendant l'inférence que le modèle Megatron-Turing.
- GLaM est au même niveau que le modèle Megatron-Turing pour les 7 tâches en utilisant une marge de 5% (ndlr: megatron (developer.nvidia.com/blog/using-dee…) est le système de machine learning de NVIDIA, oui celui qui fait les cartes graphiques pour miner le bitcoin entre autre)
- Utilise 5 fois moins de calculs pendant l'inférence
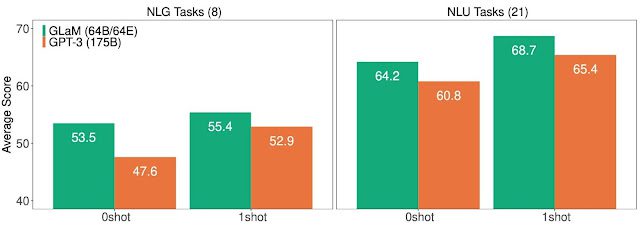
Nous présentons ci-dessous un résumé des performances sur 29 benchmarks par rapport au modèle dense (GPT-3, 175B). GLaM est supérieur ou égal à la performance du modèle dense sur presque 80% des tâches zero-shot et presque 90% des tâches one-shot.
Évaluation Supérieure (>+5%) Équivalente (dans les 5%) Inférieure (<-5%)
Tâche zéro 13 11 5
One-shot 14 10 5
Tâche zéro 13 11 5
One-shot 14 10 5
De plus, alors que la version complète de GLaM possède 1,2T de paramètres au total, elle n'active qu'un sous-réseau de 97B paramètres (8% de 1,2T) par token pendant l'inférence.
GLaM (64B/64E) GPT-3 (175B)
Paramètres totaux 1.162T 0.175T
Paramètres activés 0,097T 0,175T
GLaM (64B/64E) GPT-3 (175B)
Paramètres totaux 1.162T 0.175T
Paramètres activés 0,097T 0,175T
Voilà après je vous épargne les concours de celui qui a la plus grande... base de paramètres.
Donc même si MuM n'est pas encore là, vous savez maintenant qu'il utilise GLaM pour son entraînement et que bientôt faire une trad auto deepl ou google translate ne sera peut être plus aussi efficace, et cela aura un impact également sur le fait que google index ou pas une…
…ressource.
This thread can be read here: lune.space/glam-loutil-da…
• • •
Missing some Tweet in this thread? You can try to
force a refresh







