1/ #ChatGPT is closing out 2022 with a bang, but what’s next? 💥
@OpenAI’s #GPT4 is set to be the first big #AI thing in 2023.
So here are some bold, optimistic, yet sensible predictions from me, @vivek7ue and @rajhans_samdani ... 👀
@OpenAI’s #GPT4 is set to be the first big #AI thing in 2023.
So here are some bold, optimistic, yet sensible predictions from me, @vivek7ue and @rajhans_samdani ... 👀
2/ Biggest model size for GPT-4 will be 1T parameters. Up 6x.
Not 100T parameters like some AI hypers are claiming (
Not 100T parameters like some AI hypers are claiming (
https://twitter.com/andrewsteinwold/status/1594889562526027777).2/ Biggest model size for GPT-4 will be 1T parameters. Up 6x

3/ The reason is simple: instruction fine tuning achieves same quality with 100x smaller models.
arxiv.org/pdf/2203.02155…
arxiv.org/pdf/2203.02155…
4/ As such, the pre-trained GPT-4 model will appear to be a modest improvement over Chincilla, PALM and U-PALM on HELM and BigBench.
The raw stats on GPT-4 will look underwhelming at first glance and incremental relative to GPT-3.
The raw stats on GPT-4 will look underwhelming at first glance and incremental relative to GPT-3.
5/ The hidden secret of #LLMs? How much training data you have matters as much as model size.
GPT-4 will use 10T tokens. Up 33x, and putting them on the Chinchilla scaling curve.
GPT-4 will use 10T tokens. Up 33x, and putting them on the Chinchilla scaling curve.
6/ Biggest user facing change? Longer context windows.
We expect 16384 tokens (⬆️ from 4096).
We expect 16384 tokens (⬆️ from 4096).
7/ Biggest pre-training modeling change? A loss function that looks like UL2 (arxiv.org/pdf/2205.05131…).
8/ Put together, at least 800x more compute for the pre-trained model.
And that will mean it’s better. 🙌 🙌
And that will mean it’s better. 🙌 🙌
9/ Lots of the pre-training secret sauce will be in what goes in. 🤫
We expect:
➡️ A lot more dialog data (from @Twitter, @Reddit and elsewhere)
➡️ Proprietary signals from @bing's index and maybe even Bing clicks
We expect:
➡️ A lot more dialog data (from @Twitter, @Reddit and elsewhere)
➡️ Proprietary signals from @bing's index and maybe even Bing clicks
10/ The instruction-following models will continue to be state of the art relative to everyone else (see the HELM comparisons at arxiv.org/abs/2211.09110)
11/ They will:
👉 Incorporate RLHF/PPO (like GPT3.5)
👉 Use proprietary prompt-following training data from the OpenAI playground (that other research groups can't access)
👉 Incorporate RLHF/PPO (like GPT3.5)
👉 Use proprietary prompt-following training data from the OpenAI playground (that other research groups can't access)
12/ PPO preference training will re-use some of the tricks @AnthropicAI is using to be more helpful and harmless in their constitutional training paradigm
https://twitter.com/AnthropicAI/status/1603791161419698181
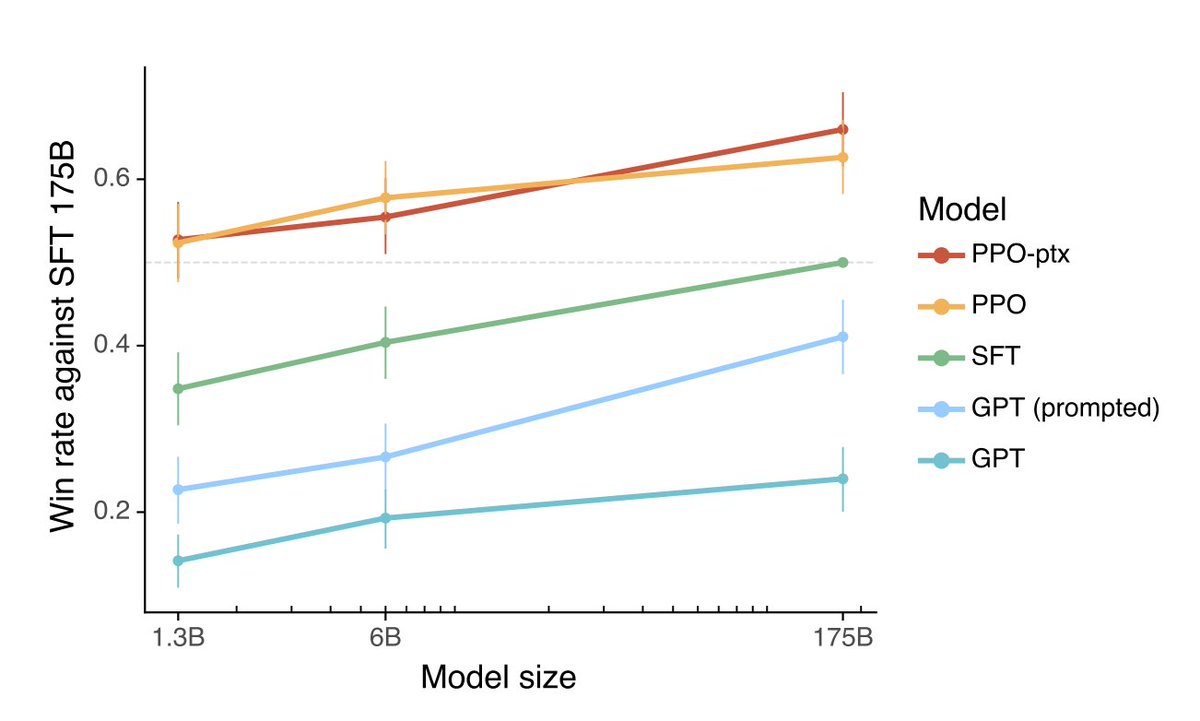
13/ InstructGPT-3 used about 20B tokens during PPO = 6% of total GPT-3 compute.
Since instruction fine tuning is a lot more compute optimal, we expect a lot more compute to be spent in the supervised fine-tuning and PPO phases.
Since instruction fine tuning is a lot more compute optimal, we expect a lot more compute to be spent in the supervised fine-tuning and PPO phases.
14/ GPT-4 will be fine-tuned on all the feedback data from ChatGPT, and that will be the key to a significant improvement.
With a million prompts a day from ChatGPT, we expect compute used in PPO to go up a lot in GPT-4.
With a million prompts a day from ChatGPT, we expect compute used in PPO to go up a lot in GPT-4.
15/ And finally, like with ChatGPT, OpenAI will NOT publish details about GPT4 as a paper, leaving the world guessing what's in there.
This will start a trend where all the big foundation model companies will stop publishing details of their models.
OpenAI will be Open no more.
This will start a trend where all the big foundation model companies will stop publishing details of their models.
OpenAI will be Open no more.
16/ This will leave a BIG opportunity for open model efforts from the likes of @AiEleuther, @huggingface, Big Science’s BLOOM, @togethercompute, and @carperai to step up their game.
• • •
Missing some Tweet in this thread? You can try to
force a refresh