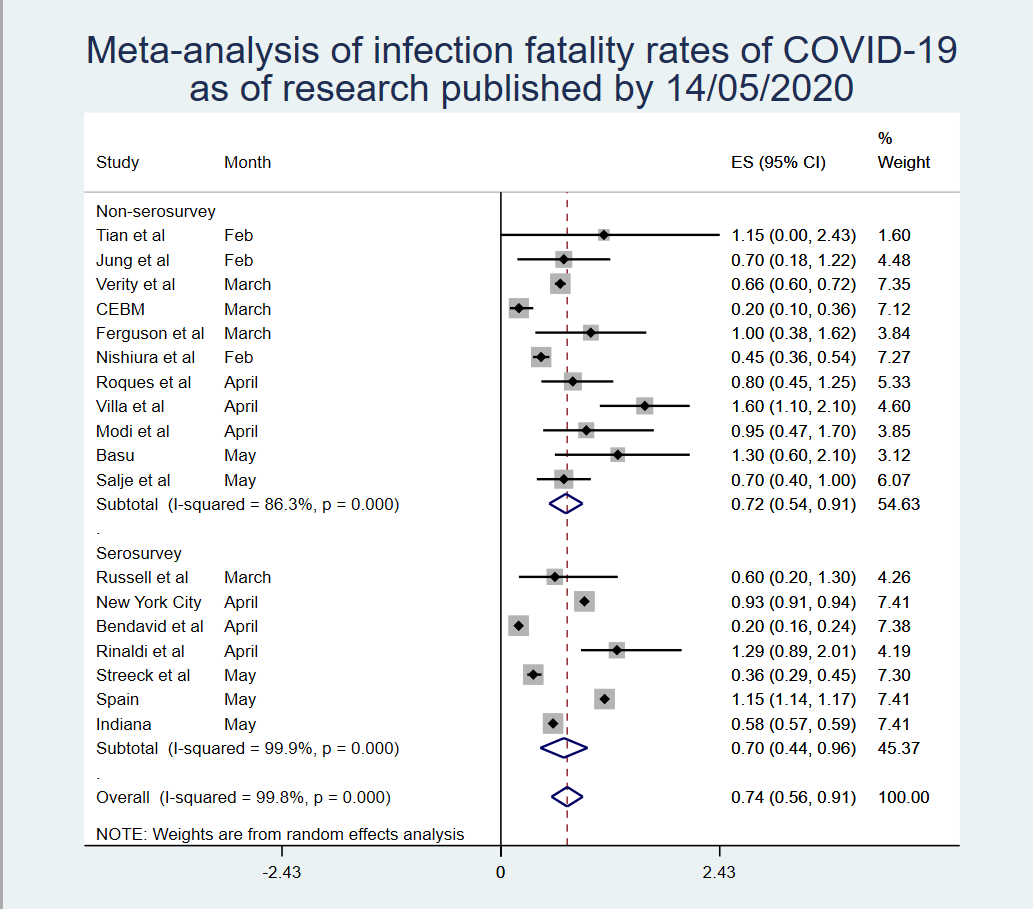
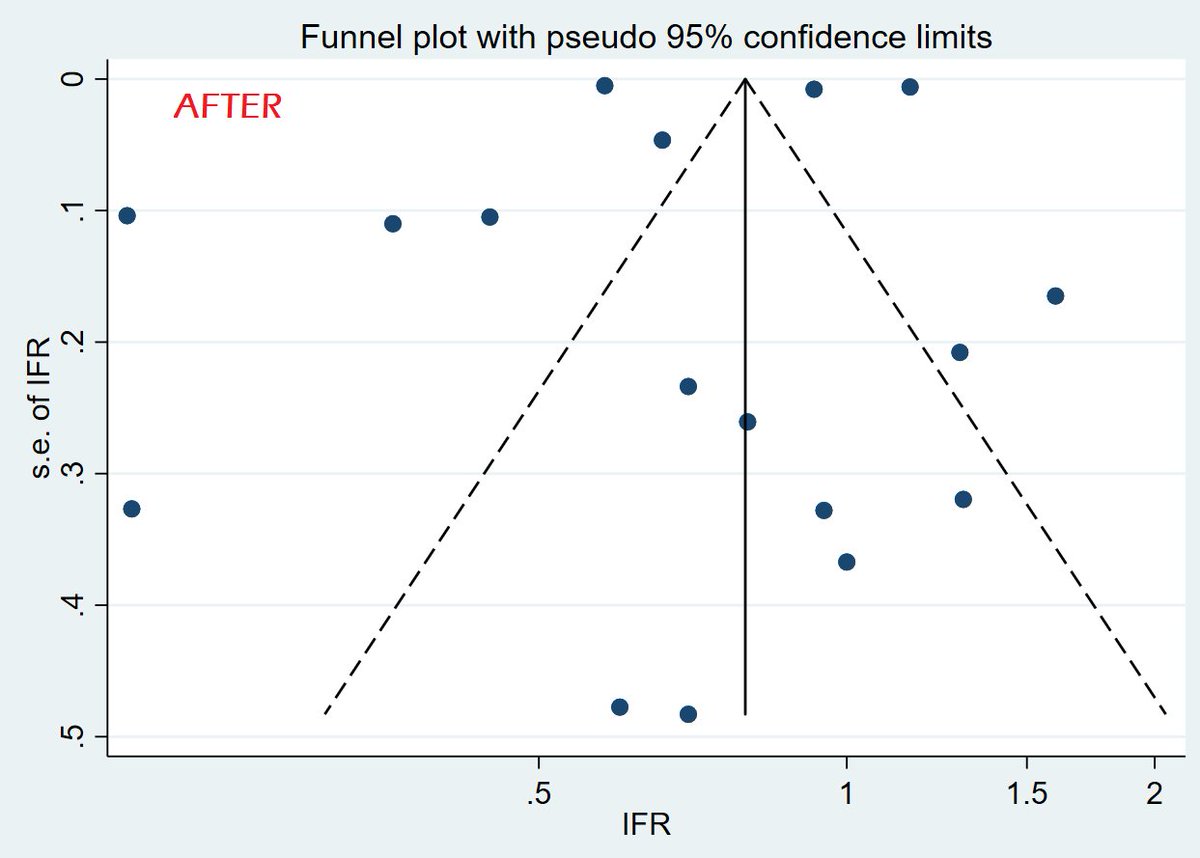
A lot of antibody surveillance results coming out at the moment, which gives us a chance to think about the fatality rate of #COVID19
But, there's a catch. Let's talk about right-censoring and why it's important 🧵
But, there's a catch. Let's talk about right-censoring and why it's important 🧵
The basic idea of right-censoring is simple: if someone leaves a study before their event happens, it's not counted and therefore the study's results are skewed 

Say we want to know the impact of smoking on lung cancer. We take two groups of 20 year olds who do and don't smoke and follow them up for 5 years
Say, 1,000 smokers and 1,000 non-smokers
Say, 1,000 smokers and 1,000 non-smokers
At the end of the study, 10 non-smokers and 11 smokers have developed lung cancer
The difference is non significant statistically
Does this mean that smoking isn't associated with lung cancer?
The difference is non significant statistically
Does this mean that smoking isn't associated with lung cancer?
Think about it - how many 30 years olds develop cancer by the age of 35?
Might this make our study's results biased towards a conclusion?
Might this make our study's results biased towards a conclusion?
The answer is...this study is probably wrong!
If we extend the timeline, and look at the LIFETIME risk of smoking for 30 year olds, suddenly there's a HUGE increase in the risk of lung cancer
If we extend the timeline, and look at the LIFETIME risk of smoking for 30 year olds, suddenly there's a HUGE increase in the risk of lung cancer
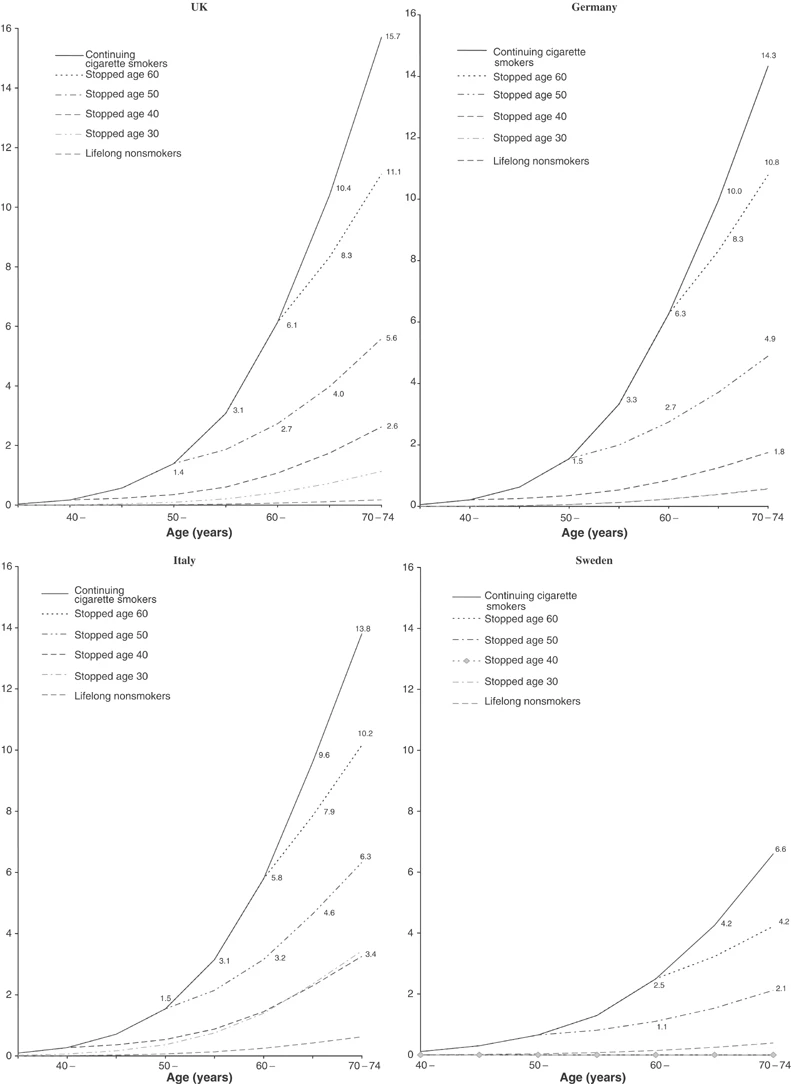
The problem is that initially, we stopped the clock BEFORE PEOPLE HAD THE OUTCOME WE ARE INTERESTED IN
This meant that the difference - even though it was there! - was impossible to see in our data
This meant that the difference - even though it was there! - was impossible to see in our data
That's right-censoring in a nutshell
If you stop counting results too early, suddenly your study has a significant bias (often towards low/no difference)
If you stop counting results too early, suddenly your study has a significant bias (often towards low/no difference)
What does this mean to antibody results for COVID-19?
Well, think about how these studies are conducted. We test a bunch of people randomly on day x to get an idea of how many people are immune to COVID-19 on that day
Well, think about how these studies are conducted. We test a bunch of people randomly on day x to get an idea of how many people are immune to COVID-19 on that day
Then, to calculate mortality, most people take the number of deaths on day x and divide by the denominator implied by the results
So, if we think 4% of 100,000 people have had COVID-19, and 10 of them have died on day x, we'd say that the infection-fatality rate is 10/4000 = 0.025%
BUT there's an issue here
People don't die from COVID-19 immediately. It usually takes somewhere between 15-20 days from when they get infected
The data is right-censored!
People don't die from COVID-19 immediately. It usually takes somewhere between 15-20 days from when they get infected
The data is right-censored!
There are probably a bunch of people who HAVE the disease on day x who are counted in our sample and will die but haven't yet!
So, what we SHOULD do in cases like these is either:
a) use a statistical model to account for this issue
b) wait a few weeks and use different death estimates to correct for potential right-censoring
a) use a statistical model to account for this issue
b) wait a few weeks and use different death estimates to correct for potential right-censoring
Instead, most people just take the proportion immune on day x and divide by deaths on the same day
This will almost certainly underestimate the 'true' infection-fatality rate, and is a big worry
This will almost certainly underestimate the 'true' infection-fatality rate, and is a big worry