ChatGPT for Robotics?
@Deepmind latest work: A general AI agent that can perform any task from human instructions!
Or at least those allowed in "the playhouse"
The cherry on top of this agent is its RL fine-tuning from human feedback, or RLHF. As in ChatGPT
1/n
@Deepmind latest work: A general AI agent that can perform any task from human instructions!
Or at least those allowed in "the playhouse"
The cherry on top of this agent is its RL fine-tuning from human feedback, or RLHF. As in ChatGPT
1/n

The base layer of the agent is trained with imitation learning and conditioned on language instructions
Initially, the agent had mediocre abilities
However, when it was fine-tuned with Reinforcement Learning and allowed to act independently, its abilities 🆙 significantly
2/n
Initially, the agent had mediocre abilities
However, when it was fine-tuned with Reinforcement Learning and allowed to act independently, its abilities 🆙 significantly
2/n

The authors structured the RL problem by training a Reward Model on human feedback, and then using this RW model to optimize the agent with online RL
The RW model, also called Inter-temporal Bradley-Terry (IBT), is trained to predict the preferences of sub-trajectories
3/n
The RW model, also called Inter-temporal Bradley-Terry (IBT), is trained to predict the preferences of sub-trajectories
3/n
A sub-trajectory is preferred over another of the same episode if it represents a improvement toward the goal. Not preferred if it's a regression.
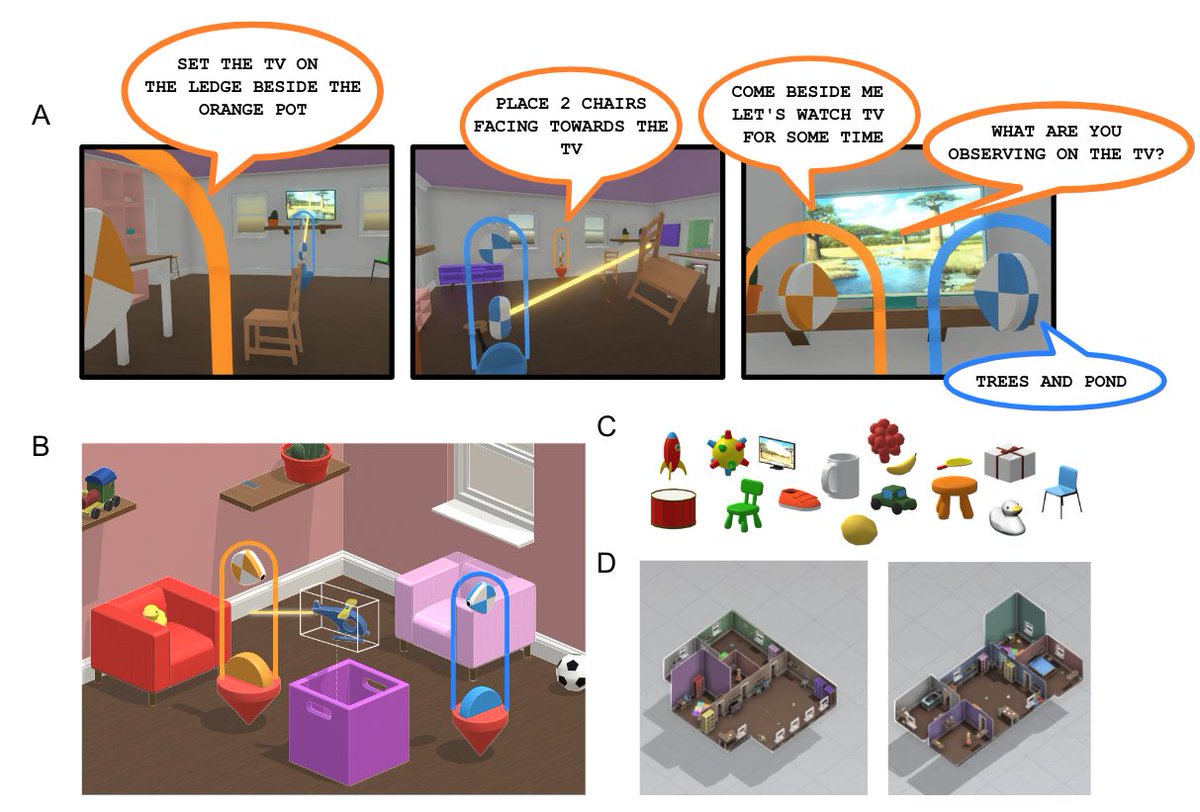
Does it work? Check out this example 📊
It appears to be effective
4/n
Does it work? Check out this example 📊
It appears to be effective
4/n

Btw, they also augmented the loss of the IBT model with BC and contrastive SSL losses.
The BC+RL agent was trained using a "setter-replay" methodology. The environment was recreated based on some initial configs and the agent was left to interact freely & learn.
5/n
The BC+RL agent was trained using a "setter-replay" methodology. The environment was recreated based on some initial configs and the agent was left to interact freely & learn.
5/n

Guess what? BC+RL performed much better than everything else
They evaluated the agent on multiple ways: offline and online, both automatically and manually
In every context the BC+RW model is the best
6/n
They evaluated the agent on multiple ways: offline and online, both automatically and manually
In every context the BC+RW model is the best
6/n

Bonus point 1:
- BC + RL benefit from model scaling - Nice!
Bonus point 2:
- The agent can also be improved iteratively.
And it gets a lot better!
7/n
- BC + RL benefit from model scaling - Nice!
Bonus point 2:
- The agent can also be improved iteratively.
And it gets a lot better!
7/n

Great work by the "Interactive Agents Team" at @deepmind : @arahuja @fede_carne @petko87ig @_agoldin @countzerozzz @TheGeorgePowell @santoroAI and others
Paper: arxiv.org/pdf/2211.11602…
Blog post: deepmind.com/blog/building-…
8/n
Paper: arxiv.org/pdf/2211.11602…
Blog post: deepmind.com/blog/building-…
8/n
I hope you find it useful! Bye
#deeplearning #RL #robotics #ML #AI
#deeplearning #RL #robotics #ML #AI
https://twitter.com/lonzaandrea/status/1608465889053274112?ref_src=twsrc%5Etfw%7Ctwcamp%5Etweetembed%7Ctwterm%5E1608465889053274112%7Ctwgr%5Ed5e948c52ca4f2c15bd3e0e4d056867d8427f246%7Ctwcon%5Es1_c10&ref_url=https%3A%2F%2Fpublish.twitter.com%2F%3Fquery%3Dhttps3A2F2Ftwitter.com2Flonzaandrea2Fstatus2F1608465889053274112widget%3DTweet
• • •
Missing some Tweet in this thread? You can try to
force a refresh