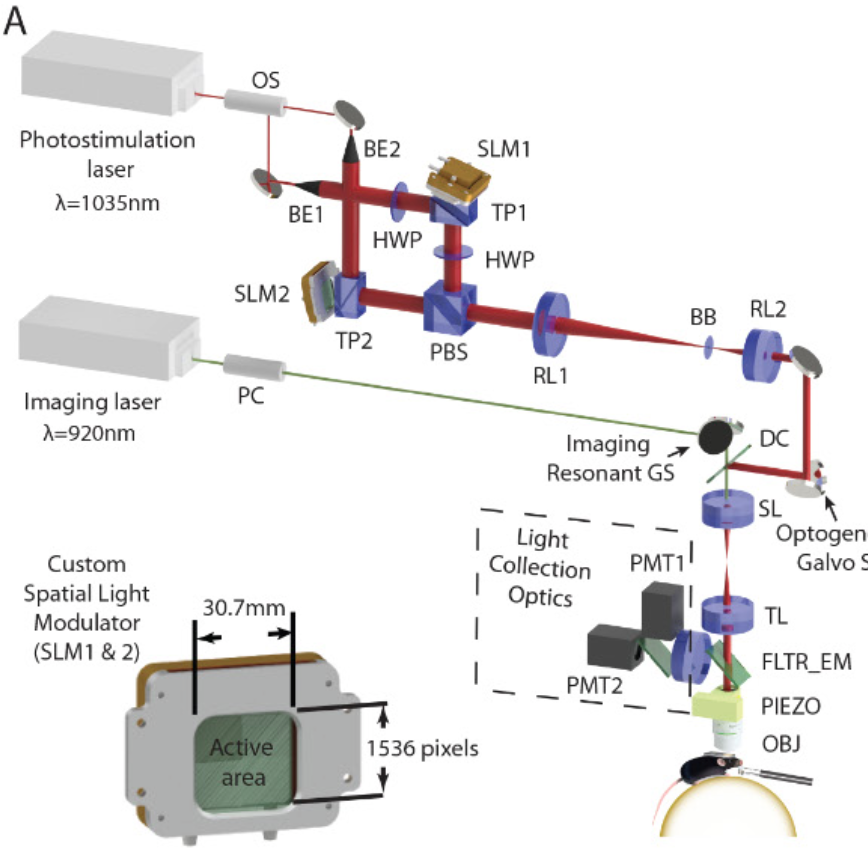
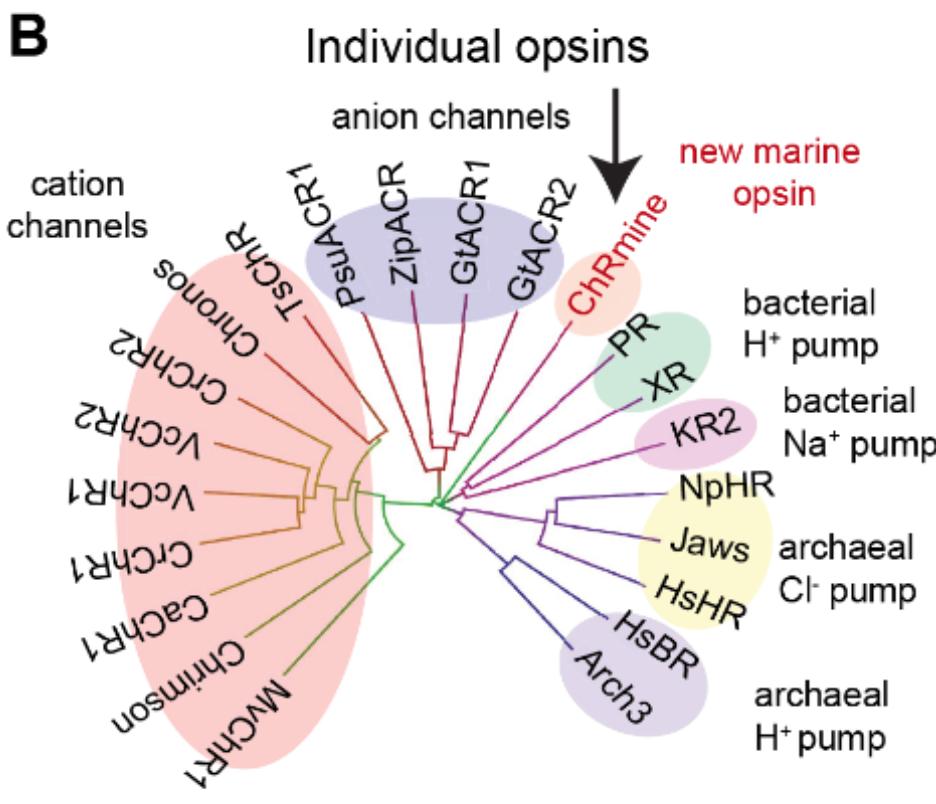
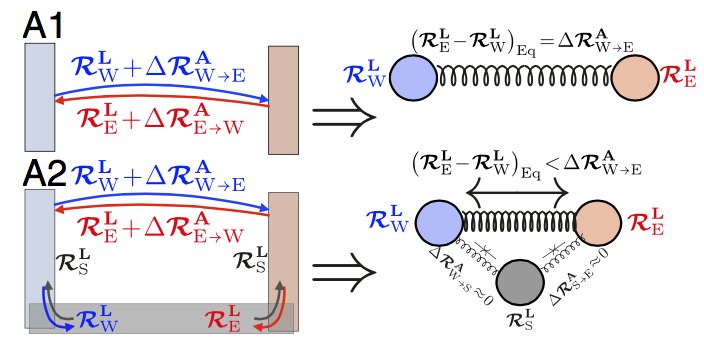
1/ Our new preprint biorxiv.org/content/10.110… on when grid cells appear in trained path integrators w/ Sorscher @meldefon @aran_nayebi @lisa_giocomo @dyamins critically assesses claims made in a #NeurIPS2022 paper described below. Several corrections in our thread ->
https://twitter.com/RylanSchaeffer/status/1587454396257796096
2/ Our prior theory authors.elsevier.com/c/1f~Ze3BtfH1Z… quantitatively explains why few hexagonal grid cells were found in the work; many choices were made which prior theory proved don’t lead to hexagonal grids; when 2 well understood choices are made grids appear robustly ~100% of the time
3/ Also corrections: (1) difference of Gaussian place cells do lead to hexagonal grids; (2) multiple bump place cells at one scale also; (3) hexagonal grids are robust to place cell scale; (4) Gaussian interactions can yield periodic patterns;
4/ (5) difference of Gaussian input patterns to place cells from grid cells are not biological implausible; more details in preprint tinyurl.com/ynpxtkpm and in the replies to specific parts of the thread copied below...
• • •
Missing some Tweet in this thread? You can try to
force a refresh