Check out our #CVPR2022 paper! We improve multimodal zero-shot text-to-video retrieval on Youcook2/MSR-VTT by leveraging fusion transformer and combinatorial loss. 1/🧵
#ComputerVision #AI #MachineLearning
@MITIBMLab @goetheuni @MIT_CSAIL @IBMResearch
#ComputerVision #AI #MachineLearning
@MITIBMLab @goetheuni @MIT_CSAIL @IBMResearch

If you want to go directly to the paper/code, please check out:
paper: arxiv.org/abs/2112.04446
Github link: github.com/ninatu/everyth…
Great work by @ninashv__ , @Brian271828, @arouditchenko Samuel Thomas, Brian Kingsbury, @RogerioFeris , David Harwath, and James Glass.
paper: arxiv.org/abs/2112.04446
Github link: github.com/ninatu/everyth…
Great work by @ninashv__ , @Brian271828, @arouditchenko Samuel Thomas, Brian Kingsbury, @RogerioFeris , David Harwath, and James Glass.
We propose a multimodal modality agnostic fusion transformer that learns to exchange information between multiple modalities, e.g. video, audio, text, and builds an embedding that aggregates multi-modal information.
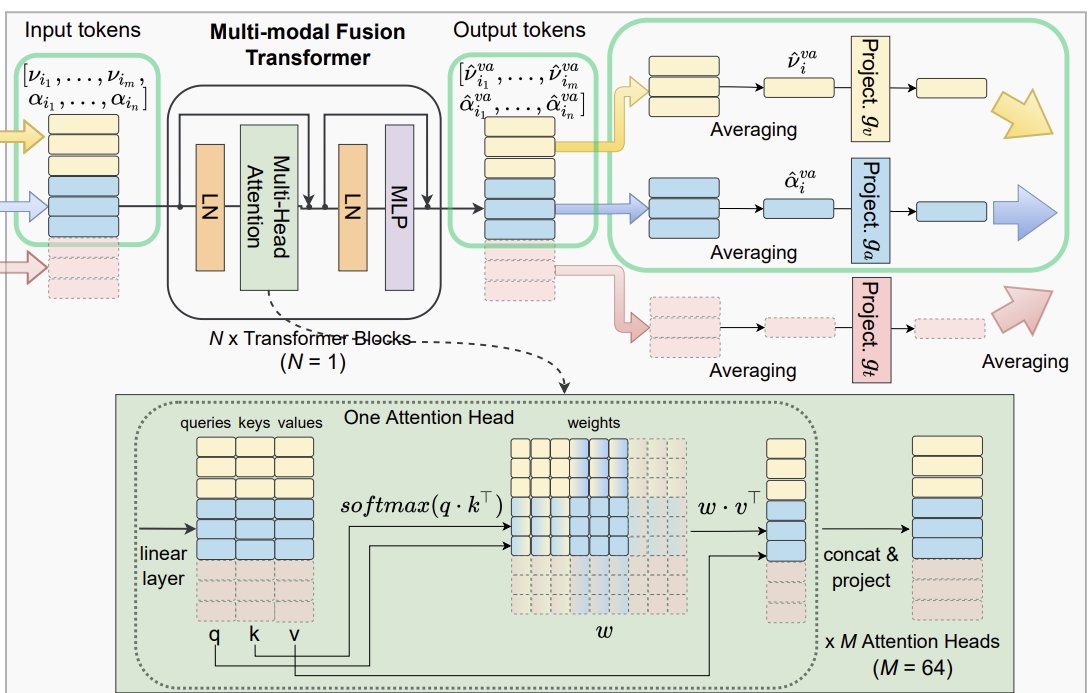
We train the system with a combinatorial loss on everything at once, single modalities as well as pairs.
At test time, the model can process and fuse any input modalities and inputs of different lengths, gets SotA results, and allows attention analysis of modalities.
At test time, the model can process and fuse any input modalities and inputs of different lengths, gets SotA results, and allows attention analysis of modalities.

If you want to know more, join us at #CVPR2022 and the Sight and Sound workshop sightsound.org or the Fri 2pm session in person!
@andrewhowens
@andrewhowens
• • •
Missing some Tweet in this thread? You can try to
force a refresh