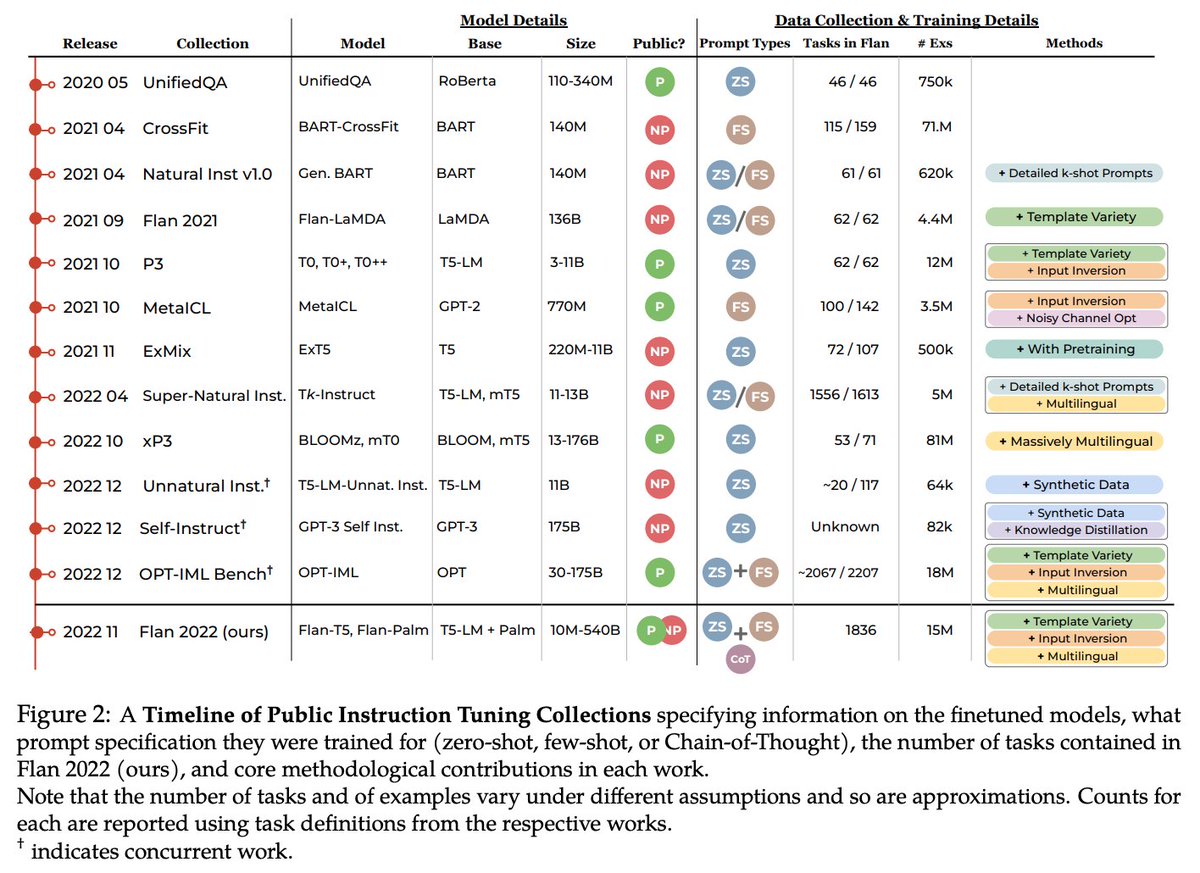
This semester my @CCCatMIT co-instructors and I taught #MIT's first post-#ChatGPT Generative AI course, covering:
➡️Uses and new abilities
➡️LM Evaluation
➡️AI-mediated communication
➡️Societal challenges
📜 Syllabus + reading list 📚: ai4comm.media.mit.edu
1/
➡️Uses and new abilities
➡️LM Evaluation
➡️AI-mediated communication
➡️Societal challenges
📜 Syllabus + reading list 📚: ai4comm.media.mit.edu
1/

It was a 🎢wild journey to teach in the midst of GPT-4 + Bard launches, moratorium letters, and raging online controversies every d*mn day.
We're excited to release our (and our students') learnings, slides, and the talks from our guest speakers.
Stay tuned!
2/
We're excited to release our (and our students') learnings, slides, and the talks from our guest speakers.
Stay tuned!
2/
Over the next few days we'll post talks/talk summaries from:
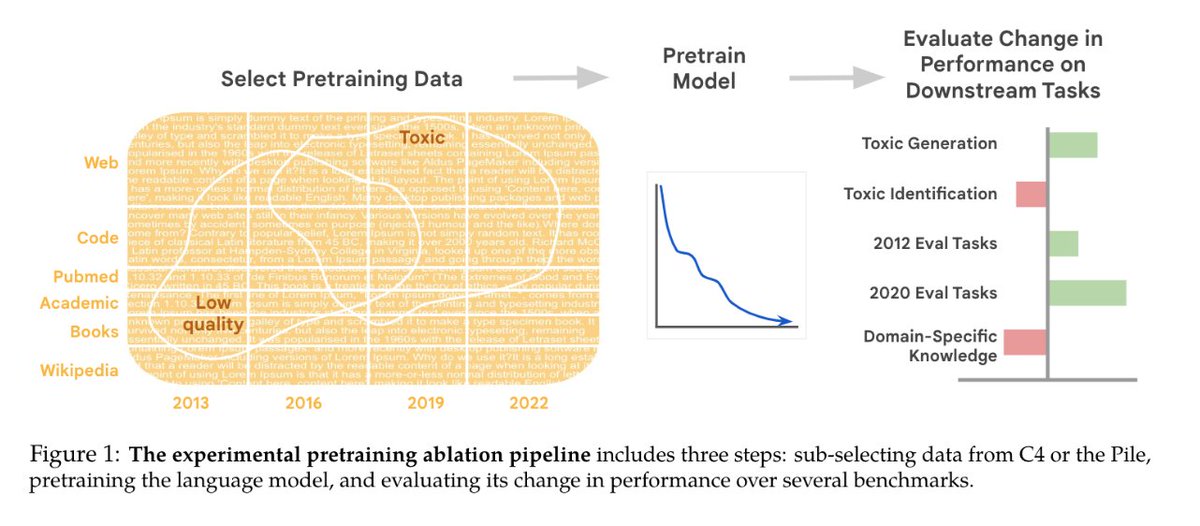
➡️ @RishiBommasani guest lecture on Holistic Evaluation of Language Models
📜: crfm.stanford.edu/helm/latest/
3/
➡️ @RishiBommasani guest lecture on Holistic Evaluation of Language Models
📜: crfm.stanford.edu/helm/latest/
3/


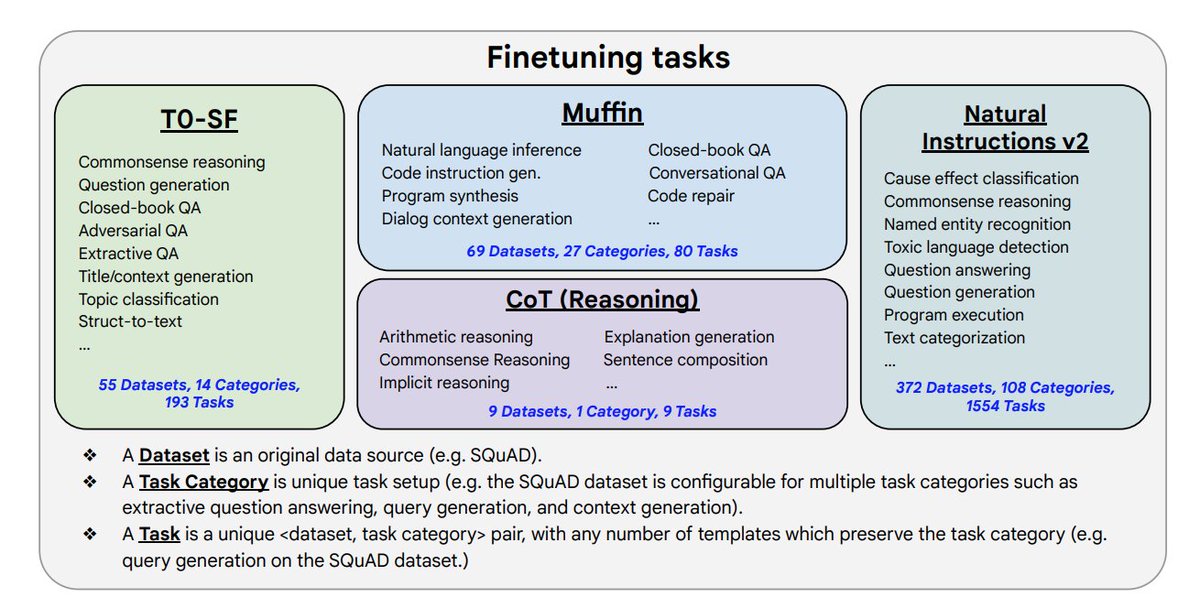
➡️ @_jasonwei on LLM Emergent Abilities as well as a general intro to LLMs
📜: ai.googleblog.com/2022/11/charac…
4/
📜: ai.googleblog.com/2022/11/charac…
4/


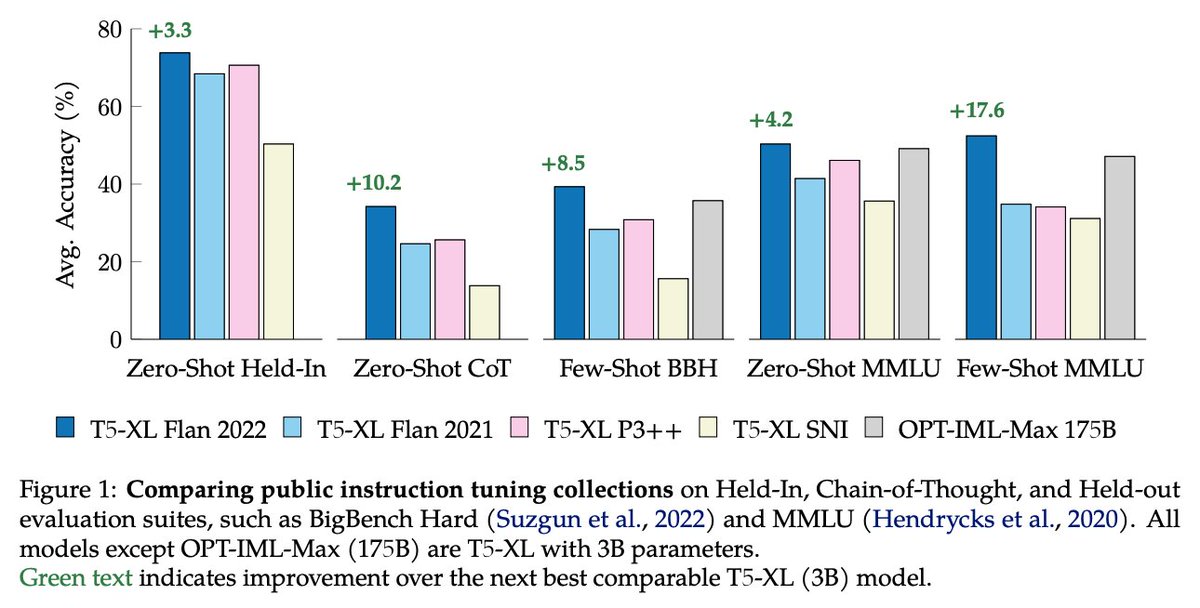
➡️ @bakkermichiel on "Fine-tuning language models to find agreement among humans with diverse preferences"
📜: arxiv.org/pdf/2211.15006…
5/
📜: arxiv.org/pdf/2211.15006…
5/


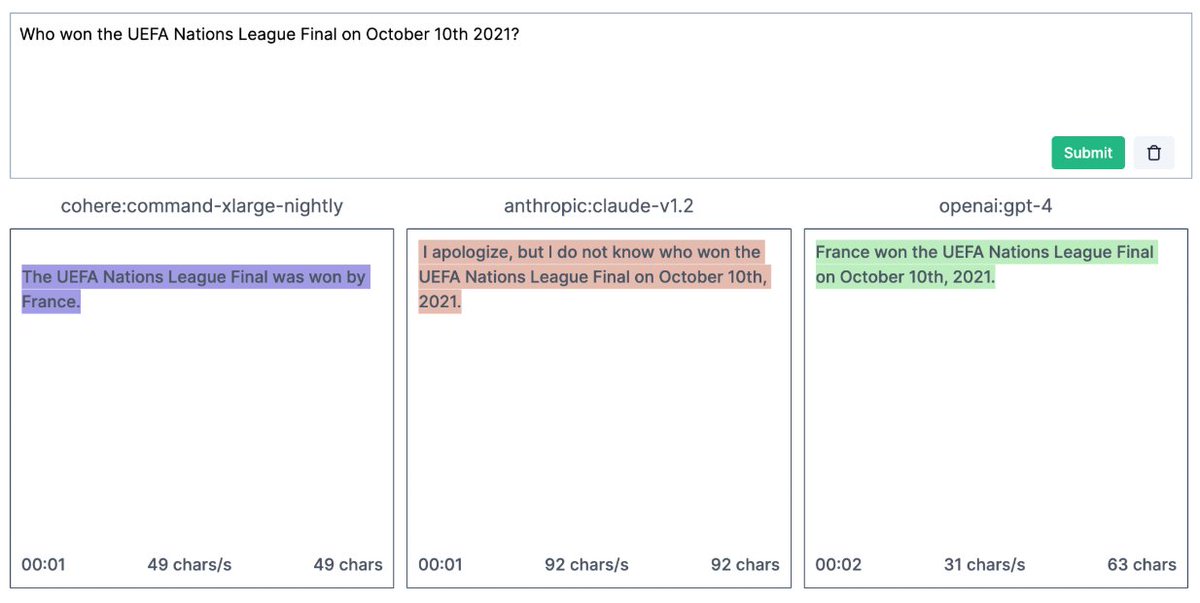
➡️ @MinaLee__ on "Designing and Evaluating Language Models for Human Interaction"
📜: arxiv.org/abs/2212.09746 and arxiv.org/abs/2201.06796
6/
📜: arxiv.org/abs/2212.09746 and arxiv.org/abs/2201.06796
6/


➡️ @informor on "My AI must have been broken": Understanding our Future of AI-Mediated Communication
📜: arxiv.org/abs/2206.07271 and dl.acm.org/doi/10.1145/32…
7/
📜: arxiv.org/abs/2206.07271 and dl.acm.org/doi/10.1145/32…
7/


➡️ @johnjhorton on "Large Language Models as Simulated Economic Agents: What Can We Learn from Homo Silicus?"
📜: arxiv.org/abs/2301.07543
8/
📜: arxiv.org/abs/2301.07543
8/


As well as a panel on a variety of topics (organized by @Schropes) with several speakers: @_ziv_e @mattgroh @bcsaldias @trudypainter and our own instructor @hjian42 !
9/
9/

This course was designed and taught with my awesome fellow student co-instructors @Schropes @jad_kabbara @hjian42 @suyashfulay @dougb
🧵/
🧵/
• • •
Missing some Tweet in this thread? You can try to
force a refresh