The London stock market is now closed and $ONT.L Oxford @nanopore is presenting technology updates. I'll live tweet my highlights, but won't be thoroughly complete with screenshots (thread)
https://twitter.com/nanopore/status/1527328231661006848
My COIs bit.ly/avilcoi
First talk is James Clark for Platform updates.
But Clive is already saying there will be a "thing at the end" that you want to stick around for. Reminiscent to the "one more thing" that certain Apple presentations had for a while.
Current platform with the P2 released in 2022 

Flowcell pore counts are 1x to 4x to 24x from Flongle to MinION to PromethION flowcells. So 3 main "platform sizes", similar to the 3 main platform sizes (instruments) that $ILMN Illumina has.
PromethION best of all flowcell now, latest iteration of ASIC and the rest. P2 instrument makes it more accessible for all budgets.

Chemical and sample loading changes to optimise the process

The triangle of better, cheaper and faster, here Quality, Volume and Features. Biosensing continuous iteration process.

New products coming soon, mainly new ASIC-derived in the near future.

New ASIC being road tested on Flongle flowcells

New ASIC has a simpler printing, small path to the electrodes, which means high accuracy.

My take from here: the ASIC part of the technology is akin to the physics/electronics part of other sequencing technologies. The rest is molecular biology, similar to the polymerases and reagents in other technologies. Both bound by our still incomplete understanding of both.
Nanopore Chemistry. Where are we and where are we going?

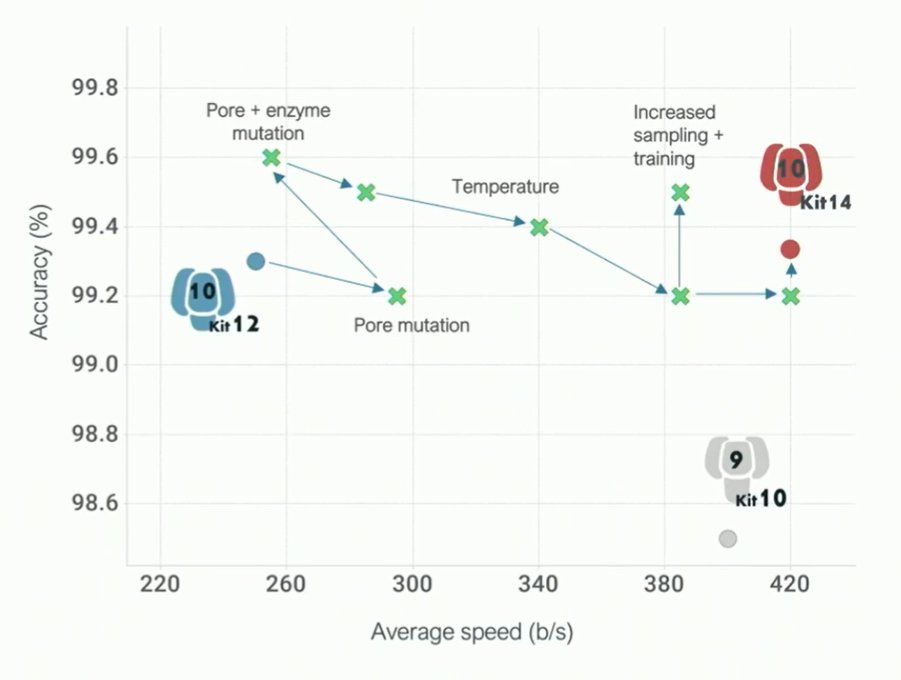
The short blanket problem of optimising both throughput and accuracy, here displayed in an x-y plot over time

Accuracy plots and pore speed plots of current iteration
This is tunable: faster or more accurate in different modes.

It's already out and people are testing it in the field. Smoothest Early Access ever.

Duplex reads, let's see what is the rate of efficiency of the process, going up to 40%, with a target of 60%. If we compare to Illumina's Paired End, that would seem to be 100% but...

... remember Illumina only shows the successfully paired-end reads, so it has to be 100% by definition.
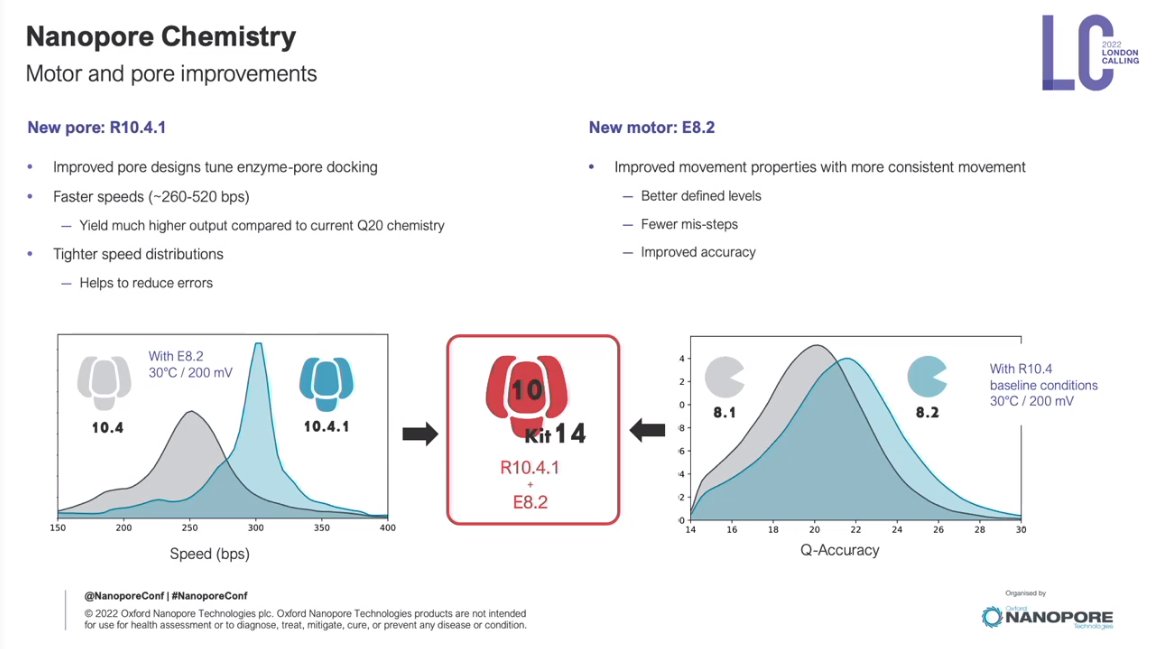
The new pore is a nonamer (reads 9-nts) and is what has taken simplex accuracy to 98%.

Better Simplex, better Duplex, overall better accuracy. What else can be improved? Homopolymer chemistry improvements.

How do we define accuracy? Raw read, variant calling, consensus, testing accuracy, etc.

On test accuracy, nothing like COVID19 variant surveillance to describe what the technology can do, both in terms of accuracy but in Oxford @nanopore's case also in ease of deployment.
Duplex accuracy very independent of read length. $PACB PacBio engineers may look at this and be a bit worried that Oxford @nanopore has something better than HiFi.

Nothing like an IGV @igvteam plot to show how things have progressed

Consensus/assembly numbers: maybe everything will be assembly-based in human genomics in the future (as people like @lh3lh3 keep saying), so these numbers matter.

Variants, not showing DeepVariant here (not invented here bias?), but I would say in many ways on par with $PACB and $ILMN on this front.

Bsae modifications, I am particularly proud to see that 5hmC is now a first-class mod. Very important for #LiquidBiopsy early cancer screening -- people will find out soon.

Headline slide

Built-in short fragment mode, meaning getting 250M reads from a single PromethION flowcell, regardless of length.
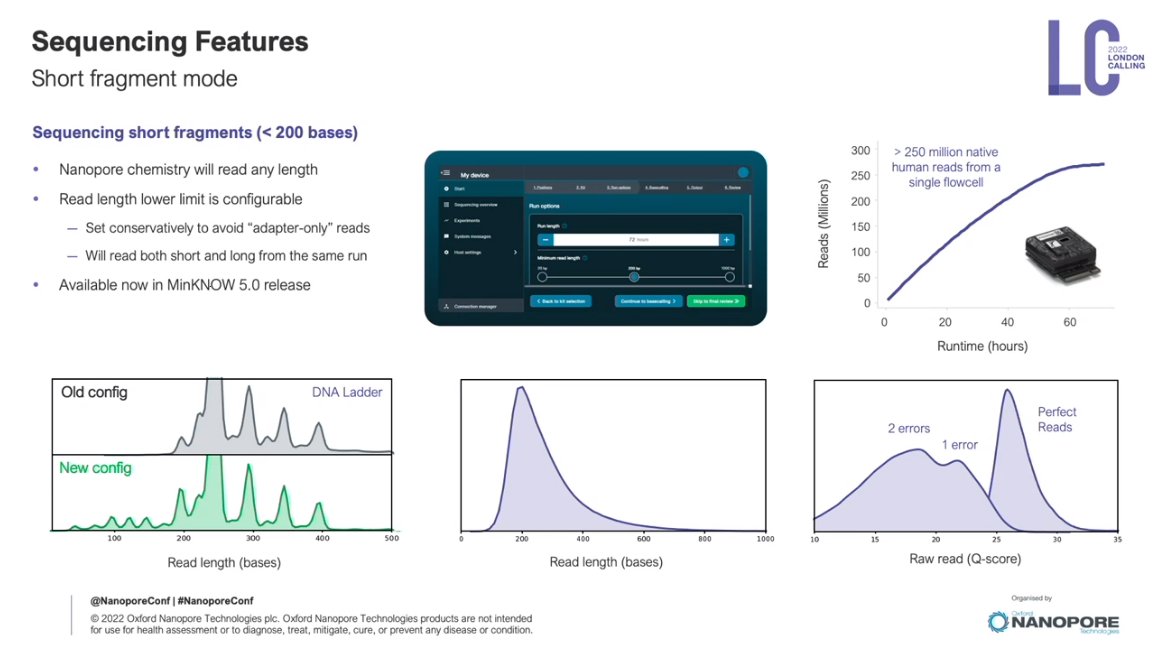
Adaptive sampling: nobody else can do this natively. Average 3x fold enrichment, but improvements coming. Still, 3x cheaper/better than not doing it.

More formats! Pod5 format as a replacement to Fast5. Many workaround coming from feedback from the Slow5 academic project. Between 4-10x improvement in performance.

New version of the basecaller, Dorado with ground-up rewrite. I am sure Chris @iiSeymour and the team are very proud of it.

Products section by @RosemaryDokos with highlights including starter packs that make this accessible to people...
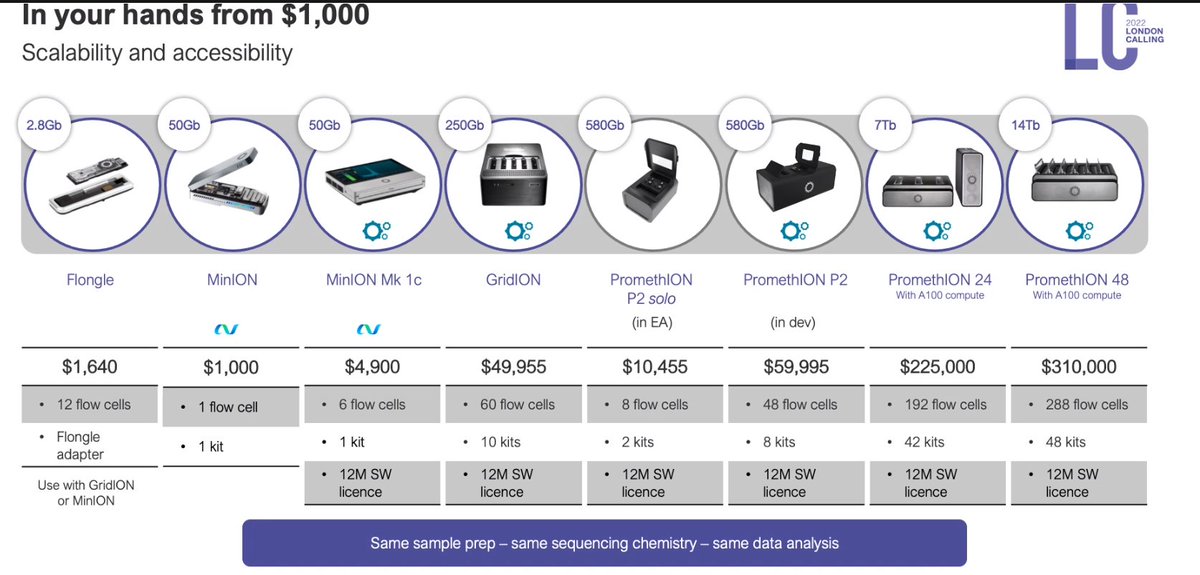
and key openness to key features to enhance the inventiveness of the users. Open and competitive pricing.
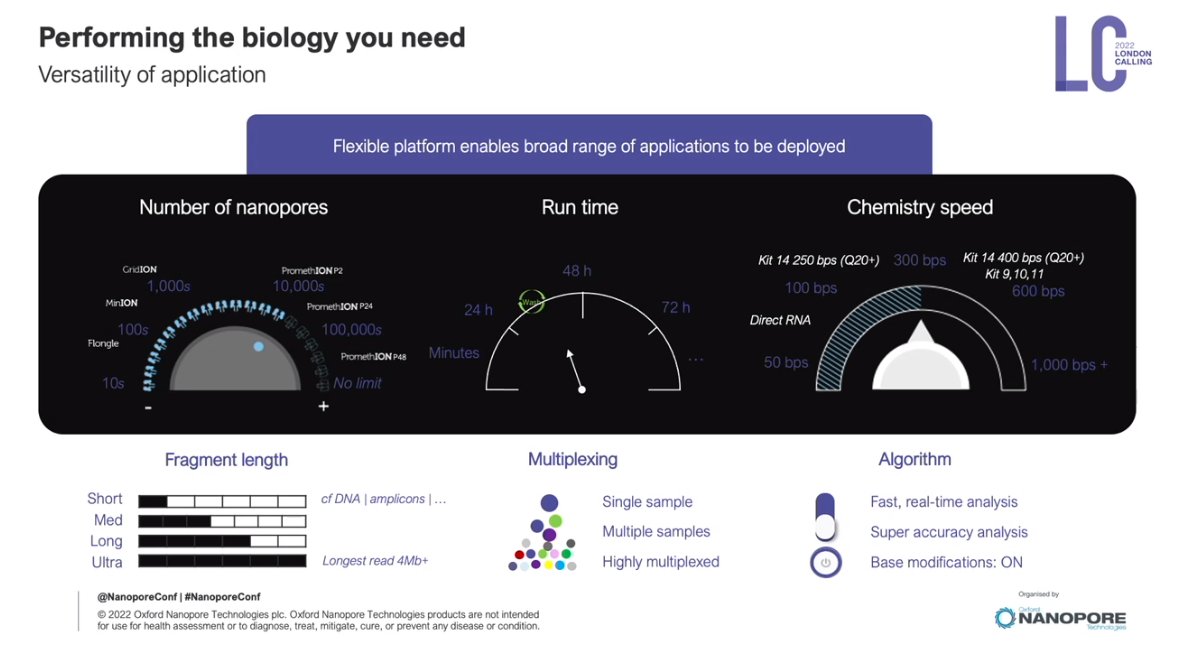

Most platform updates are *not* instrument updates, which means the user can amortize the CAPEX easily. OPEX options as well.

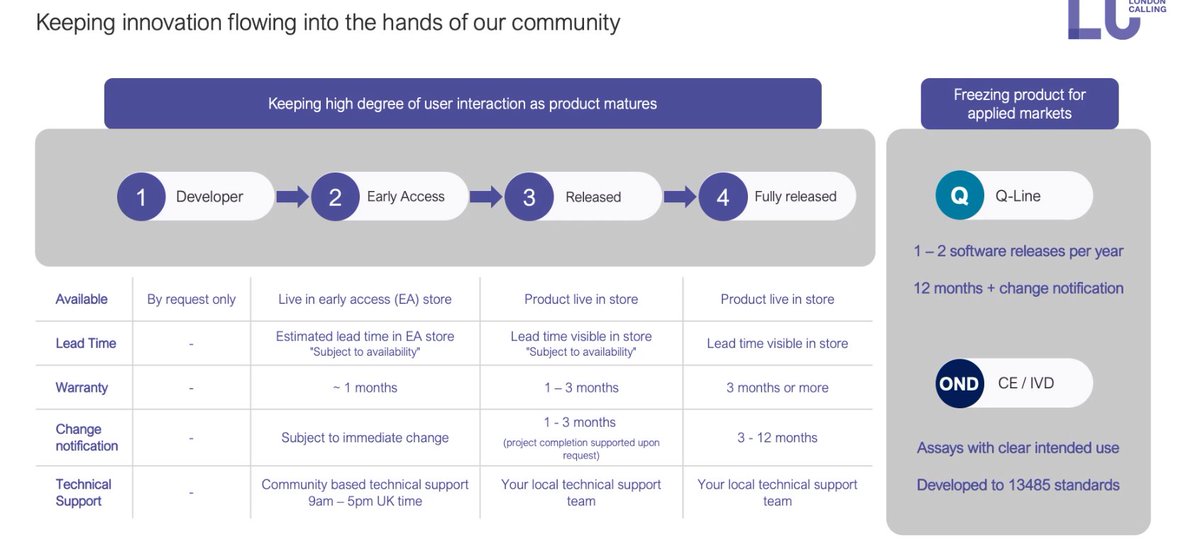
Release phases, ending in Q-Line and now working on CE/IVD products
Sample prep: more for every task, but also "Extraction central" to share/discuss. Including fragment length tuning sample prep methods.

Single cell methods and also software to analyse the results. Key area in my opinion. Direct RNA also improved (input amount, cleanups).

Key example is COVID19, deployed in more than 100 countries. Best example one can think of the ease of deployment feature of Oxford @nanopore "sequence everywhere" mantra.

Kit 14 ligation native barcoding at 24x and 96x, now working on 384-plex. Cas9 following shortly. Rapid as well.

RAD chemistry will go into lower inputs and Q20+ in Q3.

Slide showing the wave of Kit14 over the whole prep portfolio. Formal release aiming at Q4 2022.

The Kit14 is improving the numbers all over.

PromethION now starts at $10-11K with the P2. Potential customers running out of excuses here.

Yes but what about sequencing factories? Also happening. This is the cash cow of $ILMN Illumina currently, being threatened from multiple angles.

Biggest EPI2ME annoucement, for me, is the Nextflow integration. Great news in my opinion.
Clive is back for "one more thing"...
Actually a litany of R&D projects, all very cool, I would highlight the toothbrush continuous epigenomic profiling idea. I called this the expresso machine equivalent in the past.
Protein sequencing: this goes to the heart of offerings by companies like $QSI Quantum-SI and Erysion. Taking a go at it here: 20 aminoacid alphabet but also post-translational modifications (PTMs).


Amino calling equivalent to the basecalling in nucleobases. Combinatorics in proteins are enormous. In some ways the bar is lower than DNA sequencing, in some ways is higher.

Very reproducible profiles: looking at slight shifts in the squiggle, but the information is there.

This is far from a final product, but this approach aims at shotgun #proteomics
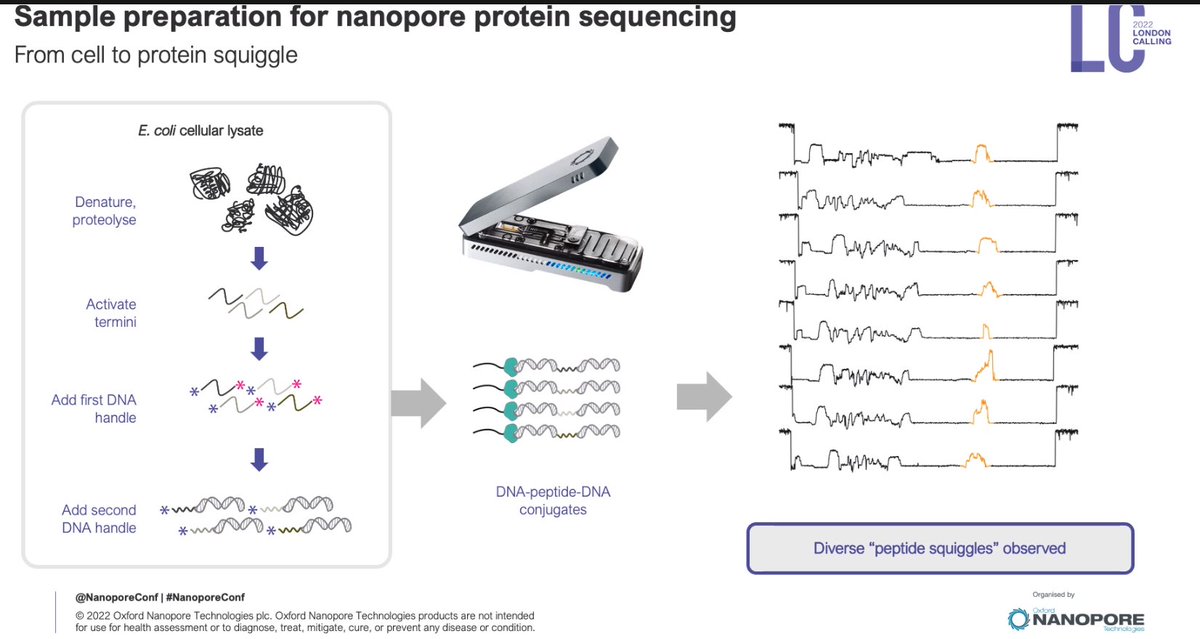
Democratizing proteomics for any biologist out there. Complex proteomics for all. That's the target, significant proof of concept done, still a way to go right now.
Re-reading capabilities, which are very important in proteomics where, same as RNA-seq, the distribution can be very loaded: lots of copies of boring proteins, and needle in a haystack problem for interesting ones.
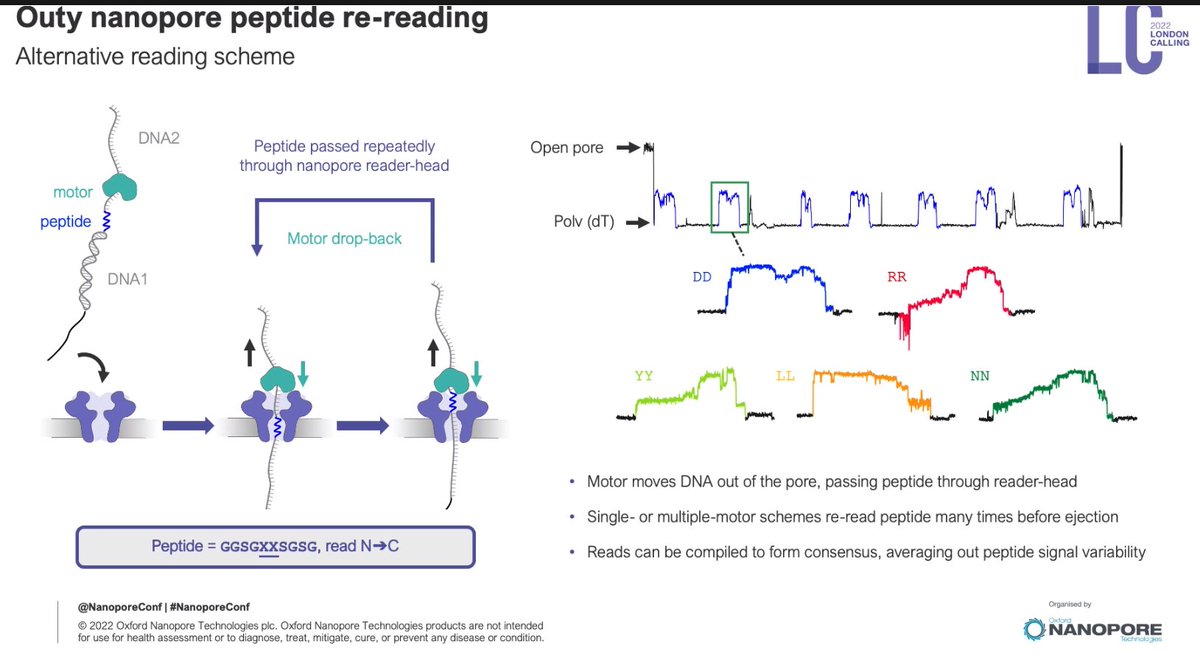
There you are! Q&A now. From my part, I'll ask you to please individually 'like' the tweets in this thread that you want to highlight. What's your best bits from this update?
• • •
Missing some Tweet in this thread? You can try to
force a refresh