How Often Does Go Preempt Goroutines?
The conventional wisdom says CPU-bound goroutines are preempted every 10ms, but this is wrong. #golang
The conventional wisdom says CPU-bound goroutines are preempted every 10ms, but this is wrong. #golang

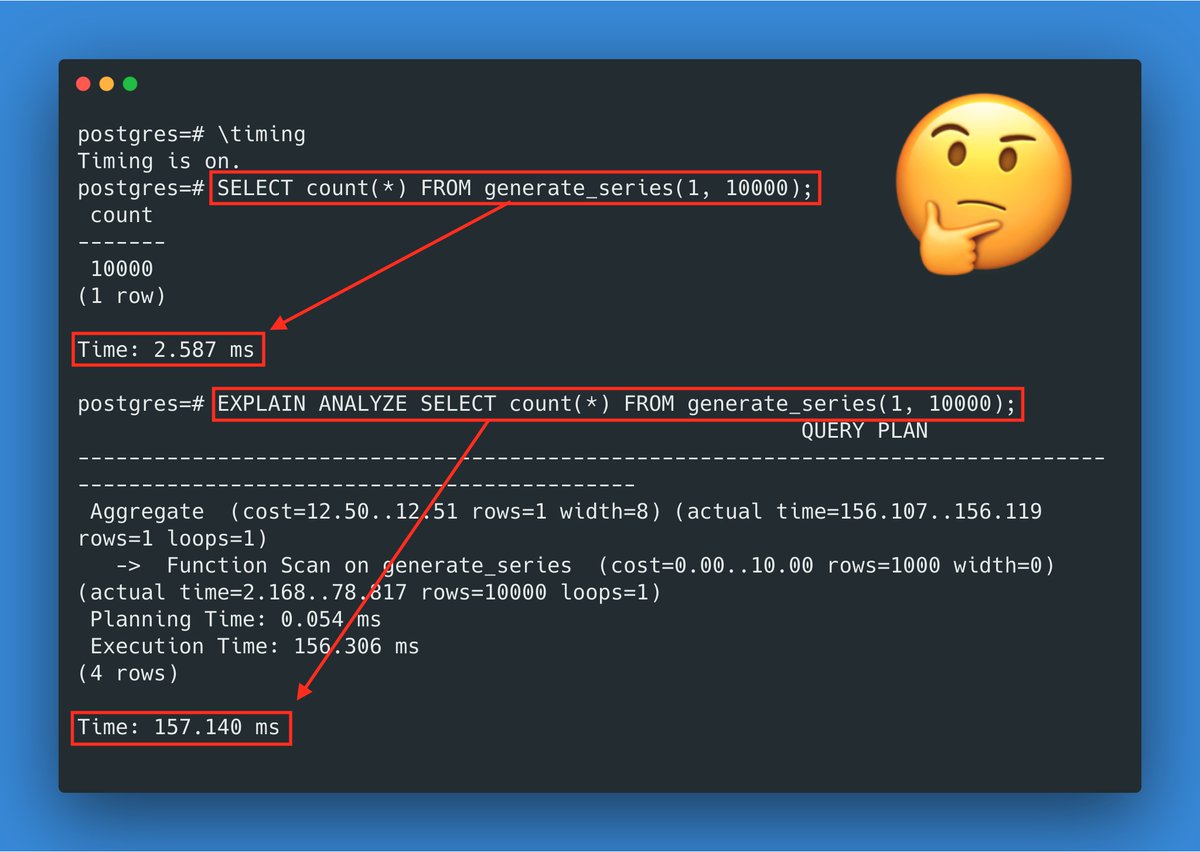
We can check this with a small test program.

Looking at the the runtime/trace of this program, we see that the goroutine is executed 201 times by the scheduler, with an average time of 24.8ms between preemptions.

So what’s going on? At first glance proc.go seems to confirm the conventional 10ms wisdom?
github.com/golang/go/blob…
github.com/golang/go/blob…
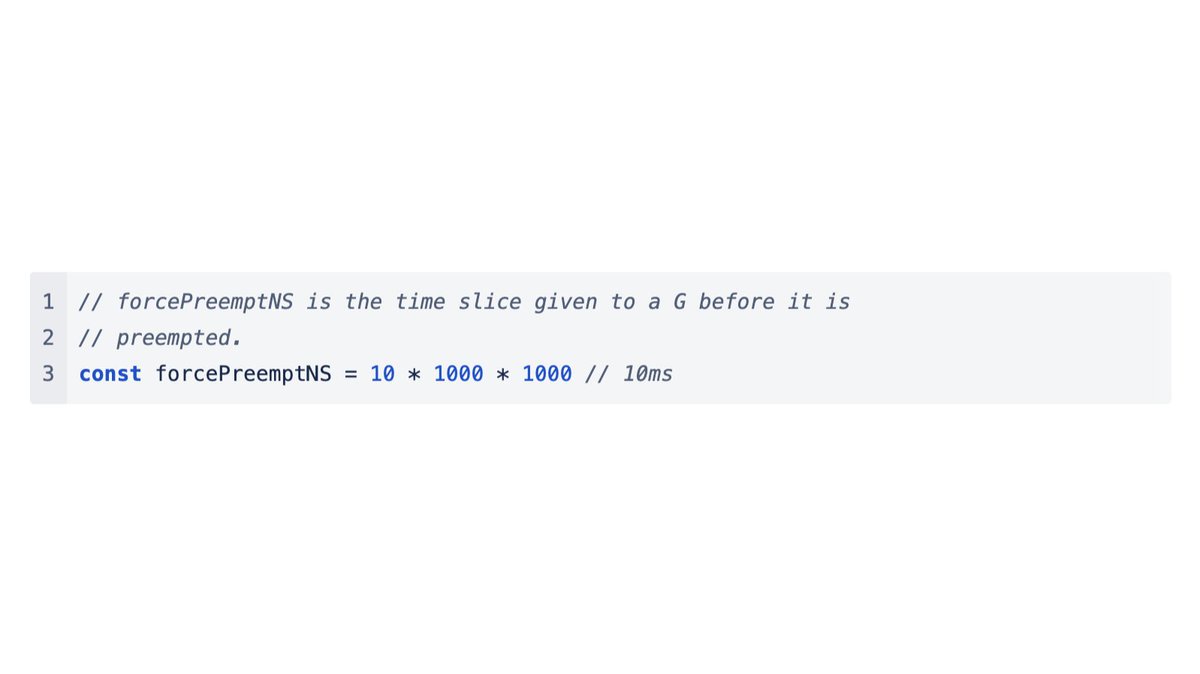
Following this reference leads us inside of the retake() function. As we can see, the first time a goroutine is considered for retaking (preemption), Go just captures the current time in pd.schedwhen.
github.com/golang/go/blob…
github.com/golang/go/blob…

The reason it does this is because it doesn’t know for how long the goroutine has been running at this point. Capturing the start time for every scheduling event would probably be too much overhead.
github.com/golang/go/issu…
github.com/golang/go/issu…
So let’s take a look at sysmon(), the background goroutine that is calling retake. Here we can see that it dynamically adjusts its wakeup frequency from 20usec to 10ms. In our case it’s always 10ms.
github.com/golang/go/blob…
github.com/golang/go/blob…

Given what we’ve seen so far would explain 20ms between preemption events, but in reality we’re observing closer to 25ms. The last piece to he puzzle is usleep() itself.
man7.org/linux/man-page…
man7.org/linux/man-page…
It turns out that on my macOS system, usleep(10*1000) usually sleeps for 12.5ms instead of 10ms to to resolution limitations of the underlaying system timer.

That's it. Thanks for reading. I don’t think the current behavior is problematic. I just went down this rabbit hole while studying runtime/trace today :)
Of course the opening tweet is click bait. 10ms isn't wrong, it's just a minimum duration which will often not be observed depending on sysmon activity and usleep precision.
• • •
Missing some Tweet in this thread? You can try to
force a refresh