
During training, your loss goes up and down up and down up and down.
But how would it go if you magically went in a straight line
from init to learnt position?
Apparently smoothly down!
On the surprising Linear Interpolation:
#scientivism #deepRead #MachineLearning
But how would it go if you magically went in a straight line
from init to learnt position?
Apparently smoothly down!
On the surprising Linear Interpolation:
#scientivism #deepRead #MachineLearning

It all started on ICLR2015(!)
@goodfellow_ian @OriolVinyalsML @SaxeLab
Checked points between the converged model and the random initialization.
They found that the loss between them is monotonically decreasing.
@goodfellow_ian @OriolVinyalsML @SaxeLab
Checked points between the converged model and the random initialization.
They found that the loss between them is monotonically decreasing.

Why shouldn't it?
Well... The real question is why should it.
If the loss terrain is anything but a slope, we would expect bumps. Maybe there are different sinks (local minima), or you need to get a bad model before you reach the best model (topologically, you are in a ditch)
Well... The real question is why should it.
If the loss terrain is anything but a slope, we would expect bumps. Maybe there are different sinks (local minima), or you need to get a bad model before you reach the best model (topologically, you are in a ditch)
One way to look at this interpolation is thinking on the graph as a slice of the loss space.
A straight line between init and converged looks as above (going down a hill).
If you got up the hill before getting down, you hit a
barrier
A straight line between init and converged looks as above (going down a hill).
If you got up the hill before getting down, you hit a
barrier
The original conclusion was:
"The reason for the success of SGD on a wide variety of tasks is now clear: these tasks are relatively easy to optimize."
You probably feel this itch too... Don't worry, later literature contested this.
"The reason for the success of SGD on a wide variety of tasks is now clear: these tasks are relatively easy to optimize."
You probably feel this itch too... Don't worry, later literature contested this.
@jefrankle continued this work with modern settings (2020) arxiv.org/pdf/2012.06898…
He replicated the main results. But:
He replicated the main results. But:
1⃣ In larger datasets loss improvement came only close to the endpoint, so optimization is more like looking for a hole in a field than going down a mountain (convex).

2⃣ Loss space is not simple.
The way from init to other points in space (iterations in training) goes through barriers (see the hills in the figure).
So it is not that all optimization is convex and simple. It is somehow a trait of the converged point.
The way from init to other points in space (iterations in training) goes through barriers (see the hills in the figure).
So it is not that all optimization is convex and simple. It is somehow a trait of the converged point.

@james_r_lucas @juhan_bae @michaelrzhang @stanislavfort Richard Zemel @RogerGrosse replicated it
But also found when it does NOT work:
large learning rate, batch-norm, adam
At least two may result from just going far away before converging
proceedings.mlr.press/v139/lucas21a.…
But also found when it does NOT work:
large learning rate, batch-norm, adam
At least two may result from just going far away before converging
proceedings.mlr.press/v139/lucas21a.…
This graph is so pretty, I couldn't resist putting it too... (speaks for itself)

Just now came the last call on this topic by Tiffany Vlaar and @jefrankle.
They share the mixed feelings about the phenomenon.
Specifically, they show test results and the loss slice from init to your point are not correlated.
arxiv.org/pdf/2106.16004…
They share the mixed feelings about the phenomenon.
Specifically, they show test results and the loss slice from init to your point are not correlated.
arxiv.org/pdf/2106.16004…
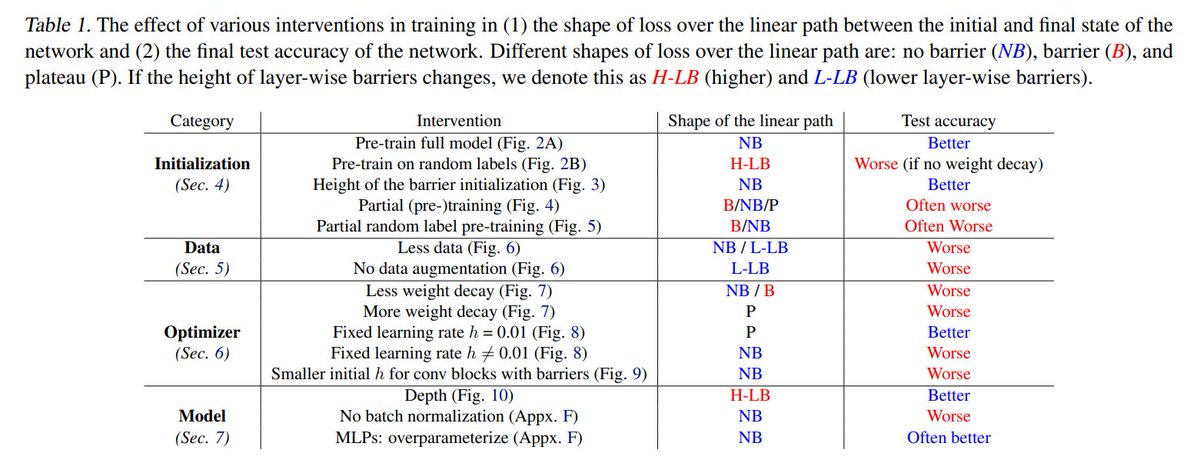
First, they show that pretraining reduces the barriers (Intuitive, true, but someone needed to show it) and
bad init adds such barriers:
Intuitively, to converge one needs to move out of bad local minima, not only to decrease to a minima
bad init adds such barriers:
Intuitively, to converge one needs to move out of bad local minima, not only to decrease to a minima
Making more complex training data adds barriers and (obviously) improves test score.
(my) possible explanation: complex training forces exiting the initial local minima (not minima for each subset of the data = batch).
(my) possible explanation: complex training forces exiting the initial local minima (not minima for each subset of the data = batch).
Weight decay (in addition to learning rate and adam mentioned) also controls the loss path seen in interpolation.

The authors deduce that this path should not tell you about what happened to the model, as more barriers mean again higher test scores.
I probably miss something, but IIUC it means that they are connected. If you passed barriers before convergence, it might just be that you got out of some local minima and reached a lower point.
(yes, one can devise a bad optimizer that just randomly moves, it will pass barriers)
(yes, one can devise a bad optimizer that just randomly moves, it will pass barriers)
Of course, if you start from a point that leads to less barriers with the same optimization, that IS a good thing (it didn't bother going away, you are already near a minima)
Last, the authors say their results are negative (as far as I can see they are just analysis work, which in this untreated territory is great) and they share it for the "widespread use". What do people use this for? Is it actually well known?
To sum up, I feel there is a lot to talk about the meaning of all of this, fascinating! What do pertaining, bad init, decay, momentum and so on has to do with the loss path, but I believe those results might click on different points of view, so I will leave mine out of it.
Oh, they may hint on it at one point near the end "a more difficult optimization trajectory can lead to improved generalization"
Oh, a last note, none of it was really tested on #NLProc ... So we assume it is all just the same.
If you got this far, you might like this as well
https://twitter.com/LChoshen/status/1491375423120613378
• • •
Missing some Tweet in this thread? You can try to
force a refresh






