
Last week @OpenAI released ChatGPT - a Large Language AI Model that interacts with users in a natural conversational way. The chatbot is able to answer complex questions, even in highly technically demanding categories.
1/7
1/7
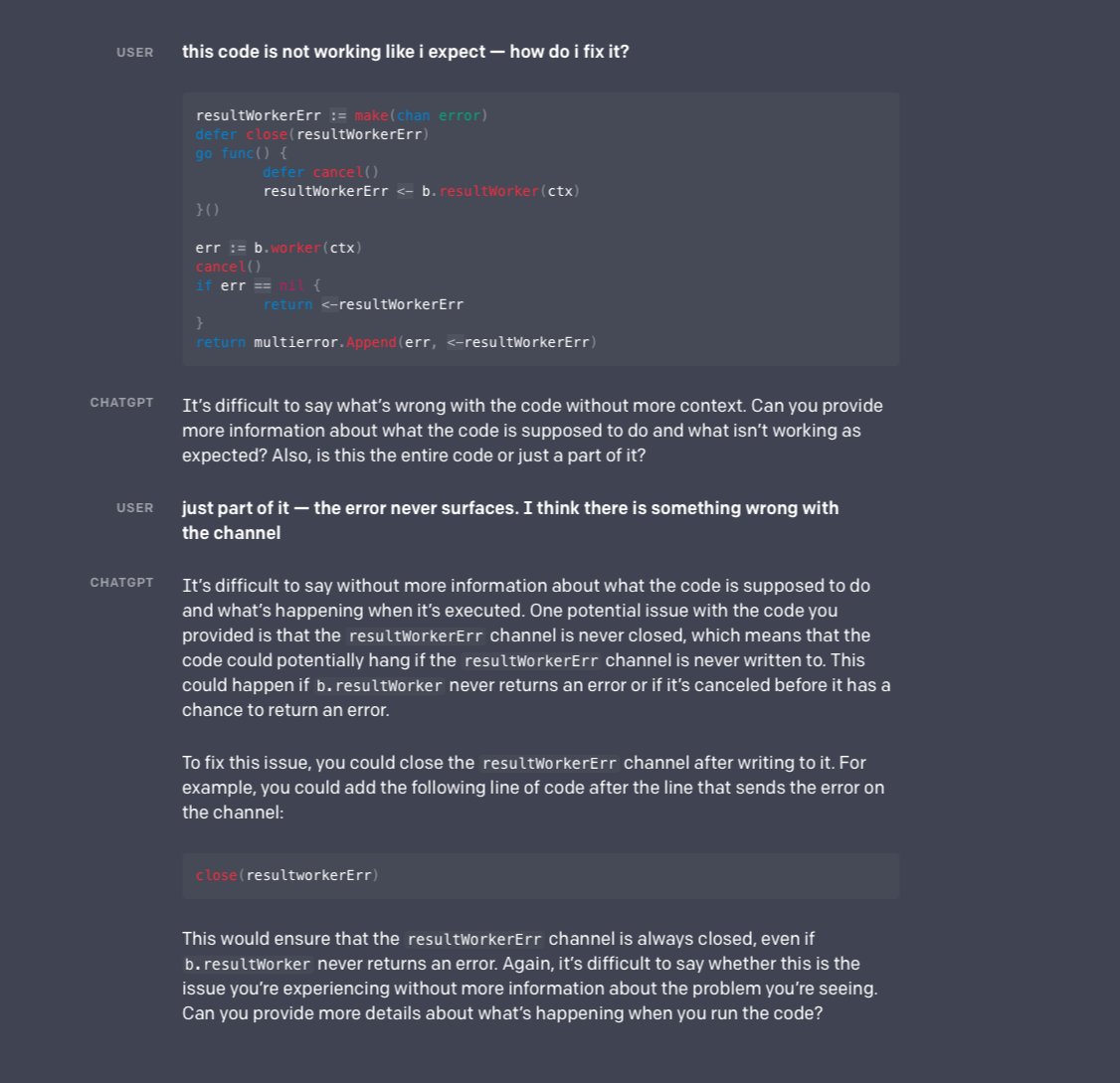
It is also able to answer the follow up question, backtrack on wrong assumptions, and provide other detailed resources, including code fragments.
2/7
2/7
Most people in tech consider this to be the greatest technological advancement of the year. Many of us consider it even more epochal, perhaps one of the biggest turning points in history.
3/7
3/7
These sorts of assessment are not coming from exaggeration-prone hype mongers, but from many very sober technological insiders.
4/7
4/7
ChatGPT still has many weaknesses and blind spots, but it is very clear to anyone with adequate technical background that they are straightforward to tackle. The system will become only more capable and powerful in the months ahead.
5/7
5/7
It will radically transform most information processing professions and industries.
In just five days from its launch ChatbotGPT has registered over a million users.
6/7
In just five days from its launch ChatbotGPT has registered over a million users.
6/7
The service is still free for experimentation, but will likely become part of the OpenAI subscription package at some point.
Link to the story: openai.com/blog/chatgpt/
Link to the service: chat.openai.com
#ArtificialIntelligence #GenerativeAI #ML #DL #AI #NLP #NLU
7/7
Link to the story: openai.com/blog/chatgpt/
Link to the service: chat.openai.com
#ArtificialIntelligence #GenerativeAI #ML #DL #AI #NLP #NLU
7/7
• • •
Missing some Tweet in this thread? You can try to
force a refresh








