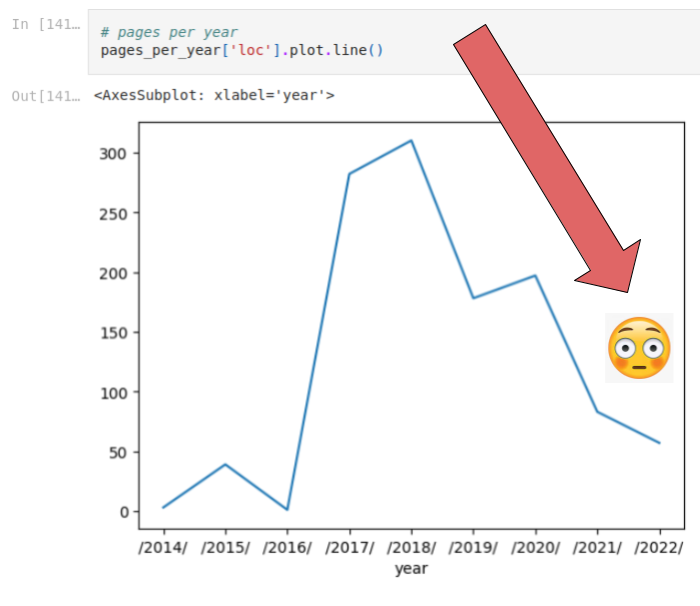
Can you reverse engineer Google?
🎯HUGE LIST OF RANKING FACTORS🎯
▶️▶️▶️Yandex says yes!! 🤯
- Full ENGLISH translations
- All 1922 search factors!
- Full catalog and analysis to surprise #SEOs
((+free 🐍 #python code! 🧵👇))
🎯HUGE LIST OF RANKING FACTORS🎯
▶️▶️▶️Yandex says yes!! 🤯
- Full ENGLISH translations
- All 1922 search factors!
- Full catalog and analysis to surprise #SEOs
((+free 🐍 #python code! 🧵👇))

First I wrote a script to translate descriptions to English and convert it into a tabular CSV format:


Every major organization invests in monitoring their competitors. Yandex is the same.
h/t to @iPullRank for finding the Google parser:
h/t to @iPullRank for finding the Google parser:
Ready for all the ranking factors?? Full 🧵 below:
1) Like + comment and I'll share the full dataset
2) follow me @alton_lex for more analysis
3) grab a copy of the code for translating here github.com/FrontAnalytics…
1) Like + comment and I'll share the full dataset
2) follow me @alton_lex for more analysis
3) grab a copy of the code for translating here github.com/FrontAnalytics…
I'm very interested in ranking factors by category (tag)
CATEGORIES INCLUDE:
1) Doc (basic factors)
2) static content factors (doc)
3) query only factors
4) host factors
5) url text factors
6) dynamic factors
7) user factors
& more 👇
CATEGORIES INCLUDE:
1) Doc (basic factors)
2) static content factors (doc)
3) query only factors
4) host factors
5) url text factors
6) dynamic factors
7) user factors
& more 👇

First, some tags suggest that the factor isn't used.
1273 of the 1922 factors are tagged as
- unimplemented
- depreciated
- unused
So we will remove all these from further analysis:
1273 of the 1922 factors are tagged as
- unimplemented
- depreciated
- unused
So we will remove all these from further analysis:

There are some basic Content factors:
### IsHTML
Document type - HTML
### IsPo***
**** Chick document
### IsFake
fake document
### IsUnreachable
The page is unreachable via links from the muzzle.
## IsHttps
The document has the https protocol
### IsHTML
Document type - HTML
### IsPo***
**** Chick document
### IsFake
fake document
### IsUnreachable
The page is unreachable via links from the muzzle.
## IsHttps
The document has the https protocol
Query only factors:
## LongQuery
The sum of the idf of the query words.
## WordCount
Min(number of query words/10, 1.f)
## InvWordCount
1 / number_words_in_request.
## SyntQuality
Does the query have full parsing
## ExpectedFound
Expected number of searches on the query
## LongQuery
The sum of the idf of the query words.
## WordCount
Min(number of query words/10, 1.f)
## InvWordCount
1 / number_words_in_request.
## SyntQuality
Does the query have full parsing
## ExpectedFound
Expected number of searches on the query
Type of content factors (static and doc):
## IsEShop
commercial page
## IsMainPage
If the main page of the owner, the factor is 1.
## Long
Long document (the longer the document, the greater the value of the factor).
## IsForum
The URL satisfies the FORUM_DETECTOR reg
## IsEShop
commercial page
## IsMainPage
If the main page of the owner, the factor is 1.
## Long
Long document (the longer the document, the greater the value of the factor).
## IsForum
The URL satisfies the FORUM_DETECTOR reg
Examples of dynamic factors include:
## FreshNewsDetectorPredict
The value of the news detector calculated in behemoth. Always 0 when the detector value is less than the threshold.
## PiracyDetectorPredict
The value of the pirate detector calculated in behemoth.
## FreshNewsDetectorPredict
The value of the news detector calculated in behemoth. Always 0 when the detector value is less than the threshold.
## PiracyDetectorPredict
The value of the pirate detector calculated in behemoth.
URL factors
## UrlLen
URL length divided by 5
## IsObsolete
There is an ancient date in the URL. Ancient news are recognized. Factor 1 if url has year <=2007.
## OnlyUrl
All matches are in the URL only, no matches in the text of the page
## IsCom
.com domain
## UrlLen
URL length divided by 5
## IsObsolete
There is an ancient date in the URL. Ancient news are recognized. Factor 1 if url has year <=2007.
## OnlyUrl
All matches are in the URL only, no matches in the text of the page
## IsCom
.com domain
More Link factors:
## UrlHasNoDigits
There are no numbers in the url
## NumSlashes
Number of slashes in the url
## IsNotCgi
Factor about presence of '?' symbol in url. Equals zero if url has cgi parameters (more precisely: all duplicates have '?' symbol in url).
## UrlHasNoDigits
There are no numbers in the url
## NumSlashes
Number of slashes in the url
## IsNotCgi
Factor about presence of '?' symbol in url. Equals zero if url has cgi parameters (more precisely: all duplicates have '?' symbol in url).
Geo Match:
## GeoCityUrlRegionCity
Matching geography defined from document url and query city (ip or lr)
## GeoCityUrlGeoCityCity
Match the geography defined from the document url and the city in the query (GeoCity rule)
## GeoCountryUrlGeoCountry
nan
## GeoCityUrlRegionCity
Matching geography defined from document url and query city (ip or lr)
## GeoCityUrlGeoCityCity
Match the geography defined from the document url and the city in the query (GeoCity rule)
## GeoCountryUrlGeoCountry
nan
Host factors:
## IsBlog
Blog page
## IsWiki
page from ru-wikipedia-org
## IsOwner
Whether the host is its own owner, conditionally Host == Owner(Host).
## NastyHost
Host Po*** classifier, chips about *** queries that were shown and clicked on by the host
## IsBlog
Blog page
## IsWiki
page from ru-wikipedia-org
## IsOwner
Whether the host is its own owner, conditionally Host == Owner(Host).
## NastyHost
Host Po*** classifier, chips about *** queries that were shown and clicked on by the host
Browser factors:
## YabarHostSearchTraffic
Share of traffic from search engines
## VisitsFromWiki
Number of hits to the Wikipedia url
## BrowserHostDwellTimeRegionFrc
Ratio of dwell time on a host in a given region to dwell time on a host in all regions
## YabarHostSearchTraffic
Share of traffic from search engines
## VisitsFromWiki
Number of hits to the Wikipedia url
## BrowserHostDwellTimeRegionFrc
Ratio of dwell time on a host in a given region to dwell time on a host in all regions
More user/browser factors:
## BrowserBookmarksUrl
The more users add to bookmarks a url
## More90SecVisitsShare
Share of visits, for which the dwell time during the day on the host is more than 90 sec
## VisitorsReturnMonthNumber
Number of users who returned during the month
## BrowserBookmarksUrl
The more users add to bookmarks a url
## More90SecVisitsShare
Share of visits, for which the dwell time during the day on the host is more than 90 sec
## VisitorsReturnMonthNumber
Number of users who returned during the month
One of the most interesting categories to me is "text machine":
## BodyPairMinProximity
PairMinProximity factor over hits from Body
## BodyMinWindowSize
MinWindowSize factor over hits from Body
## TextCosineMatchMaxPrediction
CosineMatchMaxPrediction factor over hits from Text
## BodyPairMinProximity
PairMinProximity factor over hits from Body
## BodyMinWindowSize
MinWindowSize factor over hits from Body
## TextCosineMatchMaxPrediction
CosineMatchMaxPrediction factor over hits from Text
What's more interesting is that a majority of the "text machine" factors also are tagged with "NN over feature use" tag.
This suggests that:
1) the use of Neural Nets
2) a LLM for text search
3) these simple scraped factors are overridden
4) tiers of indexing complexity
This suggests that:
1) the use of Neural Nets
2) a LLM for text search
3) these simple scraped factors are overridden
4) tiers of indexing complexity
Example feature tagged with "NN" includes:
## NeuroTextModelLongClickPredictorByWord
The result of applying a neural model trained to distinguish long clicks from other events, the input of the model are word and bigram counters, calculated from text streamlines (Body, Url).
## NeuroTextModelLongClickPredictorByWord
The result of applying a neural model trained to distinguish long clicks from other events, the input of the model are word and bigram counters, calculated from text streamlines (Body, Url).
Conclusions to my investigative analysis of Yandex and their ability to reverse engineer Google Search.
- 5 key takeaways
- recommendations
- plus my next steps
(start here.... conclusions below)
- 5 key takeaways
- recommendations
- plus my next steps
(start here.... conclusions below)
https://twitter.com/alton_lex/status/1619142191963840512
1of5) It is now evident to me that the file used for this analysis (although accessible by dropbox) might have been sourced from an alleged illegal leak.
Since this may be true I want to make it clear that I do not condone illegal behavior.
My source:
Since this may be true I want to make it clear that I do not condone illegal behavior.
My source:
https://twitter.com/alex_buraks/status/1618988134850785280
2of5) The file and its translation suggest it is related to yandex search (a reasonable conclusion that others have implied)
3of5) If 1 and 2 are true, then yandex is doing similar competitive research that all companies perform (a reasonable assumption)
3of5) If 1 and 2 are true, then yandex is doing similar competitive research that all companies perform (a reasonable assumption)
4of5) nothing in the translated contents I've seen suggests that any approach or methodology it is proprietary or beyond common knowledge (see US patents for better details of each)
5of5) I personally see no value in continuing to explore the yandex factors because: (continued)
5of5) I personally see no value in continuing to explore the yandex factors because: (continued)
5a) even if a factor is identified it might not be used in production
5b) if a factor is used, it is useless without the coefficients or relative weighting logic
5c) obtaining any proprietary coefficients without permission or by illegal means would clearly be unsanctioned
5b) if a factor is used, it is useless without the coefficients or relative weighting logic
5c) obtaining any proprietary coefficients without permission or by illegal means would clearly be unsanctioned
So can anyone reverse engineer Google?
It certainly appears that Yandex and lots of others certainly want to understand Google rankings!
Draw your own conclusions from the full translated csv and 🐍 code:
github.com/FrontAnalytics…
It certainly appears that Yandex and lots of others certainly want to understand Google rankings!
Draw your own conclusions from the full translated csv and 🐍 code:
github.com/FrontAnalytics…
Finally, none of this analysis helps in any way with the ongoing data collection and research I'm doing.
Contact me for more information:
twitter.com/alton_lex
Contact me for more information:
twitter.com/alton_lex
Join me on this journey!
I will continue to collect my own data to analyze what helps content sites succeed on organic search:
1) follow me @alton_lex for more details
2) feel free to DM me with questions
3) Please share if this was helpful!
I will continue to collect my own data to analyze what helps content sites succeed on organic search:
1) follow me @alton_lex for more details
2) feel free to DM me with questions
3) Please share if this was helpful!
https://twitter.com/alton_lex/status/1598132992785805313
• • •
Missing some Tweet in this thread? You can try to
force a refresh