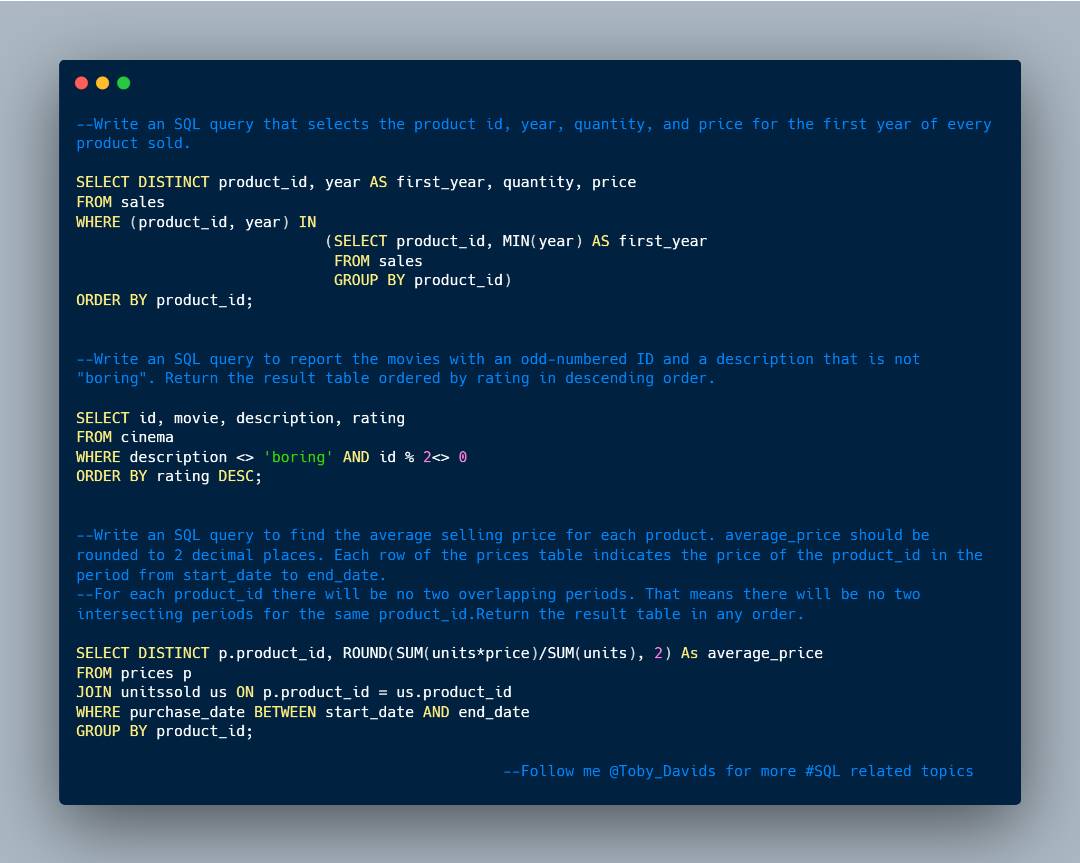
#Day5 for Reporting "Crack SQL interview in 50Qs" is hear. Let's rumble
Find the links to the questions here
1. leetcode.com/problems/the-n…
2. leetcode.com/problems/prima…
#SQL #DATAANALYSIS #Interviews #lowcode
Find the links to the questions here
1. leetcode.com/problems/the-n…
2. leetcode.com/problems/prima…
#SQL #DATAANALYSIS #Interviews #lowcode
https://twitter.com/Toby_Davids/status/1666596748905545729

Let's break them down:
1. Intuition
The query aims to retrieve information about managers in the Employees table, including their IDs, names, the number of employees reporting to them, and the average age of their reports.
1. Intuition
The query aims to retrieve information about managers in the Employees table, including their IDs, names, the number of employees reporting to them, and the average age of their reports.
The solution involves using a self join. Since we were told that a manager is also an employee, we will join the table to itself, where the employee_id field is equal reports_to field. On this premise, we aggregate the number of employees who report directly to the manager,
their average age, and names.
2. For the 2nd query, we employed a subquery in our Where clause to filter out those employees that were multiple departments, and the OR operator to ensure those with a primary flag have the 'Y' character. Finally, we select the employee_id...a
2. For the 2nd query, we employed a subquery in our Where clause to filter out those employees that were multiple departments, and the OR operator to ensure those with a primary flag have the 'Y' character. Finally, we select the employee_id...a
...and their respective departments from the employee table, that meets the criteria we had set.
Thank you so much for sticking with me 😌
💛. Merci
💛. Merci
• • •
Missing some Tweet in this thread? You can try to
force a refresh