#Day4 for Reporting "Crack SQL interview in 50Qs" is hear. Let's rumble
Find the links to the questions here
1. leetcode.com/problems/class…
2. leetcode.com/problems/find-…
3. leetcode.com/problems/bigge…
4.
leetcode.com/problems/rank-…
#SQL #DATAANALYSIS #Interviews #lowcode
Find the links to the questions here
1. leetcode.com/problems/class…
2. leetcode.com/problems/find-…
3. leetcode.com/problems/bigge…
4.
leetcode.com/problems/rank-…
#SQL #DATAANALYSIS #Interviews #lowcode
https://twitter.com/Toby_Davids/status/1666176244612841474

Let's break down each question
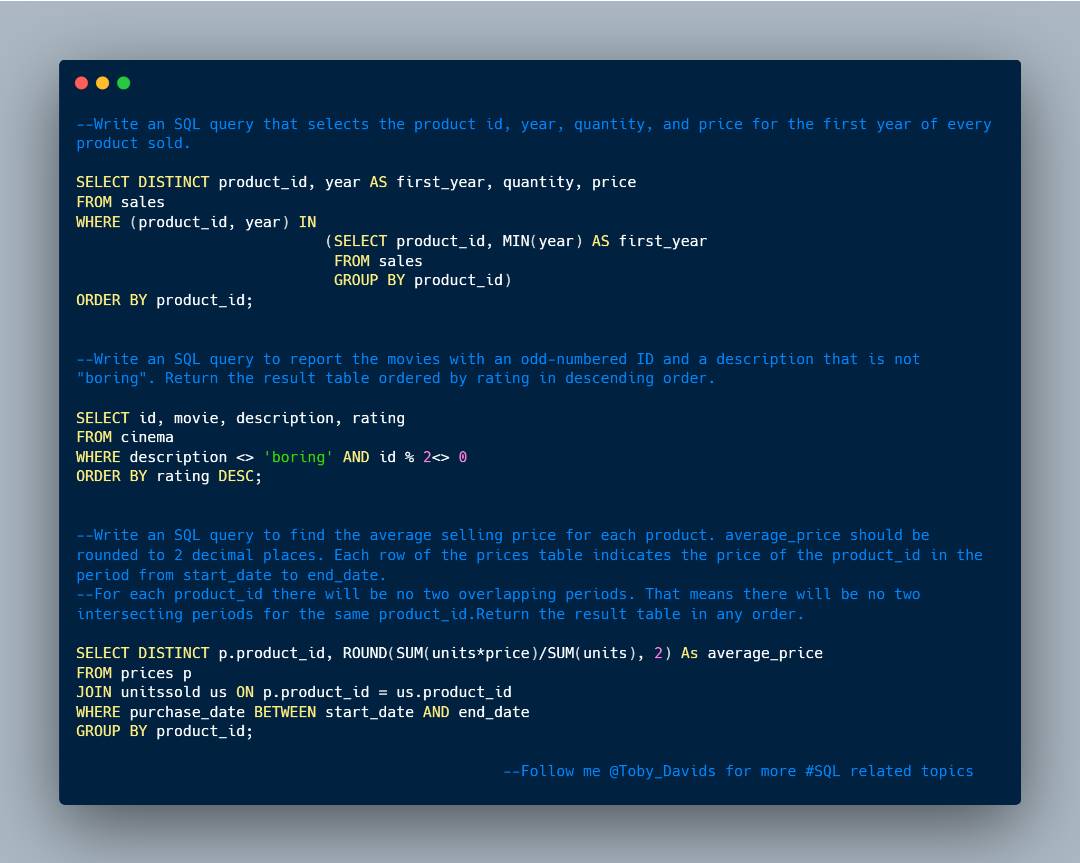
1. Logic: Show the classes, where the number of student is more than 5. The word "At least" tells us something, we have to include 5 as part of our filtering condition, hence >=5
2. This looks pretty straight forward. For each user, we want to....
1. Logic: Show the classes, where the number of student is more than 5. The word "At least" tells us something, we have to include 5 as part of our filtering condition, hence >=5
2. This looks pretty straight forward. For each user, we want to....
..return the number followers, hence the need to use the Group BY clause. This clause allows us to aggregate data against the unique categorical/qualitative values in a field.
3. The given SQL query finds the maximum value (num) from the "mynumbers" table that appears only once.
3. The given SQL query finds the maximum value (num) from the "mynumbers" table that appears only once.
It first identifies the numbers that occur exactly once by grouping and filtering, and then selects the maximum value from those numbers.
Approach
The query starts with the inner subquery (select num from mynumbers group by num having count(num) = 1) as n.
Approach
The query starts with the inner subquery (select num from mynumbers group by num having count(num) = 1) as n.
The subquery groups the numbers (num) from the "mynumbers" table and filters only those numbers that have a count of 1, meaning they appear only once.
The outer query selects the maximum value from the numbers obtained in the subquery using the MAX function and aliases it as num
The outer query selects the maximum value from the numbers obtained in the subquery using the MAX function and aliases it as num
The query retrieves the result, which is the maximum value (num) that appears only once.
4. This question requires the use of the Rank window function. Tbh, I'm always confused on how to differentiate Rank from Dense Rank, until I had to use the Olympics..
4. This question requires the use of the Rank window function. Tbh, I'm always confused on how to differentiate Rank from Dense Rank, until I had to use the Olympics..
Award/Podium ceremony for athletes. So, here's how I'll always remember. Dense rank takes the idea of the Olympics award/podium rankings. For instance, this occurs when 2 athletes gets tied on the silver medals. The next person gets the bronze medal or 3rd. I.e no position was...
Skipped. The Rank on the other hand is the opposite. The rank skips 2nd position/silver to the 4th position.
Back to our question. We were told to rank the scores. And if there is a tie between 2 scores, the next ranking number should be the next consecutive int. Value...
Back to our question. We were told to rank the scores. And if there is a tie between 2 scores, the next ranking number should be the next consecutive int. Value...
..indicating that we should not skip any number/position.
With our Olympic analogy, we should be confident to know we have to use the Dense rank function.
Thank you so much for staying till the end. 💛Merci.,
With our Olympic analogy, we should be confident to know we have to use the Dense rank function.
Thank you so much for staying till the end. 💛Merci.,
• • •
Missing some Tweet in this thread? You can try to
force a refresh