
"I have nooooo idea what to do with all this @screamingfrog information" - @danielkcheung, circa 2018-2020
If you want to learn to do some #technicalseo with one of the best crawling tools out there, here is a 🧵for you.
If you want to learn to do some #technicalseo with one of the best crawling tools out there, here is a 🧵for you.
.@screamingfrog is a crawler that you download and install onto a local or virtual machine. It allows you to crawl almost any website.
I use it as part of my technical seo audit and their customer service is 🔥
However, the initial learning curve is steep.
I use it as part of my technical seo audit and their customer service is 🔥
However, the initial learning curve is steep.

If you've looked at a finished @screamingfrog crawl and felt overwhelmed - you're NOT alone.
I, and many others, were in your EXACT shoes.
It's ok
You've got this💪🏽
⏩ Here a 9 tips to make your life with Screaming Frog easier, more enjoyable, and F-U-N👇
I, and many others, were in your EXACT shoes.
It's ok
You've got this💪🏽
⏩ Here a 9 tips to make your life with Screaming Frog easier, more enjoyable, and F-U-N👇
1. Run in database storage mode
Configuration > System > Storage mode
Doing so will save your crawl data automatically to your computer and allows you to compare between crawls of the same site.
Configuration > System > Storage mode
Doing so will save your crawl data automatically to your computer and allows you to compare between crawls of the same site.
2. You don't need to crawl an entire site
Crawling an entire website can take hours (sometimes days).
🧠You don't *always* need to have full information to make recommendations. Often, a sample is all you need to ID symptoms and make relevant recommendations.
Crawling an entire website can take hours (sometimes days).
🧠You don't *always* need to have full information to make recommendations. Often, a sample is all you need to ID symptoms and make relevant recommendations.
3. Add sitemap address to get sitemap insights
Because many robots.txt files do not reference the sitemap index URL you will have to add it yourself👇
Because many robots.txt files do not reference the sitemap index URL you will have to add it yourself👇
4. Run crawl analysis to see sitemap issues such as:
⚠️ orphaned URLs
⚠️ URLs not in sitemap
⚠️ non-indexable URLs in sitemap
Once your crawl has finished, go to Crawl Analysis > Start then click on the Sitemaps tab and the right hand side panel will display sitemap stats👇
⚠️ orphaned URLs
⚠️ URLs not in sitemap
⚠️ non-indexable URLs in sitemap
Once your crawl has finished, go to Crawl Analysis > Start then click on the Sitemaps tab and the right hand side panel will display sitemap stats👇
💡FYI, you can run a crawl analysis at any stage of the crawl - you do not have to wait to crawl the entire site.
This is great for crawling large sites and you want to get a sense if there are issues with the its sitemap.
Click Pause > Crawl Analysis > Start👇
This is great for crawling large sites and you want to get a sense if there are issues with the its sitemap.
Click Pause > Crawl Analysis > Start👇
💡A website's sitemap is one of the first things I look at.
🧠If I see many non-indexable URLs in the sitemap or many orphaned URLs, this is a strong signal that there are a host of technical issues and warrants a full audit.
Learn more about sitemaps👇
danielkcheung.com.au/xml-sitemap-fo…
🧠If I see many non-indexable URLs in the sitemap or many orphaned URLs, this is a strong signal that there are a host of technical issues and warrants a full audit.
Learn more about sitemaps👇
danielkcheung.com.au/xml-sitemap-fo…
5. Crawl a *specific* subfolder of a site (and nothing else)
Eg, I want to crawl all the URLs within /blog/ subfolder of a website.
To do this, go to Configuration > Include then put in https://domain/blog/.*
⚠️Don't forget the ‼️.*‼️
Eg, I want to crawl all the URLs within /blog/ subfolder of a website.
To do this, go to Configuration > Include then put in https://domain/blog/.*
⚠️Don't forget the ‼️.*‼️
6. On your first crawl, crawl HTML files only
By default, @screamingfrog will crawl all image, CSS, JS and SWF files.
💡Uncheck these for your initial crawl to get a quick sense of the URLs and will save you some time.
By default, @screamingfrog will crawl all image, CSS, JS and SWF files.
💡Uncheck these for your initial crawl to get a quick sense of the URLs and will save you some time.
7. Run crawler in Javascript mode
Many websites are single-page applications or rely on JS to render ⚡️important⚡️ content. Running in JS mode in @screamingfrog will give you a proxy of how well (or not) Google can crawl and render any website.
Many websites are single-page applications or rely on JS to render ⚡️important⚡️ content. Running in JS mode in @screamingfrog will give you a proxy of how well (or not) Google can crawl and render any website.
To do this:
1⃣ Configuration > Spider > Rendering
2⃣ Change "text only" to "javascript"
When crawling in JS mode:
• @screamingfrog takes a lot longer (so be patient)
• go to Rendered Page to see if all important content can be rendered
1⃣ Configuration > Spider > Rendering
2⃣ Change "text only" to "javascript"
When crawling in JS mode:
• @screamingfrog takes a lot longer (so be patient)
• go to Rendered Page to see if all important content can be rendered
It *literally* took me 3.5 years to discover the Rendered Page tab (👏@myriamjessier for showing me👏).
This is where you'll find the rendered view when you run a JS crawl in @screamingfrog 👇
This is where you'll find the rendered view when you run a JS crawl in @screamingfrog 👇
💡If you don't see the body content shown in the Rendered Page panel, this is probably a strong signal that Google will have issues rendering text and internal links on the website.
💡If this happens, corroborate with Google Search Console data.
💡If this happens, corroborate with Google Search Console data.
Since @screamingfrog takes⏳to crawl in JS mode, TameTheBots by @davewsmart is ⚡️ah-mazing⚡️ for quick diagnosis on a page-by-page basis.
IE, if important content is not displayed - this indicates a potential issue with rendering, indexing and ranking.
tamethebots.com/tools/fetch-re…
IE, if important content is not displayed - this indicates a potential issue with rendering, indexing and ranking.
tamethebots.com/tools/fetch-re…
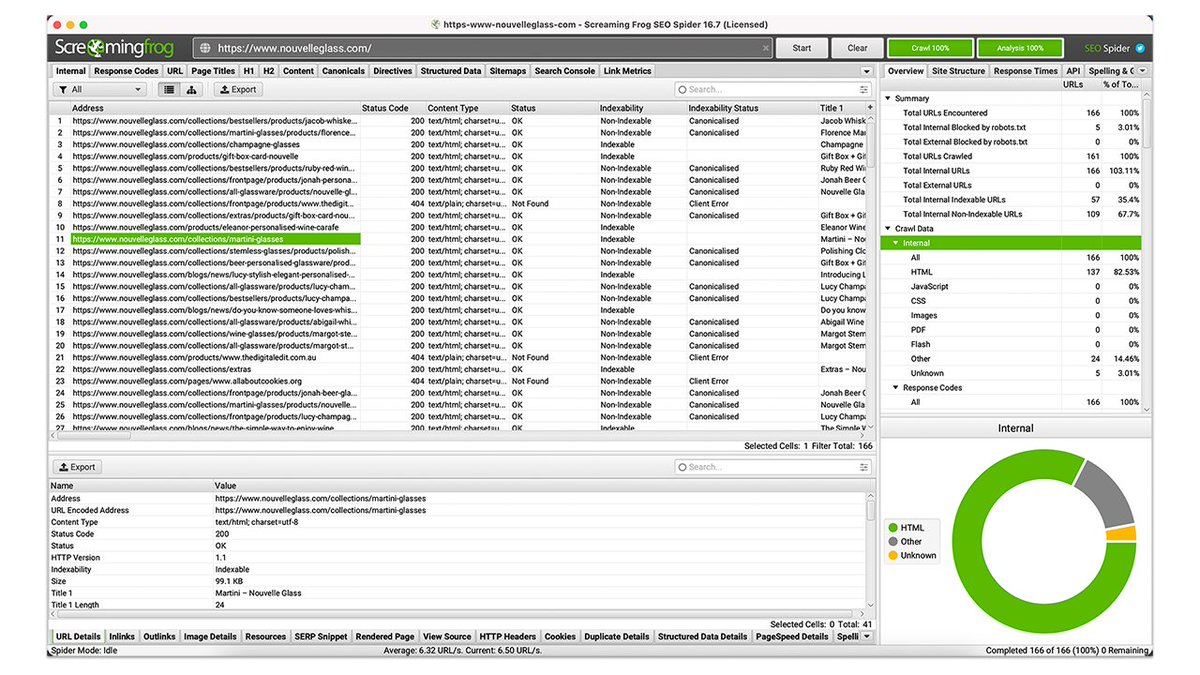
8. Look for 301, 302, 404 response codes
💡Most sites will have URLs that 301/302 redirect or have pages with 404 response codes.
After a crawl go to the Response Codes tab and filter URLs in ascending/descending order. This will show you all the URLs that are non-200👇
💡Most sites will have URLs that 301/302 redirect or have pages with 404 response codes.
After a crawl go to the Response Codes tab and filter URLs in ascending/descending order. This will show you all the URLs that are non-200👇
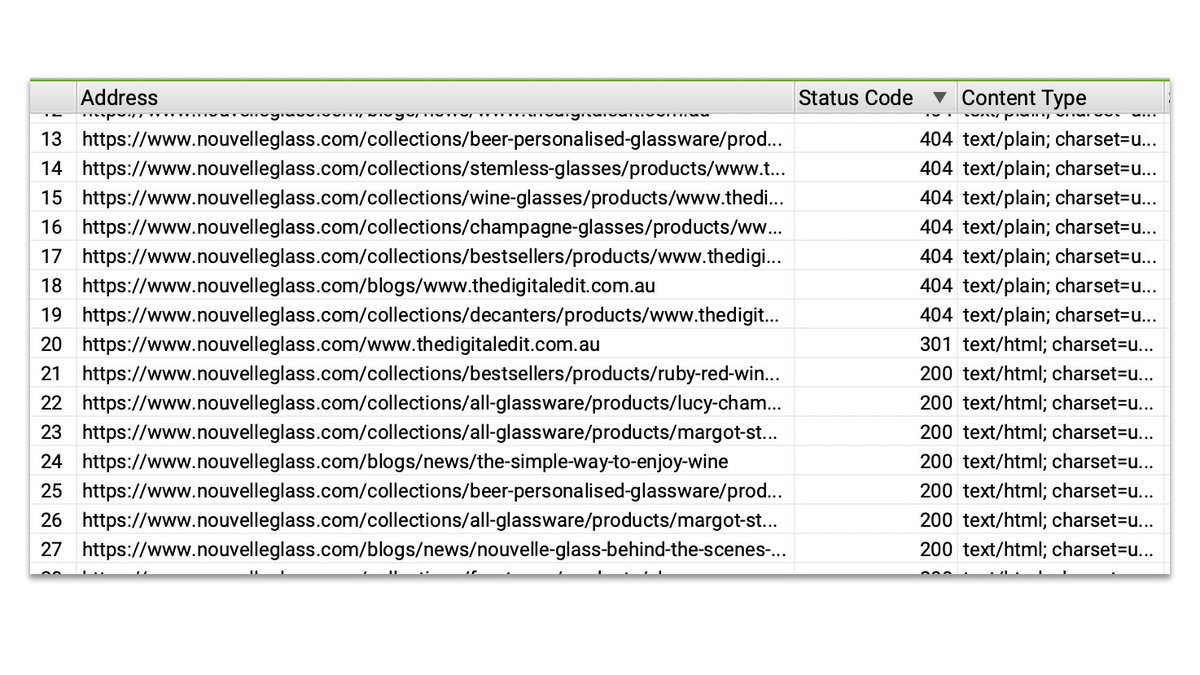
💡A really quick way to see this is by running as little extractions as possible.
You can do this by unchecking all "Resource Links" in Crawl Configuration and unchecking everything in Page Details in "Extraction".
You can do this by unchecking all "Resource Links" in Crawl Configuration and unchecking everything in Page Details in "Extraction".
9. Find low-content pages
URLs with less than 200 words often lack depth and may contribute to poor indexing of URLs. Luckily @screamingfrog can easily show you these URLs.
💡To find these run a Crawl Analysis, go to Content Tab then look for Low Content Pages.
URLs with less than 200 words often lack depth and may contribute to poor indexing of URLs. Luckily @screamingfrog can easily show you these URLs.
💡To find these run a Crawl Analysis, go to Content Tab then look for Low Content Pages.
💡 Not *all* pages with less than 200 words = bad. You'll have to use your own judgement to decide if the ones @screamingfrog has shown you are appropriate or not.
Recommended reading re: thin content pages (via @JonasSickler)👇
terakeet.com/blog/what-is-t…
Recommended reading re: thin content pages (via @JonasSickler)👇
terakeet.com/blog/what-is-t…
And that's a wrap! I trust you found this insightful and inspired you to want to work with @screamingfrog even if you don't fully understand it.
For more, give me a follow
@danielkcheung to see how else I can inspire you in your SEO journey👇
For more, give me a follow
@danielkcheung to see how else I can inspire you in your SEO journey👇
https://twitter.com/danielkcheung/status/1524633365072289793?s=20&t=tTN6rh5zcKxMjybVDB0dfw
• • •
Missing some Tweet in this thread? You can try to
force a refresh






