
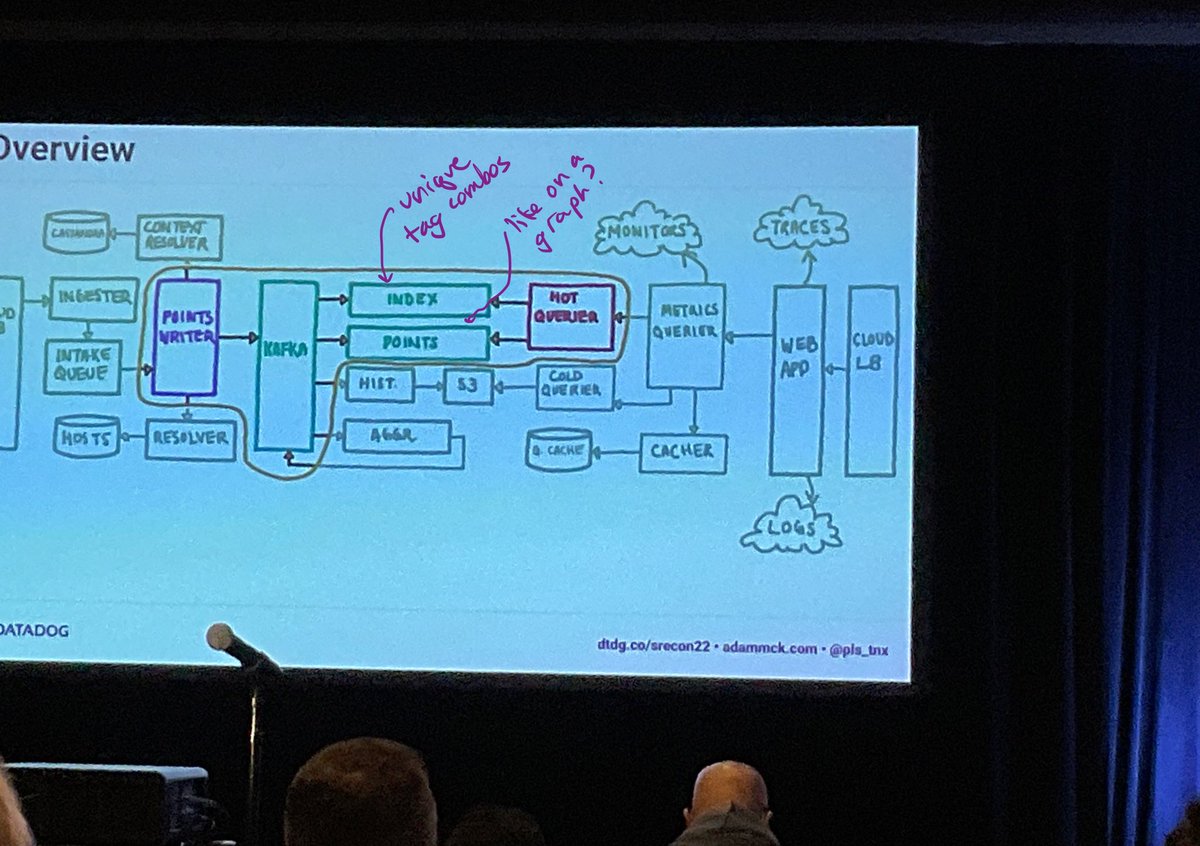
This afternoon at #srecon, Adam Mckaig and Tahia Khan from @datadoghq about the evolution of their metrics backend 

The high-level architecture looks very familiar to me. The slightly more detailed less so — many parts!


For scale, break up incoming data, put into kafka.
hash(customer_id) -> partition_id
… but then one kafka topic gets overloaded, so…
hash(customer_id) -> topic_id, partition_id
to send to topics in different clusters.
hash(customer_id) -> partition_id
… but then one kafka topic gets overloaded, so…
hash(customer_id) -> topic_id, partition_id
to send to topics in different clusters.


Later, some customers are too big.
So for those customers:
hash(metric_id) -> topic, partition
Since metrics are queried individually, @datadoghq can split up data to that fine grain and each query will still only need to hit one partition. #SREcon
So for those customers:
hash(metric_id) -> topic, partition
Since metrics are queried individually, @datadoghq can split up data to that fine grain and each query will still only need to hit one partition. #SREcon
Partitions still get unbalanced. Some customers, and some metrics, are way bigger than others.
So @datadoghq got smart with its partitioning, implementing Slicer based on a paper from Google.
#srecon
So @datadoghq got smart with its partitioning, implementing Slicer based on a paper from Google.
#srecon
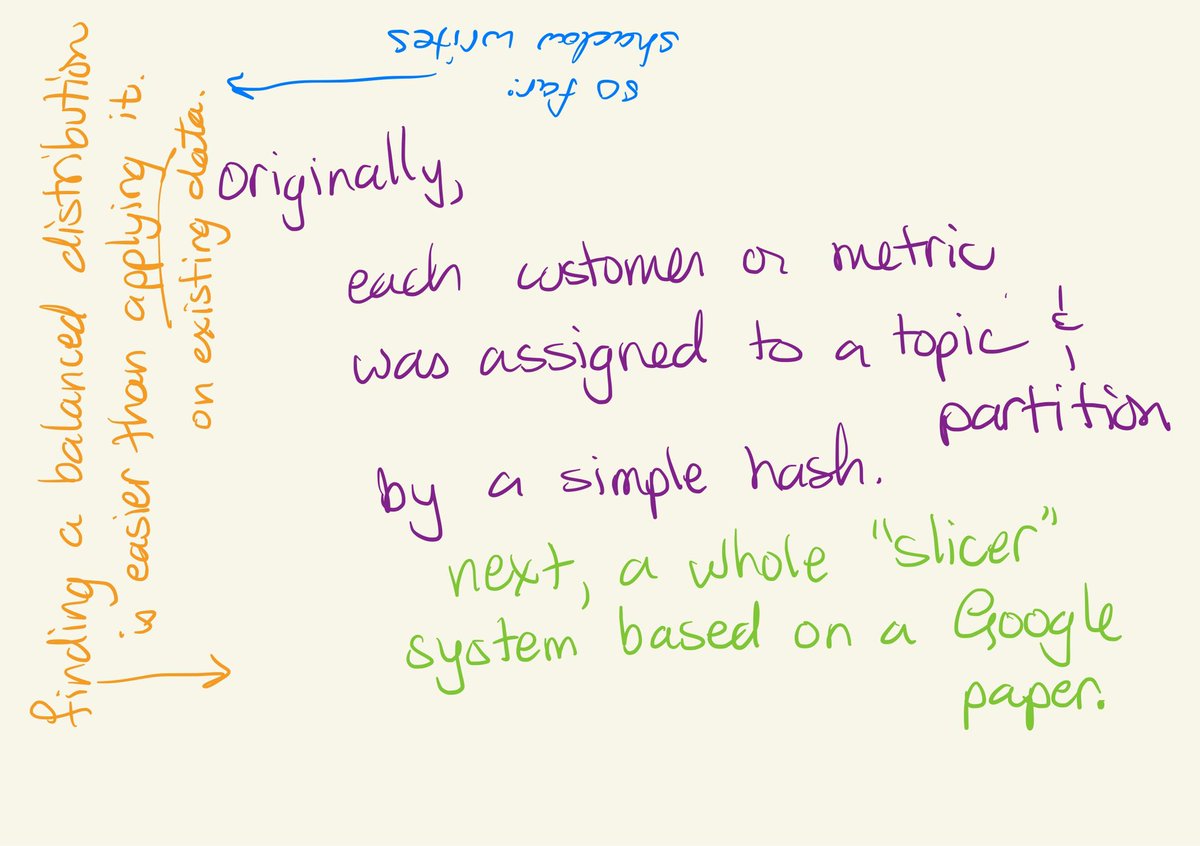
The storage layer knows nothing about the partitioning scheme.
Intake and Query need the mapping from (customer, metric) to (cluster, partition) so they can send to & query from the same node.
Intake and Query need the mapping from (customer, metric) to (cluster, partition) so they can send to & query from the same node.

• • •
Missing some Tweet in this thread? You can try to
force a refresh

















