
NVIDIA. Część 2⃣
Plan
Część 1⃣: Wprowadzenie. Wyniki, komentarze, zapowiedzi podczas konferencji kwartalnej. 5.03
Część 2⃣: Infrastruktura / oferta #NVDA pod AI. Czyli co ma tworzyć fosę wokół biznesu spółki w AI. 12.03
Część 3⃣: Omniverse, Automotive. 19.03
Dziś cz. druga 🧵
Plan
Część 1⃣: Wprowadzenie. Wyniki, komentarze, zapowiedzi podczas konferencji kwartalnej. 5.03
Część 2⃣: Infrastruktura / oferta #NVDA pod AI. Czyli co ma tworzyć fosę wokół biznesu spółki w AI. 12.03
Część 3⃣: Omniverse, Automotive. 19.03
Dziś cz. druga 🧵

2/ Nvidia uważa, że rynek, który będą mogli zaadresować (TAM, Total Addressable Market) w dłuższym terminie będzie wart 1 bilion USD.
Ten schemat mniej więcej pokazuje nam, w jakim kierunku #Nvidia będzie chciała iść i gdzie będzie próbowała rozbudowywać kompetencje.
Ten schemat mniej więcej pokazuje nam, w jakim kierunku #Nvidia będzie chciała iść i gdzie będzie próbowała rozbudowywać kompetencje.

3/ Oczywiście to NIE JEST prognoza dla ich przychodów za 10 lat (roczna sprzedaż to teraz ok. 27 mld USD)
To jest wartość tortu, z którego spółka będzie próbowała wykroić jak największy kawałek dla siebie. Musi dodać nowe kompetencje, by wykroić więcej, ale musi i chronić obecne
To jest wartość tortu, z którego spółka będzie próbowała wykroić jak największy kawałek dla siebie. Musi dodać nowe kompetencje, by wykroić więcej, ale musi i chronić obecne
4/ Spółka widzi aż 300 mld potencjału w Software (150 mld AI Enterprise + 150 mld Omniverse). Obecnie z software mają może kilkaset mln $ przychodów.
Dlatego prawdopodobnie będą tu sporo inwestować, gdyż nawet kilka procent udziału w tym rynku to już ogromne dodatkowe przychody.
Dlatego prawdopodobnie będą tu sporo inwestować, gdyż nawet kilka procent udziału w tym rynku to już ogromne dodatkowe przychody.
5/ Ogromny potencjał widzą też w Automotive ($300B), gdzie od lat inwestują oraz w Hardware pod centra danych/AI ($300B).
Hardware: Chips&Systems to jest właśnie ten obszar, gdzie już są, mają największe kompetencje, jest nadal potężny potencjał, ale i muszą odpierać konkurencję
Hardware: Chips&Systems to jest właśnie ten obszar, gdzie już są, mają największe kompetencje, jest nadal potężny potencjał, ale i muszą odpierać konkurencję
6/ I dziś skupię się na tym obszarze , gdyż ten wpis ma być poświęcony ofercie $NVDA w zakresie AI i co tworzy ich ekosystem, który jednocześnie też ma budować fosę wokół tego biznesu.
Spółka twierdzi, że wyznaje motto: "nie mamy żadnej przewagi", więc BUDUJMY JĄ.
Spółka twierdzi, że wyznaje motto: "nie mamy żadnej przewagi", więc BUDUJMY JĄ.

7/ SZTUCZNA INTELIGENCJA. Hardware
Nvidia zdominowała rynek sprzętu do trenowania AI. Udział ich akceleratorów GPU wśród TOP6 🇺🇸 dostawców usług chmurowych (CPS) wynosi ~85%, a w ostatnim roku ich sprzęt odpowiadał wg Jefferies za blisko 100% przyrostu nowych akceleratorów u CPS
Nvidia zdominowała rynek sprzętu do trenowania AI. Udział ich akceleratorów GPU wśród TOP6 🇺🇸 dostawców usług chmurowych (CPS) wynosi ~85%, a w ostatnim roku ich sprzęt odpowiadał wg Jefferies za blisko 100% przyrostu nowych akceleratorów u CPS
8/ Akceleratory Nvidii są więc zdecydowanie pierwszym wyborem. D. Driggers, CTO z Cirrascale, twierdzi, że przy Generative AI w przyszłości powinna utrzymać się zasada: 80% Nvidia / 20% reszta
Tort będzie szybko rosnąć, ale co do samych udziałów: $NVDA ma tu więcej do stracenia
Tort będzie szybko rosnąć, ale co do samych udziałów: $NVDA ma tu więcej do stracenia
9/ Nvidia podwaliny pod tę dominację stworzyła jeszcze w 2006, kiedy pokazała architekturę CUDA.
Otwarło to naukowcom drogę do wykorzystania mocy GPU i ich wielordzeniowej struktury, by rozwiązywać ogólne problemy numeryczne poprzez równoległe obliczenia na wielu rdzeniach.
Otwarło to naukowcom drogę do wykorzystania mocy GPU i ich wielordzeniowej struktury, by rozwiązywać ogólne problemy numeryczne poprzez równoległe obliczenia na wielu rdzeniach.
10/ W tym czasie ATI, przejęte wtedy przez AMD, również wprowadziło swoje rozwiązanie i rozpoczęła się nowa era, w której GPU, tradycyjnie zajmujące się obliczeniami związanymi z grafiką komputerową, mogły być także wykorzystywane do obliczeń ogólnego przeznaczenia - domena CPU.

11/ Rok później Nvidia zapoczątkowała linię Tesla - pierwsza architektura dla GPU ogólnego przeznaczenia (GPGPU) - później już określane głównie jako AKCELERATOR.
#Nvidia zrobiła wokół nowego rozwiązania zdecydowanie większy szum niż konkurent i mocniej na to postawiła.
#Nvidia zrobiła wokół nowego rozwiązania zdecydowanie większy szum niż konkurent i mocniej na to postawiła.

12/ Sama nazwa linii Tesla znika od 2020, kiedy wchodzi architektura Ampere. Nazwa Nvidia Tesla mogła być bowiem... lekko myląca, ze względu na inną popularną firmę.
Bardziej lub mniej świadoma przyszłego potencjału tej linii Nvidia przez blisko dekadę mocno ją rozwijała, aż...
Bardziej lub mniej świadoma przyszłego potencjału tej linii Nvidia przez blisko dekadę mocno ją rozwijała, aż...
13/ ...po blisko dekadzie inwestycji w ekosystem, kilku kolejnych po Tesli architekturach, w końcu wiele elementów zaskoczyło naraz, co opisywałem w części 1⃣, a Nvidia szybko stała się synonimem AI.
I ciągłe usprawnianie ekosystemu, likwidacja wąskich gardeł stała się obsesją.
I ciągłe usprawnianie ekosystemu, likwidacja wąskich gardeł stała się obsesją.
14/ DGX - "superkomputer AI w pudełku"
Tzw. serwer DGX po raz pierwszy Nvidia wprowadziła latem 2016. Składa się on z 8 akceleratorów GPU oraz 1x CPU. W najnowszej architekturze Hopper jego koszt to ~$250k.
Do większych modeli wykorzystuje się setki GPU, do największych tysiące
Tzw. serwer DGX po raz pierwszy Nvidia wprowadziła latem 2016. Składa się on z 8 akceleratorów GPU oraz 1x CPU. W najnowszej architekturze Hopper jego koszt to ~$250k.
Do większych modeli wykorzystuje się setki GPU, do największych tysiące

15/ Dlatego DGX i całe ich klastry są popularnym rozwiązaniem.
Ale system jest tak silny, jak najsłabsze jego ogniwo. Co z tego, że mamy szybkie procesory, jeśli łączność między nimi, która jest niezbędna, by prowadzić równoległe obliczenia, będzie wolna. Powstanie WĄSKIE GARDŁO
Ale system jest tak silny, jak najsłabsze jego ogniwo. Co z tego, że mamy szybkie procesory, jeśli łączność między nimi, która jest niezbędna, by prowadzić równoległe obliczenia, będzie wolna. Powstanie WĄSKIE GARDŁO
16/ NVLink, InfiniBand
Te rozwiązania oferują niezbędną skalowalność całego systemu.
NVLink to opracowane przez Nvidię szybkie łącze GPU-to-GPU wewnątrz DGX (8x GPU), bez konieczności stosowania CPU.
Z kolei InfiniBand łączy serwery DGX. To znany produkt przejętego Mellanox'a
Te rozwiązania oferują niezbędną skalowalność całego systemu.
NVLink to opracowane przez Nvidię szybkie łącze GPU-to-GPU wewnątrz DGX (8x GPU), bez konieczności stosowania CPU.
Z kolei InfiniBand łączy serwery DGX. To znany produkt przejętego Mellanox'a

17/ Do wytrenowania modelu z 1.5 mld parametrami (GPT-3 ma 175 mld) potrzebne może być 512 GPUs, tj. 64xDGX.
InfiniBand jest teraz w stanie obsłużyć taki blok serwerów, ale to nie ogranicza skalowania. Można dokładać kolejne bloki połączone kolejnymi szybkimi warstwami switchy.
InfiniBand jest teraz w stanie obsłużyć taki blok serwerów, ale to nie ogranicza skalowania. Można dokładać kolejne bloki połączone kolejnymi szybkimi warstwami switchy.
18/ Klienci są skłonni płacić krocie za systemy DGX, bo oferują one jednolity, szybko działający oraz łatwo skalowalny układ, a do tego mają cały ekosystem oprogramowania / narzędzi deweloperskich Nvidii.
Ale polityka cenowa też musi być wyważona, bo konkurencja nie śpi.
Ale polityka cenowa też musi być wyważona, bo konkurencja nie śpi.

19/ Grace CPU
To może być ważny krok dla Nvidii. W drugiej połowie roku wprowadza procesor Grace CPU. Będzie on przeznaczony do zastosowań HPC (High-Performance Computing), tak jak akceleratory.
72-rdzeniowy procesor oparty o Arm v9, który będzie przyjmował postać pakietu 2x.
To może być ważny krok dla Nvidii. W drugiej połowie roku wprowadza procesor Grace CPU. Będzie on przeznaczony do zastosowań HPC (High-Performance Computing), tak jak akceleratory.
72-rdzeniowy procesor oparty o Arm v9, który będzie przyjmował postać pakietu 2x.

20/ Grace ma być przeznaczony do zastosowań profesjonalnych, ale kto wie czy później nie trafi do mas. W każdym razie Nvidia będzie miała czym zastąpić CPU Intela w swoich serwerach DGX i dalej optymalizować swój ekosystem.
Grace CPU może też pomóc spółce w obszarze INFERENCJI.
Grace CPU może też pomóc spółce w obszarze INFERENCJI.
21/ W skrócie, mamy trzy fazy tworzenia aplikacji AI:
🔸zebranie i przygotowanie danych
🔹trening
🔸inferencja (wnioskowanie)
Ta ostatnia faza obejmuje wdrożenie w życie wytrenowanego modelu. Często będzie to miało miejsce poza centrum danych, na jakimś urządzeniu brzegowym.
🔸zebranie i przygotowanie danych
🔹trening
🔸inferencja (wnioskowanie)
Ta ostatnia faza obejmuje wdrożenie w życie wytrenowanego modelu. Często będzie to miało miejsce poza centrum danych, na jakimś urządzeniu brzegowym.
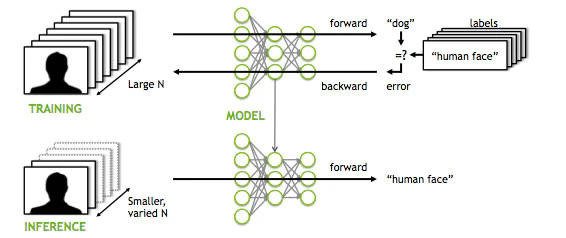
22/ Nvidia dominuje w treningu, ale inferencja to - jak określają niektórzy eksperci - na razie Dziki Zachód.
Tu często nie będą potrzebne GPU z tysiącami czy nawet setkami rdzeni. W wielu zastosowaniach wystarczą mniejsze CPU (ARM). Ale to też zależy od modelu/przeznaczenia.
Tu często nie będą potrzebne GPU z tysiącami czy nawet setkami rdzeni. W wielu zastosowaniach wystarczą mniejsze CPU (ARM). Ale to też zależy od modelu/przeznaczenia.
23/ ChatGPT do trenowania wykorzystywał 10k GPU, ale przy inferencji OpenAI może wykorzystywać nieużywane w danym czasie w chmurze CPU x86.
Przy generowaniu tekstu nie ma potrzeby mieć niezliczoną ilość rdzeni, bardziej może tu ograniczać pamięć, a CPU mają jej więcej jak GPU.
Przy generowaniu tekstu nie ma potrzeby mieć niezliczoną ilość rdzeni, bardziej może tu ograniczać pamięć, a CPU mają jej więcej jak GPU.
24/ Jeśli jednak chodziłoby o przetwarzanie / generowanie obrazu to taki model może mieć zbyt wiele parametrów, by do inferencji użyć czegoś słabszego jak Nvidia T4 z >2k rdzeni CUDA.
Te przykłady mogą nam podpowiadać, gdzie Nvidia będzie szukała swojego miejsca w inferencji
Te przykłady mogą nam podpowiadać, gdzie Nvidia będzie szukała swojego miejsca w inferencji
25/ Z czasem kolejne wytrenowane modele pójdą w świat i rynek wnioskowania będzie szybko rósł. W większości będą one optymalizowane do wersji na urządzenia brzegowe (oszczędność energii, czasu, latencja, prywatność) i w wielu zastosowaniach Nvidia nie będzie szukała obecności.
26/ Ale: pojazdy, maszyny, lokalne serwerownie w smart factories czy smart cities, tam często modele będą na tyle wymagające, że nie będzie można użyć słabszego sprzętu.
Grace CPU może być świetnym uzupełnieniem ich oferty hardware, które szerzej otworzy drzwi do fazy inferencji
Grace CPU może być świetnym uzupełnieniem ich oferty hardware, które szerzej otworzy drzwi do fazy inferencji
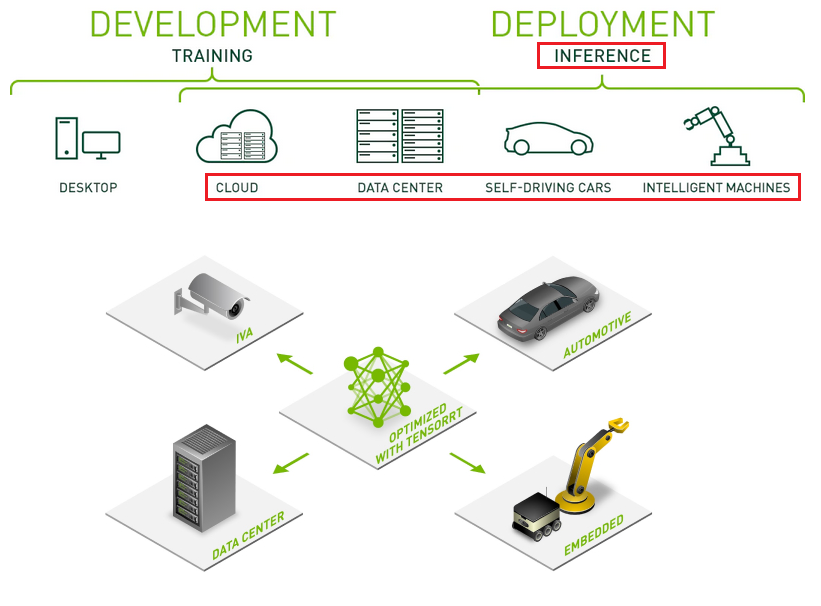
27/ SZTUCZNA INTELIGENCJA. Software, narzędzia
Nvidia nie byłaby jednak synonimem #AI, gdyby szukała przewagi tylko w hardware. Dla dużych graczy oczywiście istotna jest łatwa skalowalność całego systemu DGX, ale dla mniejszych firm, pojedynczych deweloperów to nie ma znaczenia.
Nvidia nie byłaby jednak synonimem #AI, gdyby szukała przewagi tylko w hardware. Dla dużych graczy oczywiście istotna jest łatwa skalowalność całego systemu DGX, ale dla mniejszych firm, pojedynczych deweloperów to nie ma znaczenia.
28/ W przeciwieństwie do typowego programowania w High Performance Computing, gdzie trzeba znać się na tym, co dzieje się na poziomie sprzętu, umieć to programować, dzięki platformie CUDA specjaliści od AI mogą skupić się na modelach, a platforma odpowiednio połączy to z hardware

29/ Typowe programowanie HPC vs AI: to są inne języki, inne specjalizacje.
Nvidia postawiła właśnie na podejście platformowe, wysoko wyniosła znaczenie software. Opracowała sposób, by GPU komunikowały się ze sobą, ale by i naukowcy od AI łatwo mogli się z hardware „dogadać”.
Nvidia postawiła właśnie na podejście platformowe, wysoko wyniosła znaczenie software. Opracowała sposób, by GPU komunikowały się ze sobą, ale by i naukowcy od AI łatwo mogli się z hardware „dogadać”.
30/ Nvidia zoptymalizowała popularne języki do maszynowego uczenia, jak PyTorch czy TensorFlow i ich biblioteki, pod kątem swoich GPUs i platformy CUDA
Sięgali również po popularne biblioteki i „zCUDAfikowali” je
Krok po kroku, platforma stała się pierwszym wyborem specjalistów
Sięgali również po popularne biblioteki i „zCUDAfikowali” je
Krok po kroku, platforma stała się pierwszym wyborem specjalistów

31/ Platforma CUDA zapewnia kompatybilność ze wszystkimi generacjami GPU spółki, co też ma znaczenie, jeśli tworzy się model dla celów biznesowych, długoterminowych.
Dla poważnych firm znaczenie ma też sama stabilność finansowa dostawcy ekosystemu (vs start-upy).
Dla poważnych firm znaczenie ma też sama stabilność finansowa dostawcy ekosystemu (vs start-upy).
32/ KONKURENCJA
Nie w każdym przypadku rozwiązania Nvidii czy też procesorów GPU są najbardziej optymalne. Ale na dziś dzień do treningu mogą takie być w 80% przypadków.
O ten kawał tortu Nvidia rywalizuje z AMD i Intelem, którzy wydają się ciągle pozostawać sporo w tyle.
Nie w każdym przypadku rozwiązania Nvidii czy też procesorów GPU są najbardziej optymalne. Ale na dziś dzień do treningu mogą takie być w 80% przypadków.
O ten kawał tortu Nvidia rywalizuje z AMD i Intelem, którzy wydają się ciągle pozostawać sporo w tyle.
33/ Czasami bardziej optymalne będą inne wyspecjalizowane urządzenia, które np. oferują sporo więcej pamięci po stronie obliczeniowej.
To otwiera też możliwości dla NOWEJ KONKURENCJI, jak prywatne: Cerebas, Graphcore czy SambaNova. Nvidia musi pilnie ich obserwować.
To otwiera też możliwości dla NOWEJ KONKURENCJI, jak prywatne: Cerebas, Graphcore czy SambaNova. Nvidia musi pilnie ich obserwować.
34/ Można też spotkać się z opiniami, że nowa generacja bibliotek do ML/DL, np. PyTorch 2.0, na tyle ma je zoptymalizować i otworzyć na inne urządzenia, że doprowadzi to do końca dominacji Nvidii.
To też pytanie do zajmujących się AI na co dzień: czy podzielają taki pogląd?
To też pytanie do zajmujących się AI na co dzień: czy podzielają taki pogląd?
35/ Kiedy lata temu analizowałem Adobe, to im więcej czytałem o konkurencji, tym więcej widziałem ryzyk dla $ADBE, gdyż wiele innych produktów było wyżej ocenianych, z ambitnymi planami ich twórców.
Jednak tu wychodzi SIŁA EKOSYSTEMU. Kompleksowość produktu tworzy fosę.
Jednak tu wychodzi SIŁA EKOSYSTEMU. Kompleksowość produktu tworzy fosę.

36/ Nvidia zbudowała też taką fosę, ale NIE MOŻE spocząć na laurach.
Materiał się rozrósł, a to tylko "dotknięcie" tematu. Niemniej Omniverse i automotive muszę zrobić w oddzielnej części.
Jeśli 🧵 podobała się to tradycyjnie wielka prośba o ♥️, a najlepiej RT - dla zasięgów ;)
Materiał się rozrósł, a to tylko "dotknięcie" tematu. Niemniej Omniverse i automotive muszę zrobić w oddzielnej części.
Jeśli 🧵 podobała się to tradycyjnie wielka prośba o ♥️, a najlepiej RT - dla zasięgów ;)
• • •
Missing some Tweet in this thread? You can try to
force a refresh













