
🚨 Does client-side scanning really allows you to detect known illegal content without breaking encryption? In a new @IEEESSP paper, we show that secondary features such as targeted facial recognition could actually be hidden into it. A thread 🧵
There have been long standing concerns by law enforcement agencies 👮 that encryption, and more recently end-to-end encryption, is preventing them from accessing content sent by users*.
(* some strongly disagree with the notion that law enforcement agencies are "going dark")
(* some strongly disagree with the notion that law enforcement agencies are "going dark")
Client-side scanning (CSS) aims to allow law enforcement agencies to detect when known illegal content ⛔️ is shared on end-to-end encrypted (E2EE) messaging platforms 📱↔️📱such as @signalapp and @WhatsApp "without breaking encryption".
But how would CSS work? In short, a piece of software would be installed on people's phones 📱 as part of the messaging system. Every time an image is sent or received, the software would check whether the image is not content known to be illegal ⛔️.
Basically, what the software does is to checks that the image is not part of a database 🛢️ of content known to be illegal🚦.
If it is, the image is then shared (decrypted) with a third-party for further action and, ultimately, with law enforcement authorities 👮.
If it is, the image is then shared (decrypted) with a third-party for further action and, ultimately, with law enforcement authorities 👮.

However, reliably detecting that an image is in the database 🛢️ is not easy. You indeed want to make sure it'll be flagged even if it's in a different format (png vs jpeg e.g.), if the image has been cropped, is in black and white, etc.
To do this, CSS systems rely on deep perceptual hashing algorithms (DPH). These are #AI algorithms that can detect whether an image is a “near-duplicate” of a known (illegal) image.
@Apple's system, for example, uses an algorithm called NeuralHash.
@Apple's system, for example, uses an algorithm called NeuralHash.

In this paper, we argue that while AI algorithms are very good at this (@Apple's said that NeuralHash's error rate is one in a million) they are also completely black-box ⬛️.
In the context of CSS, this is particularly problematic 😬.
In the context of CSS, this is particularly problematic 😬.
Indeed, CSS systems would have access to every single image 🖼️ sent on E2EE messaging systems and can decide to share them, unencrypted, with law enforcement 🖼️➡️⬛️➡️👮.
For @WhatsApp alone, this represents billions of images daily.
For @WhatsApp alone, this represents billions of images daily.
In the paper, we study how a hidden "secondary" feature ("backdoor") could be built into a deep perceptual hashing algorithm.
In particular, we show DPH models can be trained to identify targeted individual 🧍♂️ in images 🖼️ and report them to law enforcement 👮.
In particular, we show DPH models can be trained to identify targeted individual 🧍♂️ in images 🖼️ and report them to law enforcement 👮.
And this works... very well.
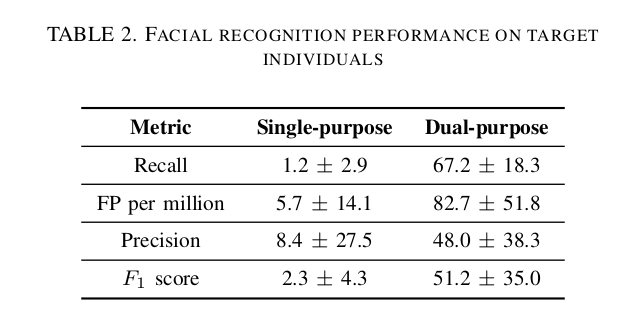
Our dual-purpose model indeed identifies a targeted individual 🧍♂️ 67% of the time!
For comparison, the "normal" single-purpose DPH model would only identify the targeted individual 1% of the time.
Our dual-purpose model indeed identifies a targeted individual 🧍♂️ 67% of the time!
For comparison, the "normal" single-purpose DPH model would only identify the targeted individual 1% of the time.
But, wouldn't this get detected somehow?
Not really, we indeed show in the paper that this new feature is hidden. The algorithm performs its primary task, detecting known illegal content, well and only flags images containing a targeted individual.
Not really, we indeed show in the paper that this new feature is hidden. The algorithm performs its primary task, detecting known illegal content, well and only flags images containing a targeted individual.


Yes, but the database 🛢️will be tightly controlled so you can't just add pictures of the targeted individuals?
True. It could be managed by a charity such as NCMEC and possibly be verifiable (see e.g. eprint.iacr.org/2023/029)
True. It could be managed by a charity such as NCMEC and possibly be verifiable (see e.g. eprint.iacr.org/2023/029)
However, @kerstingAIML's team recently showed how DPH are vulnerable to collision attacks facctconference.org/static/pdfs_20…
Using their code, we managed to hide the information necessary to identify a target individual (facial rec template) into an illegal image (center, picture of a dog)
Using their code, we managed to hide the information necessary to identify a target individual (facial rec template) into an illegal image (center, picture of a dog)

To conclude: DPH the algorithms at the core of CSS are black-box #AI models ⬛️.
What our results show is that it's easy to actually get them to look absolutely normal yet to include secondary hidden features ("backdoor"), here targeted facial recognition 🧍♂️.
What our results show is that it's easy to actually get them to look absolutely normal yet to include secondary hidden features ("backdoor"), here targeted facial recognition 🧍♂️.
While this is a concern in general with #AI models, the issue is particularly salient in the context of CSS where these algorithms can flag and share private content with authorities before it gets encrypted 🔐.
Importantly, these new results adds to a long list of concerns about CSS including questions about their effectiveness (avoidance detection attacks e.g. usenix.org/conference/use… and eprint.iacr.org/2021/1531) or how easy it is to create false positive (e.g. arxiv.org/abs/2111.06628)
For more info on the topic, Bugs in our pockets is a great summary of the concerns raised by CSS systems arxiv.org/abs/2110.07450 while arxiv.org/abs/2207.09506 is a thoughtful piece from @NCSC and @GCHQ on CSS from the law enforcement 👮 perspective.
Last but not least, CSS are not just theoretical proposals. @Apple was about to deploy it at scale two years ago theregister.com/2021/12/16/app… and CSS are a key part of legislative proposals incl. the 🇬🇧 #OnlineSafety Bill and the 🇪🇺 CSAR (see e.g. techcrunch.com/2022/05/11/eu-… by @riptari)
This is work by my amazing students 🧑🎓 @shubhamjain0594 and @AnaMariaCretu5 with help from @CULLYAntoine at @ICComputing.
@shubhamjain0594 presented the work yesterday at @IEEESSP in San Francisco and the paper is available at imperialcollegelondon.app.box.com/s/xv46sdud6kvh…
@shubhamjain0594 presented the work yesterday at @IEEESSP in San Francisco and the paper is available at imperialcollegelondon.app.box.com/s/xv46sdud6kvh…
cc/ @carmelatroncoso, @ThomasClaburn, @AlecMuffett, @rossjanderson, @matthew_d_green, @jonathanmayer, @SteveBellovin, @schneierblog, @mer__edith, @wcathcart.
• • •
Missing some Tweet in this thread? You can try to
force a refresh




