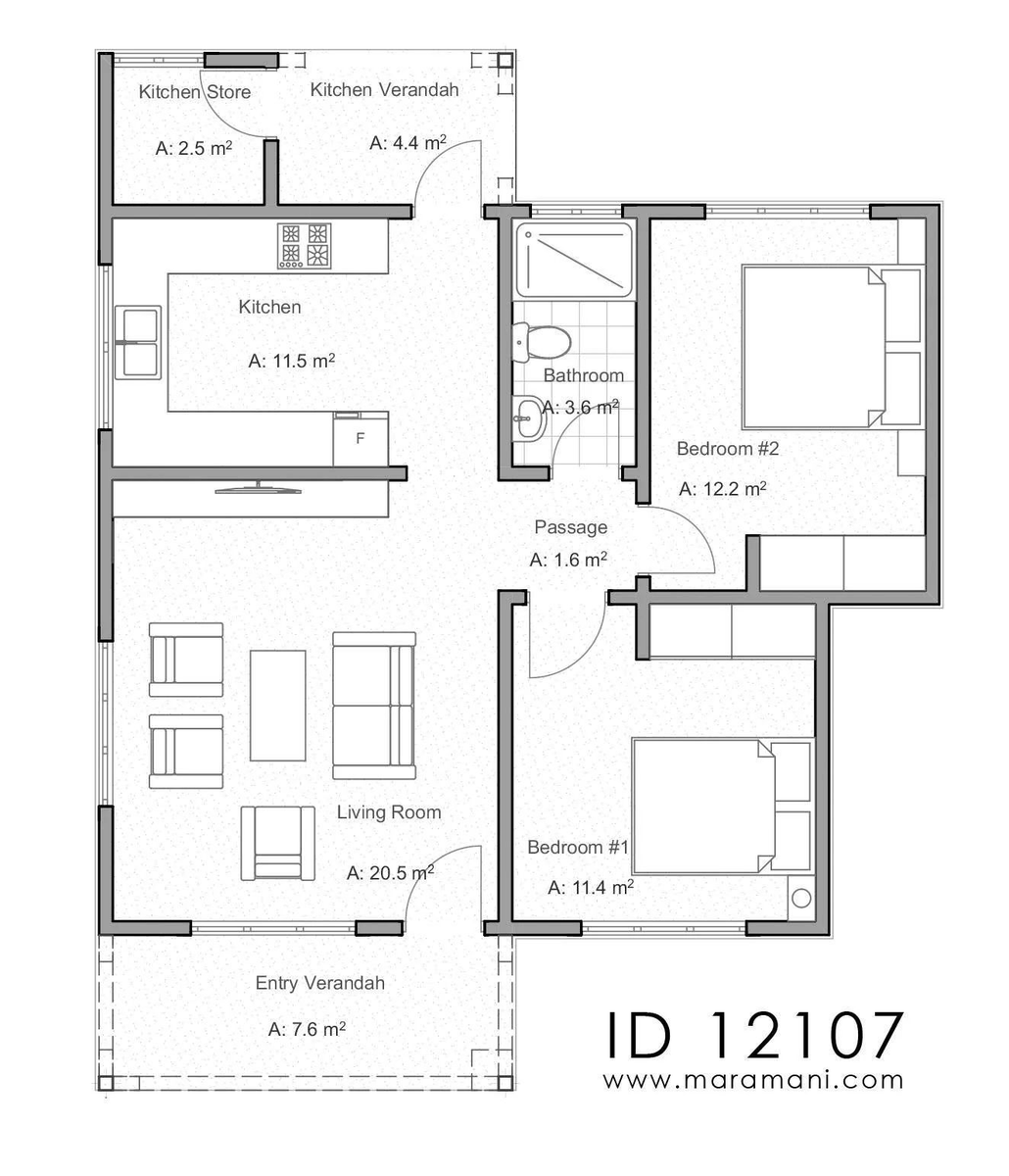
121 little characters with pointy ears. A small village.
All 100% designed with #AI.
Men, women, kids, soldiers, wizards, goblins, etc. All created in less than one hour, while keeping a solid style consistency.
Thread 🧵
#StableDiffusion #Dreambooth #Gaming @Scenario_gg
All 100% designed with #AI.
Men, women, kids, soldiers, wizards, goblins, etc. All created in less than one hour, while keeping a solid style consistency.
Thread 🧵
#StableDiffusion #Dreambooth #Gaming @Scenario_gg


I bought a pack of characters with pointy ears. They made me think of the goblins in Harry Potter (but more human-like)
I trained a finetune using @Scenario_gg (internal alpha) and started prompting (calling them "persons").
At first, you get this, but then the fun begins.👇
I trained a finetune using @Scenario_gg (internal alpha) and started prompting (calling them "persons").
At first, you get this, but then the fun begins.👇


A basic prompt, no modifier ("a person")
All are perfectly consistent (the clothes, the ears, the accessories). There are some variations, though.
All are perfectly consistent (the clothes, the ears, the accessories). There are some variations, though.


For a village, you need males and females, so I did "a female person".
Despite having zero female characters in the initial training data, it generated this:
Despite having zero female characters in the initial training data, it generated this:


Any village has kids, so kids I did. Boys and girls.
With pointy ears like their parents.
With pointy ears like their parents.


The girls look even better.


When a specific character looks interesting, it's worth generating some variants (different poses, accessories, expressions).
I just use img2img on the initial character to get 16, 40 or more.
I just use img2img on the initial character to get 16, 40 or more.


They can dance, too ("a dancing person").


Every village needs protection, so I did some soldiers.


The soldiers could be samurais, too (with pointy ears).
This gets further than the original style, so there are some discrepancies.
This gets further than the original style, so there are some discrepancies.


Same for "the Inca warriors"


Or the African tribesmen (raw output, without background removal)

I usually finish explorations with fun prompts, for example, using "#plasticine" (newly discovered modifiers).
"A plasticine figurine of a person"
They would be amazing, 3D printed.
"A plasticine figurine of a person"
They would be amazing, 3D printed.




That's it!
It's the type of exploration we want people to do, using @Scenario_gg, soon.
If you liked this thread, please feel free to RT the first tweets, like/follow, or just leave your email, so you are notified when we launch🚀 >> scenario.gg
It's the type of exploration we want people to do, using @Scenario_gg, soon.
If you liked this thread, please feel free to RT the first tweets, like/follow, or just leave your email, so you are notified when we launch🚀 >> scenario.gg

• • •
Missing some Tweet in this thread? You can try to
force a refresh