
Associate Prof of Applied Physics @Stanford, and departments of Computer Science, Electrical Engineering and Neurobiology. Venture Partner @GeneralCatalyst
 Moreover, it explains how creative new diffusion model outputs, far from the training data, are constructed by mixing and matching different local training set image patches at different locations in the new output, yielding a local patch mosaic model of creativity.
Moreover, it explains how creative new diffusion model outputs, far from the training data, are constructed by mixing and matching different local training set image patches at different locations in the new output, yielding a local patch mosaic model of creativity. 
 2/#XAI will become increasingly important in #neuroscience as deep learning allows us to derive highly accurate but complex models of biological circuits.But will we just be replacing something we don't understand-the brain-with something else we don't understand-our model of it?
2/#XAI will become increasingly important in #neuroscience as deep learning allows us to derive highly accurate but complex models of biological circuits.But will we just be replacing something we don't understand-the brain-with something else we don't understand-our model of it? 
 2/ In joint work @MetaAI w/Ben Sorscher, Robert Geirhos, Shashank Shekhar & @arimorcos we show both in theory (via statistical mechanics) and practice how to achieve exponential scaling by only learning on selected data subsets of difficult nonredundant examples(defined properly)
2/ In joint work @MetaAI w/Ben Sorscher, Robert Geirhos, Shashank Shekhar & @arimorcos we show both in theory (via statistical mechanics) and practice how to achieve exponential scaling by only learning on selected data subsets of difficult nonredundant examples(defined properly) 
 2/ Many methods can train to low loss using very few degrees of freedom (DoF). But why? We show that to train to a small loss L using a small number of random DoF, the number of DoF + the Gaussian width of the loss sublevel set projected onto a sphere around initialization...
2/ Many methods can train to low loss using very few degrees of freedom (DoF). But why? We show that to train to a small loss L using a small number of random DoF, the number of DoF + the Gaussian width of the loss sublevel set projected onto a sphere around initialization... 

 2/ See also here for a free version: rdcu.be/b26wp and tweeprint below ->
2/ See also here for a free version: rdcu.be/b26wp and tweeprint below ->
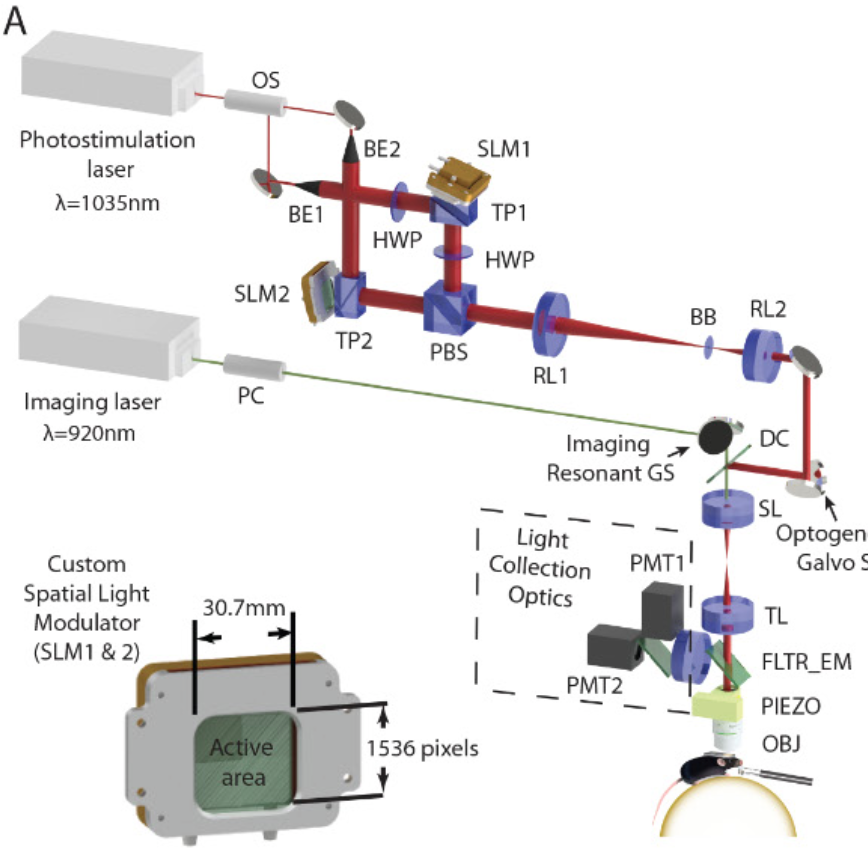
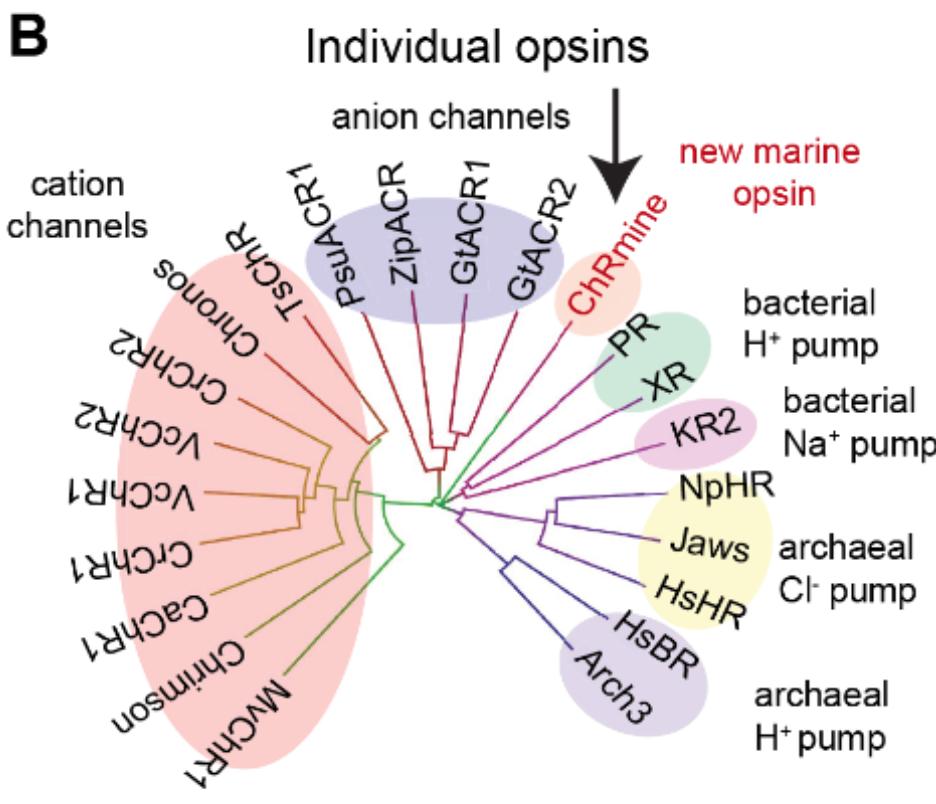 2/ that visual cortex operates in a highly sensitive critically excitable regime in which stimulating a tiny subset of ~20 cells with similar orientation tuning is sufficient to both selectively recruit a large fraction of similarly responding cells and drive a specific percept
2/ that visual cortex operates in a highly sensitive critically excitable regime in which stimulating a tiny subset of ~20 cells with similar orientation tuning is sufficient to both selectively recruit a large fraction of similarly responding cells and drive a specific percept 
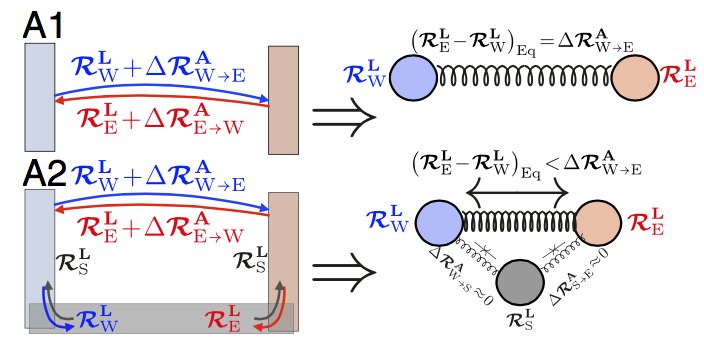 2/ We ask: how do we learn where we are? two info sources are needed: 1) our recent history of velocity; 2) what landmarks we have encountered. How can neurons/synapses fuse these two sources to build a consistent spatial map as we explore a new place we have never seen before?
2/ We ask: how do we learn where we are? two info sources are needed: 1) our recent history of velocity; 2) what landmarks we have encountered. How can neurons/synapses fuse these two sources to build a consistent spatial map as we explore a new place we have never seen before?
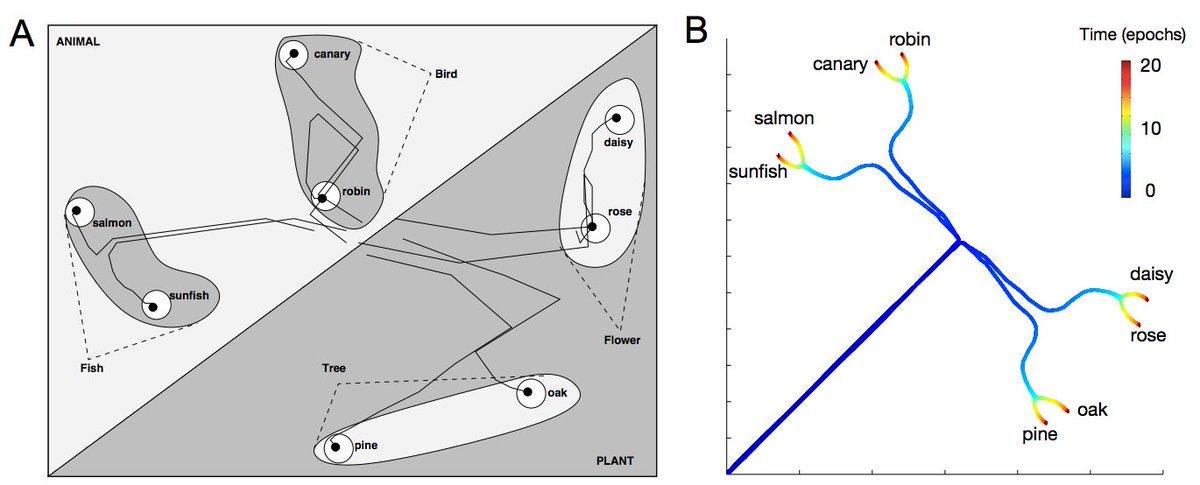 2/ We study how many phenomena in human semantic cognition arise in deep neural networks, and how these phenomena can be understood analytically in a simple deep linear network. Such phenomena include…
2/ We study how many phenomena in human semantic cognition arise in deep neural networks, and how these phenomena can be understood analytically in a simple deep linear network. Such phenomena include…