
Guitarist, Researcher Google DeepMind. Opinions are my own.
@jesseengel.bsky.social
@jesseengel@sigmoid.social

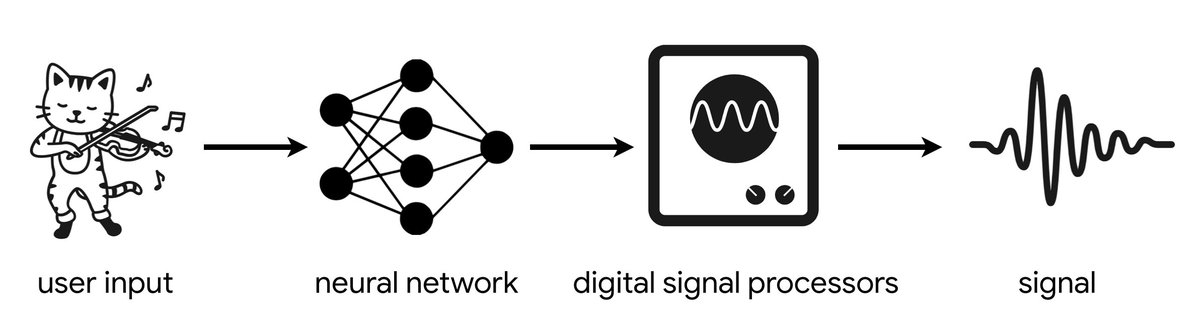 2/ tl; dr: We've made a library of differentiable DSP components (oscillators, filters, etc.) and show that it enables combining strong inductive priors with expressive neural networks, resulting in high-quality audio synthesis with less data, less compute, and fewer parameters.
2/ tl; dr: We've made a library of differentiable DSP components (oscillators, filters, etc.) and show that it enables combining strong inductive priors with expressive neural networks, resulting in high-quality audio synthesis with less data, less compute, and fewer parameters. 
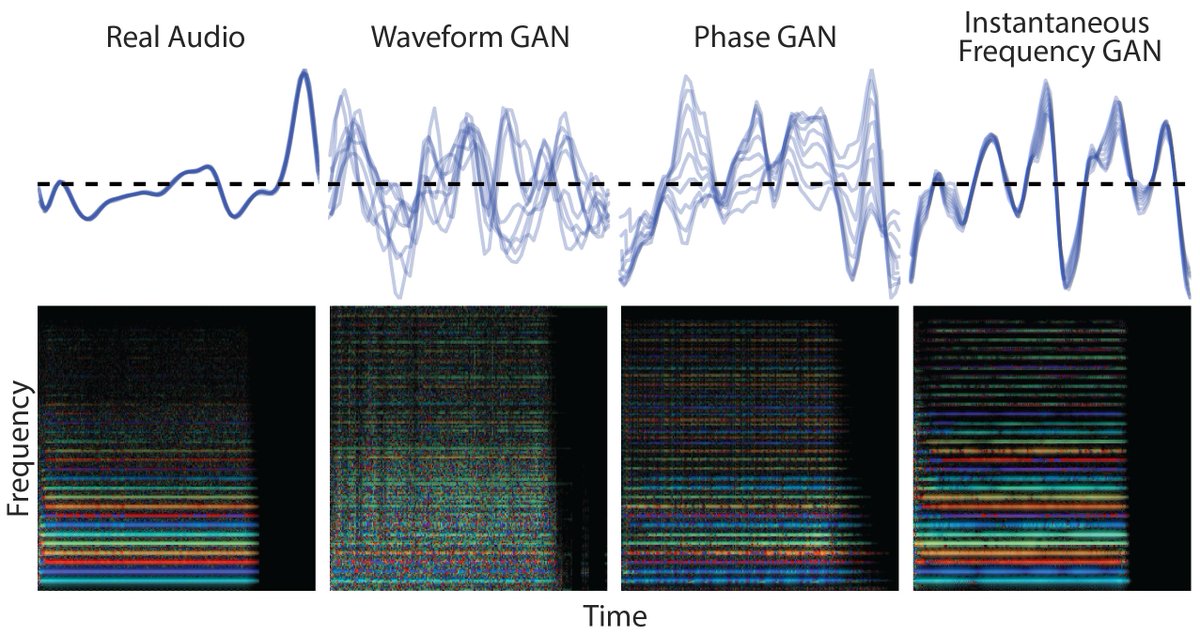 2/ tl; dr: We show that for musical instruments, we can generate audio ~50,000x faster than a standard WaveNet, with higher quality (both quantitative and listener tests), and have independent control of pitch and timbre, enabling smooth interpolation between instruments.
2/ tl; dr: We show that for musical instruments, we can generate audio ~50,000x faster than a standard WaveNet, with higher quality (both quantitative and listener tests), and have independent control of pitch and timbre, enabling smooth interpolation between instruments. 