Happy to finally share our paper about differentiable Top-K Learning by Sorting that didn’t make it to #CVPR2022, but was accepted for #ICML2022! We show that you can improve classification by actually considering top-1 + runner-ups… 1/6🧵
#ComputerVision #AI #MachineLearning
#ComputerVision #AI #MachineLearning
Paper: arxiv.org/abs/2206.07290
Great work by @FHKPetersen in collaboration with Christian Borgelt, @OliverDeussen . 2/6🧵
@MITIBMLab @goetheuni @UniKonstanz
Great work by @FHKPetersen in collaboration with Christian Borgelt, @OliverDeussen . 2/6🧵
@MITIBMLab @goetheuni @UniKonstanz
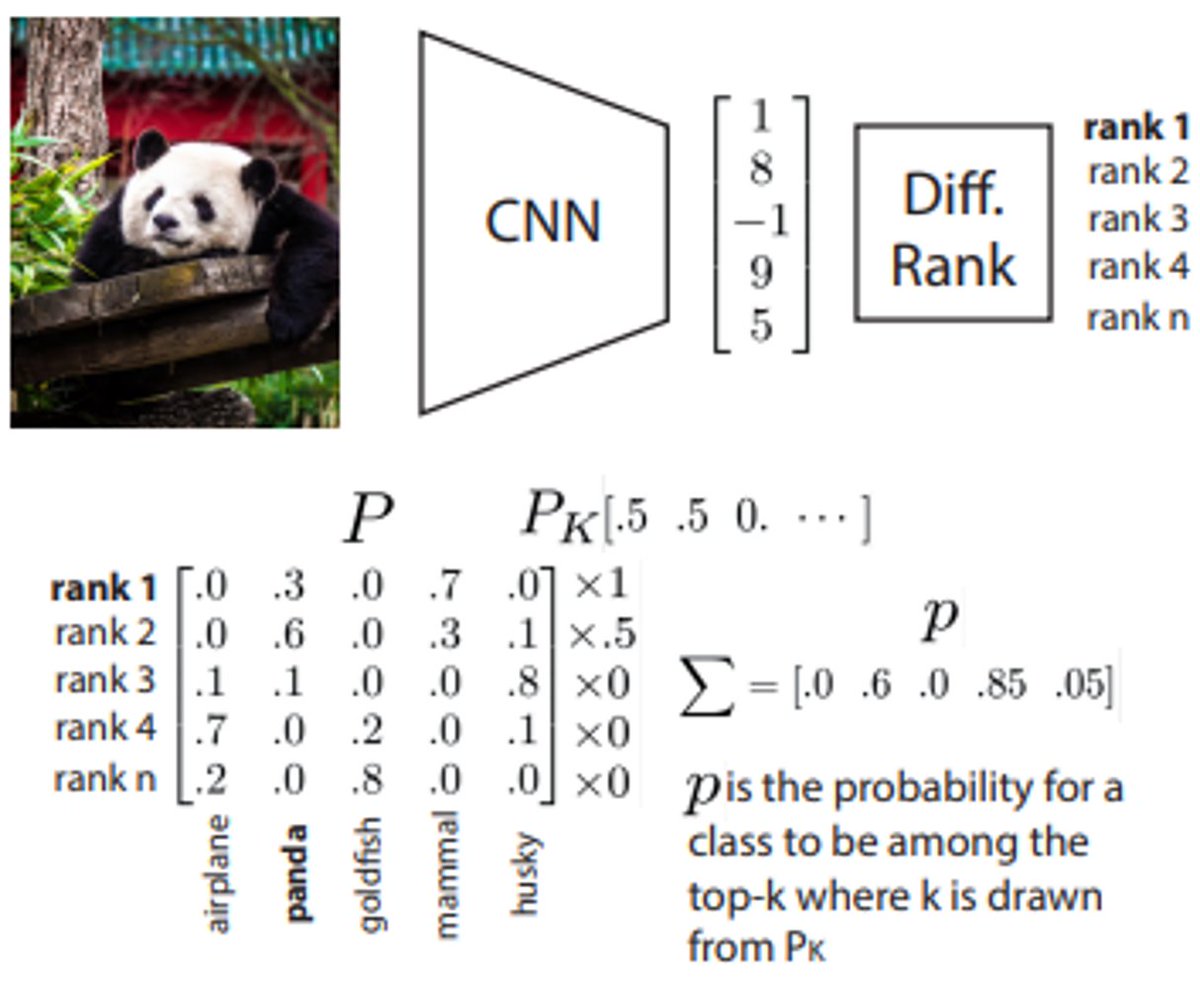
Idea: Top-k class accuracy is used in many ML tasks, but training is usually limited to top-1 accuracy (or another k). We propose a differentiable top-k classification loss that allows training by considering any combination of top-k predictions, e.g. top-2 top-5, 3/6🧵
To this end, we leverage recent advances in differentiable sorting and ranking. We capture the probability for a class to be among the top-k given, e.g. an image. 4/6🧵

This works with any differentiable sorting framework:
NeuralSort: arxiv.org/abs/1903.08850
SoftSort: arxiv.org/abs/2006.16038
SinkhornSort: arxiv.org/abs/1905.11885
DiffSortNets: arxiv.org/abs/2203.09630 arxiv.org/abs/2105.04019
5/6🧵
@CuturiMarco @adityagrover_ @SebastianPrillo
NeuralSort: arxiv.org/abs/1903.08850
SoftSort: arxiv.org/abs/2006.16038
SinkhornSort: arxiv.org/abs/1905.11885
DiffSortNets: arxiv.org/abs/2203.09630 arxiv.org/abs/2105.04019
5/6🧵
@CuturiMarco @adityagrover_ @SebastianPrillo
We evaluate the top-k loss on state-of-the-art architectures. We find that relaxing k does not only produce better top-5 accuracies but also leads to top-1 accuracy improvements and can achieve new state-of-the-art by fine-tuning on publicly available ImageNet models. 6/6🧵

Hope you enjoy the paper! Feel free to leave comments or contact us if you have questions. Code will be available soon!
• • •
Missing some Tweet in this thread? You can try to
force a refresh