
 Multilingual LLMs ≠ Native speakers
Multilingual LLMs ≠ Native speakers
 Our findings:
Our findings:
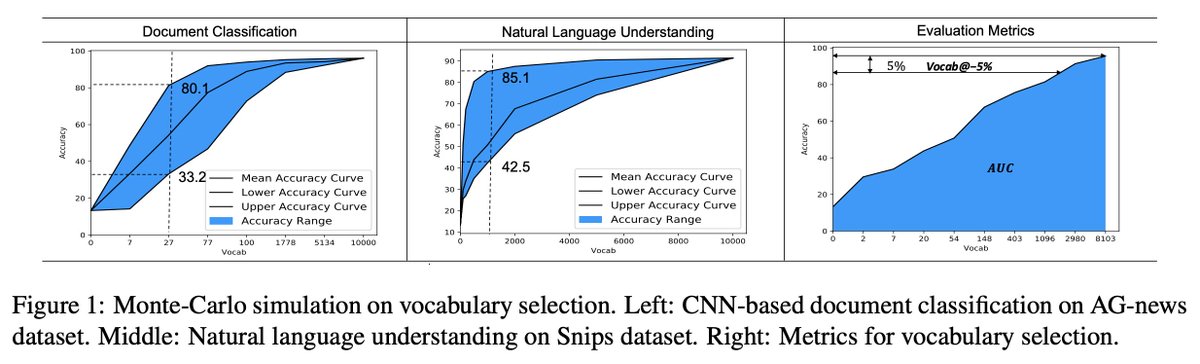
 Principle 2. How an algorithm scales is more important than its starting point. Avoid performance ceilings. Deep Learning is successful because it scales so effectively.
Principle 2. How an algorithm scales is more important than its starting point. Avoid performance ceilings. Deep Learning is successful because it scales so effectively.
 : "We should have more inductive biases. We are clueless about how to add inductive biases so we do dataset augmentation, create pseudo training data to encode those biases. Seems like a strange way to go about doing things."
: "We should have more inductive biases. We are clueless about how to add inductive biases so we do dataset augmentation, create pseudo training data to encode those biases. Seems like a strange way to go about doing things."