
#zkEVM has been the holy grail of layer2 and Ethereum scaling and is at the forefront of the blockchain && ethereum
There's a lot of zkp and engineering innovation here, bringing together all the most talented people in the Ethereum ecosystem
There's a lot of zkp and engineering innovation here, bringing together all the most talented people in the Ethereum ecosystem
This is a very interesting and well-worth research topic, in this thread I will dive into zkEVM and explain the native zkEVM architecture of EF and @Scroll_ZKP
1/4 Three levels of zkEVM
1) First of all not all zkVM is equivalent to zkEVM, even for zkEVM itself it is divided into three levels (thanks to @drakefjustin for the research)
1) First of all not all zkVM is equivalent to zkEVM, even for zkEVM itself it is divided into three levels (thanks to @drakefjustin for the research)

2) The first level is "language-level" (EVM-compatible), that is, transpile an EVM-friendly language (e.g. Solidity or Yul) into a zk-friendly language (e.g. @zksync' Zinc, and @StarkWareLtd's Cairo)
And then translate The later Zinc and Cairo code runs on their own VM, which may be completely different from Ethereum's EVM

The advantage of this solution is that we can design a zk-friendly VM from scratch without being limited by the past design of the EVM
@gavofyork never thought that zk-snark would be used in EVM one day, so if the zero-knowledge circuit is directly applied in many places of EVM, it will cause a huge overhead
Especially Keccak hash and MPT. For details, refer to @yezhang1998's article
hackmd.io/@yezhang/S1_KM…
Especially Keccak hash and MPT. For details, refer to @yezhang1998's article
hackmd.io/@yezhang/S1_KM…
The disadvantage is that it is difficult for developers to get the best development experience. These zkVMs use the instruction set of their own language at the bottom and do not support many important EVM opcodes
Therefore, if developers want to get the best development experience, they may need to learn these zkVM own languages (Cairo), which may cause zk-Rollup to be unable to directly inherit the Layer1 ecology, and Layer2 developers and languages are separated
3) The second level is "bytecode-level" (EVM-equivalent), which can not only achieve compatibility at the solidity language level but also achieve full compatibility at the EVM opcode level
Only when it reaches the bytecode level can it be called "zkEVM". On this zkEVM, solidity developers can get the best development experience, and L1 applications and development tools can basically be migrated to L2 without modification
The current stage of @Scroll_ZKP and EF’s native zkEVM (including the efforts of @ConsenSys and @0xPolygonHermez), both target bytecode-level zkEVM
4) The third level is "consensus-level", which is also the final zkEVM. It will not only achieve compatibility at the language and bytecode levels but also at the consensus level
After achieving consensus layer compatibility, each miner will generate a proof for each block when generating a block
When all nodes are synchronized, they only need to verify that the proof is valid, and there is no need to recalculate all transactions
When all nodes are synchronized, they only need to verify that the proof is valid, and there is no need to recalculate all transactions
And based on the recursive proof of Halo2, a proof can be used to prove that the history of the entire block is valid
At that time, the synchronization node does not even need to verify each proof, but only needs to verify the last proof to access the network
At that time, the synchronization node does not even need to verify each proof, but only needs to verify the last proof to access the network

In the long run, when it only takes minutes or even seconds to synchronize an Ethereum node, anyone can easily join the Ethereum network, and Ethereum will become more decentralized and robust
I'm really looking forward to seeing it happen
I'm really looking forward to seeing it happen
5) So the ultimate goal of zkEVM is actually to apply it to L1, replacing our current EVM (Very ambitious!)
This is also the ultimate goal of EF(@PrivacyScaling), @Scroll_ZKP, and all of us working together
This is also the ultimate goal of EF(@PrivacyScaling), @Scroll_ZKP, and all of us working together
For details, see the last part of the ethereum roadmap sent by @VitalikButerin - "zk-snark everything"
I believe @VitalikButerin and @barrywhitehat will also explore stack solutions
I believe @VitalikButerin and @barrywhitehat will also explore stack solutions
https://twitter.com/VitalikButerin/status/1466411377107558402?s=20&t=C4tGAMPSYsolSZYyMRas7g
2/4 zero-knowledge proof
1) What makes zkEVM around the corner
There are many cryptographic breakthroughs behind it that can make zkevm from imagination to reality, the most important of which is the Plonk and Halo2
1) What makes zkEVM around the corner
There are many cryptographic breakthroughs behind it that can make zkevm from imagination to reality, the most important of which is the Plonk and Halo2
For details, can see this thread by @Zac_Aztec, and he is also the founder of Plonk and @aztecnetwork
https://twitter.com/Zac_Aztec/status/1440295503938215947?s=20&t=eRMnynNmiB1vaKdhD5IJWw
2) Plonk is an innovation based on Sonic and polynomial commitment
Based on sonic, Plonk has a "universal and updateable" trusted setup, that is, only one setup is required, and then it can be reused
Based on sonic, Plonk has a "universal and updateable" trusted setup, that is, only one setup is required, and then it can be reused
And based on polynomial commitment (very beautiful math), we can use more expressive PLONKish Arithmetization, better than R1CS which is widely used by groth16 and other zk-snark proof schemes
3) zkEVM also uses two very important features of Plonkish, namely "custom gate" and "lookup table argument"
These two features of Plonk (halo2 inherited) allow us to write highly customized constraints, which are very helpful to reduce the overhead of the circuit (you will find that we frequently use these two features in the native zkEVM architecture later)
Thanks to @zeroknowledgefm for accumulating so many zkp resources for anyone to understand the amazing magic and wonderful math behind zkp
3/4 Architecture of native zkevm
1) As we mentioned earlier, the native zkEVM will not only be used in the zk-Rollup but also will replace our current L1 EVM and become the L1 zkEVM
So its design/code and architecture are very worth learning (the most cutting-edge innovation!)
1) As we mentioned earlier, the native zkEVM will not only be used in the zk-Rollup but also will replace our current L1 EVM and become the L1 zkEVM
So its design/code and architecture are very worth learning (the most cutting-edge innovation!)
2) The well-known EVM is essentially a state machine, which drives state1 to state2 through transactions
So it can be understood that the operation that drives the smallest state change is a transaction (actually trace)
So it can be understood that the operation that drives the smallest state change is a transaction (actually trace)

If we can get transactions and constrain/prove them, in fact, it can constrain/prove the entire state machine
3) The basic idea of zkEVM is to create an evm circuit to constrain the EVM (the state machine) and prove that all the execution logic of the EVM is correct
This EVM circuit can get all transactions, and each specific opcode called by this transaction
Then prove that each transaction, as well as all opcodes called by each transaction, the operation logic of opcodes, and even the sequence of operations, are completely correct
Then prove that each transaction, as well as all opcodes called by each transaction, the operation logic of opcodes, and even the sequence of operations, are completely correct
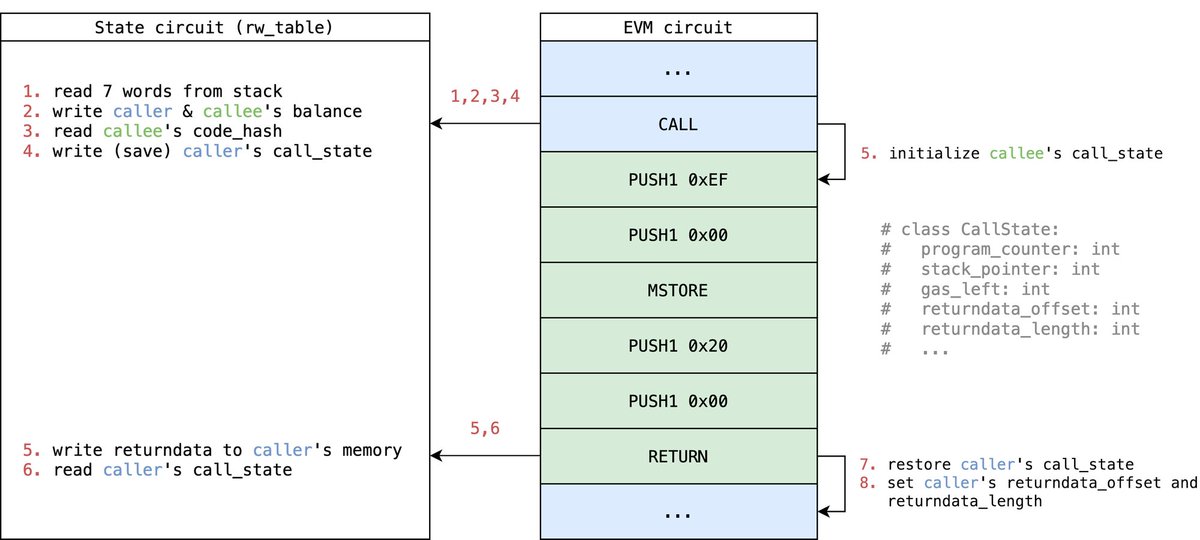

4) But in our practice, we found that if only one circuit (EVM circuit) is used to constrain the EVM, this circuit will become very huge, and finally it will increase unnecessary complexity and overhead
So we designed many different sub-circuits/tables according to different modules in EVM. When proving, we only need to query the corresponding table (a table probably looks like this, fill in different variables according to requirements)

5) For example, if it is the logic of memory/stack/stoarge read & write, the EVM circuit will query the state table
If it is some operation involving opcode, the EVM circuit will query the bytecode table. Similarly, tx and block will query tx table and block table respectively
If it is some operation involving opcode, the EVM circuit will query the bytecode table. Similarly, tx and block will query tx table and block table respectively

Here, the state circuit needs to operate MPT when constraining storage-related operations (state table), so the corresponding MPT table is queried
The Tx circuit also needs to query the corresponding Keccak and Sig table when calculating the hash and transaction sig verification
The Tx circuit also needs to query the corresponding Keccak and Sig table when calculating the hash and transaction sig verification
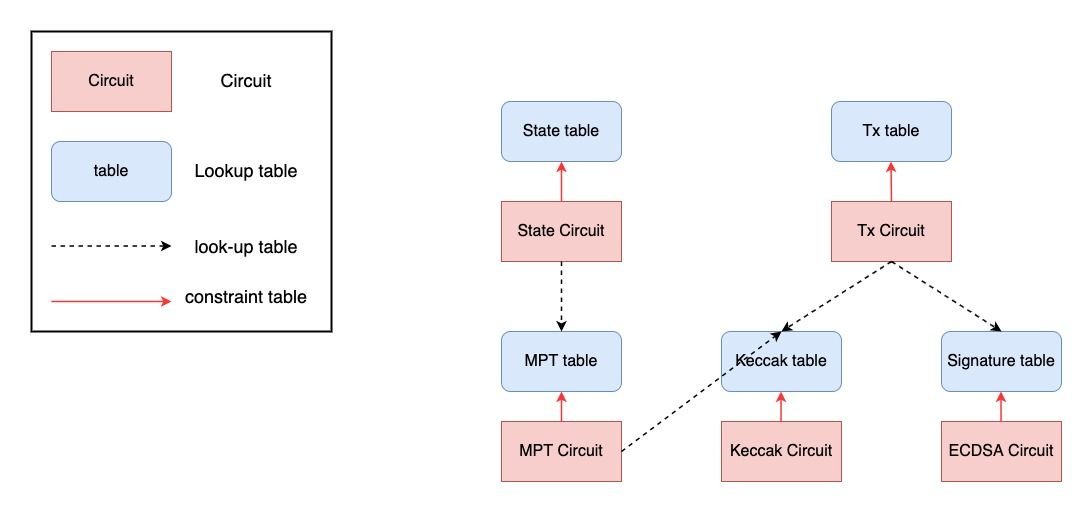
6) This table is not fixed, but filled in with different values according to different operations (this is one of the reasons why zkEVM can become universal)
So prover has the ability to fill in false values to forge an invalid table
So prover has the ability to fill in false values to forge an invalid table
Therefore, in order to ensure the correctness of the table, we design a circuit for each table, and each circuit has some special polynomial constraints on the table to ensure that the table is completely correct

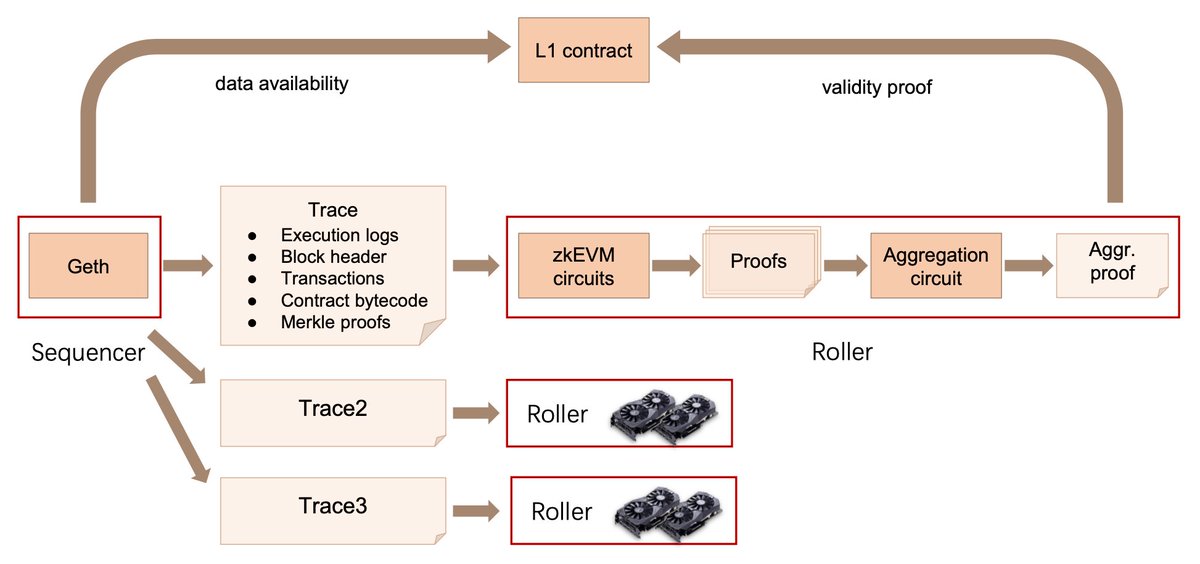
7) When a transaction/trace enters the EVM circuit, all operations (opcode, stack/storage, etc.) involved in it will be reordered and then assigned to different sub-circuits
These sub-circuits will prove the correctness of these operations and generate a proof
These sub-circuits will prove the correctness of these operations and generate a proof
Finally, the proofs generated by these sub-circuits will be input into an aggregation circuit as public input, and the aggregation circuit will aggregate these single proofs into an aggregate proof

After that, the aggregate proof can be sent to the L1 contract to verify the validity of the proof, which is also the workflow of Scroll at the High-level
4/4 Ending and the beginning
zkEVM is a milestone of "zk everything" and innovation that can only appear after the practical zk-proving systems are mature
zkEVM is a milestone of "zk everything" and innovation that can only appear after the practical zk-proving systems are mature
While researching zkEVM, I was deeply impressed by the mathematical mechanism behind it, I believe zk is a huge innovation and we are at the forefront of this innovation
• • •
Missing some Tweet in this thread? You can try to
force a refresh




