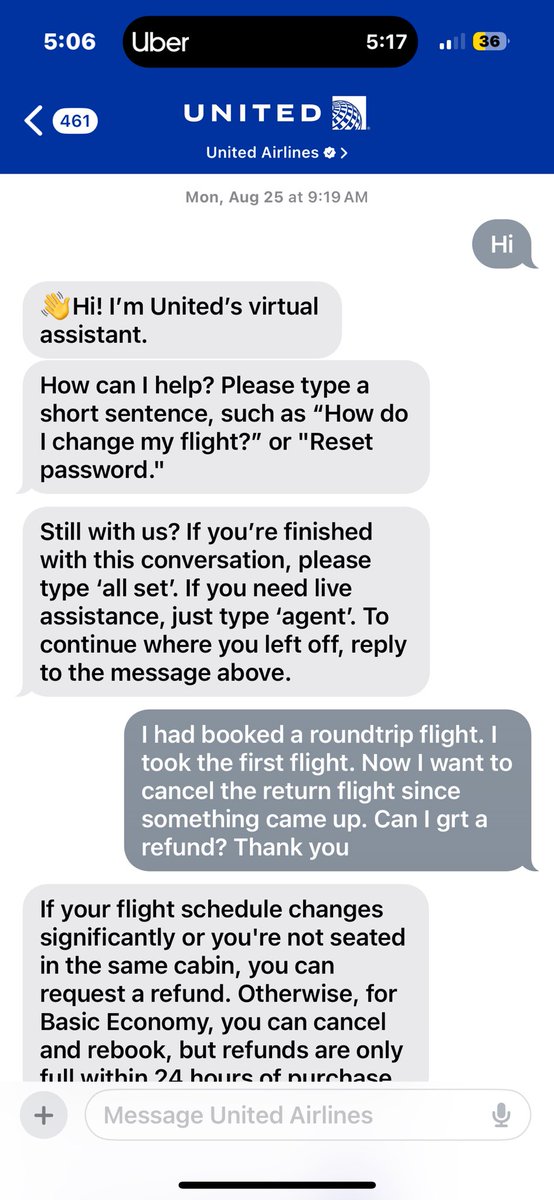
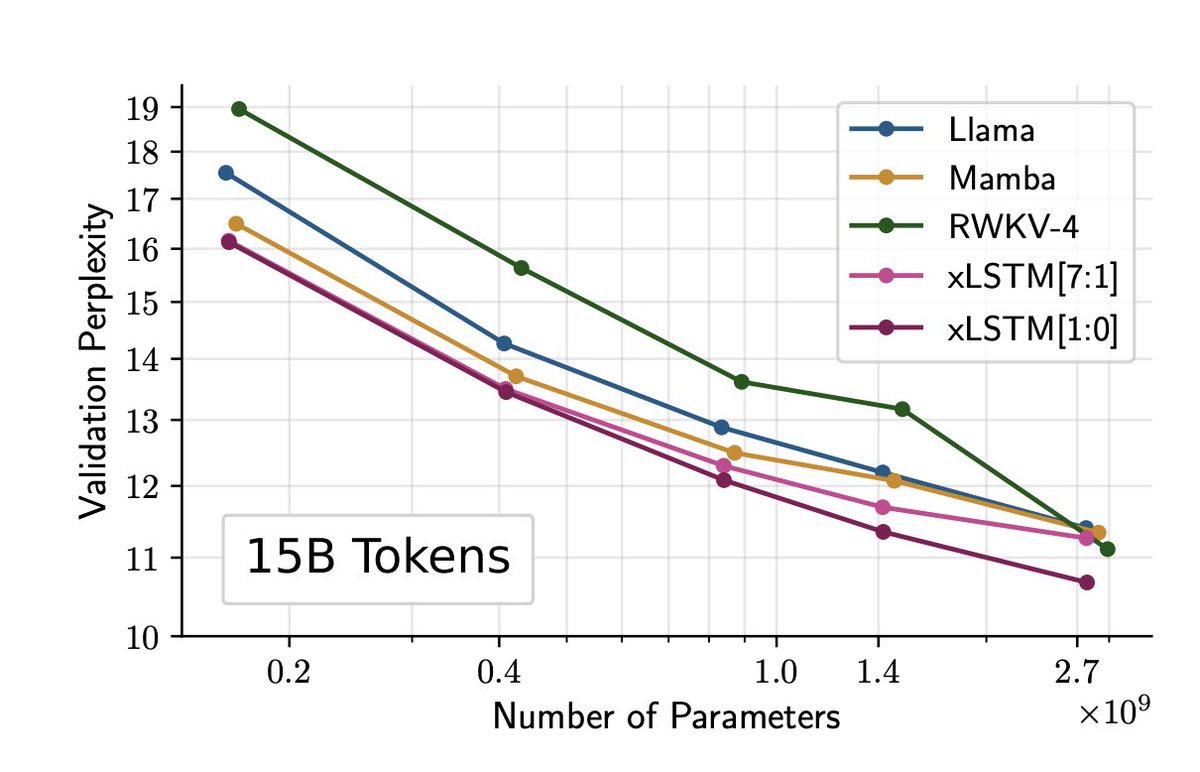
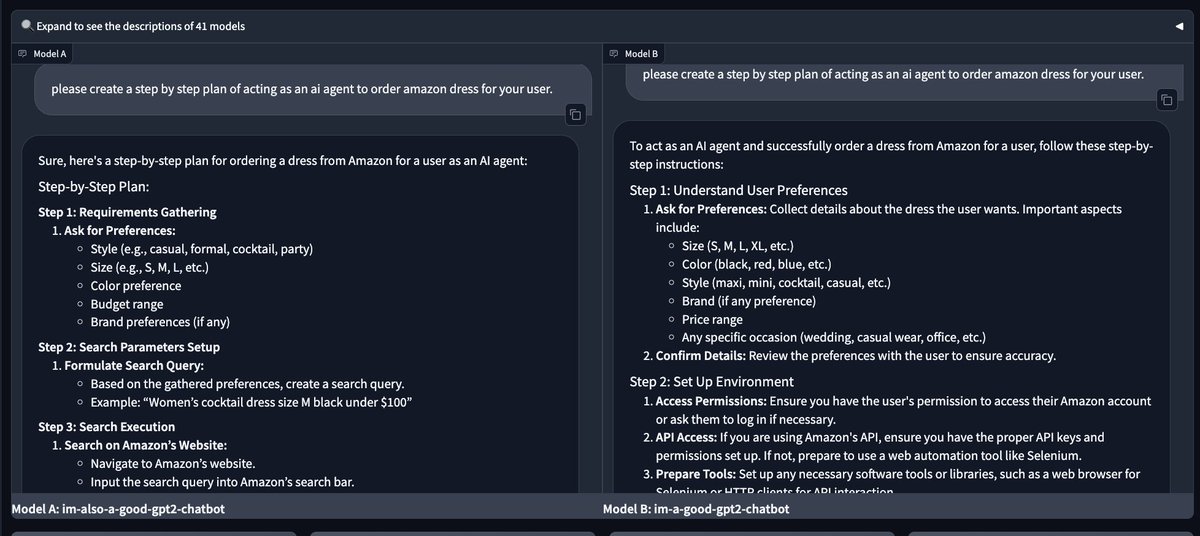
see what the future looks like with AI!
generate scifi style images with an auto-complete interface to help you write prompts quicker.
try now: portalpix.app
made using Leap from @leap_api @fdotinc
#aiart #ai #ml #generativeai #stablediffusion #buildspace #fdotinc
generate scifi style images with an auto-complete interface to help you write prompts quicker.
try now: portalpix.app
made using Leap from @leap_api @fdotinc
#aiart #ai #ml #generativeai #stablediffusion #buildspace #fdotinc

San Francisco


dubai 🏝️

japanese street market

• • •
Missing some Tweet in this thread? You can try to
force a refresh