
Have you seen #dalle2 and #Imagen and wondered how it works?
Both models utilize diffusion models, a new class of generative models that have overtaken GANs in terms of visual quality.
Here are 10 resources to help you learn about diffusion models ⬇ ⬇ ⬇
Both models utilize diffusion models, a new class of generative models that have overtaken GANs in terms of visual quality.
Here are 10 resources to help you learn about diffusion models ⬇ ⬇ ⬇

1. "What are Diffusion Models?" by @ari_seff
Link →
This 3blue1brown-esque YouTube video is a great introduction to diffusion models!
Link →
This 3blue1brown-esque YouTube video is a great introduction to diffusion models!

2. "Introduction to Diffusion Models for Machine Learning" by @r_o_connor
Link → assemblyai.com/blog/diffusion…
This article provides a great deep-dive of the theoretical foundations for Diffusion Models.
Link → assemblyai.com/blog/diffusion…
This article provides a great deep-dive of the theoretical foundations for Diffusion Models.

3. "What are Diffusion Models?" by @lilianweng
Link → lilianweng.github.io/posts/2021-07-…
Admittedly much more mathematically dense and a little harder to approach but still an awesome resource!
Link → lilianweng.github.io/posts/2021-07-…
Admittedly much more mathematically dense and a little harder to approach but still an awesome resource!
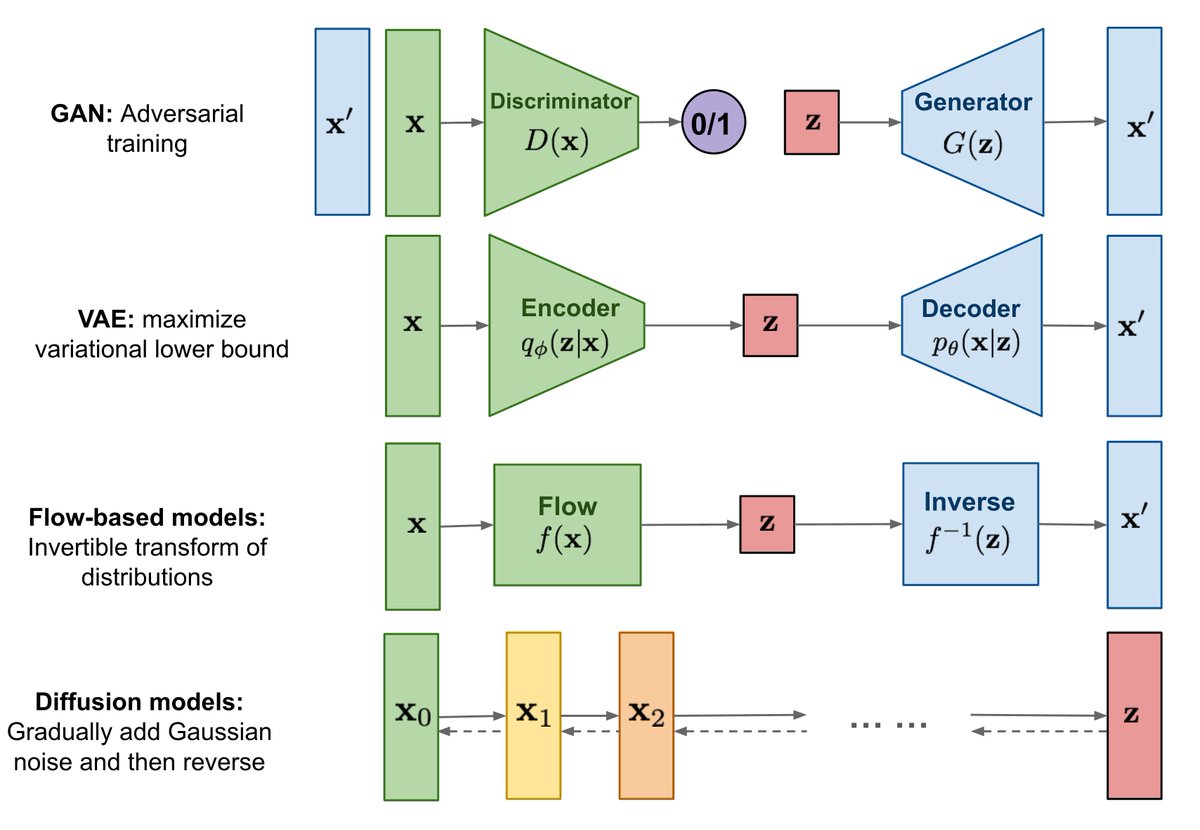
4. "Generative Modeling by Estimating Gradients of the Data Distribution" by @YSongStanford
Link → yang-song.github.io/blog/2021/scor…
This *awesome* blog post (+Colab notebook) is a tutorial about the general class of score-based generative models, which includes diffusion models.
Link → yang-song.github.io/blog/2021/scor…
This *awesome* blog post (+Colab notebook) is a tutorial about the general class of score-based generative models, which includes diffusion models.

5. "An introduction to Diffusion Probabilistic Models" by @dasayan05
Link → ayandas.me/blog-tut/2021/…
This is another great blog post reviewing diffusion models and related score-based generative models.
Link → ayandas.me/blog-tut/2021/…
This is another great blog post reviewing diffusion models and related score-based generative models.

6. "Diffusion Models as a kind of VAE" by @AngusTurner9
Link → angusturner.github.io/generative_mod…
Diffusion models have connections to multiple types of generative models. The previous resources talk about the score-based model connection, this one connects diffusion models to VAEs.
Link → angusturner.github.io/generative_mod…
Diffusion models have connections to multiple types of generative models. The previous resources talk about the score-based model connection, this one connects diffusion models to VAEs.

7. "Diffusion models are autoencoders" by @sedielem
Link → benanne.github.io/2022/01/31/dif…
This blog post provides a great review of diffusion models while also detailing the connection between diffusion models and *denoising* autoencoders.
Link → benanne.github.io/2022/01/31/dif…
This blog post provides a great review of diffusion models while also detailing the connection between diffusion models and *denoising* autoencoders.

8. "The new contender to GANs: score matching with Langevin Sampling" by @jm_alexia
Link → ajolicoeur.wordpress.com/the-new-conten…
Back in 2020, Alexia was already excited about diffusion models and provided us with a great blog post on the topic.
Link → ajolicoeur.wordpress.com/the-new-conten…
Back in 2020, Alexia was already excited about diffusion models and provided us with a great blog post on the topic.

9. "Diffusion-based Deep Generative Models" by @jmtomczak
Link → jmtomczak.github.io/blog/10/10_ddg…
As part of his amazing "Introduction to deep generative modeling" blog series, Dr. Jakub Tomczak provides a great intro and code examples of diffusion models.
Link → jmtomczak.github.io/blog/10/10_ddg…
As part of his amazing "Introduction to deep generative modeling" blog series, Dr. Jakub Tomczak provides a great intro and code examples of diffusion models.

10. "Denoising Diffusion Probabilistic Models" by @hojonathanho et al.
Link → arxiv.org/abs/2006.11239
After going through the introductory resources shared here, reading the original papers will be quite informative too!
The DDPM paper was the breakout diffusion model paper.
Link → arxiv.org/abs/2006.11239
After going through the introductory resources shared here, reading the original papers will be quite informative too!
The DDPM paper was the breakout diffusion model paper.

I have tried to include a diversity of resources that provide different perspectives on diffusion models. Hopefully it provides you different ways about thinking and learning about the topic!
If you like this thread, please share! 🙏
I am also working on my own blog post about diffusion models 👀
Follow me to stay tuned!🙂 → @iScienceLuvr
I am also working on my own blog post about diffusion models 👀
Follow me to stay tuned!🙂 → @iScienceLuvr
• • •
Missing some Tweet in this thread? You can try to
force a refresh











