Few-shot learning almost reaches traditional machine translation
Xavier Garcia @whybansal @ColinCherry George Foster, Maxim Krikun @fengfangxiaoyu @melvinjohnsonp @orf_bnw
arxiv.org/abs/2302.01398
#enough2skim #NLProc #neuralEmpty
Xavier Garcia @whybansal @ColinCherry George Foster, Maxim Krikun @fengfangxiaoyu @melvinjohnsonp @orf_bnw
arxiv.org/abs/2302.01398
#enough2skim #NLProc #neuralEmpty
The setting is quite simple:
Take a smaller (8B vs 100-500B in some baselines)
bilingual LM in two languages (one might be low resource see fig)
Show it a few translation examples in the prompt
Say abra kadabra 🪄
and you got a very good translation system
Take a smaller (8B vs 100-500B in some baselines)
bilingual LM in two languages (one might be low resource see fig)
Show it a few translation examples in the prompt
Say abra kadabra 🪄
and you got a very good translation system

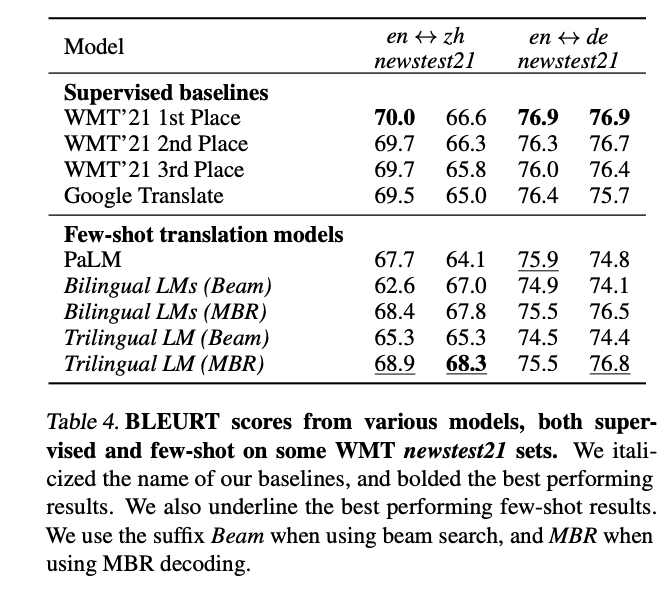
They reproduce known results and detail how to do it (especially for low resource)
e.g., continue previous training for speed\stability have many epochs on the monolingual training (fig)
etc.
e.g., continue previous training for speed\stability have many epochs on the monolingual training (fig)
etc.

Also, they replicate the result that quality of the few shot examples matters and state that
matching the style to the required output also matters (matched vs mismatched bottom row in fig )
matching the style to the required output also matters (matched vs mismatched bottom row in fig )


I was left wondering, if this is so good, would also training with supervision, back translation and everything else won't make it much better? If not, than this is just a tradeoff stating how hard it is to improve? If it is, than, maybe worth the effort for some.
• • •
Missing some Tweet in this thread? You can try to
force a refresh