
Musician, math lover, cook, dancer, 🏳️🌈, and an ass prof of Computer Science at New York University
 Why did I fail? I'm not that smart.
Why did I fail? I'm not that smart.

 Say x is a sentence of T words: x = {w₁, w₂, …, w_T}.
Say x is a sentence of T words: x = {w₁, w₂, …, w_T}.



 Here you can find the @MLStreetTalk's interview, where these topics are discussed in a conversational format.
Here you can find the @MLStreetTalk's interview, where these topics are discussed in a conversational format. «Graph Transformer Networks are deep learning architectures whose states are not tensors but graphs.
«Graph Transformer Networks are deep learning architectures whose states are not tensors but graphs.



 A GAN is simply a contrastive technique where a cost net C is trained to assign low energy to samples y (blue, cold 🥶, low energy) from the data set and high energy to contrastive samples ŷ (red, hot 🥵, where the “hat” points upward indicating high energy).
A GAN is simply a contrastive technique where a cost net C is trained to assign low energy to samples y (blue, cold 🥶, low energy) from the data set and high energy to contrastive samples ŷ (red, hot 🥵, where the “hat” points upward indicating high energy).



 Edit: updating a thumbnail and adding one more.
Edit: updating a thumbnail and adding one more.

 The classical definition of an encoder-decoder architecture is the autoencoder (AE). The (blue / cold / low-energy) target y is auto-encoded. (The AE slides are coming out later today.)
The classical definition of an encoder-decoder architecture is the autoencoder (AE). The (blue / cold / low-energy) target y is auto-encoded. (The AE slides are coming out later today.) 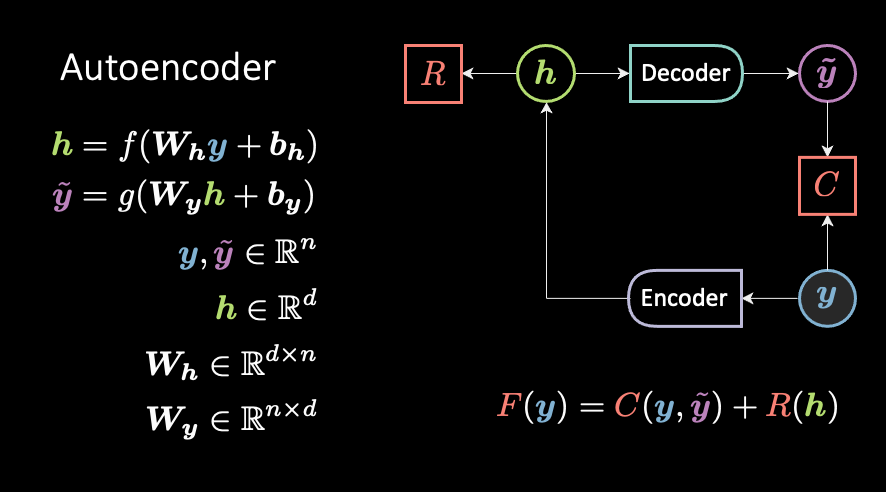



 Be careful with that thermostat! If it's gonna get too hot 🥵 you'll end up killing ☠️ your latents 👻 and end up with averaging them all out, indiscriminately, ending up with plain boring MSE (fig 1.3)! 🤒
Be careful with that thermostat! If it's gonna get too hot 🥵 you'll end up killing ☠️ your latents 👻 and end up with averaging them all out, indiscriminately, ending up with plain boring MSE (fig 1.3)! 🤒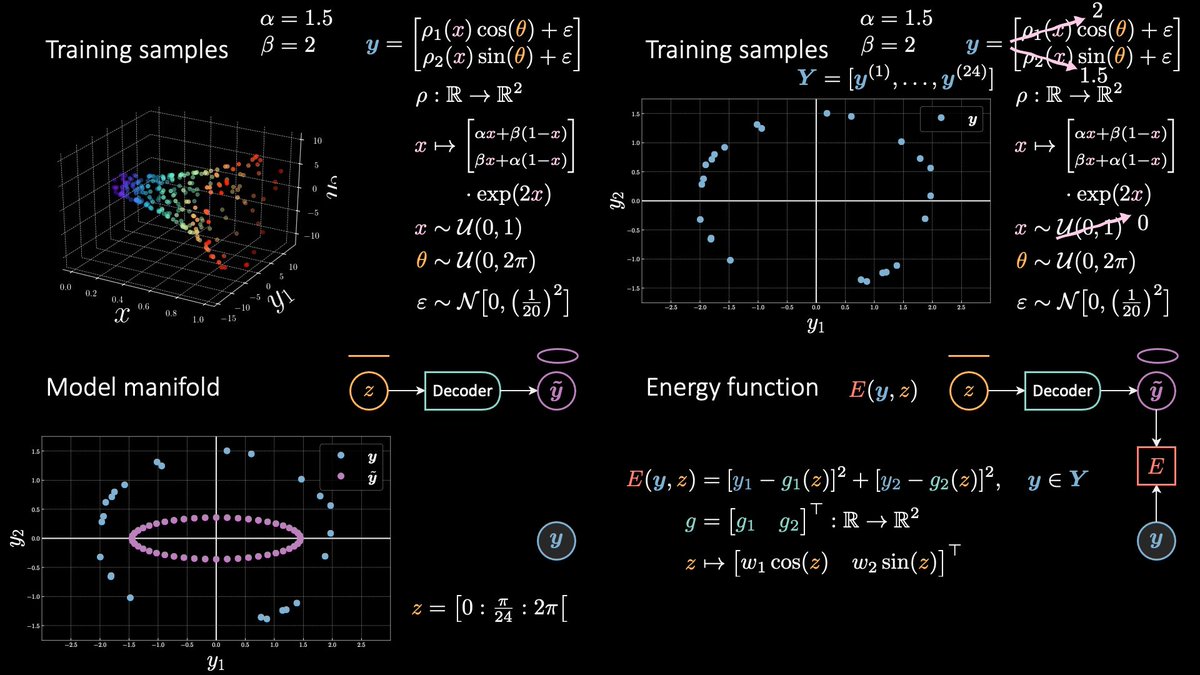


 Take the example of the horn 📯 (this time I drew it correctly, i.e. points do not lie on a grid 𐄳). Given an x there are multiple correct y's, actually, there is a whole ellipse (∞ nb of points) that's associated with it!
Take the example of the horn 📯 (this time I drew it correctly, i.e. points do not lie on a grid 𐄳). Given an x there are multiple correct y's, actually, there is a whole ellipse (∞ nb of points) that's associated with it! Summary of today's class.
Summary of today's class.

 This week's slides were quite dense, but we've been building up momentum since the beginning of class, 3 months ago.
This week's slides were quite dense, but we've been building up momentum since the beginning of class, 3 months ago.