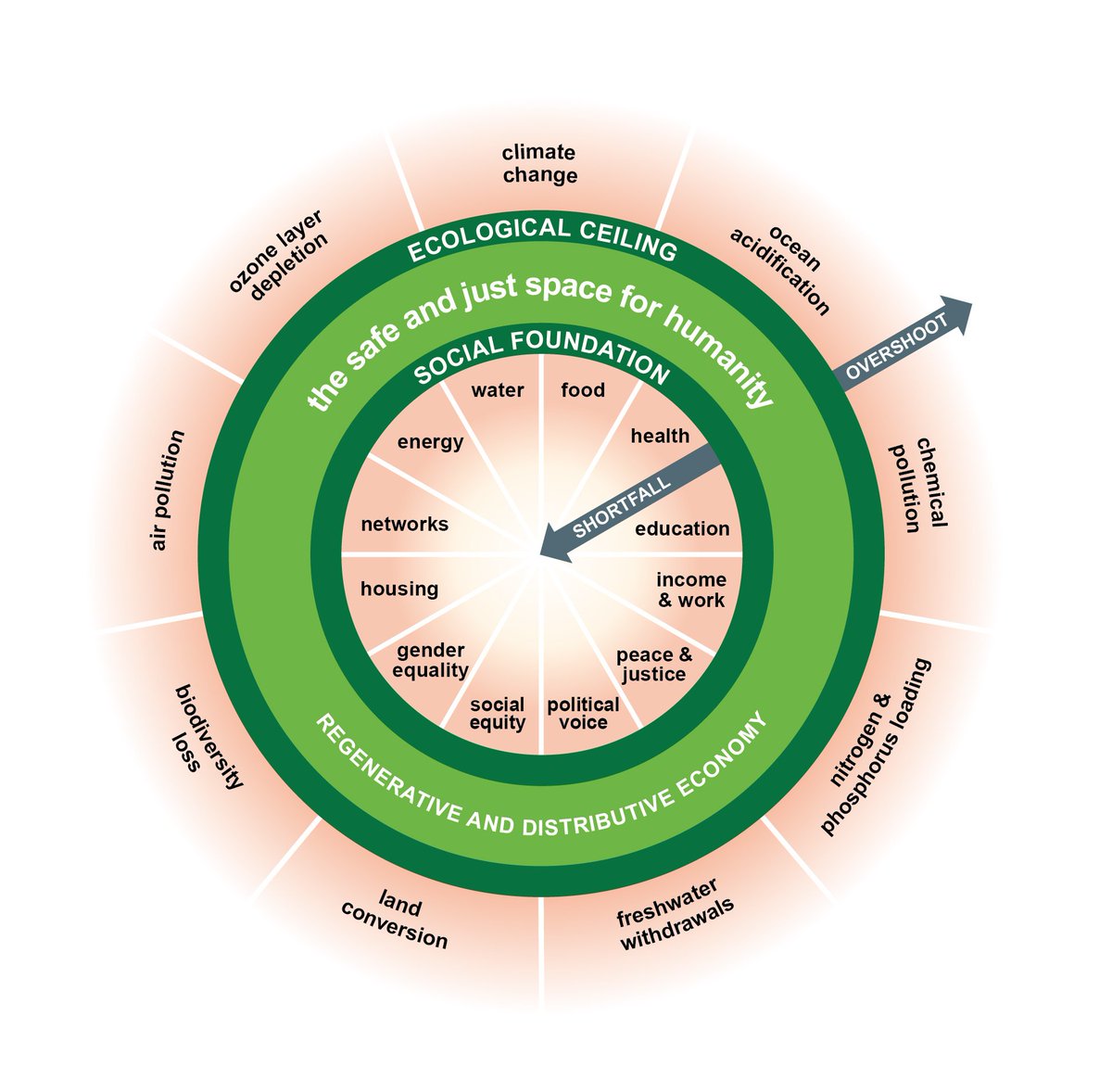
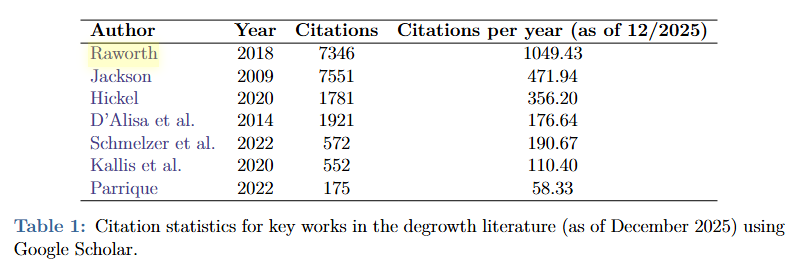
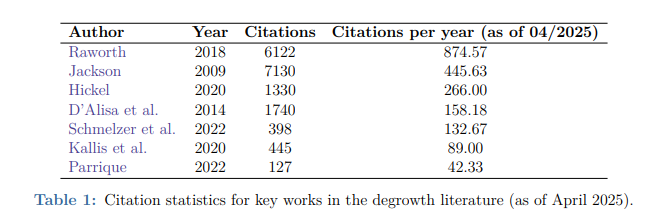
Thread: New paper available at Social Science Quarterly (cc. @SSQ_Online) with @casey_joe on the myth of wartime prosperity. onlinelibrary.wiley.com/doi/10.1111/ss… #econhist #econtwitter 

We take inspiration from Robert Higgs' 1992 "Myth of Wartime Prosperity" in the Journal of Economic History but shift from the USA to Canada.

Higgs had found that all claims of rising living standards were ill-founded. Most of this was the result of bad statistics, bad understanding of economics and wartime distortions to the meaningfulness of prices to convert quantities into "GDP" as a measure of wellbeing
Why Canada? Because it was in the war in 1939 rather than 1941 (i.e. more time to study) and it was also avoided the physical destruction. We also apply this to WW1. So, do we find the same results as Higgs?
Yes, we do. First, when we correct GDP numbers to concentrate on civilian well-being , we find that there was far smaller increases over the course of the war than the uncorrected figures do. This is true for WW1 as well.

When we correct for the disruptive effects of price controls on the deflator, we find that the war was merely a continuation of the Great Depression.

We also find that investments (private) were not above trends during either war. Similar finding for stock market data (from the TSX)



Again, the paper is here: onlinelibrary.wiley.com/doi/10.1111/ss…
cc. @ccoyne1 @IndependentInst @AlexNowrasteh @danieljmitchell @bryan_caplan @ATabarrok @tylercowen @CatoEdwards @edstringham @DrPatrickNewman
• • •
Missing some Tweet in this thread? You can try to
force a refresh