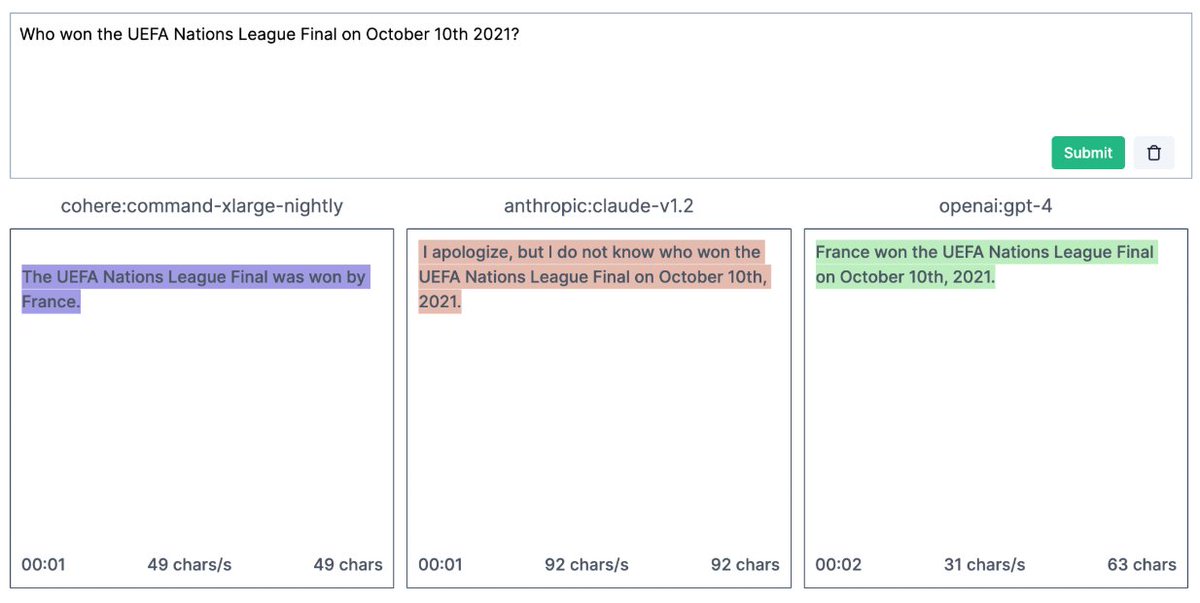
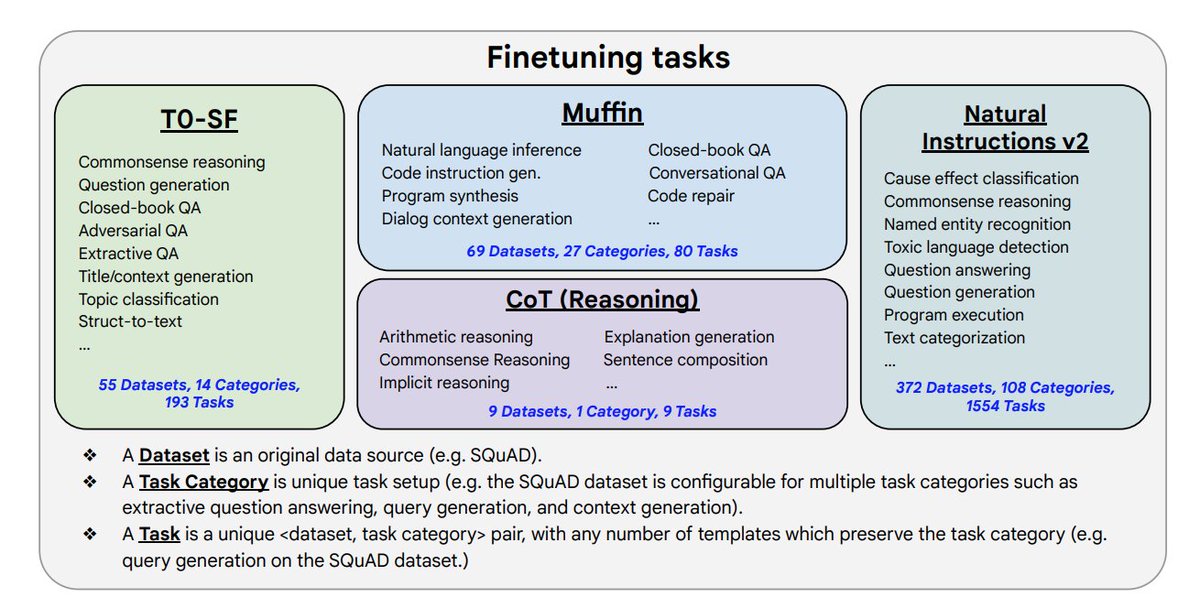
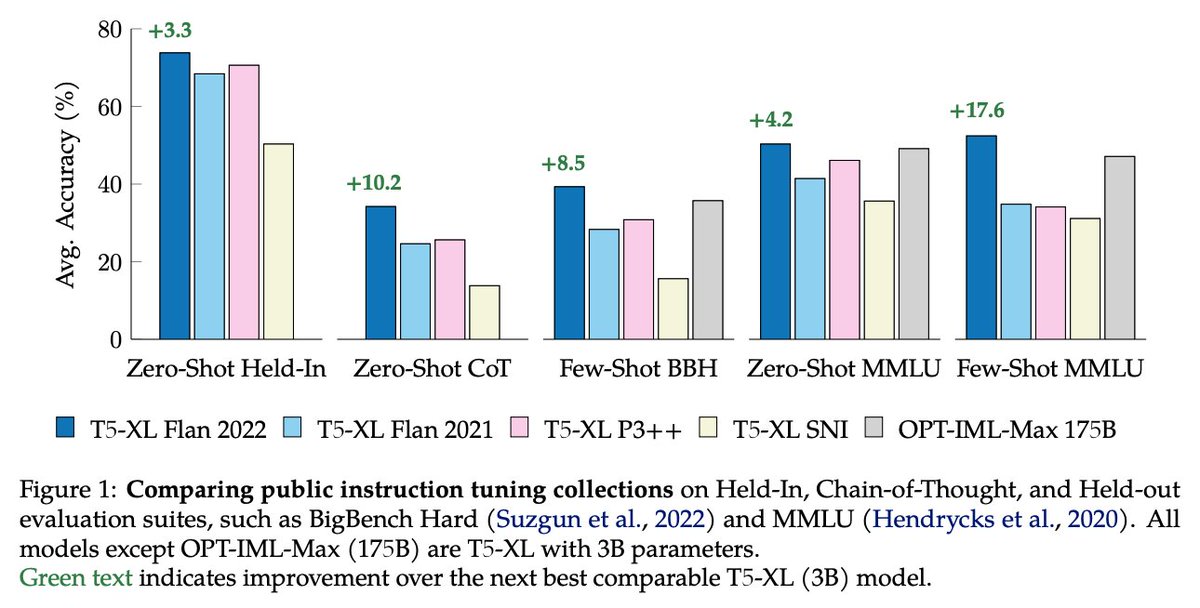
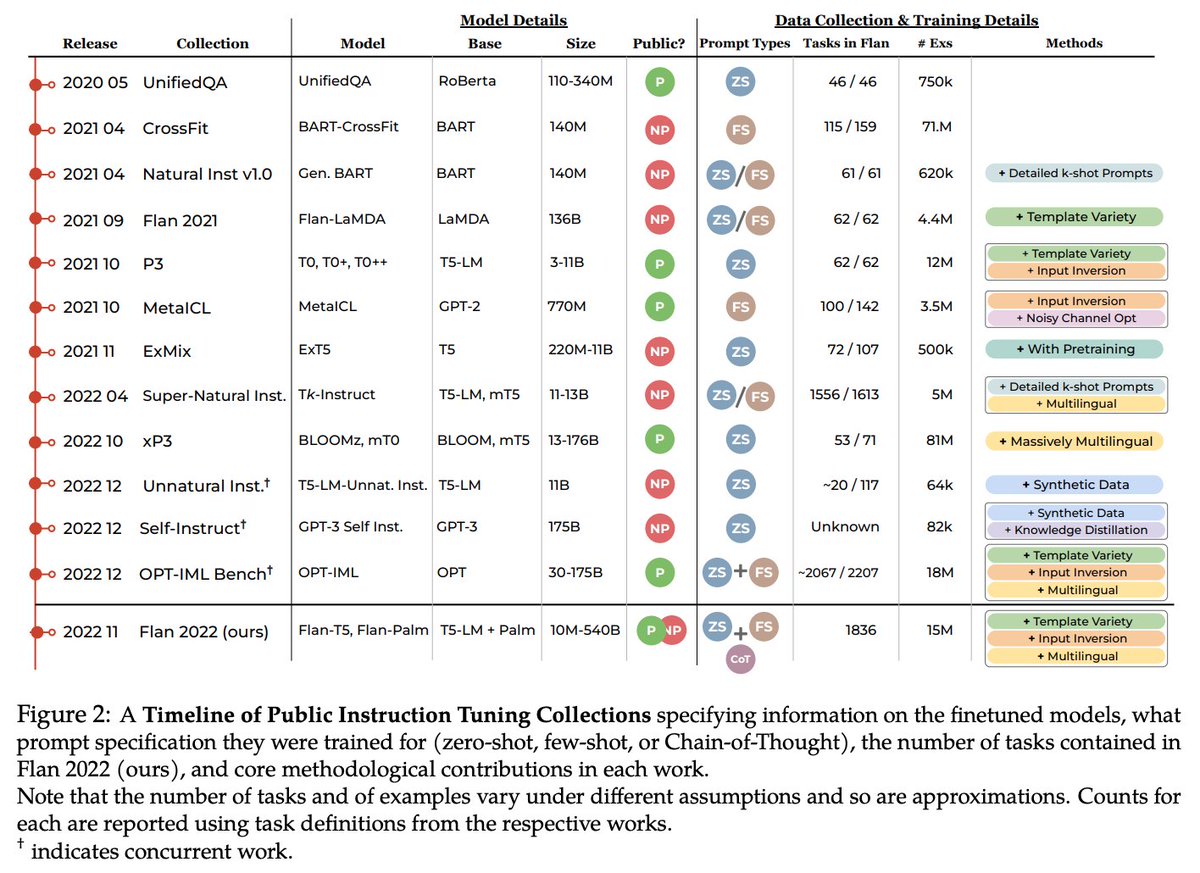
#NewPaperAlert When and where does pretraining (PT) data matter?
We conduct the largest published PT data study, varying:
1⃣ Corpus age
2⃣ Quality/toxicity filters
3⃣ Domain composition
We have several recs for model creators…
📜: bit.ly/3WxsxyY
1/ 🧵
We conduct the largest published PT data study, varying:
1⃣ Corpus age
2⃣ Quality/toxicity filters
3⃣ Domain composition
We have several recs for model creators…
📜: bit.ly/3WxsxyY
1/ 🧵
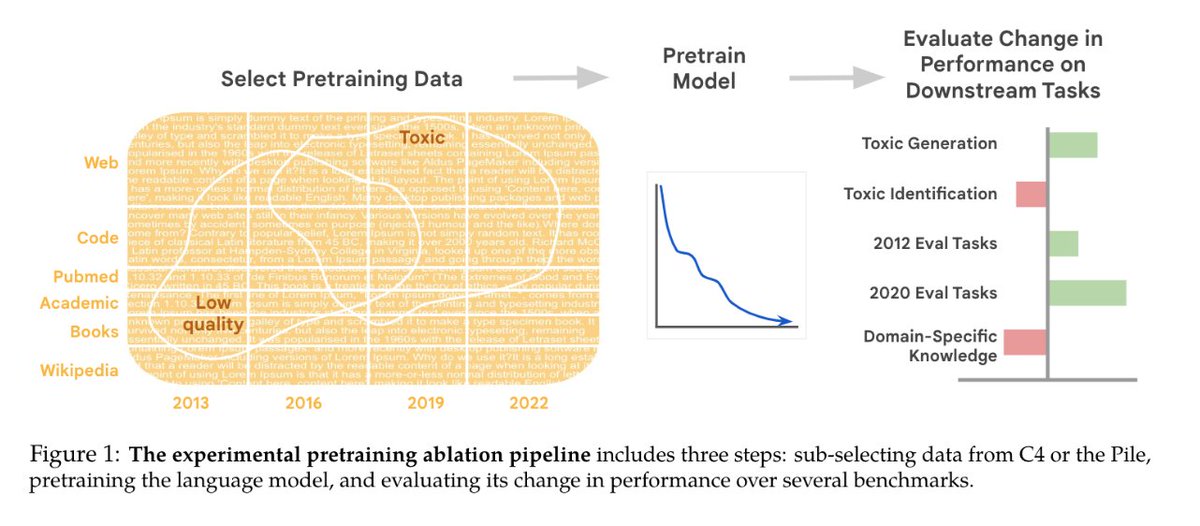
First, PT data selection is mired in mysticism.
1⃣ Documentation Debt: #PALM2 & #GPT4 don't document their data
2⃣ PT is expensive ➡️ experiments are sparse
3⃣ So public data choices are largely guided by ⚡️intuition, rumors, and partial info⚡️
2/
1⃣ Documentation Debt: #PALM2 & #GPT4 don't document their data
2⃣ PT is expensive ➡️ experiments are sparse
3⃣ So public data choices are largely guided by ⚡️intuition, rumors, and partial info⚡️
2/

PT is the foundation of data-centric and modern LMs. This research was expensive but important to shed light on open questions in training data design.
Here are our main findings:
3/
Here are our main findings:
3/
🌟Finding 1 – Corpus age matters 🌟
➡️ Diffs in PT and eval year lead to 🔻performance – and it isn’t overcome by finetuning!
➡️ Size matters: this effect is larger for XL than Small models
➡️ This phenomenon complicates NLP evaluations comparing new and old models.
4/
➡️ Diffs in PT and eval year lead to 🔻performance – and it isn’t overcome by finetuning!
➡️ Size matters: this effect is larger for XL than Small models
➡️ This phenomenon complicates NLP evaluations comparing new and old models.
4/

🌟Finding 2 – Qual/Tox Filter Trade-Offs 🌟
➡️ Quality filters trade-off: boosts performance, but also toxic generation.
➡️ Toxicity filters impose the opposite trade-off: 🔻perf and 🔻toxic gen
5/
➡️ Quality filters trade-off: boosts performance, but also toxic generation.
➡️ Toxicity filters impose the opposite trade-off: 🔻perf and 🔻toxic gen
5/

🌟Finding 3 – Inverse Toxicity Filters 🌟
Surprisingly, *inverse* toxicity filters (removing the least toxic content) improve toxicity identification tasks.
(Also improves QA in books, academic, and common sense domains.)
6/
Surprisingly, *inverse* toxicity filters (removing the least toxic content) improve toxicity identification tasks.
(Also improves QA in books, academic, and common sense domains.)
6/

🌟Finding 5 – Filter effects are unpredictable from text characteristics 🌟
E.g. quality classifier ranks Books as highest quality, but eval on Books were NOT helped by quality filtering.
And “low-quality” domains (e.g. biomedical) benefited most from quality filters.
Why?
7/
E.g. quality classifier ranks Books as highest quality, but eval on Books were NOT helped by quality filtering.
And “low-quality” domains (e.g. biomedical) benefited most from quality filters.
Why?
7/

We believe relevant/beneficial training text isn’t always on the ends of the narrowly-defined “quality” spectrum.
➡️ Future work: More nuanced & multidimensional measures of quality could lead to much stronger results.
8/
➡️ Future work: More nuanced & multidimensional measures of quality could lead to much stronger results.
8/
🌟Finding 6 – One size filter does not fit all 🌟
Our results suggest one filter type is not best for all situations.
9/
Our results suggest one filter type is not best for all situations.
9/
🌟Finding 7 – Domain composition effects 🌟
➡️ Web and books sources are most beneficial, emphasizing data heterogeneity (web) and quality (books)
➡️ For generalization, train on all data sources!
10/
➡️ Web and books sources are most beneficial, emphasizing data heterogeneity (web) and quality (books)
➡️ For generalization, train on all data sources!
10/

We tie these findings back to a detailed breakdown of C4 and the Pile’s characteristics.
Check out the paper for more details: 📜 bit.ly/3WxsxyY 📜
11/
Check out the paper for more details: 📜 bit.ly/3WxsxyY 📜
11/
🌟 Limitations 🌟
➡️ These ablations are computationally costly, but we believe justified to avoid model creators from repeating each other’s (undocumented) mistakes.
➡️ These results are an early preprint (not yet peer reviewed)→ we welcome & hope for community feedback!
12/
➡️ These ablations are computationally costly, but we believe justified to avoid model creators from repeating each other’s (undocumented) mistakes.
➡️ These results are an early preprint (not yet peer reviewed)→ we welcome & hope for community feedback!
12/
There’s been a lot of discussion lately on training dataset composition! Some other tweet threads:
13/
https://twitter.com/JesseDodge/status/1656378085816643584
https://twitter.com/leavittron/status/1657096163072565253
https://twitter.com/LucileSaulnier/status/1597262246278680576
13/
And also @sangmichaelxie's recent work on stronger methods for balancing Pile domains:
14/
https://twitter.com/sangmichaelxie/status/1659230705165975552?s=20
14/
Finally, thank you for reading!
This has been my favourite long term project to date because of the irreplaceable and incredibly supportive core collaborators @daphneipp @emilyrreif @katherine1ee @gyauney and @dmimno.
15/
This has been my favourite long term project to date because of the irreplaceable and incredibly supportive core collaborators @daphneipp @emilyrreif @katherine1ee @gyauney and @dmimno.
15/

Also thank you to @ada_rob @JasonWei @barret_zoph @denny_zhou @krob for their critical guidance and support, as well as @MaartenBosma, @noahconst, Noah Fiedel, @dsmilkov & @jacobandreas for their constructive feedback and early guidance.
🧵/🧵
🧵/🧵
Wrong Jason, my bad! I meant @_jasonwei / @agikoala
• • •
Missing some Tweet in this thread? You can try to
force a refresh