=>
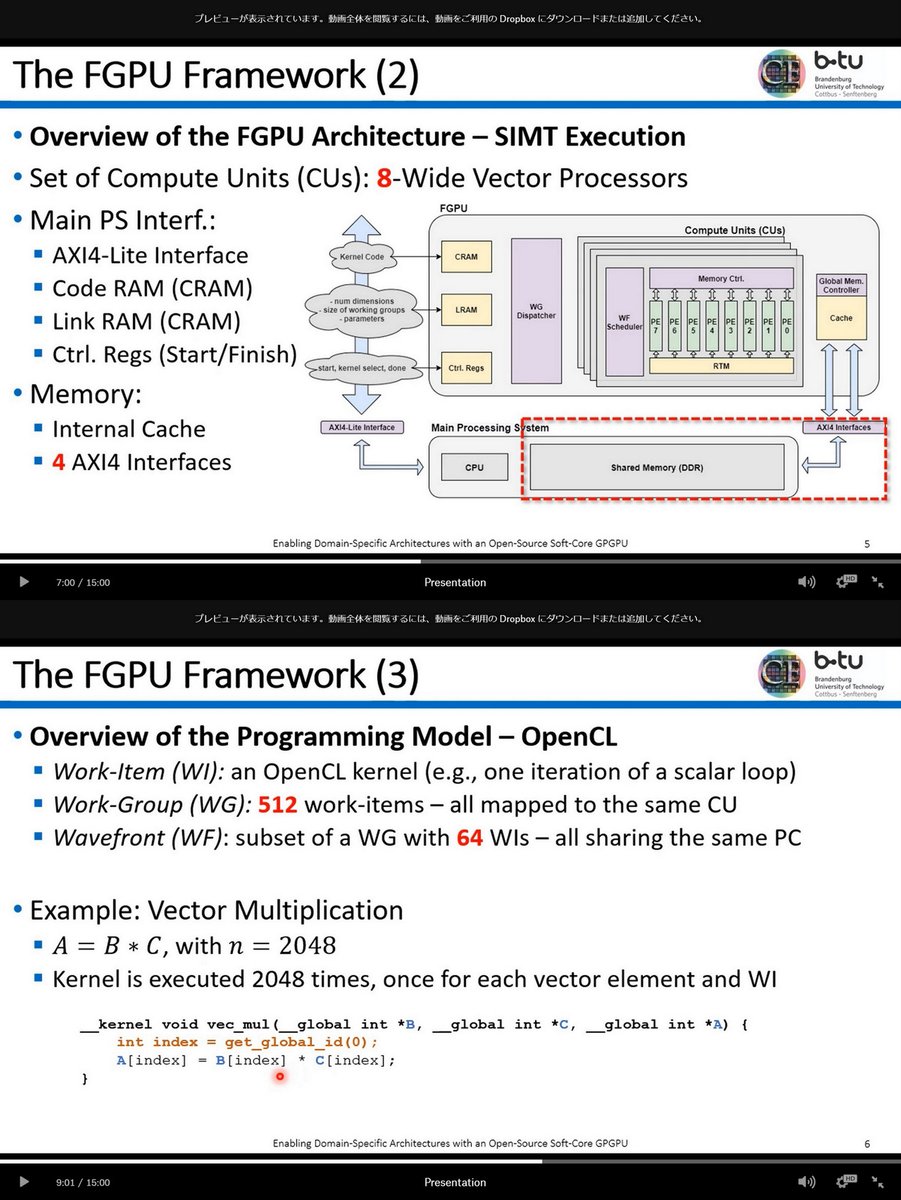
"Enabling Domain-Specific Architectures with an Open-Source Soft-Core GPGPU", Heterogeneity in Computing WS, May 18, 2020
Video dropbox.com/s/6hpq13kf262c…
Fully Customizable
Optimized for FPGA
github.com/mbrandalero/FG…
mbrandalero.github.io
FGPU, FPGA 2016 isfpga.org/fpga2016/index…
"Enabling Domain-Specific Architectures with an Open-Source Soft-Core GPGPU", Heterogeneity in Computing WS, May 18, 2020
Video dropbox.com/s/6hpq13kf262c…
Fully Customizable
Optimized for FPGA
github.com/mbrandalero/FG…
mbrandalero.github.io
FGPU, FPGA 2016 isfpga.org/fpga2016/index…



=>
"Acceleration of Structural Analysis Simulations using CNN-based Auto-Tuning of Solver Tolerance", Fujitsu and U of Tokyo, iWAPT 2020, May 22, 2020
MP4 iwapt.org/2020/upload/da…
Slides iwapt.org/2020/upload/da…
AI inside HPC simulation
Incorporate AI inference at minimal overhead
"Acceleration of Structural Analysis Simulations using CNN-based Auto-Tuning of Solver Tolerance", Fujitsu and U of Tokyo, iWAPT 2020, May 22, 2020
MP4 iwapt.org/2020/upload/da…
Slides iwapt.org/2020/upload/da…
AI inside HPC simulation
Incorporate AI inference at minimal overhead




=>
"CrypTFlow: Secure TensorFlow Inference", Microsoft Research, IEEE Symposium on Security and Privacy, May 2020
PDF microsoft.com/en-us/research…
Athos, Porthos, Aramis
EzPC (Easy Secure Multi-party Computation) microsoft.com/en-us/research…
github.com/mpc-msri/EzPC
"CrypTFlow: Secure TensorFlow Inference", Microsoft Research, IEEE Symposium on Security and Privacy, May 2020
PDF microsoft.com/en-us/research…
Athos, Porthos, Aramis
EzPC (Easy Secure Multi-party Computation) microsoft.com/en-us/research…
github.com/mpc-msri/EzPC




=>
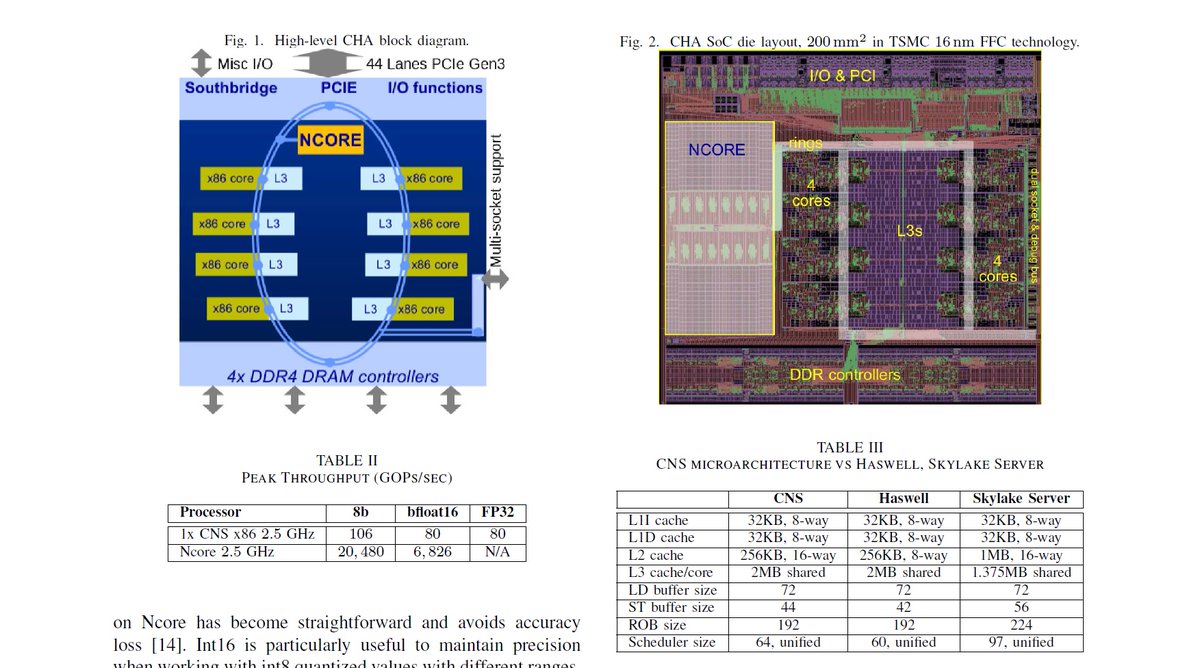
"High-Performance Deep-Learning Coprocessor Integrated into x86 SoC with Server-Class CPUs", Centaur Technology and Advantage Engineering, Industry Track, ISCA 2020 iscaconf.org/isca2020/paper…
Apr 2020
Glenn Henry, EE380, Feb 2020
"High-Performance Deep-Learning Coprocessor Integrated into x86 SoC with Server-Class CPUs", Centaur Technology and Advantage Engineering, Industry Track, ISCA 2020 iscaconf.org/isca2020/paper…
Apr 2020
https://twitter.com/ogawa_tter/status/1250389551949873154
Glenn Henry, EE380, Feb 2020
https://twitter.com/ogawa_tter/status/1230895504084492288



=>
"Embedded Computer Vision Hardware through the Eyes of AR/VR", Hans Reyserhove, Postdoctoral, FB Reality Labs, tinyML, May 14, 2020
tinyml.org/wp-content/upl…
PhD Thesis, 2018 limo.libis.be/primo-explore/…
AR glasses, Yann LeCun, Dec 2019
"Embedded Computer Vision Hardware through the Eyes of AR/VR", Hans Reyserhove, Postdoctoral, FB Reality Labs, tinyML, May 14, 2020
tinyml.org/wp-content/upl…
PhD Thesis, 2018 limo.libis.be/primo-explore/…
https://twitter.com/ogawa_tter/status/1232997316849590272
AR glasses, Yann LeCun, Dec 2019




=>
"Gamebreaker AI Effort Gets Under Way", May 13, 2020 darpa.mil/news-events/20…
"The AI used to break the first game will be tested on a second game."
StarCraft II & Google Research Football
SpringRTS: 1944 & OpenRA, etc.
Feb 2020
"Gamebreaker AI Effort Gets Under Way", May 13, 2020 darpa.mil/news-events/20…
"The AI used to break the first game will be tested on a second game."
StarCraft II & Google Research Football
SpringRTS: 1944 & OpenRA, etc.
Feb 2020
https://twitter.com/ogawa_tter/status/1226918628081074178




=>
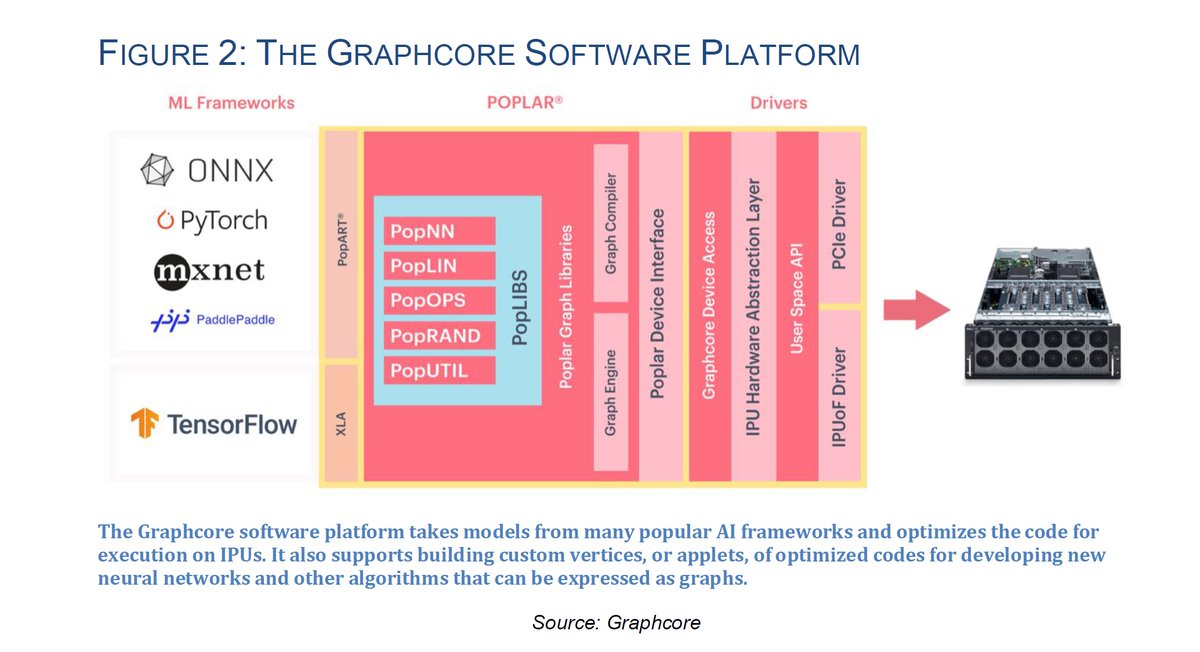
The @graphcoreai Software Stack: Built To Scale, Research Paper, Moor Insights & Strategy, May 2020, PDF moorinsightsstrategy.com/wp-content/upl…
Graphcore IPU (Dell DSS8440 Graphcore IPU Server)
Poplar SDK 1.1, Apr 2020
The @graphcoreai Software Stack: Built To Scale, Research Paper, Moor Insights & Strategy, May 2020, PDF moorinsightsstrategy.com/wp-content/upl…
Graphcore IPU (Dell DSS8440 Graphcore IPU Server)
https://twitter.com/ogawa_tter/status/1229494302549504000
Poplar SDK 1.1, Apr 2020
https://twitter.com/ogawa_tter/status/1250461202565566466

=>
"Using TensorFlow Lite for Microcontrollers for High-Efficiency NN Inference on Ultra-Low Power Processors", Synopsys, tinyML Talks, May 14, 2020
38;06
tinyml.org/wp-content/upl…
embARC embarc.org
Synopsys, May 27, 2020 news.synopsys.com/2020-05-27-Syn…
"Using TensorFlow Lite for Microcontrollers for High-Efficiency NN Inference on Ultra-Low Power Processors", Synopsys, tinyML Talks, May 14, 2020
38;06
tinyml.org/wp-content/upl…
embARC embarc.org
Synopsys, May 27, 2020 news.synopsys.com/2020-05-27-Syn…




=>
"ML for Systems and Chip Design", Azalia Mirhoseini & Anna Goldie, Google Brain, Guest Lecture. Data-Driven Algorithm Design, Caltech, May 28, 2020
1:02:49
drive.google.com/file/d/1xpZHX5…
arXiv
Google Blog, Apr 23 ai.googleblog.com/2020/04/chip-d…
"ML for Systems and Chip Design", Azalia Mirhoseini & Anna Goldie, Google Brain, Guest Lecture. Data-Driven Algorithm Design, Caltech, May 28, 2020
1:02:49
drive.google.com/file/d/1xpZHX5…
arXiv
https://twitter.com/ogawa_tter/status/1253170477943545857
Google Blog, Apr 23 ai.googleblog.com/2020/04/chip-d…



=>
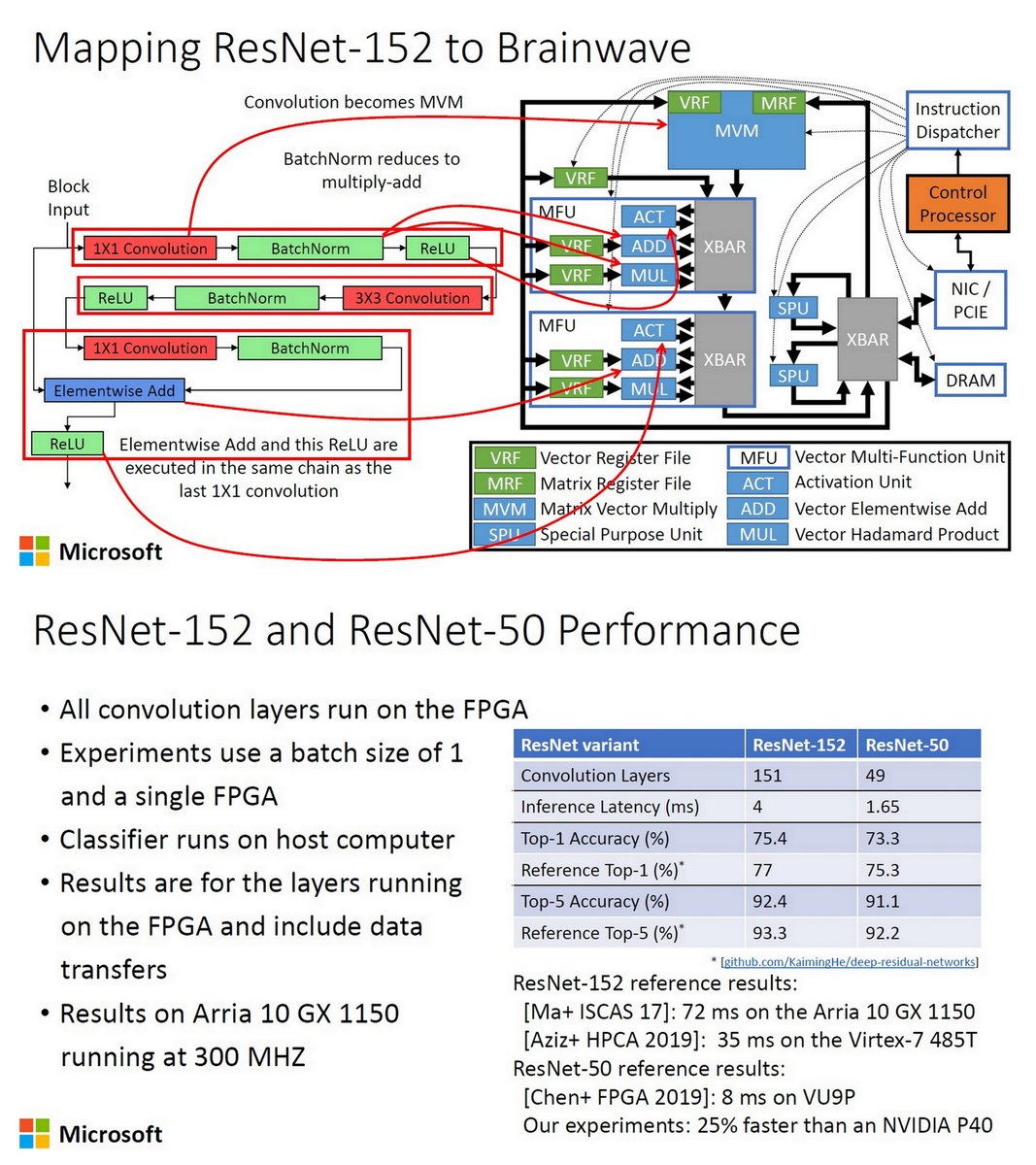
"Global-Scale FPGA-Accelerated Deep Learning Inference with Microsoft's Project Brainwave", The Future of FPGA-Acceleration in Cloud & DCs, FCCM 2020 WS, May 6, 2020 fccm.org/proceedings/20…
Brainwave Overlay Architecture
Mapping ResNet-152 to Brainwave
"Global-Scale FPGA-Accelerated Deep Learning Inference with Microsoft's Project Brainwave", The Future of FPGA-Acceleration in Cloud & DCs, FCCM 2020 WS, May 6, 2020 fccm.org/proceedings/20…
Brainwave Overlay Architecture
Mapping ResNet-152 to Brainwave
https://twitter.com/ogawa_tter/status/1245340188387098625



=>
"AI for Architecture: Principles and Prospects for the Next Paradigm", D. Penney and L. Chen, OSU, AIDArc 2020 (ISCA 2020), May 30, 2020 eecs.oregonstate.edu/aidarc/wp-cont…
55 pp
References Cited: 93
Additional References: 96
web.engr.oregonstate.edu/~chenliz/resea…
arXiv, Sep 2019
"AI for Architecture: Principles and Prospects for the Next Paradigm", D. Penney and L. Chen, OSU, AIDArc 2020 (ISCA 2020), May 30, 2020 eecs.oregonstate.edu/aidarc/wp-cont…
55 pp
References Cited: 93
Additional References: 96
web.engr.oregonstate.edu/~chenliz/resea…
arXiv, Sep 2019
https://twitter.com/ogawa_tter/status/1213828001256726535




=>
Timeloop/Accelergy Tutorial: Tools for Evaluating Deep Neural Network Accelerator Designs, ISCA 2020, May 29, 2020
Web accelergy.mit.edu/isca20_tutoria…
Video (1:55:42)
Timeloop, ISPASS 2019
Accelergy, ICCAD 2019
Timeloop/Accelergy Tutorial: Tools for Evaluating Deep Neural Network Accelerator Designs, ISCA 2020, May 29, 2020
Web accelergy.mit.edu/isca20_tutoria…
Video (1:55:42)
Timeloop, ISPASS 2019
https://twitter.com/ogawa_tter/status/1104662885370802178
Accelergy, ICCAD 2019
https://twitter.com/ogawa_tter/status/1194688956308180992




=>
"MN-3が動き出します"、2020年6月1日 tech.preferred.jp/ja/blog/mn-3-l…
Making of PFN's MN-3 supercomputer, PFN, Jun 1, 2020
MN-Coreについて、2019年2月2日
Interconnect card (Xilinx FPGA), Kei Hiraki, XDF 2019, Oct 2019
"MN-3が動き出します"、2020年6月1日 tech.preferred.jp/ja/blog/mn-3-l…
Making of PFN's MN-3 supercomputer, PFN, Jun 1, 2020
MN-Coreについて、2019年2月2日
https://twitter.com/ogawa_tter/status/1093063406490345477
Interconnect card (Xilinx FPGA), Kei Hiraki, XDF 2019, Oct 2019
https://twitter.com/ogawa_tter/status/1218145529600692224




=>
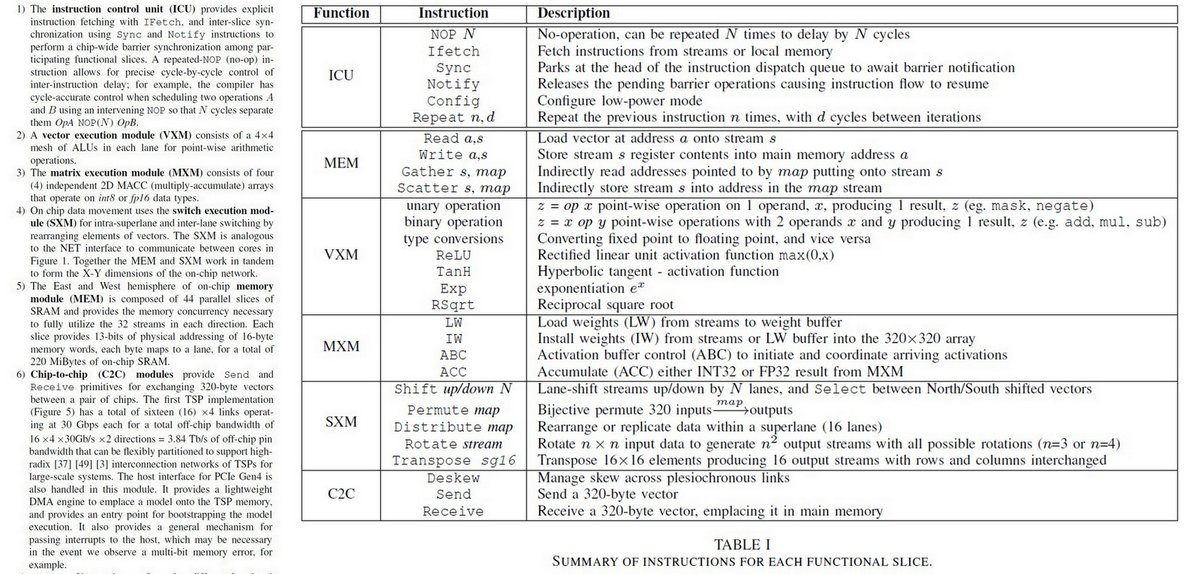
"Think Fast: A Tensor Streaming Processor (TSP) for Accelerating Deep Learning Workloads", Dennis Abts, et al., @GroqInc , ISCA 2020 iscaconf.org/isca2020/paper…
1 TeraOp/s per square mm, 25×29 mm 14nm
900 MHz
Patent Appl, Mar 2020
Challenge of Batch Size 1
"Think Fast: A Tensor Streaming Processor (TSP) for Accelerating Deep Learning Workloads", Dennis Abts, et al., @GroqInc , ISCA 2020 iscaconf.org/isca2020/paper…
1 TeraOp/s per square mm, 25×29 mm 14nm
900 MHz
Patent Appl, Mar 2020
https://twitter.com/ogawa_tter/status/1262142875669757955
Challenge of Batch Size 1



=>
State-of-the-Art on Neural Rendering, STAR (State of The Art Report), Eurographics 2020, May 27, 2020
PDF (27 MB) diglib.eg.org/bitstream/hand…
Learning Generative Models, Tutorials, Eurographics 2019
CreativeAI geometry.cs.ucl.ac.uk/creativeai/
State-of-the-Art on Neural Rendering, STAR (State of The Art Report), Eurographics 2020, May 27, 2020
PDF (27 MB) diglib.eg.org/bitstream/hand…
Learning Generative Models, Tutorials, Eurographics 2019
https://twitter.com/ogawa_tter/status/1132920690028363777
CreativeAI geometry.cs.ucl.ac.uk/creativeai/


=>
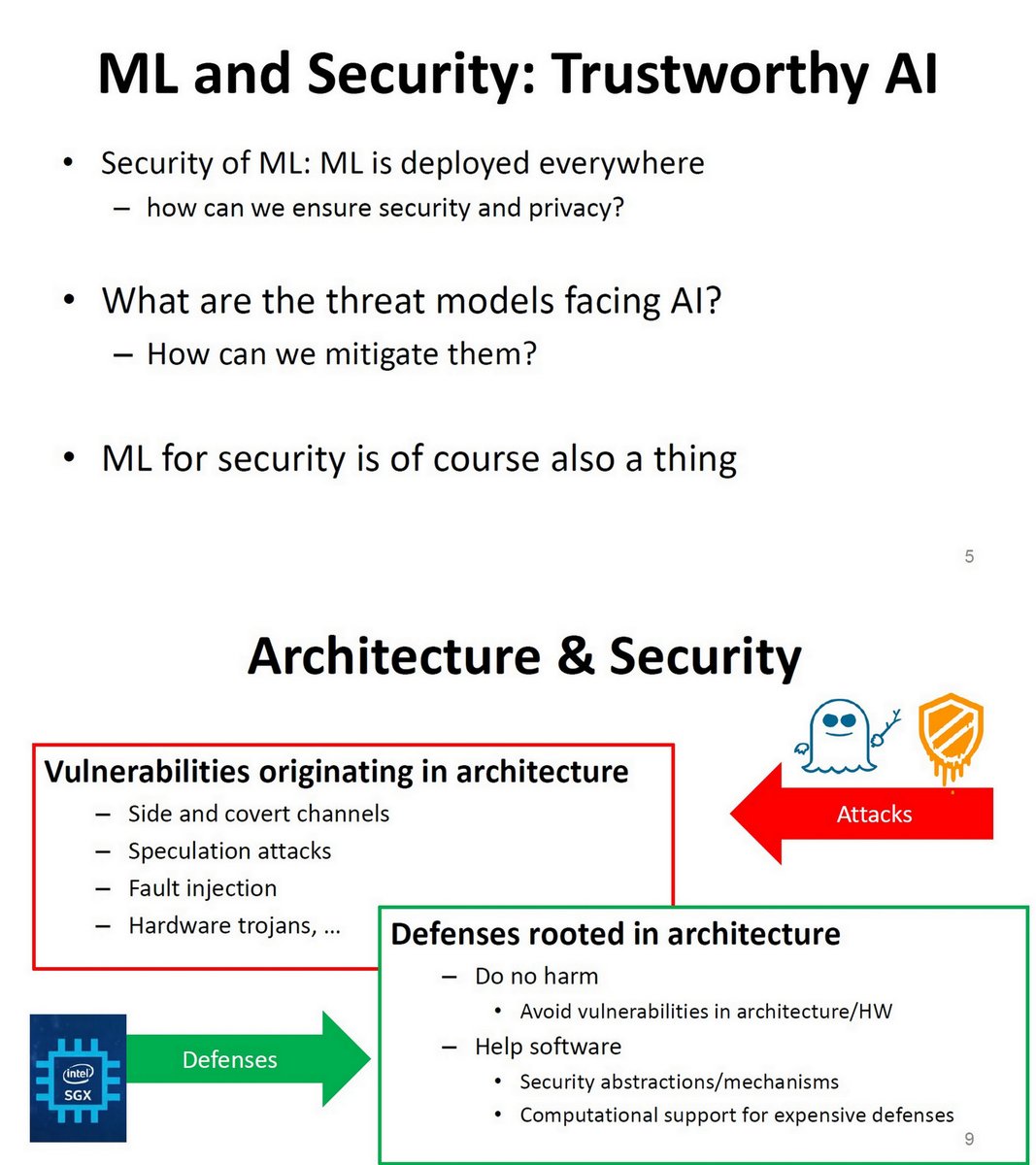
"Securing Architecture Supported ML systems ", Nael Abu-Ghazaleh, UC Riverside, Keynote, AIDArc 2020, PDF eecs.oregonstate.edu/aidarc/wp-cont…
Intersection of ML/AI, Arch and Security
Three examples
cs.ucr.edu/~nael/
"Securing Architecture Supported ML systems ", Nael Abu-Ghazaleh, UC Riverside, Keynote, AIDArc 2020, PDF eecs.oregonstate.edu/aidarc/wp-cont…
Intersection of ML/AI, Arch and Security
Three examples
cs.ucr.edu/~nael/


=>
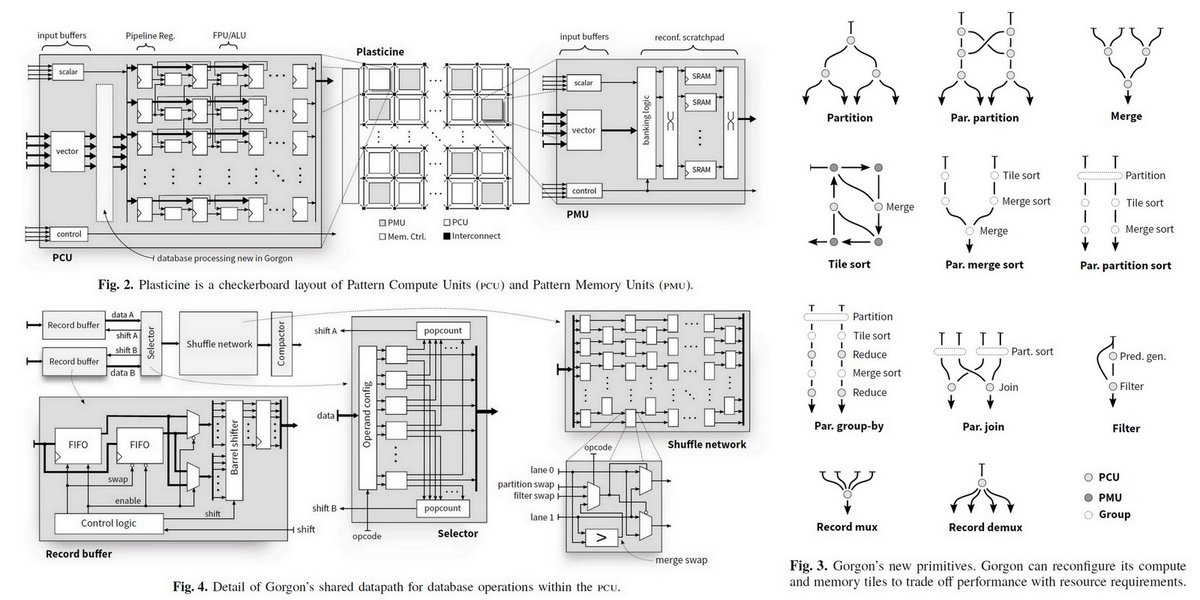
"Gorgon: Accelerating Machine Learning from Relational Data", ..., Kunle Olukotun, Stanford, ISCA 2020, PDF iscaconf.org/isca2020/paper…
Unified data analysis CGRA for In-DB ML
Plasticine
"Democratizing AI", Kunle Olukotun, Nov 2019
"Gorgon: Accelerating Machine Learning from Relational Data", ..., Kunle Olukotun, Stanford, ISCA 2020, PDF iscaconf.org/isca2020/paper…
Unified data analysis CGRA for In-DB ML
Plasticine
https://twitter.com/ogawa_tter/status/1078063540869582848
"Democratizing AI", Kunle Olukotun, Nov 2019
https://twitter.com/ogawa_tter/status/1195431844512055296



=>
A 0.32-128 TOPS, Scalable McM-based DNN Inference Accelerator with GRS in 16nm, NVIDIA, IEEE JSSCC, Apr 2020 people.eecs.berkeley.edu/~ysshao/assets…
Simba (Best Paper)
B. Zimmer:
Analog and In-memory Computing,
ISSCC 2020
A 0.32-128 TOPS, Scalable McM-based DNN Inference Accelerator with GRS in 16nm, NVIDIA, IEEE JSSCC, Apr 2020 people.eecs.berkeley.edu/~ysshao/assets…
Simba (Best Paper)
https://twitter.com/ogawa_tter/status/1184113161378467840
B. Zimmer:
Analog and In-memory Computing,
https://twitter.com/ogawa_tter/status/1252927368521347072
ISSCC 2020
https://twitter.com/ogawa_tter/status/1252692938259218432




=>
"Elastic Machine Learning Algorithms in Amazon SageMaker", Amazon AI, Industrial Papers, SIGMOD 2020, Jun 2020, PDF edoliberty.github.io/papers/sagemak…
Edo Liberty edoliberty.github.io
Alex Smola scholar.google.com.au/citations?hl=j…
aws.amazon.com/sagemaker/
AWS re:Invent 2019
"Elastic Machine Learning Algorithms in Amazon SageMaker", Amazon AI, Industrial Papers, SIGMOD 2020, Jun 2020, PDF edoliberty.github.io/papers/sagemak…
Edo Liberty edoliberty.github.io
Alex Smola scholar.google.com.au/citations?hl=j…
aws.amazon.com/sagemaker/
AWS re:Invent 2019
https://twitter.com/ogawa_tter/status/1209411976427782147




=>
"Stochastic Computing for Machine Learning towards an Intelligent Edge", Invited, Edge Intelligence WS, Mar 3, 2020 drive.google.com/file/d/1ZEt3w-…
isip.ece.mcgill.ca/index.html
VLSI Implementation ieeexplore.ieee.org/abstract/docum…
2019 link.springer.com/book/10.1007%2…
Survey, May 2013
"Stochastic Computing for Machine Learning towards an Intelligent Edge", Invited, Edge Intelligence WS, Mar 3, 2020 drive.google.com/file/d/1ZEt3w-…
isip.ece.mcgill.ca/index.html
VLSI Implementation ieeexplore.ieee.org/abstract/docum…
2019 link.springer.com/book/10.1007%2…
Survey, May 2013
https://twitter.com/ogawa_tter/status/996001616368095233




=>
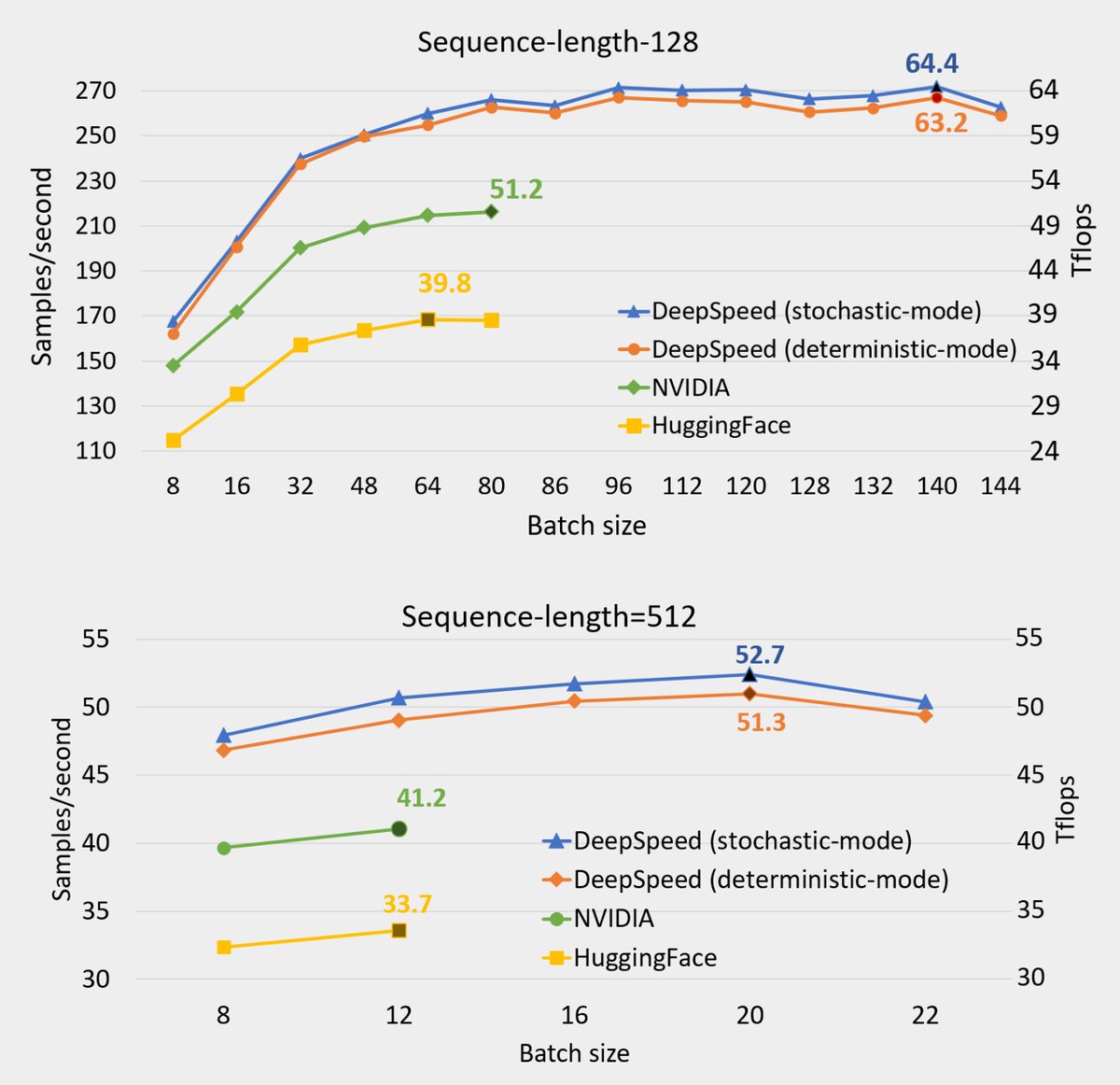
"Microsoft DeepSpeed achieves the fastest BERT training time", May 27, 2020 deepspeed.ai/news/2020/05/2…
44 min on 1024 NVIDIA V100 GPU (64 DGX-2)
64 TF of single GPU performance on a NVIDIA V100 GPU (50% of the hardware peak)
Stochastic transformer
Overlapping I/O with Computation
"Microsoft DeepSpeed achieves the fastest BERT training time", May 27, 2020 deepspeed.ai/news/2020/05/2…
44 min on 1024 NVIDIA V100 GPU (64 DGX-2)
64 TF of single GPU performance on a NVIDIA V100 GPU (50% of the hardware peak)
Stochastic transformer
Overlapping I/O with Computation

=>
"An Overview of Resource-Efficiency in Deep Learning", Workshop on Embedded Machine Learning, Feb 13, 2020 drive.google.com/file/d/1Zst2Q9…
Quantized Neural Networks
Network Pruning
Structural Efficiency
arXiv, Jan 7, 2020 arxiv.org/abs/2001.03048
Overview of the vast literature
"An Overview of Resource-Efficiency in Deep Learning", Workshop on Embedded Machine Learning, Feb 13, 2020 drive.google.com/file/d/1Zst2Q9…
Quantized Neural Networks
Network Pruning
Structural Efficiency
arXiv, Jan 7, 2020 arxiv.org/abs/2001.03048
Overview of the vast literature




=>
Dive into Deep Learning d2l.ai
An interactive deep learning book with code, math, and discussions
Provides both NumPy/MXNet and PyTorch implementations
github.com/d2l-ai/d2l-en
Book, Release 0.8.0, Jun 4, 2020, PDF (31 MB / 992 pages) d2l.ai/d2l-en.pdf
Dive into Deep Learning d2l.ai
An interactive deep learning book with code, math, and discussions
Provides both NumPy/MXNet and PyTorch implementations
github.com/d2l-ai/d2l-en
Book, Release 0.8.0, Jun 4, 2020, PDF (31 MB / 992 pages) d2l.ai/d2l-en.pdf




=>
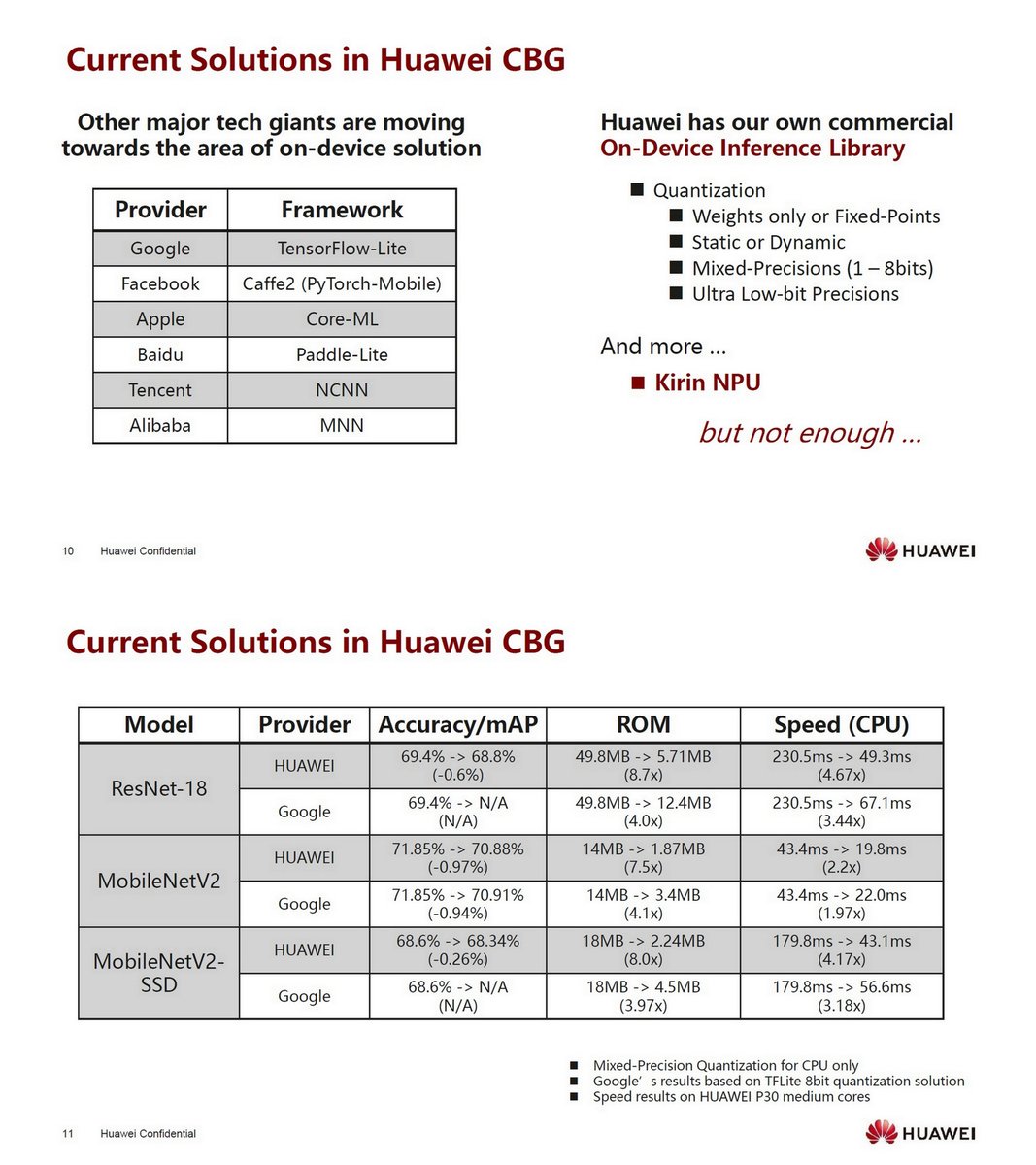
"On-Device AI: Bringing AI Closer to Consumers", Huawei Montreal Research Center, Edge Intelligence WS, Mar 3, 2020 drive.google.com/file/d/1JRqDnP…
Kirin, HiSilicon hisilicon.com/en/Products/Pr…
Kirin 990 and Kirin 990 5G, Sep 2019 anandtech.com/show/14851/hua…
DaVinci
"On-Device AI: Bringing AI Closer to Consumers", Huawei Montreal Research Center, Edge Intelligence WS, Mar 3, 2020 drive.google.com/file/d/1JRqDnP…
Kirin, HiSilicon hisilicon.com/en/Products/Pr…
Kirin 990 and Kirin 990 5G, Sep 2019 anandtech.com/show/14851/hua…
DaVinci
https://twitter.com/ogawa_tter/status/1205326982361145345



=>
NSF Funds $5M Neocortex, a Groundbreaking AI Supercomputer, at PSC, Jun 9, 2020 psc.edu/news-publicati…
Two Cerebras CS-1 AI servers
An shared-memory HPE Superdome Flex
Cerebras cerebras.net/pittsburgh-sup…
hpcwire.com/2020/06/09/neo…
PSC will present a tutorial on AI HW at PEARC
NSF Funds $5M Neocortex, a Groundbreaking AI Supercomputer, at PSC, Jun 9, 2020 psc.edu/news-publicati…
Two Cerebras CS-1 AI servers
An shared-memory HPE Superdome Flex
Cerebras cerebras.net/pittsburgh-sup…
hpcwire.com/2020/06/09/neo…
PSC will present a tutorial on AI HW at PEARC
=>
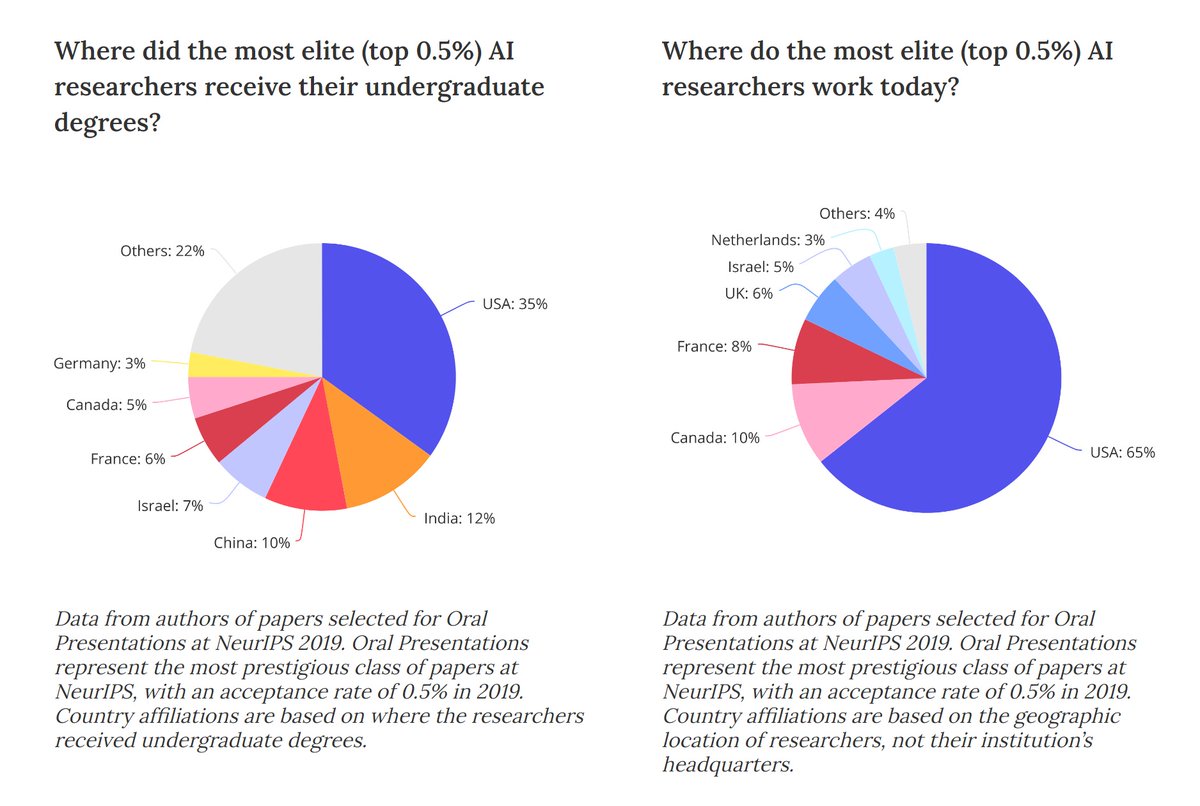
"America's Got AI Talent: US' Big Lead in AI Research Is Built on Importing Researchers", Jun 9 2020 macropolo.org/americas-got-a…
Global AI Talent Tracker macropolo.org/digital-projec…
"Chinese AI Talent in Six Charts", May 29, 2019 macropolo.org/china-ai-resea…
ChinAI macropolo.org/digital-projec…
"America's Got AI Talent: US' Big Lead in AI Research Is Built on Importing Researchers", Jun 9 2020 macropolo.org/americas-got-a…
Global AI Talent Tracker macropolo.org/digital-projec…
"Chinese AI Talent in Six Charts", May 29, 2019 macropolo.org/china-ai-resea…
ChinAI macropolo.org/digital-projec…


=>
"IBM CEO's Letter to Congress on Racial Justice Reform", Jun 9, 2020 ibm.com/blogs/policy/f…
" IBM has sunset its general purpose facial recognition and analysis software products."
Letter, PDF ibm.com/blogs/policy/w…
Policy letter # 4, Sep 1953 IBM 100 ibm.com/ibm/history/ib…
"IBM CEO's Letter to Congress on Racial Justice Reform", Jun 9, 2020 ibm.com/blogs/policy/f…
" IBM has sunset its general purpose facial recognition and analysis software products."
Letter, PDF ibm.com/blogs/policy/w…
Policy letter # 4, Sep 1953 IBM 100 ibm.com/ibm/history/ib…



=>
"The race to develop AI chips heats up as Graphcore says it's shipped ‘tens of thousands’", Jun 9, 2020 cnbc.com/2020/06/09/gra…
Nigel Toon, co-founder & CEO
as opposed to the hundreds of thousands
100+ organizations
MS, Nov 2019
"The race to develop AI chips heats up as Graphcore says it's shipped ‘tens of thousands’", Jun 9, 2020 cnbc.com/2020/06/09/gra…
Nigel Toon, co-founder & CEO
as opposed to the hundreds of thousands
100+ organizations
MS, Nov 2019
https://twitter.com/ogawa_tter/status/1194672571712557057
https://twitter.com/ogawa_tter/status/1266314894254587904
=>
"Using Libfabric for Scalable Distributed Machine Learning: Use cases, Learnings, and Best Practices", AWS, OFA Virtual WS, Jun 8, 2020
34:25
openfabrics.org/wp-content/upl…
Elastic Fabric Adapter on AWS
EFA, Webinars, AWS re:Invent 2019
"Using Libfabric for Scalable Distributed Machine Learning: Use cases, Learnings, and Best Practices", AWS, OFA Virtual WS, Jun 8, 2020
34:25
openfabrics.org/wp-content/upl…
Elastic Fabric Adapter on AWS
EFA, Webinars, AWS re:Invent 2019
https://twitter.com/ogawa_tter/status/1209807105164603392



=>
"We are implementing a one-year moratorium on police use of Rekognition (facial recognition technology)", Amazon Blog, Jun 10, 2020 blog.aboutamazon.com/policy/we-are-…
".. will continue to allow organizations like Thorn, the International Center for Missing and Exploited Children, and .."
"We are implementing a one-year moratorium on police use of Rekognition (facial recognition technology)", Amazon Blog, Jun 10, 2020 blog.aboutamazon.com/policy/we-are-…
".. will continue to allow organizations like Thorn, the International Center for Missing and Exploited Children, and .."
=>
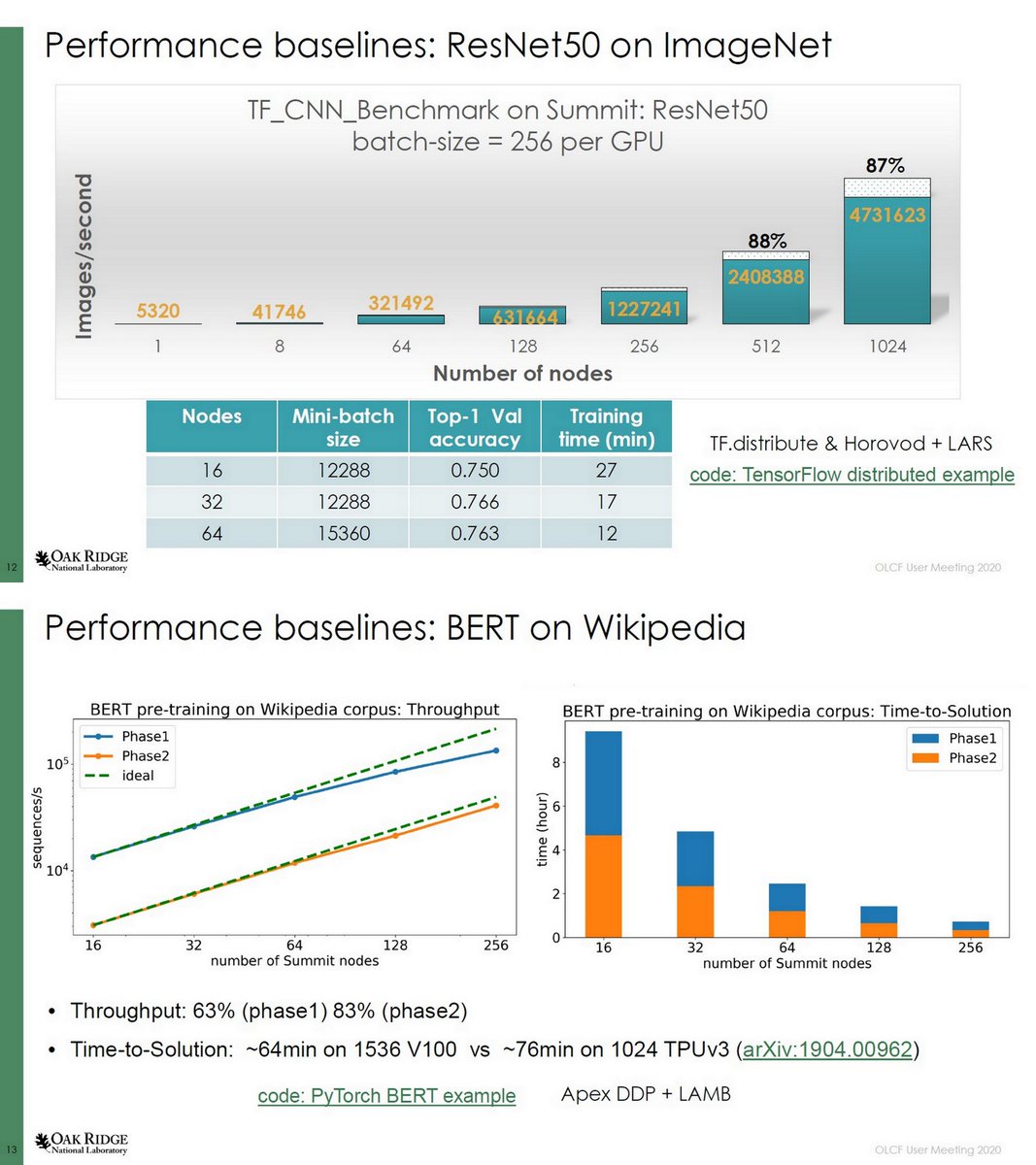
OLCF User Meeting, Jun 3, 2020
Machine Learning/Deep Learning on Summit
31:16 vimeo.com/427791205
olcf.ornl.gov/wp-content/upl…
Summit Burst Buffe
13;36 vimeo.com/427790836
olcf.ornl.gov/wp-content/upl…
Burst Buffer on Summit
10.06 vimeo.com/427792243
olcf.ornl.gov/wp-content/upl…
OLCF User Meeting, Jun 3, 2020
Machine Learning/Deep Learning on Summit
31:16 vimeo.com/427791205
olcf.ornl.gov/wp-content/upl…
Summit Burst Buffe
13;36 vimeo.com/427790836
olcf.ornl.gov/wp-content/upl…
Burst Buffer on Summit
10.06 vimeo.com/427792243
olcf.ornl.gov/wp-content/upl…



=>
"Neural forecasting: Introduction and literature overview", Amazon Research, arXiv, Apr 21, 2020 arxiv.org/abs/2004.10240
Introduction
A brief history of NNs
An overview of modern NNs
Neural forecasting models
Applications
A look into the future
Conclusions
66 pp
206 references
"Neural forecasting: Introduction and literature overview", Amazon Research, arXiv, Apr 21, 2020 arxiv.org/abs/2004.10240
Introduction
A brief history of NNs
An overview of modern NNs
Neural forecasting models
Applications
A look into the future
Conclusions
66 pp
206 references


=>
"Resilient Neural Forecasting Systems", Amazon Research, DEEM: WS on Data Management for End-to-End Machine Learning, @ ACM SIGMOD 2020
MP4 (12:02) deem-workshop.org/videos/2020/11…
"Neural forecasting: Introduction and literature overview", arXiv, Apr 21, 2020
"Resilient Neural Forecasting Systems", Amazon Research, DEEM: WS on Data Management for End-to-End Machine Learning, @ ACM SIGMOD 2020
MP4 (12:02) deem-workshop.org/videos/2020/11…
"Neural forecasting: Introduction and literature overview", arXiv, Apr 21, 2020
https://twitter.com/ogawa_tter/status/1272369954847744000


=>
"A 3.0 TFLOPS 0.62V Scalable Processor Core for High Compute Utilization AI Training and Inference", IBM T. J. Watson Research, VLSI 2020
Program vlsisymposium.org/wp-content/upl…
Highlights vlsisymposium.org/wp-content/upl…
DLFloat16, ARITH 2019 ieeexplore.ieee.org/document/88774…
"A 3.0 TFLOPS 0.62V Scalable Processor Core for High Compute Utilization AI Training and Inference", IBM T. J. Watson Research, VLSI 2020
Program vlsisymposium.org/wp-content/upl…
Highlights vlsisymposium.org/wp-content/upl…
DLFloat16, ARITH 2019 ieeexplore.ieee.org/document/88774…
https://twitter.com/ogawa_tter/status/1144158015349612544

=>
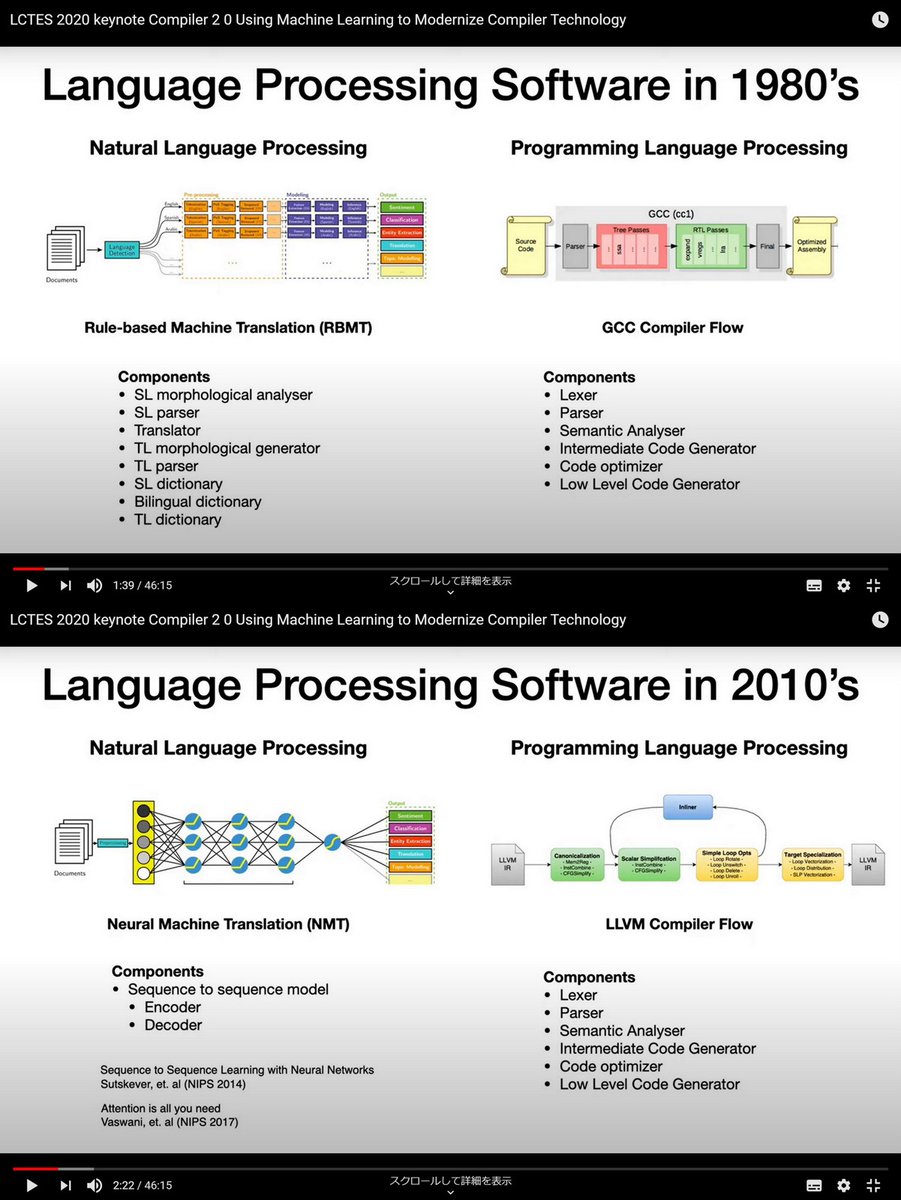
"Compiler 2 0 Using Machine Learning to Modernize Compiler Technology", Saman Amarasinghe, MIT, Keynote, LCTES 2020, Jun 16, 2020
46:15
people.csail.mit.edu/saman/
Commit groups.csail.mit.edu/commit/
Automatic Tuning of Compilers Using ML
"Compiler 2 0 Using Machine Learning to Modernize Compiler Technology", Saman Amarasinghe, MIT, Keynote, LCTES 2020, Jun 16, 2020
46:15
people.csail.mit.edu/saman/
Commit groups.csail.mit.edu/commit/
Automatic Tuning of Compilers Using ML
https://twitter.com/ogawa_tter/status/968841228656586754



=>
"Can Weight Sharing Outperform Random Architecture Search? An Investigation With TuNAS", Google, Poster, CVPR 2020 openaccess.thecvf.com/content_CVPR_2…
scholar.google.com/citations?hl=j…
scholar.google.com/citations?hl=e…
Quoc V. Le, Apr 2020
Song Han, Apr 2020
"Can Weight Sharing Outperform Random Architecture Search? An Investigation With TuNAS", Google, Poster, CVPR 2020 openaccess.thecvf.com/content_CVPR_2…
scholar.google.com/citations?hl=j…
scholar.google.com/citations?hl=e…
Quoc V. Le, Apr 2020
https://twitter.com/ogawa_tter/status/1257367888668786691
Song Han, Apr 2020
https://twitter.com/ogawa_tter/status/1258355095869128704




=>
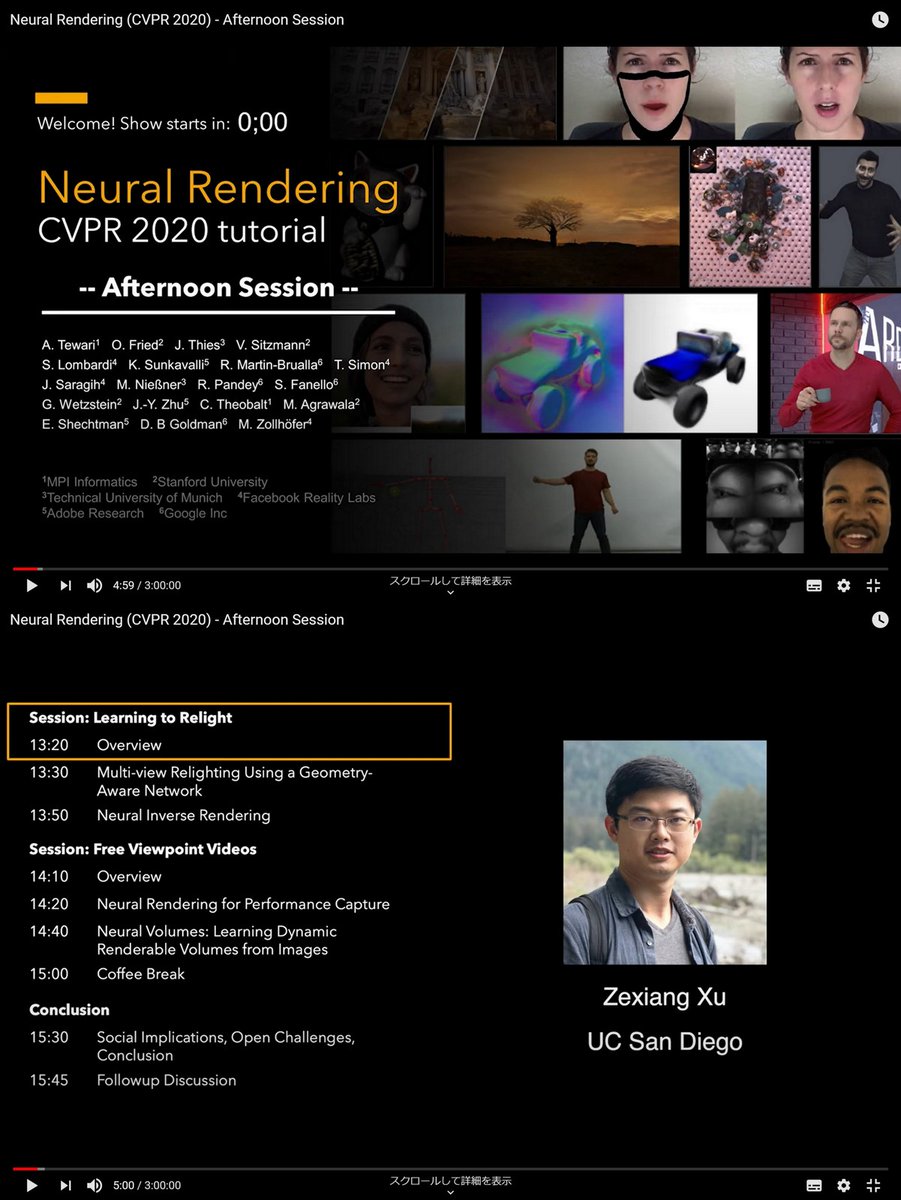
Neural Rendering, CVPR 2020 tutorial, Jun 15 neuralrender.com
4:20:00
3:00:00
DNNs for image or video generaton
that enable explicit or implicit contrrol
of scene properties
based on Eurographics 20
Neural Rendering, CVPR 2020 tutorial, Jun 15 neuralrender.com
4:20:00
3:00:00
DNNs for image or video generaton
that enable explicit or implicit contrrol
of scene properties
based on Eurographics 20
https://twitter.com/ogawa_tter/status/1267534742162771969



=>
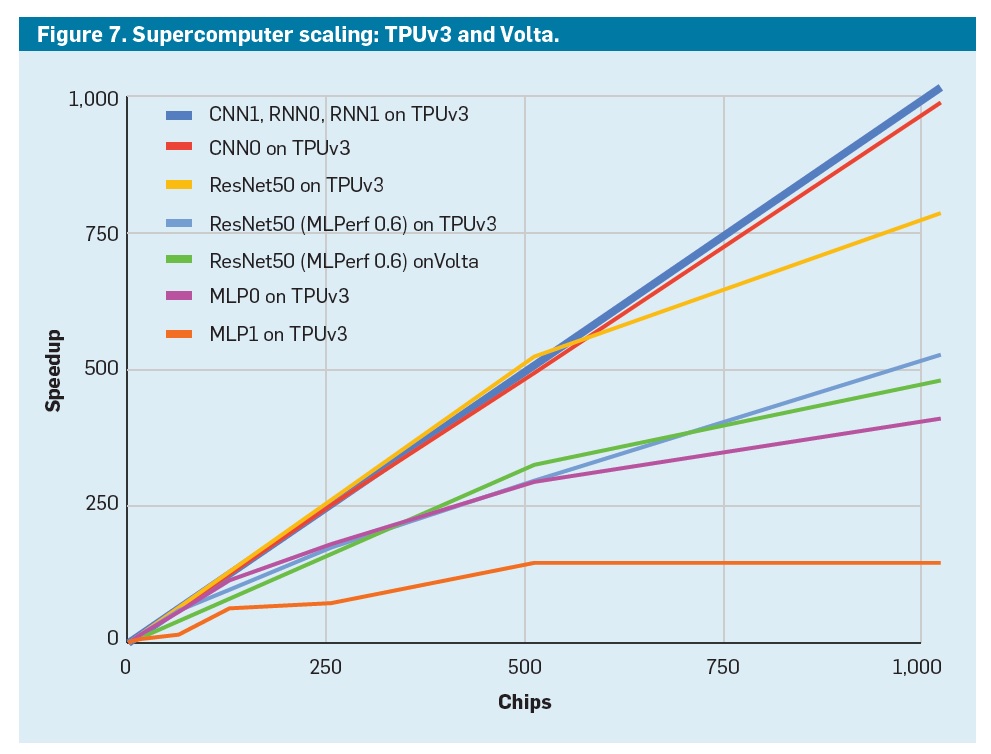
"A Domain-Specific Supercomputer for Training Deep Neural Networks", Norman P. Jouppi, ., Cliff Young, and David Patterson, Comm of the ACM, Jul 2020 cacm.acm.org/magazines/2020…
Google TPUv2/v3
TPUv1, Sep, 2018
D. Patterson, Oct 2019
"A Domain-Specific Supercomputer for Training Deep Neural Networks", Norman P. Jouppi, ., Cliff Young, and David Patterson, Comm of the ACM, Jul 2020 cacm.acm.org/magazines/2020…
Google TPUv2/v3
TPUv1, Sep, 2018
https://twitter.com/ogawa_tter/status/1037868660482695168
D. Patterson, Oct 2019
https://twitter.com/ogawa_tter/status/1192329877963149312



=>
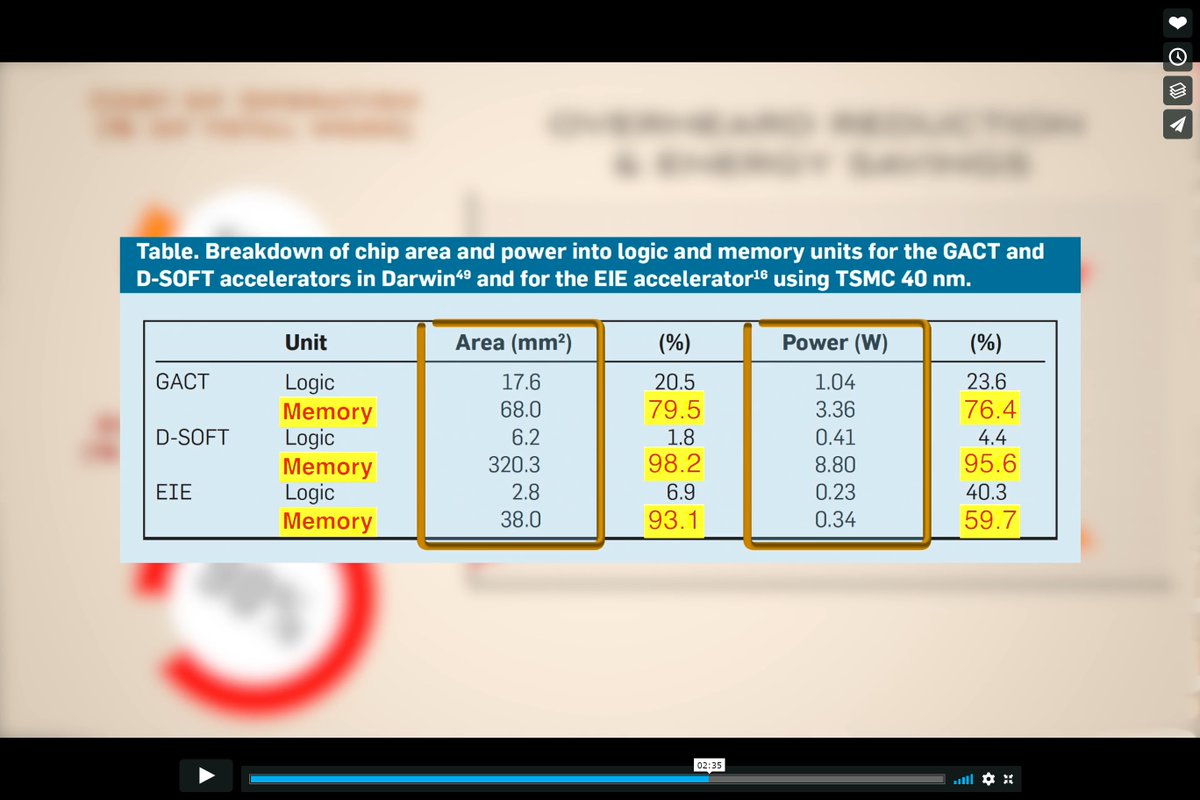
"Domain-Specific Hardware Accelerators", William J. Dally, Yatish Turakhia, and Song Han, Comm of the ACM, July 2020 cacm.acm.org/magazines/2020…
Darwin-WGA
Y. Turakhia, PhD Thesis, 2019 searchworks.stanford.edu/view/13333373
scholar.google.com/citations?hl=e…
scholar.google.com/citations?hl=e…
"Domain-Specific Hardware Accelerators", William J. Dally, Yatish Turakhia, and Song Han, Comm of the ACM, July 2020 cacm.acm.org/magazines/2020…
Darwin-WGA
https://twitter.com/ogawa_tter/status/1103283421730680832
Y. Turakhia, PhD Thesis, 2019 searchworks.stanford.edu/view/13333373
scholar.google.com/citations?hl=e…
scholar.google.com/citations?hl=e…



=>
Design Space Exploration, Tutorial, PLDI 2020, Jun 15, 2020 pldi20.sigplan.org/details/pldi-2…
Matthew Feldman, Artur Souza, Luigi Nardi
Kunle Olukotun
4:01:21
Practical Design Space Exploration, MASCOTS 2019 arxiv.org/abs/1810.05236
Spatial
Design Space Exploration, Tutorial, PLDI 2020, Jun 15, 2020 pldi20.sigplan.org/details/pldi-2…
Matthew Feldman, Artur Souza, Luigi Nardi
Kunle Olukotun
4:01:21
Practical Design Space Exploration, MASCOTS 2019 arxiv.org/abs/1810.05236
Spatial
https://twitter.com/ogawa_tter/status/1180299819249586176




=>
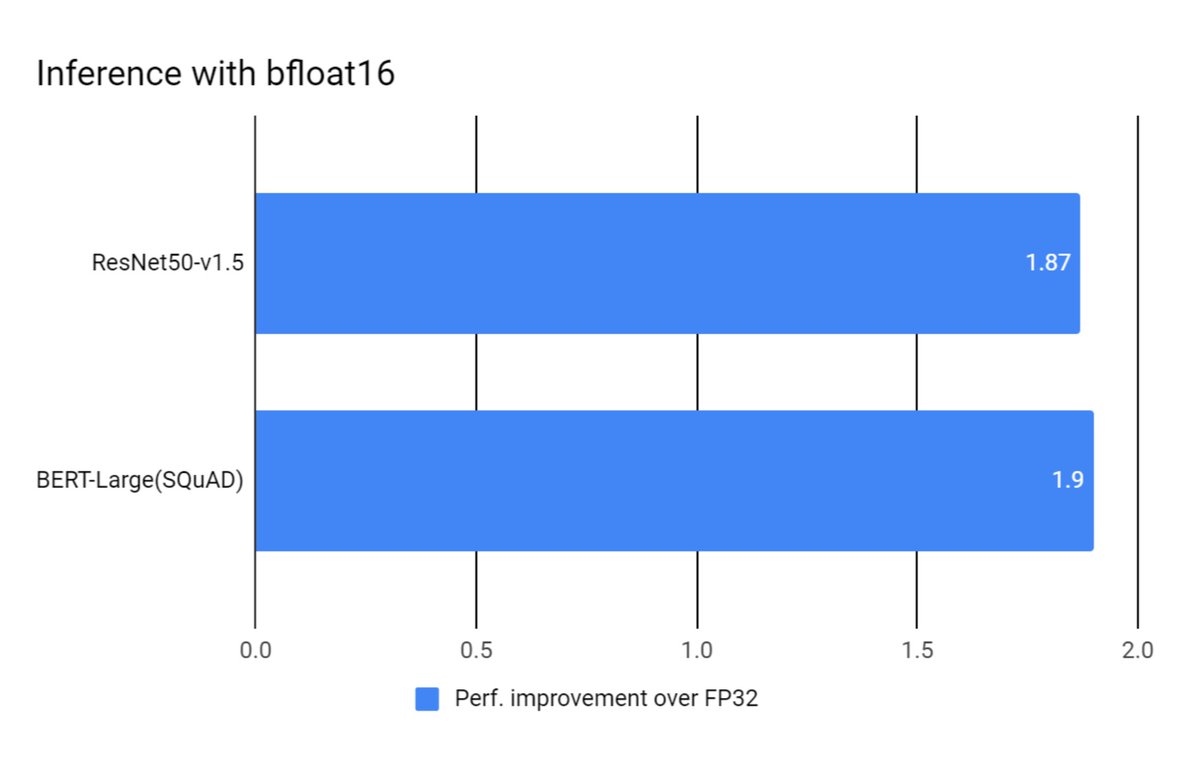
"Accelerating AI performance on 3rd Gen Intel Xeon Scalable processors with TensorFlow and Bfloat16", Jun 18, 2020 blog.tensorflow.org/2020/06/accele…
intel.com/content/www/us…
Product Brief newsroom.intel.com/wp-content/upl…
Bfloat16 Demo itpeernetwork.intel.com/wp-content/upl…
*) Sound!!!
"Accelerating AI performance on 3rd Gen Intel Xeon Scalable processors with TensorFlow and Bfloat16", Jun 18, 2020 blog.tensorflow.org/2020/06/accele…
https://twitter.com/ogawa_tter/status/1273762221714096129
intel.com/content/www/us…
Product Brief newsroom.intel.com/wp-content/upl…
Bfloat16 Demo itpeernetwork.intel.com/wp-content/upl…
*) Sound!!!

=>
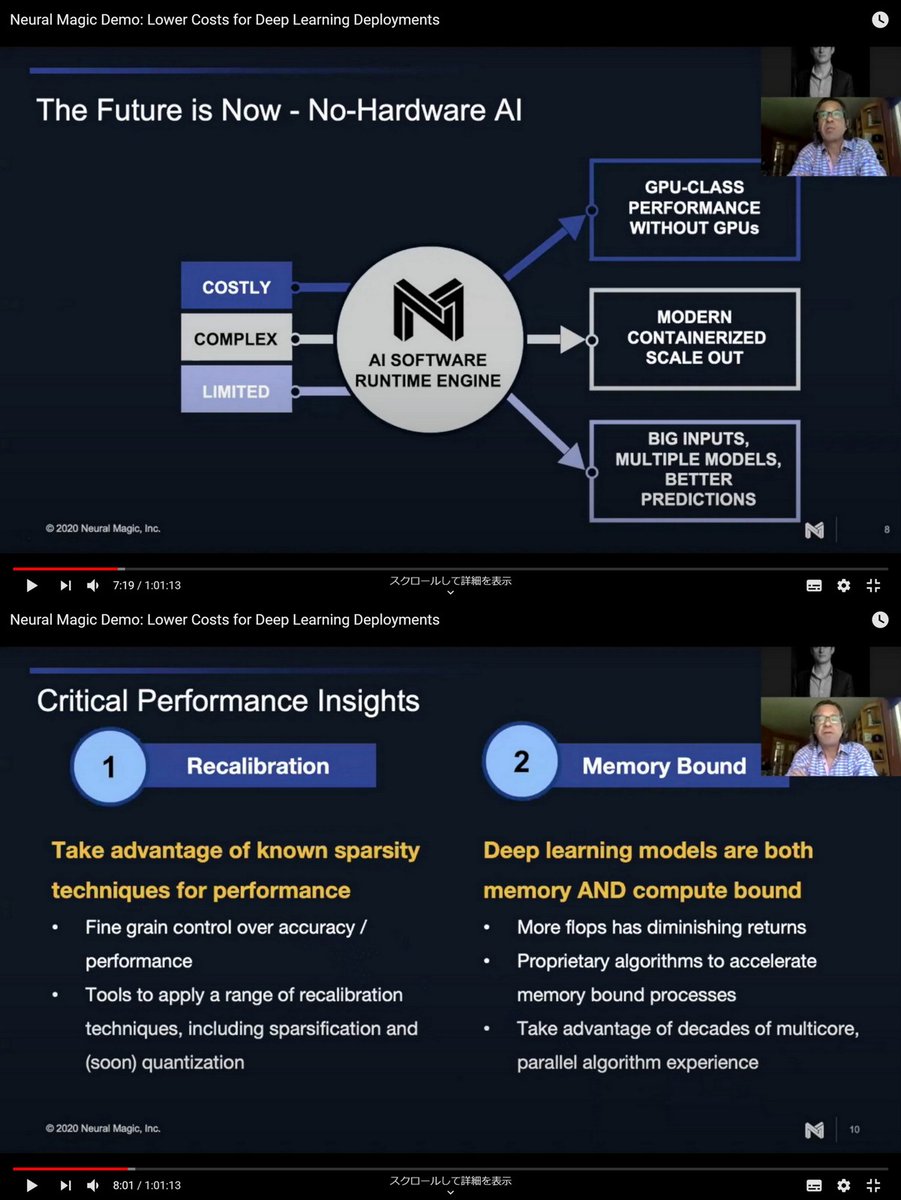
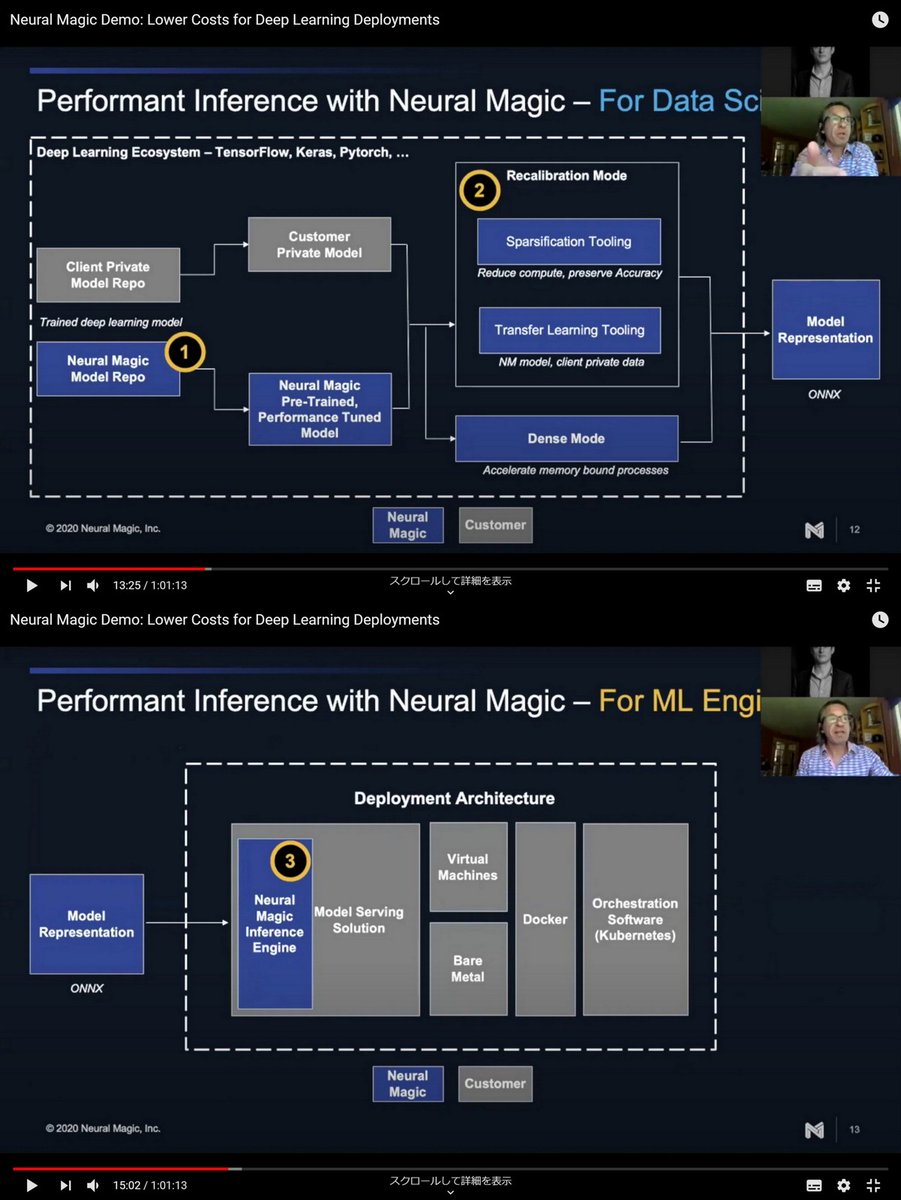
@neuralmagic Launches High-Performance Inference Engine and Tool Suite for CPUs, Jun 18, 2020 neuralmagic.com/blog/neural-ma…
Model Repo
ML Tooling (Pruning / Transfer Learning API)
Neural Magic Inference Engine
No-Hardware AI: The Next Era of ML, May 5
1:01:13
@neuralmagic Launches High-Performance Inference Engine and Tool Suite for CPUs, Jun 18, 2020 neuralmagic.com/blog/neural-ma…
Model Repo
ML Tooling (Pruning / Transfer Learning API)
Neural Magic Inference Engine
No-Hardware AI: The Next Era of ML, May 5
1:01:13

=>
"Groq's Tensor Streaming Processor: From Chip to Sysmtes", Dennis Abts , Chief Architect, @GroqInc , IWMLHW, Jun 2020
21:15
Slides mlhardware.github.io/2020/groq.pdf
Flexible Node Organization
SDK, API
Scale Configurations
TSP, ISCA 2020
"Groq's Tensor Streaming Processor: From Chip to Sysmtes", Dennis Abts , Chief Architect, @GroqInc , IWMLHW, Jun 2020
21:15
Slides mlhardware.github.io/2020/groq.pdf
Flexible Node Organization
SDK, API
Scale Configurations
TSP, ISCA 2020
https://twitter.com/ogawa_tter/status/1267500323838390272




=>
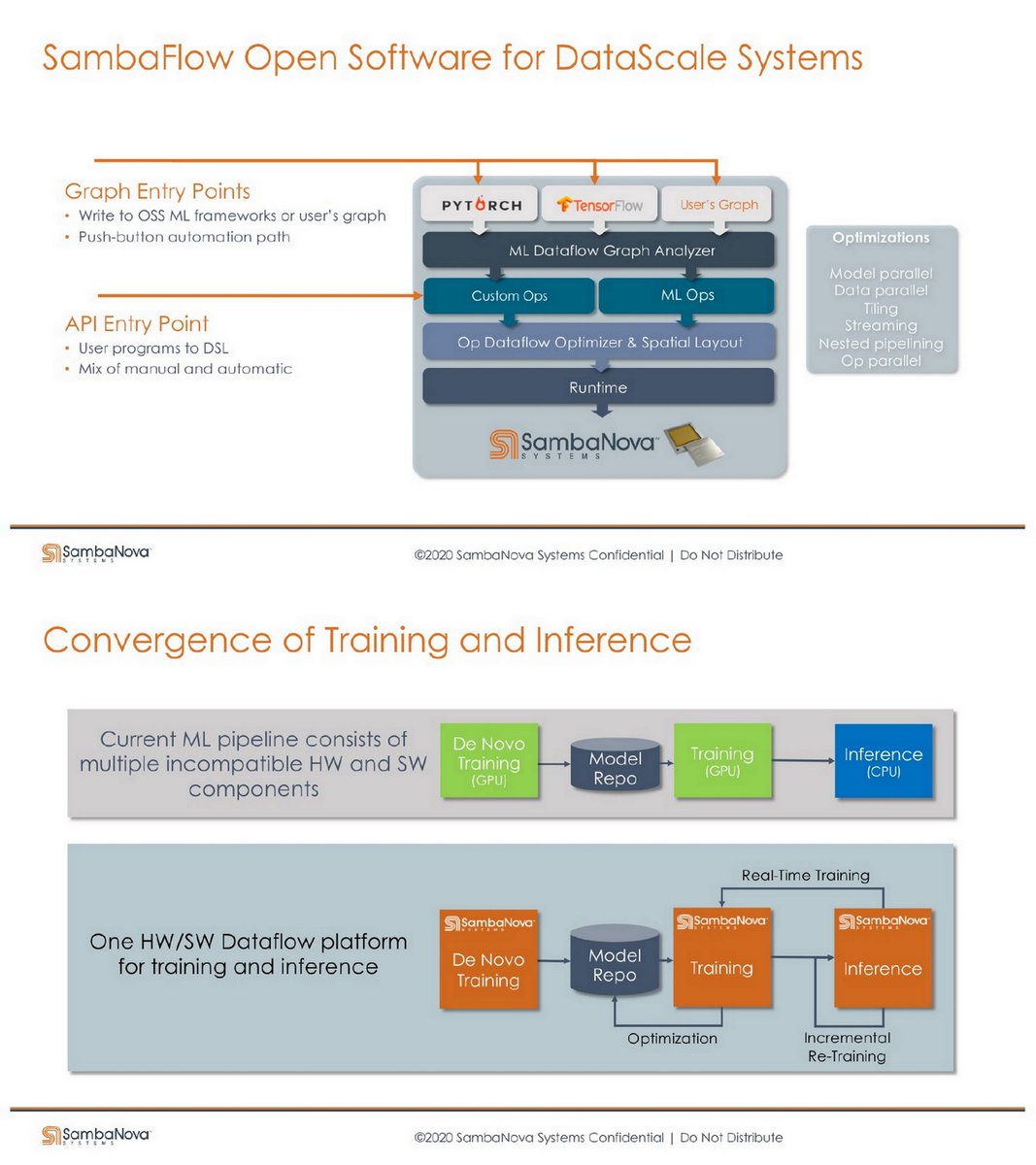
"Accelerating Software 2.0", Kunle Olukotun, Chief Technologist and Co-Founder. @SambaNovaAI , IWMLHW, Jun 2020
21:51
Slides mlhardware.github.io/2020/sambanova…
Cardinal SN10 Reconfigurable Dataflow Unit
Accelerating ML from RDB, ISCA 2020
"Accelerating Software 2.0", Kunle Olukotun, Chief Technologist and Co-Founder. @SambaNovaAI , IWMLHW, Jun 2020
21:51
Slides mlhardware.github.io/2020/sambanova…
Cardinal SN10 Reconfigurable Dataflow Unit
Accelerating ML from RDB, ISCA 2020
https://twitter.com/ogawa_tter/status/1267849004487815171



=>
"Wafer-scale AI for science and HPC", Andy Hock, @CerebrasSystems , IWMLH, Jun 2020
17:40
Slides mlhardware.github.io/2020/cerebras.…
CS-1, Nov 2019
COVID-19 ANL
LLNL
PSC
"Wafer-scale AI for science and HPC", Andy Hock, @CerebrasSystems , IWMLH, Jun 2020
17:40
Slides mlhardware.github.io/2020/cerebras.…
CS-1, Nov 2019
https://twitter.com/ogawa_tter/status/1200694836384260096
COVID-19 ANL
https://twitter.com/ogawa_tter/status/1260632729089011712
LLNL
https://twitter.com/ogawa_tter/status/1263389042999062528
PSC
https://twitter.com/ogawa_tter/status/1270405883248250880




=>
"Scalable Machine Intelligence Systems", @graphcoreai , IWMLH, Jun 2020
25:59
Slides (65 MB) mlhardware.github.io/2020/graphcore…
(Bulk) Synchronization
IPU-Link
CNBC, Jun 9, 2020
Software Stack, Res Paper
Dissecting
"Scalable Machine Intelligence Systems", @graphcoreai , IWMLH, Jun 2020
25:59
Slides (65 MB) mlhardware.github.io/2020/graphcore…
(Bulk) Synchronization
IPU-Link
CNBC, Jun 9, 2020
https://twitter.com/ogawa_tter/status/1270481883462111233
Software Stack, Res Paper
Dissecting
https://twitter.com/ogawa_tter/status/1204774489411608579




=>
Compiler Construction for HW Acceleration: Challenges and Opportunities, A. Cohen, Google, Keynote, IWMLH, Jun 25, 2020
34:40
mlhardware.github.io/2020/mlir-albe…
A New Golden Age for
TPUv2/v3
Compiler Construction for HW Acceleration: Challenges and Opportunities, A. Cohen, Google, Keynote, IWMLH, Jun 25, 2020
34:40
mlhardware.github.io/2020/mlir-albe…
A New Golden Age for
https://twitter.com/ogawa_tter/status/1090543939885518848
TPUv2/v3
https://twitter.com/ogawa_tter/status/1273962542230982656
https://twitter.com/ogawa_tter/status/1247886288637677573




=>
"Machine Learning for Smart Building Applications: Review and Taxonomy", ACM Computing Surveys, Mar 2019 dl.acm.org/doi/abs/10.114…
Occupancy-Centric Solutions
Energy/Device-Centric Solutions
97 references
D. Djenouri sites.google.com/site/djenouri/
I. Balasingham ntnu.edu/employees/ilan…
"Machine Learning for Smart Building Applications: Review and Taxonomy", ACM Computing Surveys, Mar 2019 dl.acm.org/doi/abs/10.114…
Occupancy-Centric Solutions
Energy/Device-Centric Solutions
97 references
D. Djenouri sites.google.com/site/djenouri/
I. Balasingham ntnu.edu/employees/ilan…

=>
「AI戦略2019」フォローアップ、統合イノベーション戦略推進会議、令和2年6月26日
概要 kantei.go.jp/jp/singi/tougo…
本文 kantei.go.jp/jp/singi/tougo…
別紙 kantei.go.jp/jp/singi/tougo…
「AI戦略2019」、令和元年6月11日、統合イノベーション戦略推進会議決定
「AI戦略2019」フォローアップ、統合イノベーション戦略推進会議、令和2年6月26日
概要 kantei.go.jp/jp/singi/tougo…
本文 kantei.go.jp/jp/singi/tougo…
別紙 kantei.go.jp/jp/singi/tougo…
「AI戦略2019」、令和元年6月11日、統合イノベーション戦略推進会議決定
https://twitter.com/ogawa_tter/status/1159376615039569920




=>
"Configurable and programmable image processor unit", Google, Patent Applications, May 28, 2020 patents.google.com/patent/US20200…
May 15, 2017: Priority to US15/595,289
The Pixel Visual Core, Hot Chips 2018
Patent: May 8, 2018
"Configurable and programmable image processor unit", Google, Patent Applications, May 28, 2020 patents.google.com/patent/US20200…
May 15, 2017: Priority to US15/595,289
The Pixel Visual Core, Hot Chips 2018
https://twitter.com/ogawa_tter/status/1219083283696275456
Patent: May 8, 2018




=>
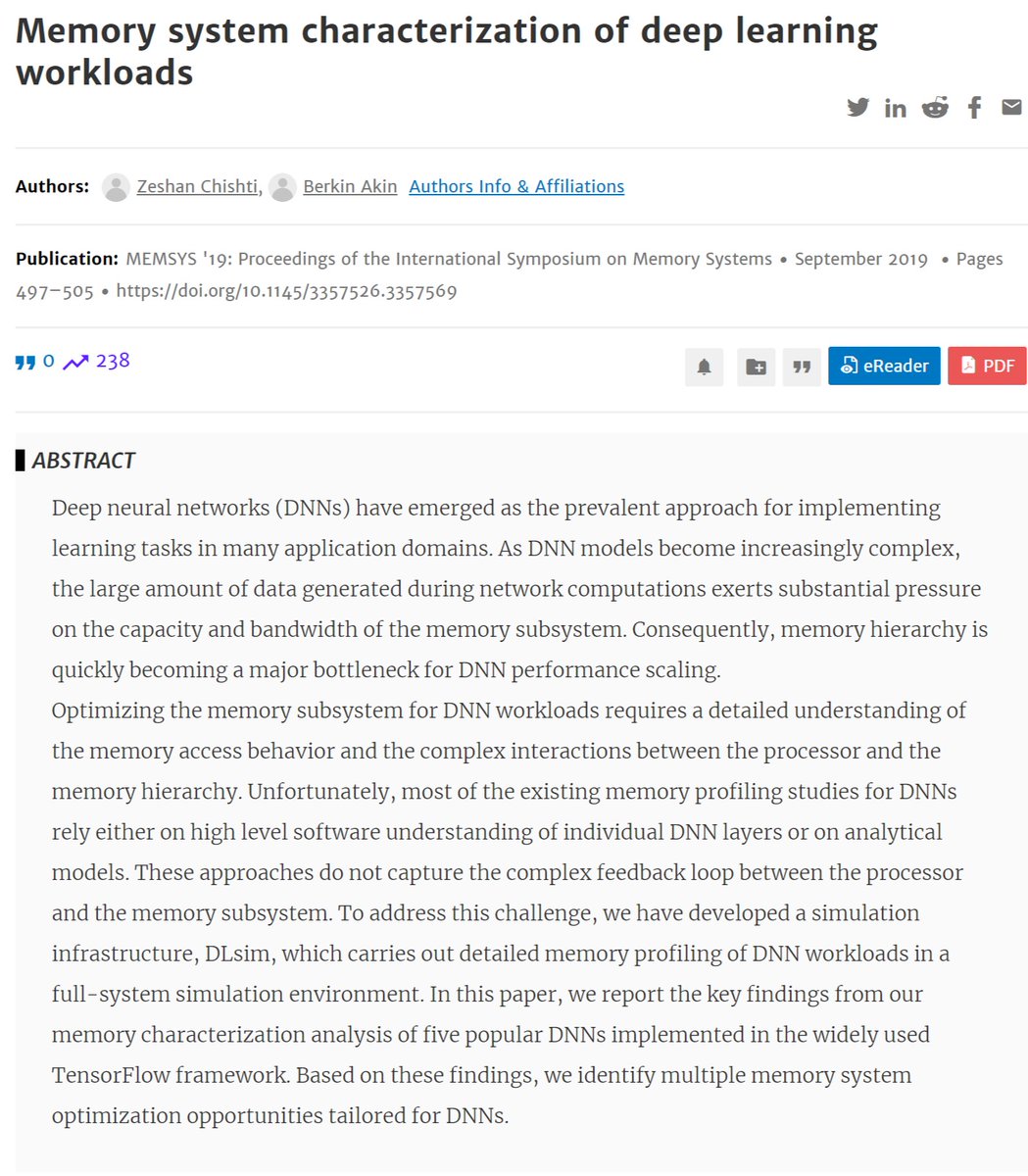
"Memory system characterization of deep learning workloads", MEMSYS 2019 dl.acm.org/doi/abs/10.114…
Z. Chishti scholar.google.com/citations?hl=j…
B. Akin scholar.google.com/citations?hl=e…
"Memory Requirements for Convolutional Neural Network Hardware Accelerators", IISWC 2018
"Memory system characterization of deep learning workloads", MEMSYS 2019 dl.acm.org/doi/abs/10.114…
Z. Chishti scholar.google.com/citations?hl=j…
B. Akin scholar.google.com/citations?hl=e…
"Memory Requirements for Convolutional Neural Network Hardware Accelerators", IISWC 2018
https://twitter.com/ogawa_tter/status/1139960432435687424
=>
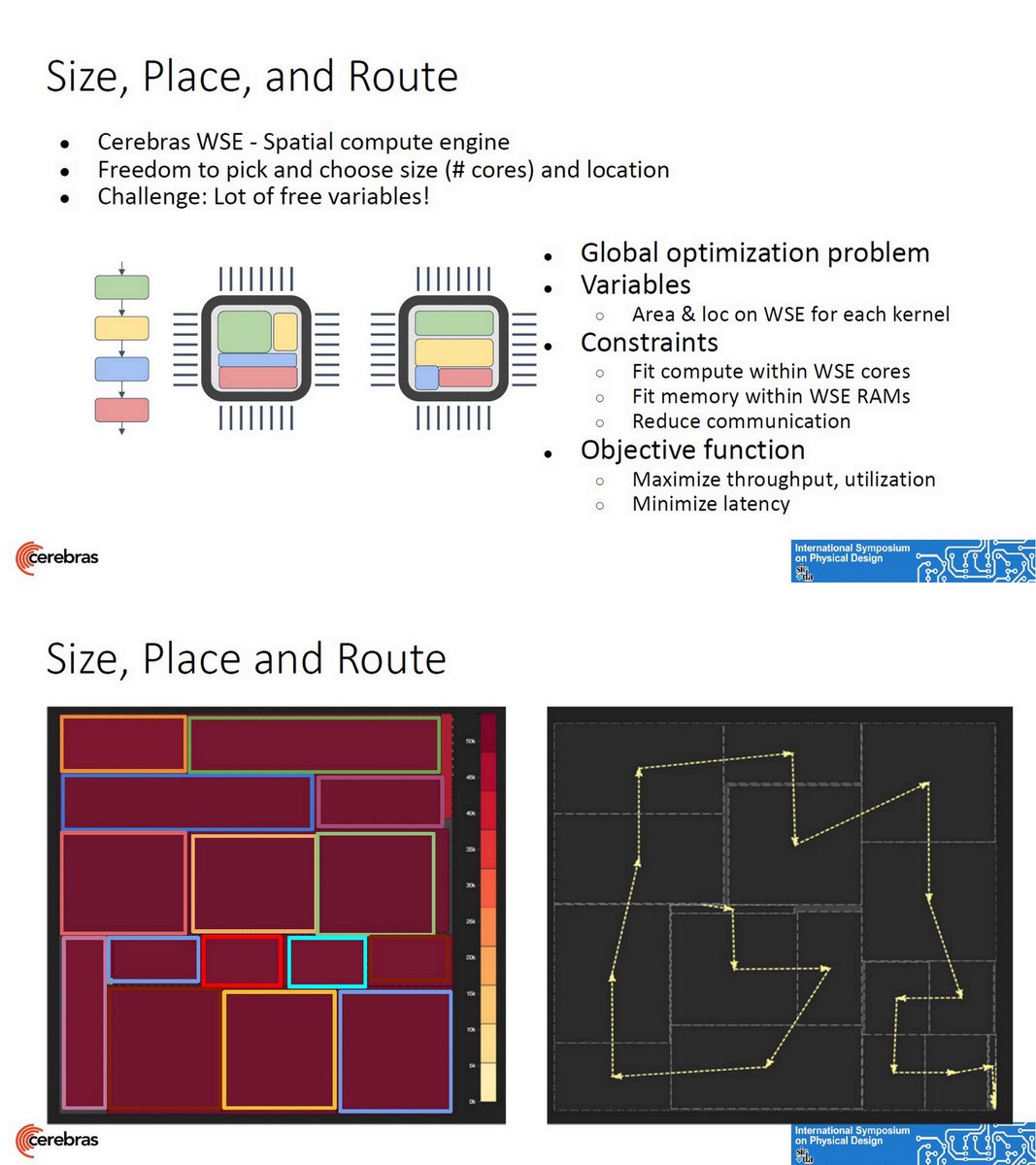
Wafer Scale Engine Placement Contest, ISPD 2020 Special Session, Jun 18 2020 @CerebrasSystems
1:18:31 zoom.us/rec/play/6Jd8I…
45MB secureservercdn.net/198.12.145.239…
dl.acm.org/doi/abs/10.114…
Taiwan: 3
USA, Hong Kong, China :2
Korea: 1
Dec 12 cerebras.net/ispd-2020-cont…
Wafer Scale Engine Placement Contest, ISPD 2020 Special Session, Jun 18 2020 @CerebrasSystems
1:18:31 zoom.us/rec/play/6Jd8I…
45MB secureservercdn.net/198.12.145.239…
dl.acm.org/doi/abs/10.114…
Taiwan: 3
USA, Hong Kong, China :2
Korea: 1
Dec 12 cerebras.net/ispd-2020-cont…
https://twitter.com/ogawa_tter/status/1275691244799373316



=>
"Sparse-TPU: Adapting Systolic Arrays for Sparse Matrices", ICS 2020
22:45
PDF web.eecs.umich.edu/~subh/publicat…
Hold, Latch, Accumulate, Bypass
vs TPU
16.08x performance
4.39x and 19.79x lower energy for INT8 and FP32 on average
HPCA 2020
"Sparse-TPU: Adapting Systolic Arrays for Sparse Matrices", ICS 2020
22:45
PDF web.eecs.umich.edu/~subh/publicat…
Hold, Latch, Accumulate, Bypass
vs TPU
16.08x performance
4.39x and 19.79x lower energy for INT8 and FP32 on average
HPCA 2020
https://twitter.com/ogawa_tter/status/1242050351475253248




=>
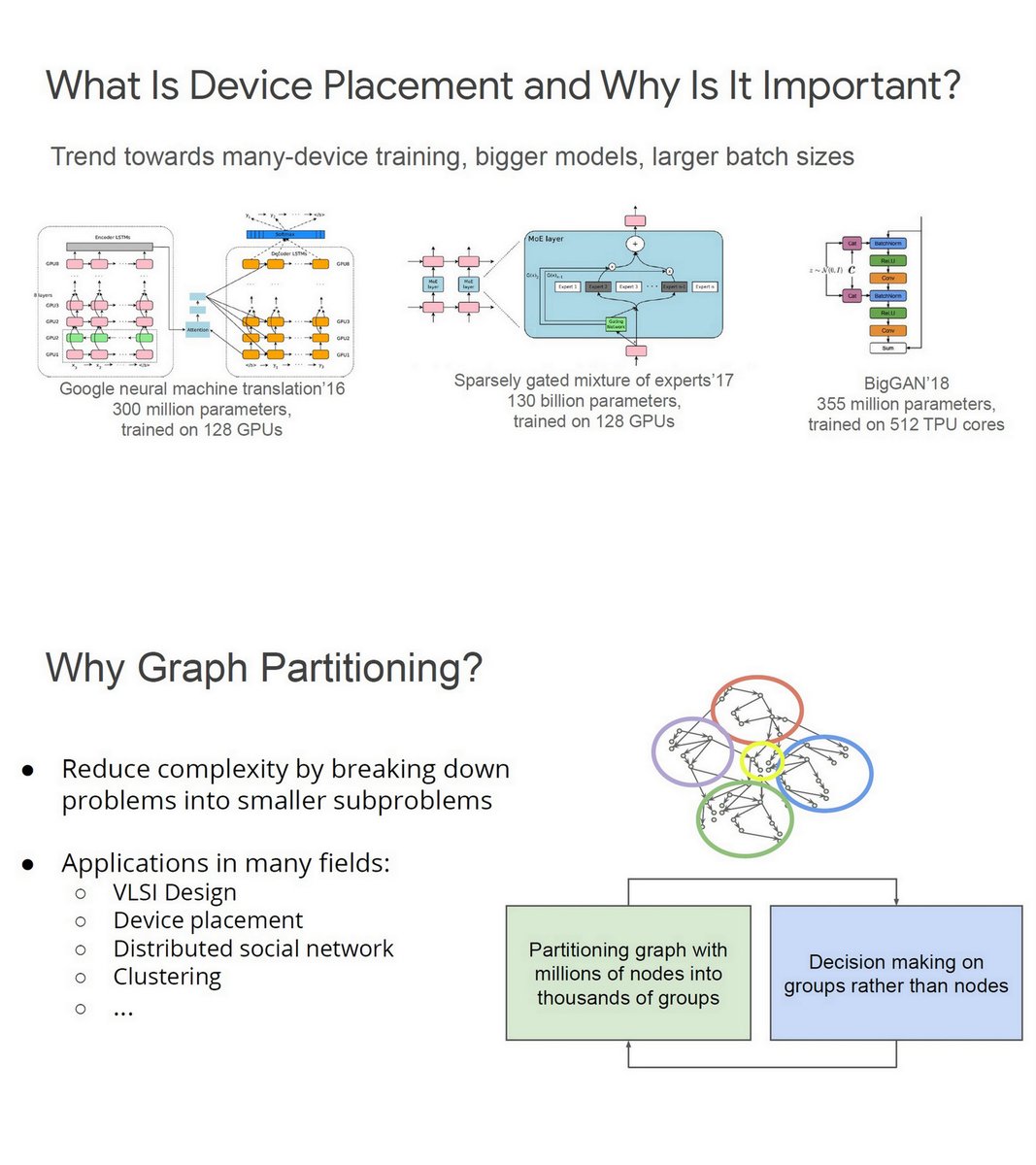
"Placement Optimization with Deep Reinforcement Learning", Anna Goldie & Azalia Mirhoseini, Google Brain, ISPD 2020 dl.acm.org/doi/abs/10.114…
ML for Systems & Chip Design, Guest Lecture, CalTech, May 2020
Patent Appl, Jun 4, 2020 patents.google.com/patent/US20200…
"Placement Optimization with Deep Reinforcement Learning", Anna Goldie & Azalia Mirhoseini, Google Brain, ISPD 2020 dl.acm.org/doi/abs/10.114…
ML for Systems & Chip Design, Guest Lecture, CalTech, May 2020
https://twitter.com/ogawa_tter/status/1266444762158034944
Patent Appl, Jun 4, 2020 patents.google.com/patent/US20200…




=>
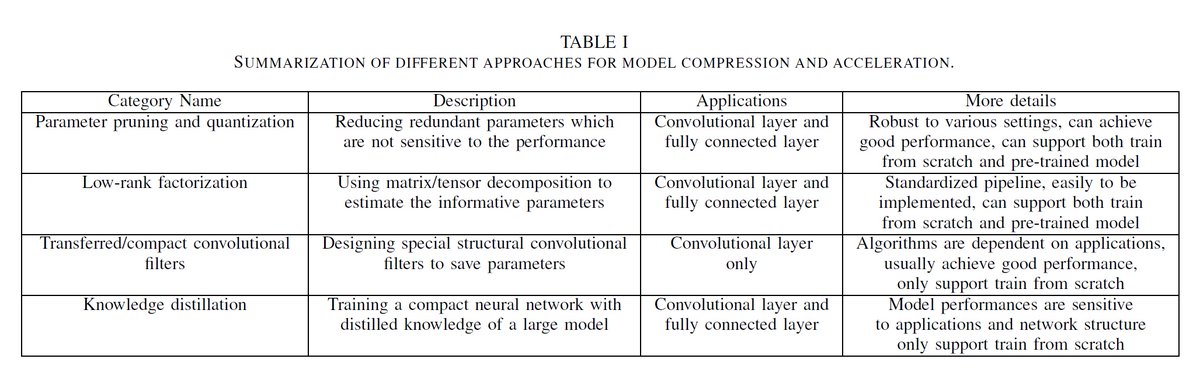
"A Survey of Model Compression and Acceleration for Deep Neural Networks", arXiv, Jun 14, 2020 arxiv.org/abs/1710.09282
Parameter Pruning & Quantization
Low-Rank Approximation & Sparsity
Transferred/Compact Convolutional Filters
Knowledge Distillation
..
sites.google.com/site/chengyu05
"A Survey of Model Compression and Acceleration for Deep Neural Networks", arXiv, Jun 14, 2020 arxiv.org/abs/1710.09282
Parameter Pruning & Quantization
Low-Rank Approximation & Sparsity
Transferred/Compact Convolutional Filters
Knowledge Distillation
..
sites.google.com/site/chengyu05


=>
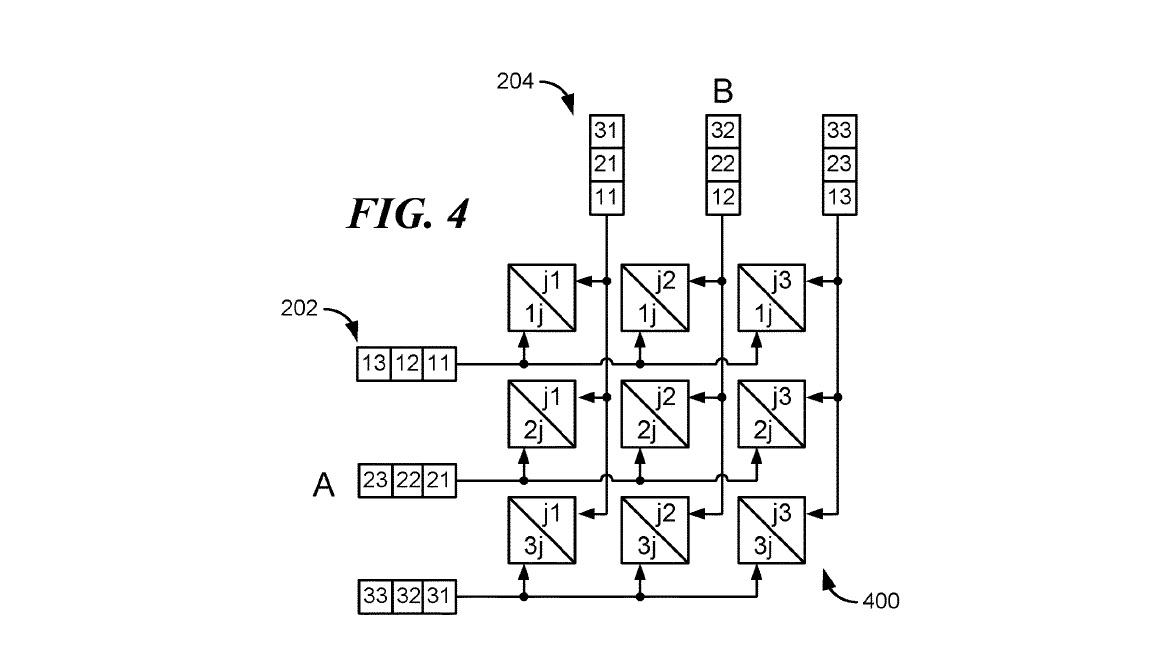
"Systolic Convolutional Neural Network", Arm, Patent Application, Oct 10, 2019 patents.google.com/patent/US20190…
PE
Transposing Buffer
Weight buffer
Computation has two parts
Matthew Mattina community.arm.com/members/mattm
Head of Arm's Machine Learning Research Lab
was CTO at Tilera
"Systolic Convolutional Neural Network", Arm, Patent Application, Oct 10, 2019 patents.google.com/patent/US20190…
PE
Transposing Buffer
Weight buffer
Computation has two parts
Matthew Mattina community.arm.com/members/mattm
Head of Arm's Machine Learning Research Lab
was CTO at Tilera



=>
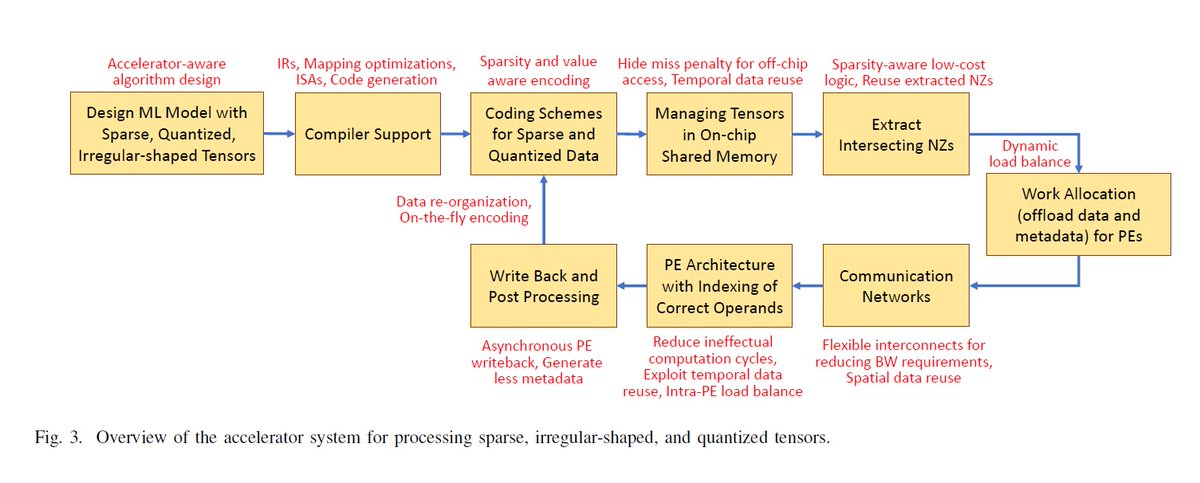
"Hardware Acceleration of Sparse and Irregular Tensor Computations of ML Models: A Survey and Insights", arXiv, Jul 2, 2020 arxiv.org/abs/2007.00864
58 pp
341 references
Shail Dave sites.google.com/view/shail
Tony Nowatzki web.cs.ucla.edu/~tjn/
Baoxin Li public.asu.edu/~bli24/
"Hardware Acceleration of Sparse and Irregular Tensor Computations of ML Models: A Survey and Insights", arXiv, Jul 2, 2020 arxiv.org/abs/2007.00864
58 pp
341 references
Shail Dave sites.google.com/view/shail
Tony Nowatzki web.cs.ucla.edu/~tjn/
Baoxin Li public.asu.edu/~bli24/



=>
New Graphcore Poplar SDK 1.2 released, Jul 7, 2020 graphcore.ai/posts/new-grap…
What’s new in SDK 1.2?
PyTorch for IPU (preview feature)
Keras for IPU
New libraries and features
...
User Guide docs.graphcore.ai/projects/popla…
Open sourced PopLibs Poplar Libraries github.com/graphcore
New Graphcore Poplar SDK 1.2 released, Jul 7, 2020 graphcore.ai/posts/new-grap…
What’s new in SDK 1.2?
PyTorch for IPU (preview feature)
Keras for IPU
New libraries and features
...
User Guide docs.graphcore.ai/projects/popla…
Open sourced PopLibs Poplar Libraries github.com/graphcore
=>
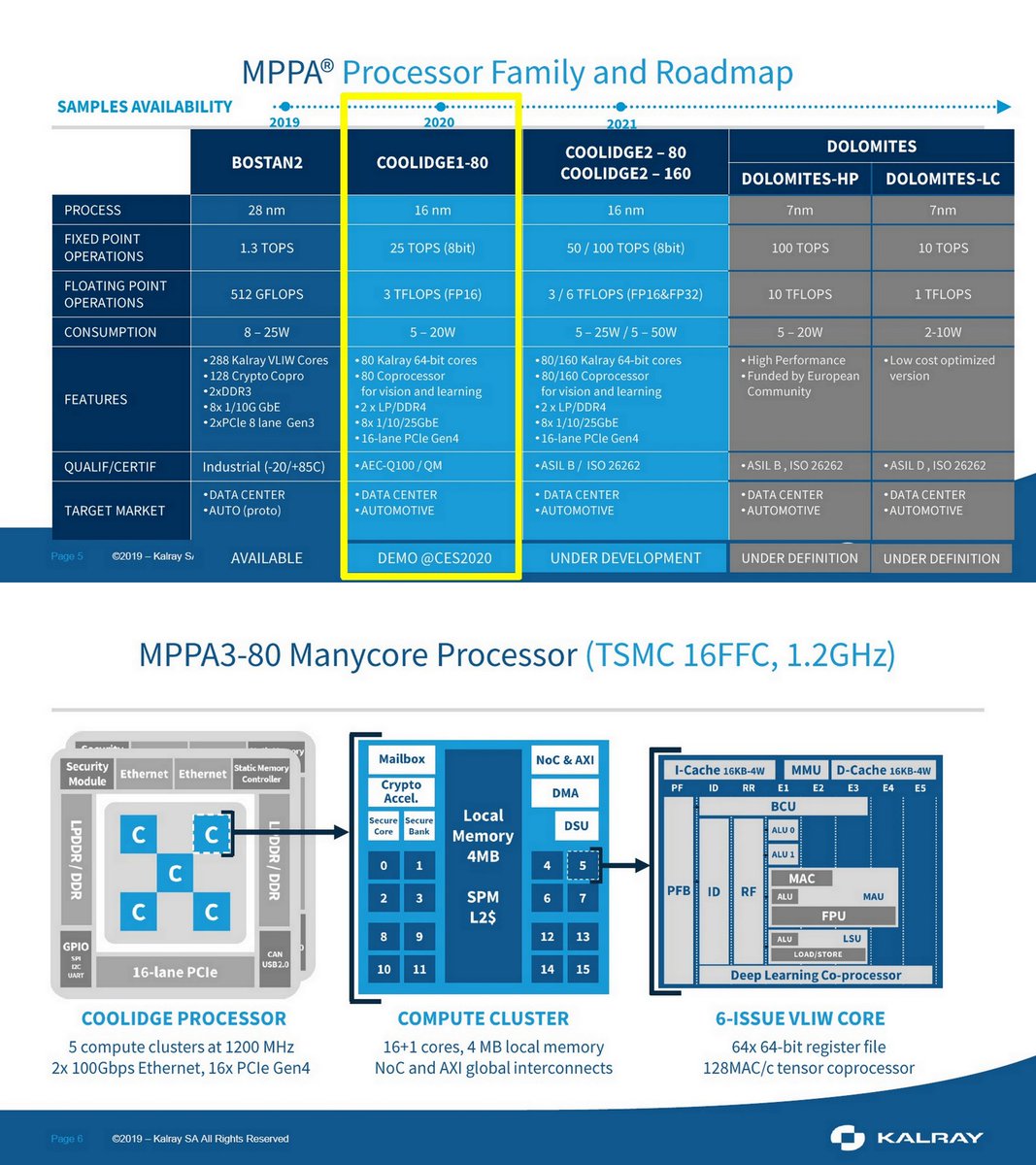
"Deep Learning Inference on the MPPA3 Manycore Processor", Kalray, Embedded World 2020, Feb 2020 PDF european-processor-initiative.eu/wp-content/upl…
kalrayinc.com/portfolio/proc…
AI Computing for Automotive, Yole & Kalray, Apr 2020
EPI Automotive, Dec 2019
"Deep Learning Inference on the MPPA3 Manycore Processor", Kalray, Embedded World 2020, Feb 2020 PDF european-processor-initiative.eu/wp-content/upl…
kalrayinc.com/portfolio/proc…
AI Computing for Automotive, Yole & Kalray, Apr 2020
https://twitter.com/ogawa_tter/status/1270391012309884931
EPI Automotive, Dec 2019
https://twitter.com/ogawa_tter/status/1217245339607941120



=>
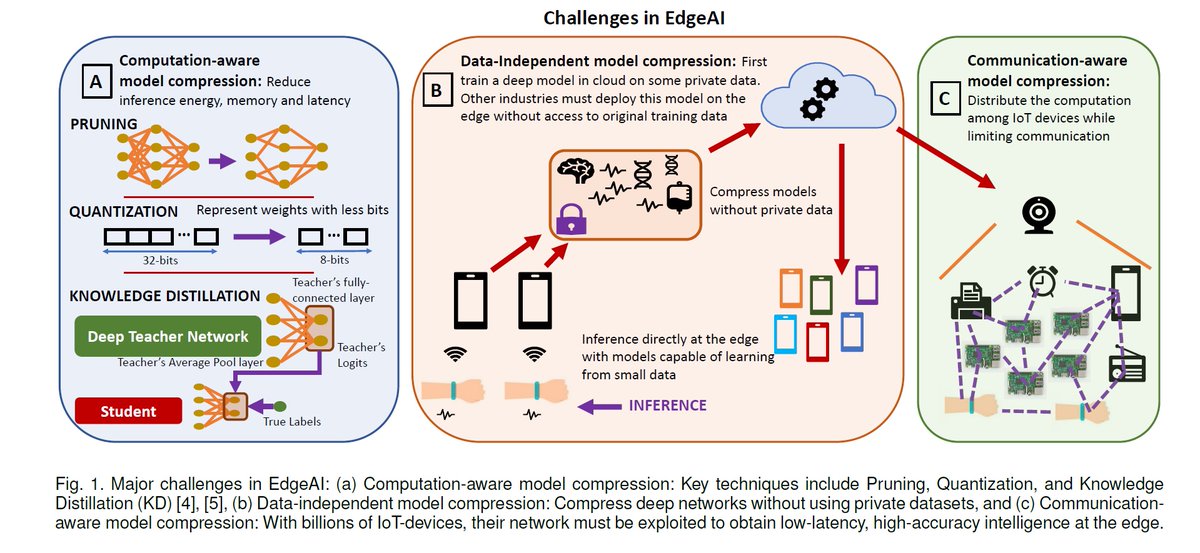
"EdgeAI: A Vision for Deep Learning in IoT Era", arXiv, Oct 23 2019 (IEEE Design & Test) arxiv.org/abs/1910.10356
Challenges in EdgeAI
K Bhardwaj scholar.google.com/citations?hl=e…
PhD Thesis, 2019 kilthub.cmu.edu/articles/thesi…
N Suda scholar.google.com/citations?hl=e…
R Marculescu users.ece.utexas.edu/~radum/
"EdgeAI: A Vision for Deep Learning in IoT Era", arXiv, Oct 23 2019 (IEEE Design & Test) arxiv.org/abs/1910.10356
Challenges in EdgeAI
K Bhardwaj scholar.google.com/citations?hl=e…
PhD Thesis, 2019 kilthub.cmu.edu/articles/thesi…
N Suda scholar.google.com/citations?hl=e…
R Marculescu users.ece.utexas.edu/~radum/

=>
"Efficient Fitness Action Analysis Based on Spatio-temporal Feature Encoding", IEEE Int Workshop of Artificial Intelligence in Sports (AI-Sports), Jul 10, 2020 ieeexplore.ieee.org/document/91060…
Beijing Sport University, China en.bsu.edu.cn
"Efficient Fitness Action Analysis Based on Spatio-temporal Feature Encoding", IEEE Int Workshop of Artificial Intelligence in Sports (AI-Sports), Jul 10, 2020 ieeexplore.ieee.org/document/91060…
Beijing Sport University, China en.bsu.edu.cn
=>
"Intelligent Memory for Intelligent Computing", Graphcore, Jul 7, 2020 graphcore.ai/posts/intellig…
Colossus GC2 IPU: 300MB
+ Exchange Memory access design (two principles)
Streaming Memory: 16GB
Poplar SDK 1.2
Graphcore IPU, Dec 2019
"Intelligent Memory for Intelligent Computing", Graphcore, Jul 7, 2020 graphcore.ai/posts/intellig…
Colossus GC2 IPU: 300MB
+ Exchange Memory access design (two principles)
Streaming Memory: 16GB
Poplar SDK 1.2
https://twitter.com/ogawa_tter/status/1280447025088061440
Graphcore IPU, Dec 2019
https://twitter.com/ogawa_tter/status/1204774489411608579


=>
"Introducing 2nd @graphcoreai IPU Systems for AI at Scale", Jul 15, 2020 graphcore.ai/posts/introduc…
7nm Colossus MK2 GC200 IPU graphcore.ai/products/ipu
6x 1472
900 MB, 47.5 TB/s
IPU-Machine & IPU-POD graphcore.ai/products/mk2/i…
Report graphcore.ai/mk2-ipu-m2000-…
"Introducing 2nd @graphcoreai IPU Systems for AI at Scale", Jul 15, 2020 graphcore.ai/posts/introduc…
7nm Colossus MK2 GC200 IPU graphcore.ai/products/ipu
6x 1472
900 MB, 47.5 TB/s
IPU-Machine & IPU-POD graphcore.ai/products/mk2/i…
Report graphcore.ai/mk2-ipu-m2000-…




@graphcoreai =>
"The Elegance (And Limitations Of) Precisely Engineered Accelerators", Jul 15, 2020 nextplatform.com/2020/07/15/the…
"BUT"
2015 was a hopeful time for new ...
Graphcore
Exchange Memory
7nm Colossus MK2 GC200 IPU, IPU-M2000, IPU-POD64
"The Elegance (And Limitations Of) Precisely Engineered Accelerators", Jul 15, 2020 nextplatform.com/2020/07/15/the…
"BUT"
2015 was a hopeful time for new ...
Graphcore
Exchange Memory
https://twitter.com/ogawa_tter/status/1283060857497214976
7nm Colossus MK2 GC200 IPU, IPU-M2000, IPU-POD64
https://twitter.com/ogawa_tter/status/1283335660921708544
=>
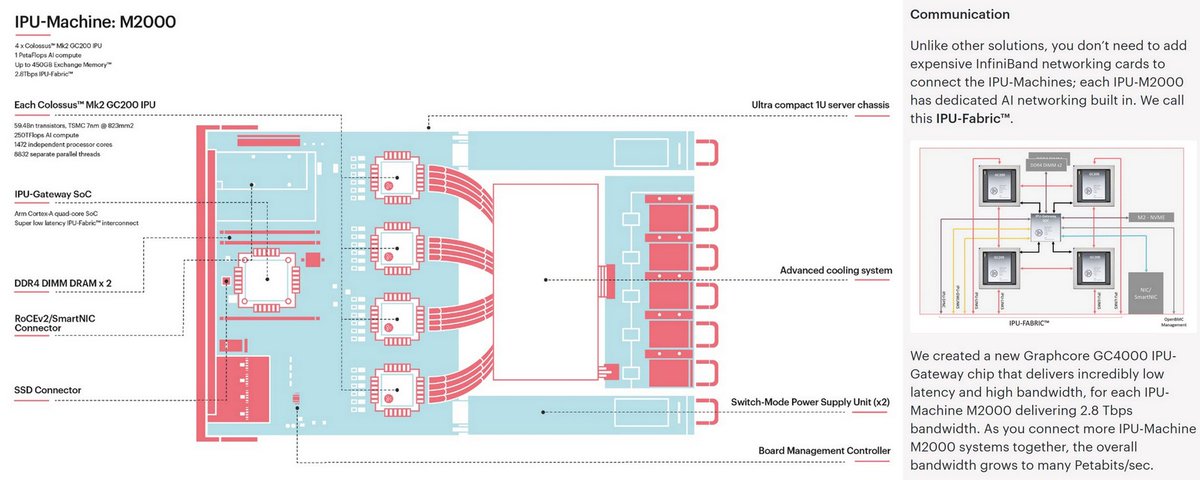
@graphcoreai : IPU-Machine M2000 & IPU-POD
1:44
IPU-M2000 PDF graphcore.ai/hubfs/assets/p…
4 x Colossus Mk2 GC200 IPU
Gateway SoC
2.8Tbps IPU-Fabric
Up to 450GB Exchange Memory
2nd Gen IPU Systems, Jul 15, 2020
@graphcoreai : IPU-Machine M2000 & IPU-POD
1:44
IPU-M2000 PDF graphcore.ai/hubfs/assets/p…
4 x Colossus Mk2 GC200 IPU
Gateway SoC
2.8Tbps IPU-Fabric
Up to 450GB Exchange Memory
https://twitter.com/ogawa_tter/status/1283060857497214976
2nd Gen IPU Systems, Jul 15, 2020
https://twitter.com/ogawa_tter/status/1283335660921708544



=>
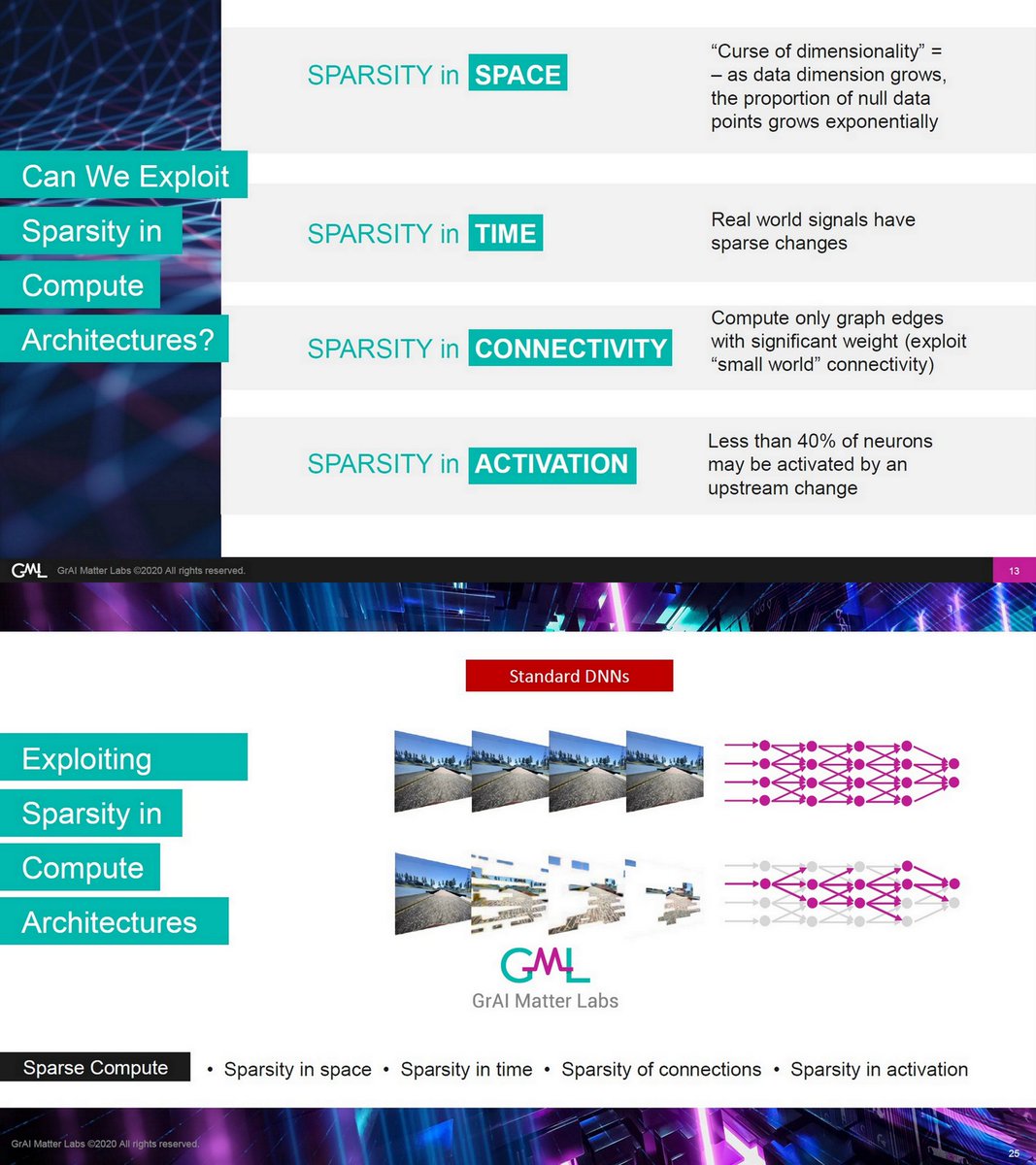
"Saving 95% of your edge power with Sparsity to enable tiny ML", GrAI Matter Labs has, tinyML talks, Jun 16, 2020
31:33
tinyml.org/wp-content/upl…
graimatterlabs.ai
2:04
New PDF graimatterlabs.ai/files/GML-AI-H…
"Saving 95% of your edge power with Sparsity to enable tiny ML", GrAI Matter Labs has, tinyML talks, Jun 16, 2020
31:33
tinyml.org/wp-content/upl…
graimatterlabs.ai
2:04
https://twitter.com/ogawa_tter/status/1187419205454352385
New PDF graimatterlabs.ai/files/GML-AI-H…



=>
"The eX3 infrastructure brings state-of-the-art AI compute to the research community", Simula Research Lab, Jul 15, 2020 simula.no/news/ex3-infra…
Acquiring one of the first Graphcore IPU-POD64 systems, 64 IPUs, 8 PetaFLOPS mixed precision AI compute
"The eX3 infrastructure brings state-of-the-art AI compute to the research community", Simula Research Lab, Jul 15, 2020 simula.no/news/ex3-infra…
Acquiring one of the first Graphcore IPU-POD64 systems, 64 IPUs, 8 PetaFLOPS mixed precision AI compute
https://twitter.com/ogawa_tter/status/1283640460662079495
=>
"An Updated Survey of Efficient Hardware Architectures for Accelerating Deep Convolutional Neural Networks", Review, Future Internet, Jul 7, 2020 mdpi.com/1999-5903/12/7…
Models
Energy-Efficient
Memory
HW Metrics
102 ref
M Martina scholar.google.it/citations?user…
"An Updated Survey of Efficient Hardware Architectures for Accelerating Deep Convolutional Neural Networks", Review, Future Internet, Jul 7, 2020 mdpi.com/1999-5903/12/7…
Models
Energy-Efficient
Memory
HW Metrics
102 ref
M Martina scholar.google.it/citations?user…
https://twitter.com/ogawa_tter/status/1252187841037135873




=>
"How to Watch: Graphcore 2nd Generation Launch", Jul 15, 2020, Cirrascale Cloud Services Blog, blog.cirrascale.com/blog/graphcore…
GRAPHCLOUD cirrascale.com/graphcore-grap…
Preview Access
64 to 1024 Graphcore IPUs
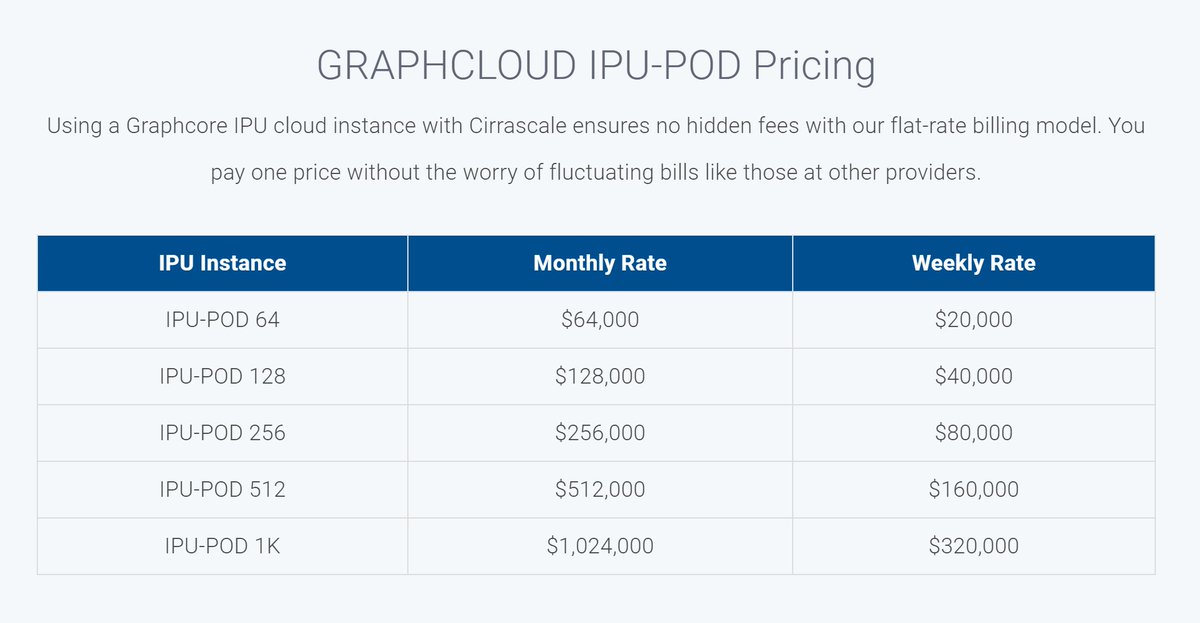
IPU-POD 64: $64,000 / M
IPU-POD 1K: $1,024,000 / M
"How to Watch: Graphcore 2nd Generation Launch", Jul 15, 2020, Cirrascale Cloud Services Blog, blog.cirrascale.com/blog/graphcore…
GRAPHCLOUD cirrascale.com/graphcore-grap…
Preview Access
64 to 1024 Graphcore IPUs
IPU-POD 64: $64,000 / M
IPU-POD 1K: $1,024,000 / M
https://twitter.com/ogawa_tter/status/1283640460662079495
=>
Introduction to Neocortex, Jul 15, 2020
59:45
Slides (16 MB) cmu.edu/psc/aibd/neoco…
Q&A cmu.edu/psc/aibd/neoco…
HPE Superdome Flex (24 TiB)
2x @CerebrasSystems CS-1
Wafer-scale AI for science and HPC
CS-1
Introduction to Neocortex, Jul 15, 2020
59:45
Slides (16 MB) cmu.edu/psc/aibd/neoco…
Q&A cmu.edu/psc/aibd/neoco…
HPE Superdome Flex (24 TiB)
https://twitter.com/ogawa_tter/status/1280149279777017863
2x @CerebrasSystems CS-1
Wafer-scale AI for science and HPC
https://twitter.com/ogawa_tter/status/1275691244799373316
CS-1




=>
"Matrix multiplication on a systolic array", IBM, Patent Granted: Nov 26 2019 patents.google.com/patent/US10489…
Method to Map Conv Layers of DNN on ... SIMD Execution Units .. as a 2D Systolic Processor Array, IBM, Patent Appl, Apr 30 2020 patents.google.com/patent/US20200…
"Matrix multiplication on a systolic array", IBM, Patent Granted: Nov 26 2019 patents.google.com/patent/US10489…
Method to Map Conv Layers of DNN on ... SIMD Execution Units .. as a 2D Systolic Processor Array, IBM, Patent Appl, Apr 30 2020 patents.google.com/patent/US20200…
https://twitter.com/ogawa_tter/status/1272558654869213184




=>
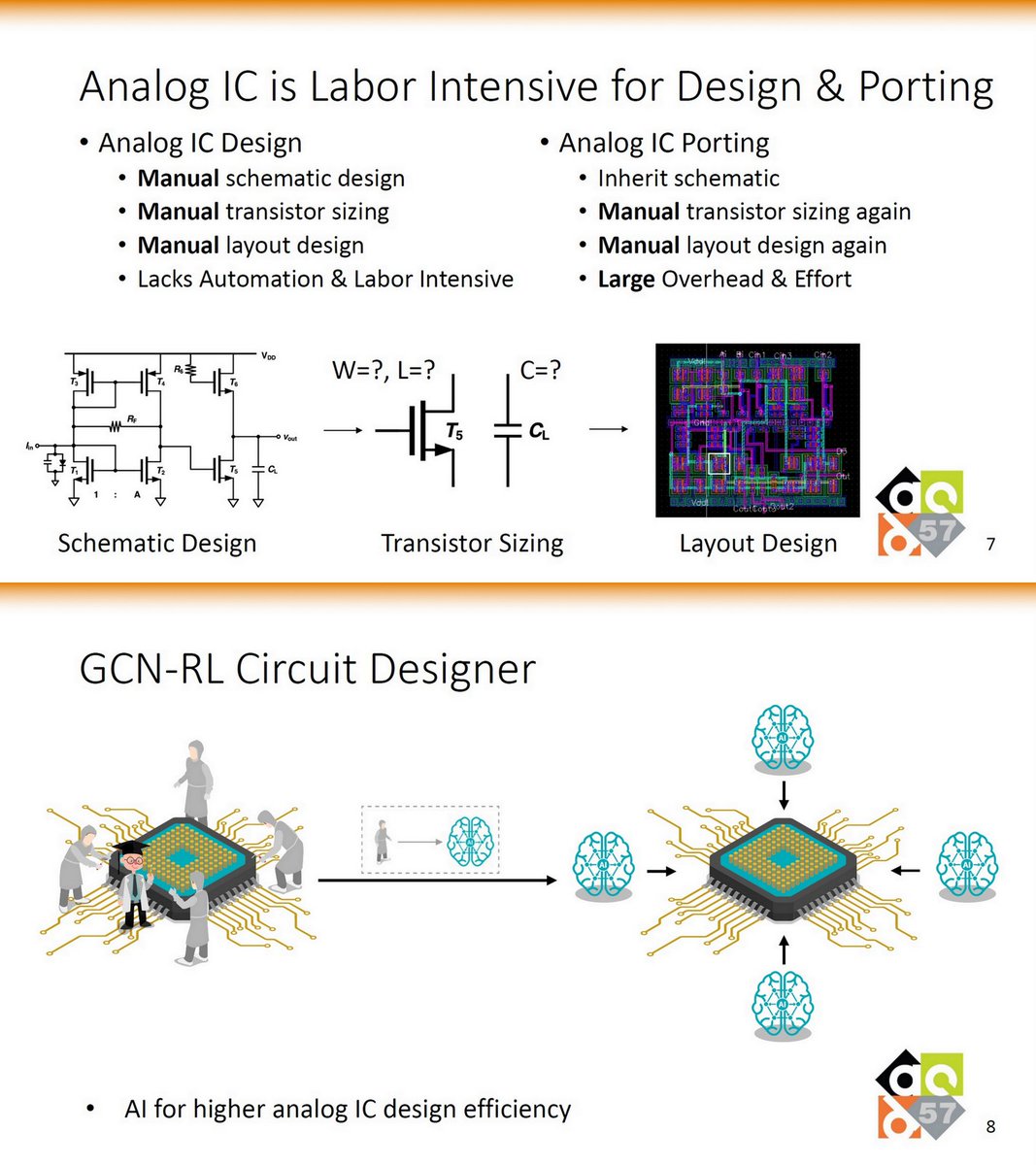
GCN-RL Circuit Designer: Transferable Transistor Sizing With GNNs & RL, Hanrui Wang, .., Song Han, DAC 2020, Jul 24
arxiv.org/abs/2005.00406
hanruiwang.me/project_pages/…
ML-based Design Automation (135 pp), DREAMPlace, Jul 2019
Google
GCN-RL Circuit Designer: Transferable Transistor Sizing With GNNs & RL, Hanrui Wang, .., Song Han, DAC 2020, Jul 24
arxiv.org/abs/2005.00406
hanruiwang.me/project_pages/…
ML-based Design Automation (135 pp), DREAMPlace, Jul 2019
https://twitter.com/ogawa_tter/status/1220879266734231552
https://twitter.com/ogawa_tter/status/1278365378792439808



=>
AIネットワーク社会推進会議 報告書2020、令和2年7月21日 soumu.go.jp/menu_news/s-ne…
AI利活用ガイドライン、令和元年8月9日 soumu.go.jp/menu_news/s-ne…
国際的な議論のためのAI開発ガイドライン案、平成29年7月28日 soumu.go.jp/menu_news/s-ne…
人間中心のAI社会原則会議 cas.go.jp/jp/seisaku/jin…
AIネットワーク社会推進会議 報告書2020、令和2年7月21日 soumu.go.jp/menu_news/s-ne…
AI利活用ガイドライン、令和元年8月9日 soumu.go.jp/menu_news/s-ne…
国際的な議論のためのAI開発ガイドライン案、平成29年7月28日 soumu.go.jp/menu_news/s-ne…
人間中心のAI社会原則会議 cas.go.jp/jp/seisaku/jin…



=>
"Adversarial Attacks and Defenses in Deep Learning", Engineering, Mar 2020 (Jan 3, 2020), Chinese Academy of Engineering sciencedirect.com/science/articl…
115 references
Adversarial ML, Tutorial, AAAI 2019
GARD program, DARPA
"Adversarial Attacks and Defenses in Deep Learning", Engineering, Mar 2020 (Jan 3, 2020), Chinese Academy of Engineering sciencedirect.com/science/articl…
115 references
Adversarial ML, Tutorial, AAAI 2019
https://twitter.com/ogawa_tter/status/1203385659714461696
GARD program, DARPA
https://twitter.com/ogawa_tter/status/1248615337194434562


=>
"Adversarial Sparsity Attacks on Deep Neural Networks", arXiv, Jun 18, 2020 arxiv.org/abs/2006.08020
A systematic methodology to generate adversarial inputs for sparsity attacks
Degradations up to 1.59x in latency
White-box and Black-box versions
"Adversarial Sparsity Attacks on Deep Neural Networks", arXiv, Jun 18, 2020 arxiv.org/abs/2006.08020
A systematic methodology to generate adversarial inputs for sparsity attacks
Degradations up to 1.59x in latency
White-box and Black-box versions
https://twitter.com/ogawa_tter/status/1286608983810170880




=>
How Increasing Power and Advanced Cooling Techniques Are Converging for AI, Supercomputing and Cloud DCs, Feb 10, 2020 embedded-computing.com/home-page/how-…
Vicor
@CerebrasSystems
15kW with Vicor Vertical Power Delivery vicorpower.com/documents/pres…
How Increasing Power and Advanced Cooling Techniques Are Converging for AI, Supercomputing and Cloud DCs, Feb 10, 2020 embedded-computing.com/home-page/how-…
Vicor
https://twitter.com/ogawa_tter/status/1286910679572598784
@CerebrasSystems
https://twitter.com/ogawa_tter/status/1200694836384260096
15kW with Vicor Vertical Power Delivery vicorpower.com/documents/pres…




=>
A New Block Floating Point Arithmetic Unit for Processing AI/ML Workloads in FPGA, Achronix, Mar 3, 2020 achronix.com/node/460
Training DNNs w/ Hybrid Block Floating Point, NIPS 2018 papers.nips.cc/paper/7327-tra…
FPGA Design w/ Integrated NoC, May 18, 2020 achronix.com/node/474
A New Block Floating Point Arithmetic Unit for Processing AI/ML Workloads in FPGA, Achronix, Mar 3, 2020 achronix.com/node/460
Training DNNs w/ Hybrid Block Floating Point, NIPS 2018 papers.nips.cc/paper/7327-tra…
FPGA Design w/ Integrated NoC, May 18, 2020 achronix.com/node/474




=>
"Computation on Sparse Neural Networks: an Inspiration for Future Hardware", ...., Yuan Xie, Alibaba DAMO Academy, arXiv, Apr 24, 2020 arxiv.org/abs/2004.11946
Problems
Pruning algorithms
SW / HW
Future
100 Refs
Yuan Xie, Head damo.alibaba.com/labs/computing…
いつから?、兼任なの?
"Computation on Sparse Neural Networks: an Inspiration for Future Hardware", ...., Yuan Xie, Alibaba DAMO Academy, arXiv, Apr 24, 2020 arxiv.org/abs/2004.11946
Problems
Pruning algorithms
SW / HW
Future
100 Refs
Yuan Xie, Head damo.alibaba.com/labs/computing…
いつから?、兼任なの?




=>
"IPU-M2000 and IPU-POD: New Breakthroughs in AI at scale", @graphcoreai Jul 27, 2020
24:42 graphcore.ai/webinar-record…
Bencmakrs, Jul 13 graphcore.ai/hubfs/assets/p…
IWMLH, Jun 2020
Dissecting Mk1
Jul 15
GRAPHCLOUD
"IPU-M2000 and IPU-POD: New Breakthroughs in AI at scale", @graphcoreai Jul 27, 2020
24:42 graphcore.ai/webinar-record…
Bencmakrs, Jul 13 graphcore.ai/hubfs/assets/p…
IWMLH, Jun 2020
https://twitter.com/ogawa_tter/status/1275704232260382721
Dissecting Mk1
Jul 15
https://twitter.com/ogawa_tter/status/1283640460662079495
GRAPHCLOUD
https://twitter.com/ogawa_tter/status/1284682060146200579




=>
MLPerf Training v0.7 Results, Jul 27, 2020 mlperf.org/training-resul…
Google TPU v3: 4096
Google TPU v4: 256 !! なんと!
NVIDIA V100-SXM3-32GB (350W): 1536
NVIDIA A100-SXM4-40GB (400W): 2048
Huawei Ascend910: 512
3rd Gen Xeon Platinum (28core, 2.70GHz)
Xeon Platinum 8380H 2.90GHz
MLPerf Training v0.7 Results, Jul 27, 2020 mlperf.org/training-resul…
Google TPU v3: 4096
Google TPU v4: 256 !! なんと!
NVIDIA V100-SXM3-32GB (350W): 1536
NVIDIA A100-SXM4-40GB (400W): 2048
Huawei Ascend910: 512
3rd Gen Xeon Platinum (28core, 2.70GHz)
Xeon Platinum 8380H 2.90GHz

=>
MLPerf Training v0.7, Jul 29, 2020
NVIDIA Breaks 16 AI Performance Records in Latest MLPerf Benchmarks blogs.nvidia.com/blog/2020/07/2…
Google claims its new TPUs are 2.7 times faster than the previous generation venturebeat.com/2020/07/29/goo…
TPU v4: 256 !!!
なんと!
MLPerf Training v0.7, Jul 29, 2020
NVIDIA Breaks 16 AI Performance Records in Latest MLPerf Benchmarks blogs.nvidia.com/blog/2020/07/2…
Google claims its new TPUs are 2.7 times faster than the previous generation venturebeat.com/2020/07/29/goo…
https://twitter.com/ogawa_tter/status/1288525278587703297
TPU v4: 256 !!!
なんと!
=>
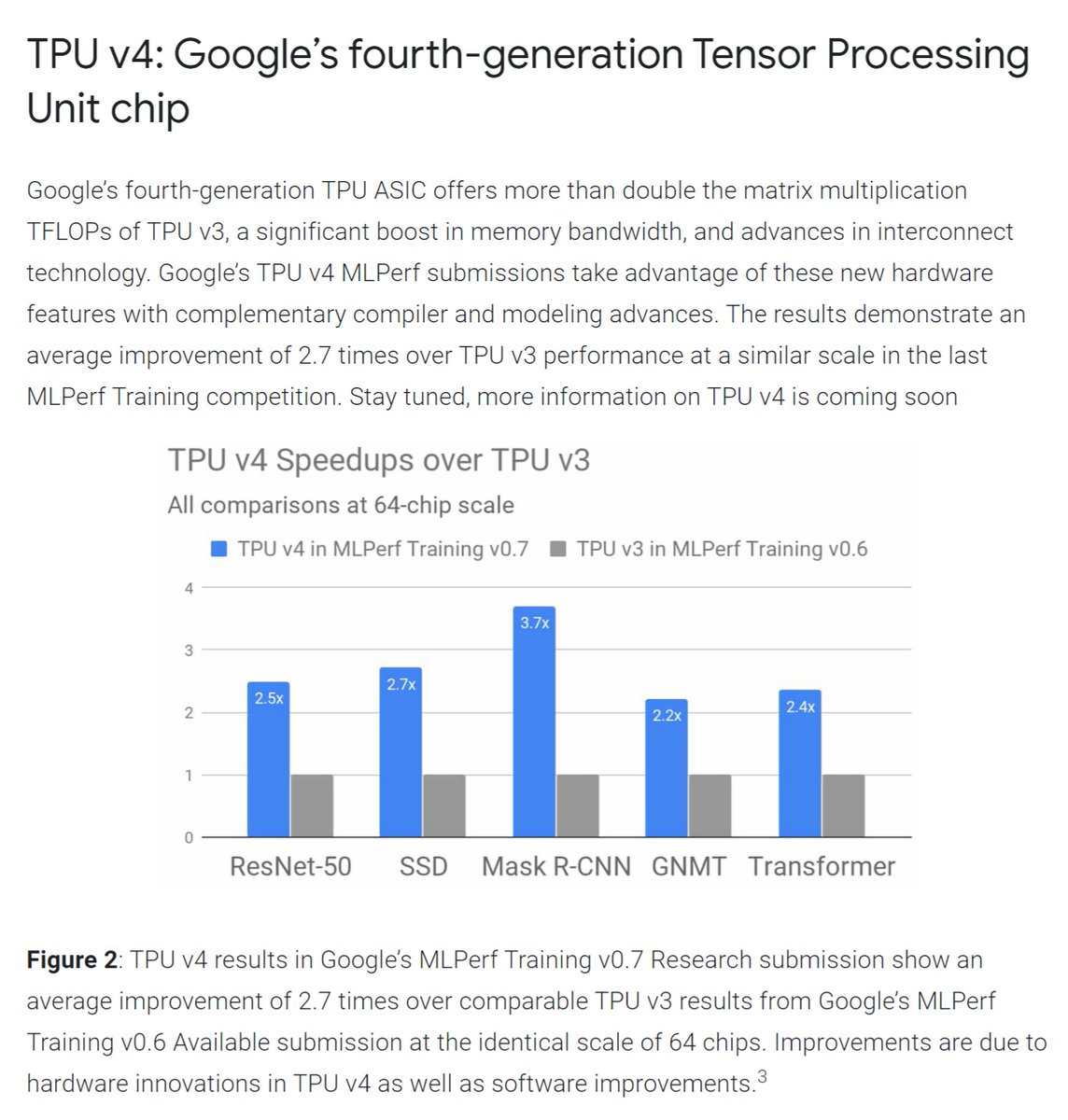
Google: AI performance records in MLPerf with world's fastest training supercomputer, Jul 29, 2020 cloud.google.com/blog/products/…
TPU v4
2x+ Matrix Multiplication
Boost in Memory BW
Interconnect
TPUv2/v3, Jul 2020
MLPerf Training v0.7
Google: AI performance records in MLPerf with world's fastest training supercomputer, Jul 29, 2020 cloud.google.com/blog/products/…
TPU v4
2x+ Matrix Multiplication
Boost in Memory BW
Interconnect
TPUv2/v3, Jul 2020
https://twitter.com/ogawa_tter/status/1273962542230982656
MLPerf Training v0.7
https://twitter.com/ogawa_tter/status/1288525278587703297
=>
"Matrix processing apparatus", Google, Patent, Filed: Feb 5, 2016 (Appl. No: US 15/016,486 ) and Granted: Feb 20, 2018 patents.google.com/patent/US98984…
"including a system for transforming sparse elements into a dense matrix."
Claims (17)
=>
"Matrix processing apparatus", Google, Patent, Filed: Feb 5, 2016 (Appl. No: US 15/016,486 ) and Granted: Feb 20, 2018 patents.google.com/patent/US98984…
"including a system for transforming sparse elements into a dense matrix."
Claims (17)
=>
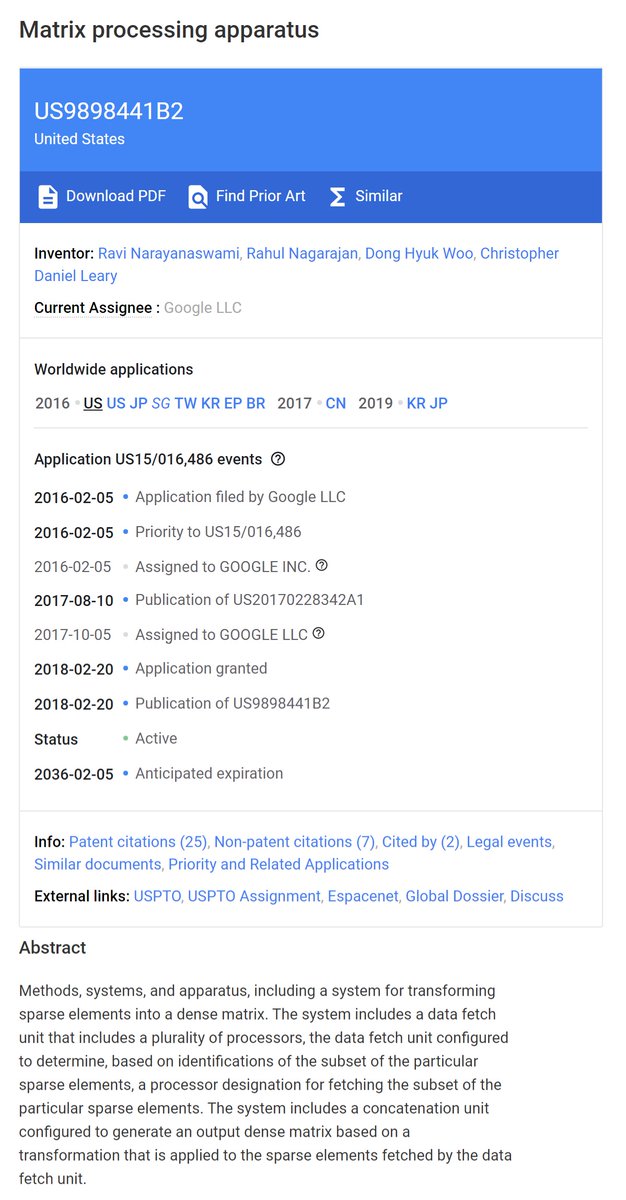



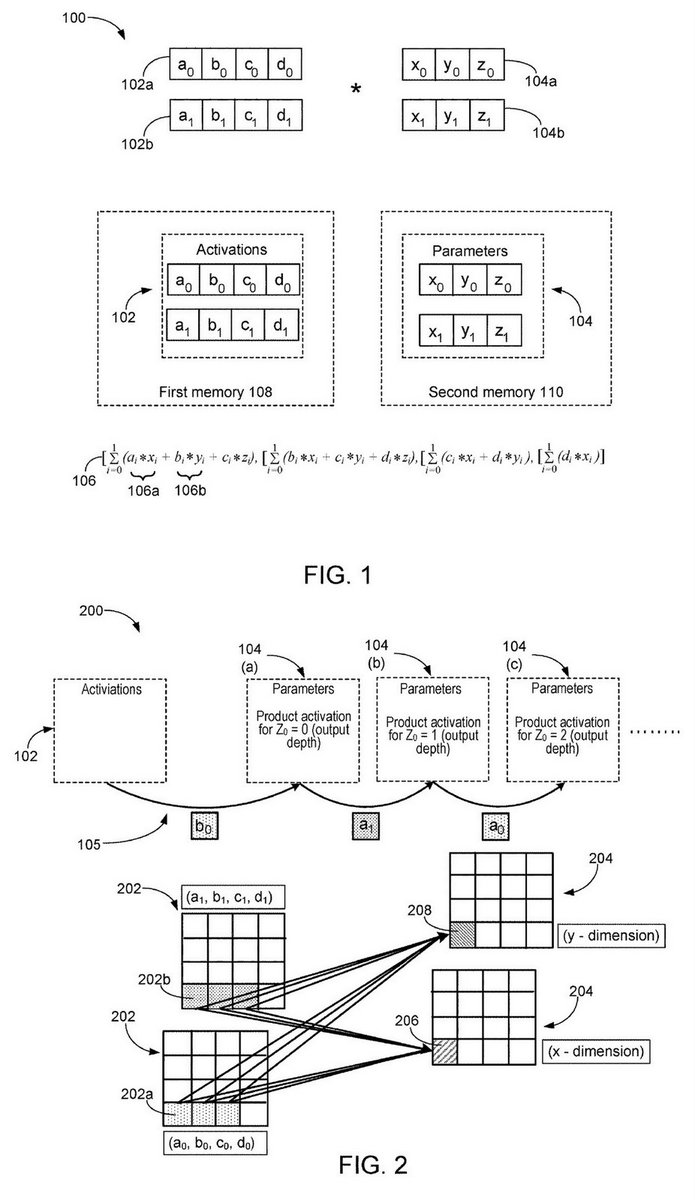
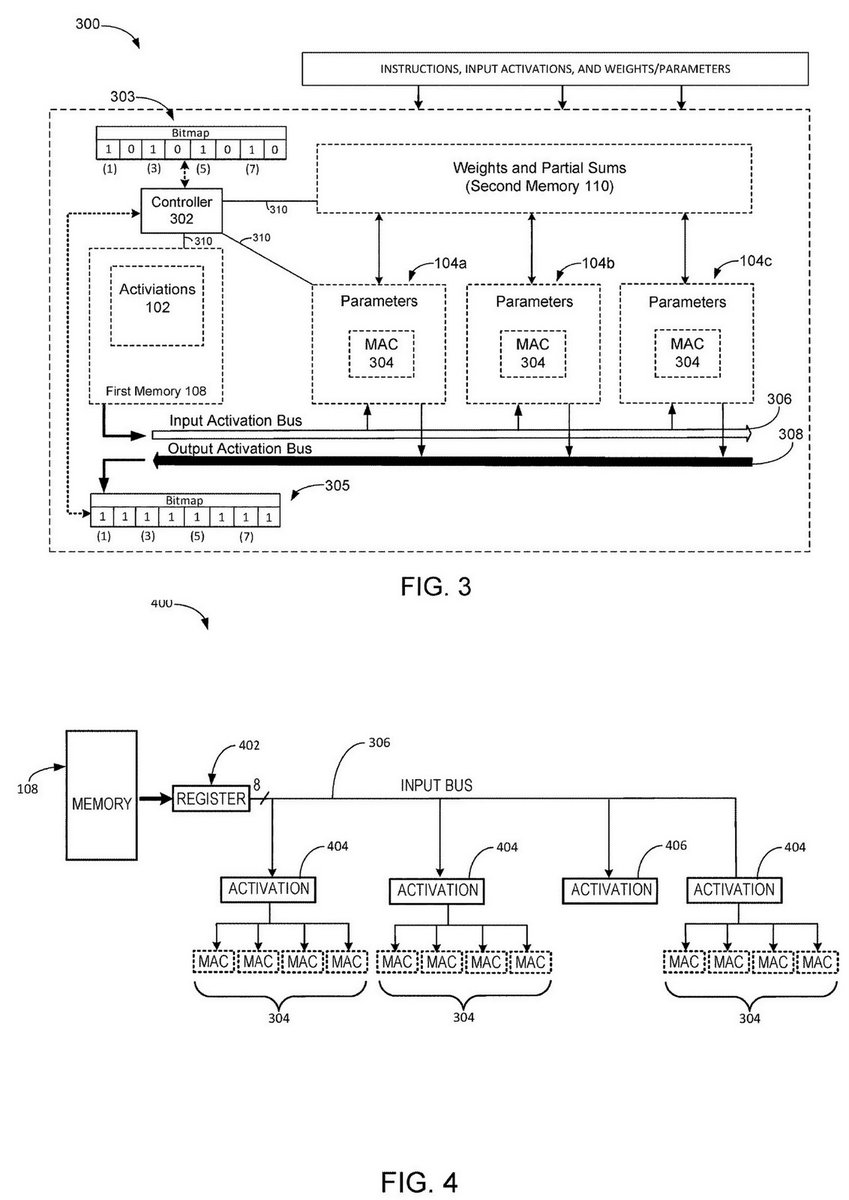
=>
"Exploiting input data sparsity in neural network compute units", Google, Patent, Filed: Oct 27, 2016 and Granted: Jul 23, 2019 patents.google.com/patent/US10360…
The activations, associated with the index.
Matrix processing apparatus, Patent Granted: Feb 2018
"Exploiting input data sparsity in neural network compute units", Google, Patent, Filed: Oct 27, 2016 and Granted: Jul 23, 2019 patents.google.com/patent/US10360…
The activations, associated with the index.
Matrix processing apparatus, Patent Granted: Feb 2018
https://twitter.com/ogawa_tter/status/1288816287175434240


=>
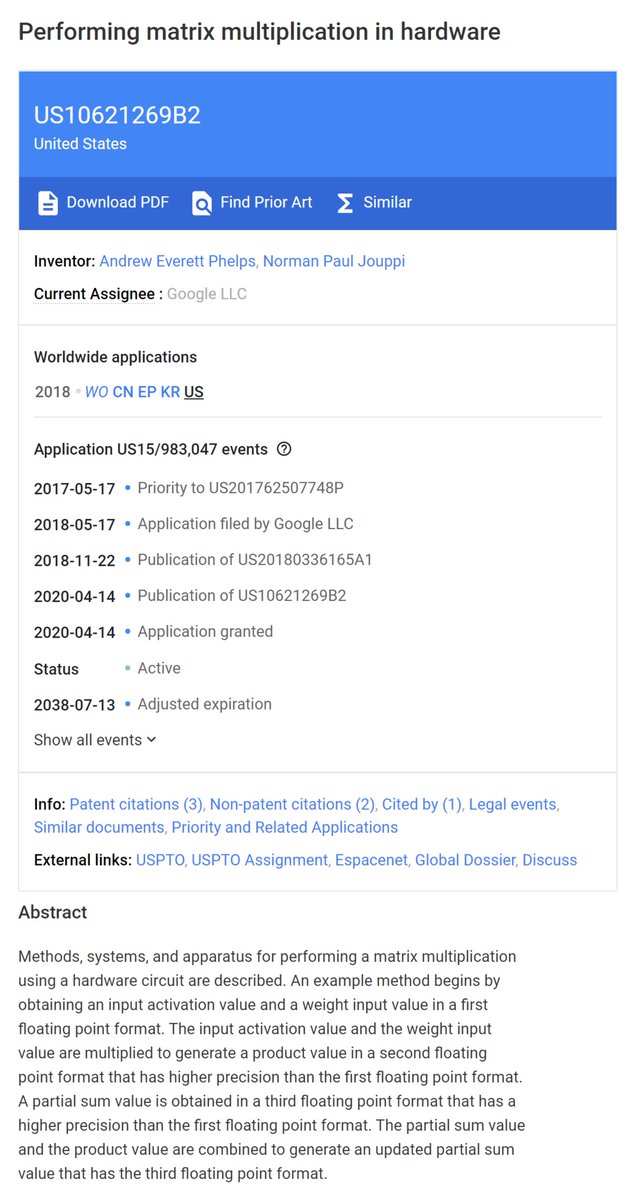
"Performing matrix multiplication in hardware", Google, Patent Granted: Apr 14, 2020 patents.google.com/patent/US10621…
An example sparse computation core maps very sparse, high-dimensional data ....
Patents (15/016,486)
TPUv2/v3, Jul 2020
"Performing matrix multiplication in hardware", Google, Patent Granted: Apr 14, 2020 patents.google.com/patent/US10621…
An example sparse computation core maps very sparse, high-dimensional data ....
Patents (15/016,486)
https://twitter.com/ogawa_tter/status/1288829449786363905
TPUv2/v3, Jul 2020
https://twitter.com/ogawa_tter/status/1273962542230982656



=>
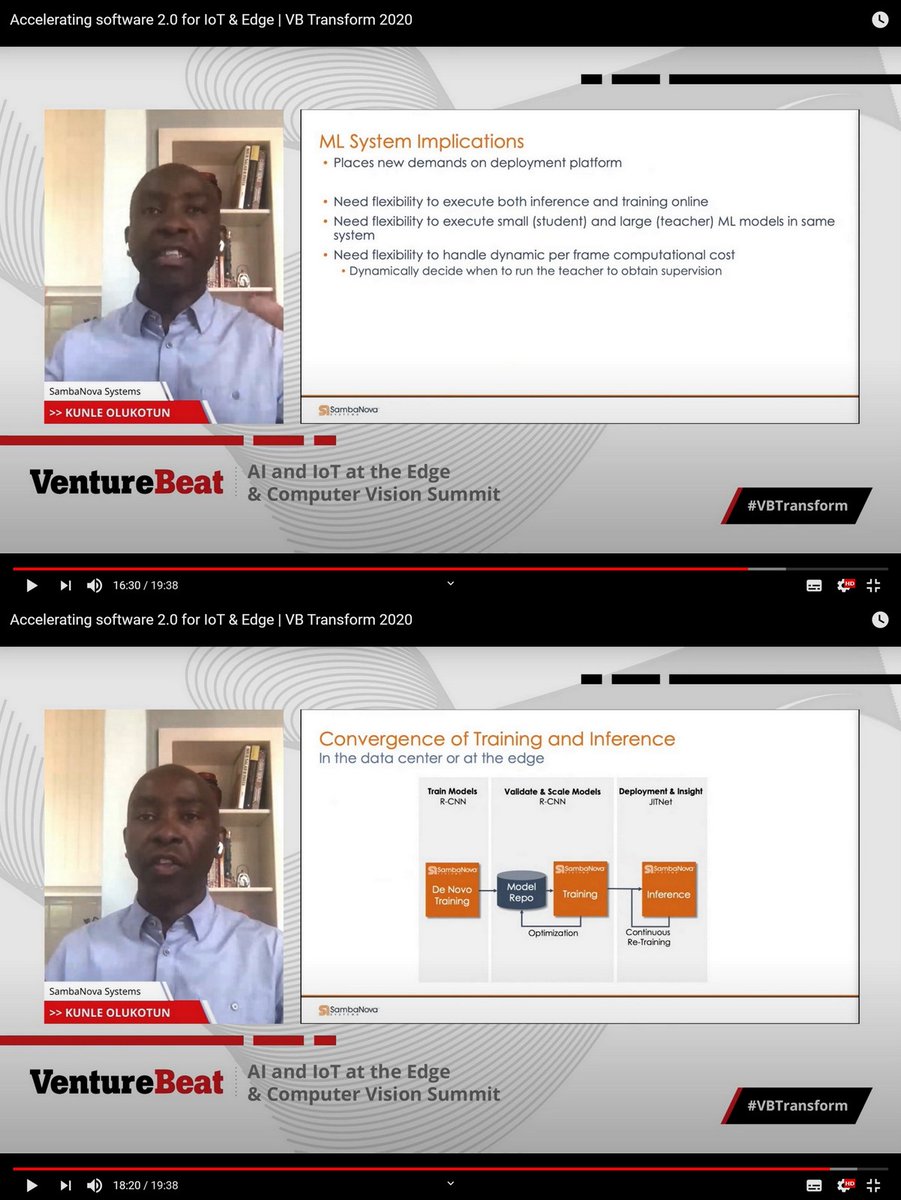
"Accelerating software 2.0 for IoT & Edge", Kunle Olukotun, Chief Technologist & Co-Founder, @SambaNovaAI , and Stanford, VB Transform 2020, Jul 17, 2020
19:38
JITNet, Jan 27, 2020 arxiv.org/abs/1812.02699
IWMLHW, Jun 2020
"Accelerating software 2.0 for IoT & Edge", Kunle Olukotun, Chief Technologist & Co-Founder, @SambaNovaAI , and Stanford, VB Transform 2020, Jul 17, 2020
19:38
JITNet, Jan 27, 2020 arxiv.org/abs/1812.02699
IWMLHW, Jun 2020
https://twitter.com/ogawa_tter/status/1275582463754899456



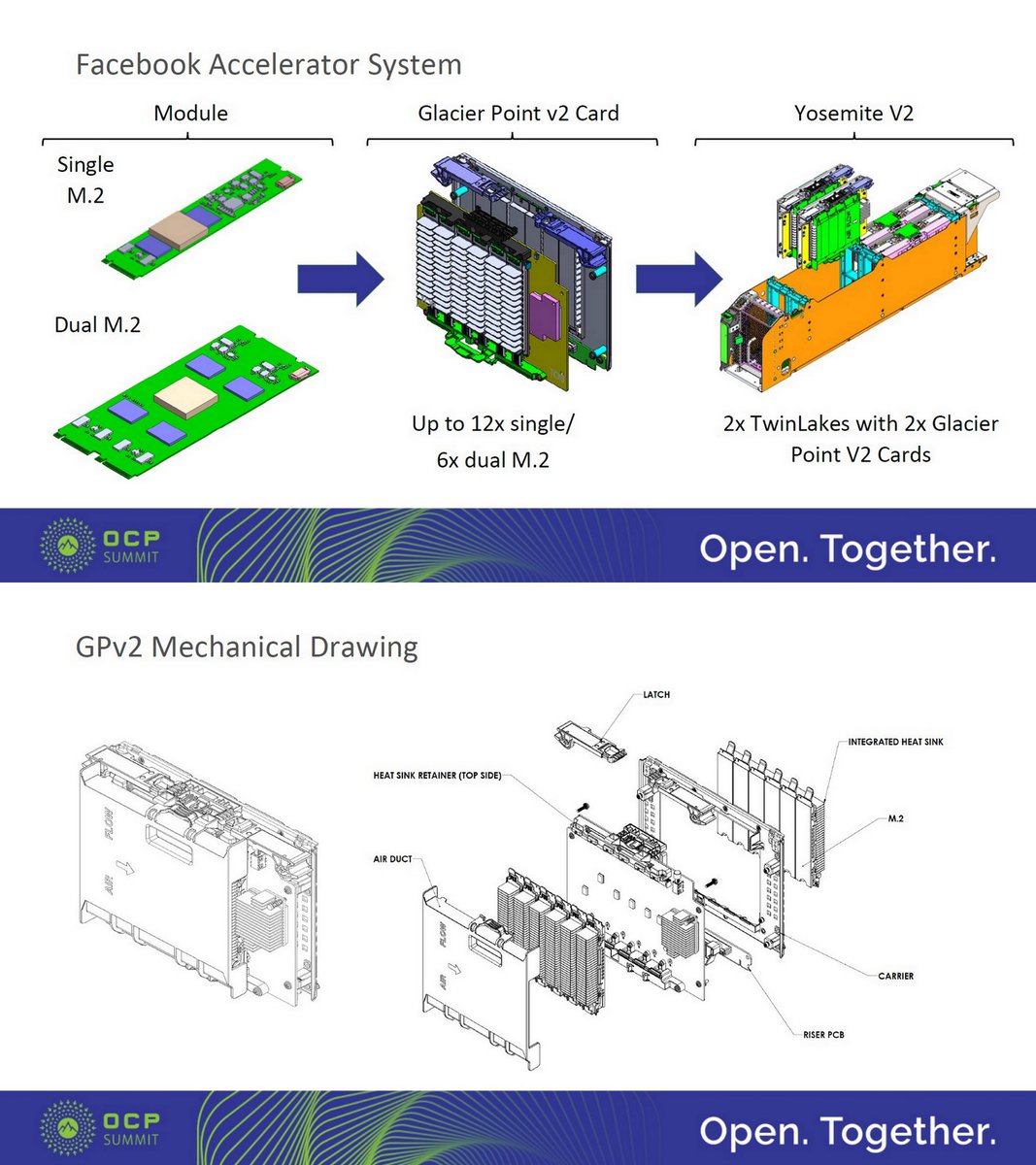
=>
Facebook, Mar 20 2019
Spec Contri files.opencompute.org/oc/public.php?…
-Glaciers Point V2
-M.2 Accelerator
-Dual M.2
Design Spec
Glacier Point V2, v0.1 files.opencompute.org/oc/public.php?…
v0.2, Dec 13. 2019
M.2 files.opencompute.org/oc/public.php?…
Dual M.2 files.opencompute.org/oc/public.php?…
Mar 2019 servethehome.com/10nm-intel-nnp…
Facebook, Mar 20 2019
Spec Contri files.opencompute.org/oc/public.php?…
-Glaciers Point V2
-M.2 Accelerator
-Dual M.2
Design Spec
Glacier Point V2, v0.1 files.opencompute.org/oc/public.php?…
v0.2, Dec 13. 2019
M.2 files.opencompute.org/oc/public.php?…
Dual M.2 files.opencompute.org/oc/public.php?…
Mar 2019 servethehome.com/10nm-intel-nnp…



=>
CEO Interview: Q&A with Ljubisa Bajic of @tenstorrent , Jul 31, 2020 semiwiki.com/artificial-int…
Linley Spring Processor Conf, Apr 9, 2020
18:15
Slides linleygroup.com/events/proceed…
Hot Chips 2020, Aug 18 hotchips.org/program/
CEO Interview: Q&A with Ljubisa Bajic of @tenstorrent , Jul 31, 2020 semiwiki.com/artificial-int…
Linley Spring Processor Conf, Apr 9, 2020
18:15
Slides linleygroup.com/events/proceed…
https://twitter.com/ogawa_tter/status/1247521251196719104
Hot Chips 2020, Aug 18 hotchips.org/program/
=>
"Extreme-scale AI computing with @CerebrasSystems ", ATPESC, Jul 27, 2020 (39 MB / 36 pp) press3.mcs.anl.gov/atpesc/files/2…
IWMLH, Jun 2020
SIMD Instructions
WSE Placement Contest, ISPD 2020
"Extreme-scale AI computing with @CerebrasSystems ", ATPESC, Jul 27, 2020 (39 MB / 36 pp) press3.mcs.anl.gov/atpesc/files/2…
IWMLH, Jun 2020
https://twitter.com/ogawa_tter/status/1275691244799373316
SIMD Instructions
https://twitter.com/ogawa_tter/status/1220152691210346496
WSE Placement Contest, ISPD 2020
https://twitter.com/ogawa_tter/status/1277701520167862272
https://twitter.com/ogawa_tter/status/1223136217849446401




=>
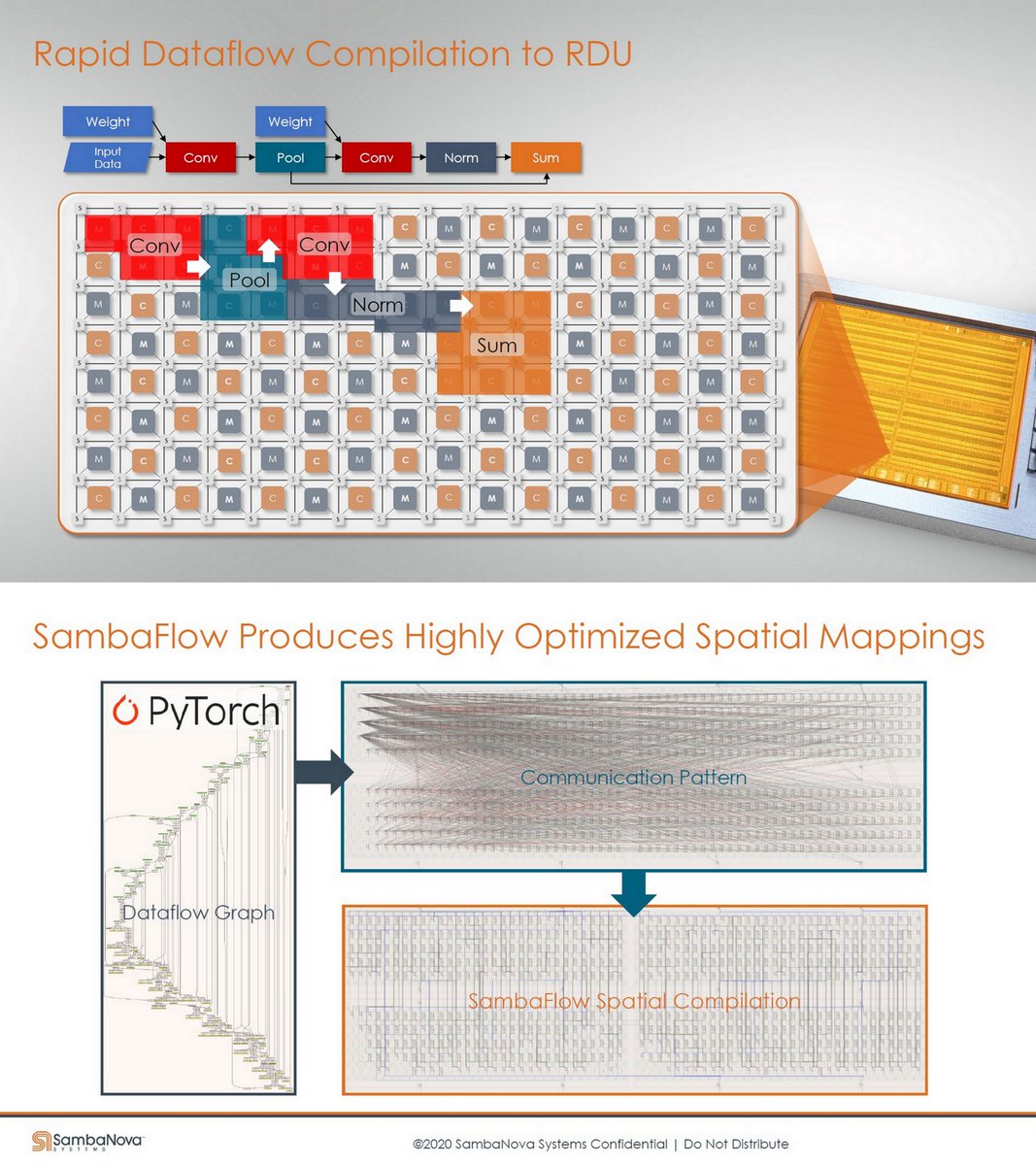
"Accelerating Software 2.0", @SambaNovaAI , ATPESC, Jul 27, 2020 (23 MB / 47 pp) press3.mcs.anl.gov/atpesc/files/2…
PipeMare arxiv.org/abs/1910.05124
IWMLHW, Jun 2020
IoT & Edge, Jul 2020
Democratizing AI, K. Olukotun
"Accelerating Software 2.0", @SambaNovaAI , ATPESC, Jul 27, 2020 (23 MB / 47 pp) press3.mcs.anl.gov/atpesc/files/2…
PipeMare arxiv.org/abs/1910.05124
IWMLHW, Jun 2020
https://twitter.com/ogawa_tter/status/1275582463754899456
IoT & Edge, Jul 2020
https://twitter.com/ogawa_tter/status/1288881342407569408
Democratizing AI, K. Olukotun
https://twitter.com/ogawa_tter/status/1195431844512055296



=>
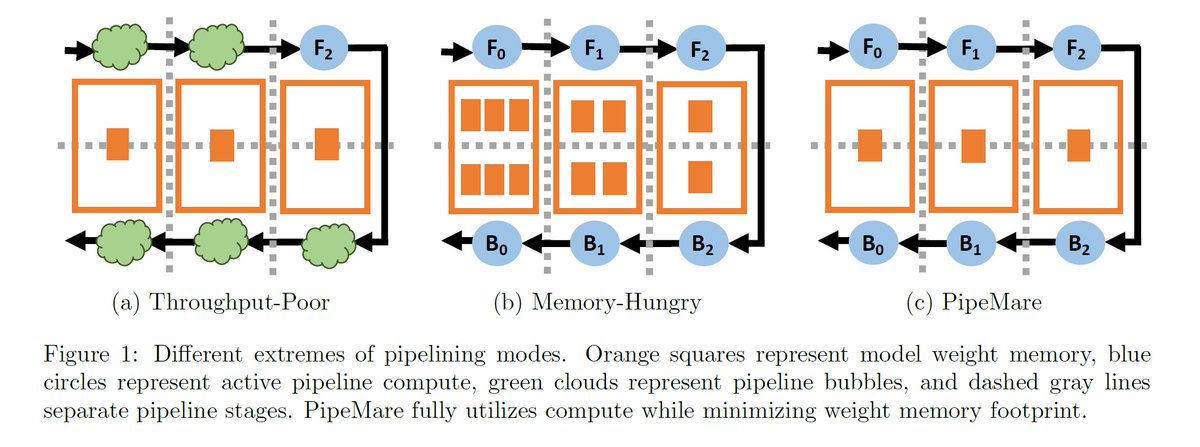
"PipeMare: Asynchronous Pipeline Parallel DNN Training", @SambaNovaAI , arXiv, Feb 9, 2020 arxiv.org/abs/1910.05124
"to use up to 2.7× less memory or get 4.3× higher pipeline utilization, with similar model quality."
Chris De Sa cs.cornell.edu/~cdesa/
"PipeMare: Asynchronous Pipeline Parallel DNN Training", @SambaNovaAI , arXiv, Feb 9, 2020 arxiv.org/abs/1910.05124
"to use up to 2.7× less memory or get 4.3× higher pipeline utilization, with similar model quality."
Chris De Sa cs.cornell.edu/~cdesa/
https://twitter.com/ogawa_tter/status/1289234707821916165



=>
Graph Challenge graphchallenge.mit.edu
Sparse Deep Neural Network Graph Challenge - draft -, Jun 2019, PDF graphchallenge.mit.edu/sites/default/…
arXiv, Sep 2, 2019 arxiv.org/abs/1909.05631
Analysis 2019 Sparce Graph DNN, arXiv, Apr 4, 2020 arxiv.org/abs/2004.01181
2020 Dadeline: July 24 2020
Graph Challenge graphchallenge.mit.edu
Sparse Deep Neural Network Graph Challenge - draft -, Jun 2019, PDF graphchallenge.mit.edu/sites/default/…
arXiv, Sep 2, 2019 arxiv.org/abs/1909.05631
Analysis 2019 Sparce Graph DNN, arXiv, Apr 4, 2020 arxiv.org/abs/2004.01181
2020 Dadeline: July 24 2020




=>
TDK Ventures adds AI accelerator @GroqInc to its portfolio, Aug 4, 2020 tdk-ventures.com/groq
Sixth investment since its July 2019 launch, and the first one in AI space
Predictable, reliable, low-latency. automotive ADAS solutions
via @NicoleHemsoth
TDK Ventures adds AI accelerator @GroqInc to its portfolio, Aug 4, 2020 tdk-ventures.com/groq
Sixth investment since its July 2019 launch, and the first one in AI space
Predictable, reliable, low-latency. automotive ADAS solutions
via @NicoleHemsoth
https://twitter.com/ogawa_tter/status/1275577199014240256
=>
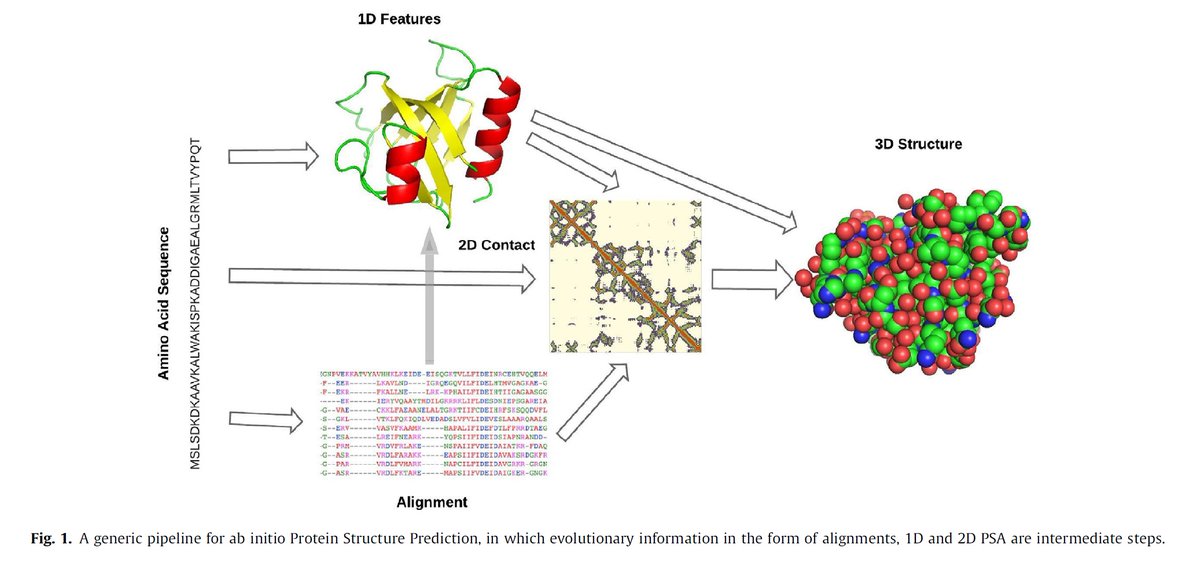
"Deep learning methods in protein structure prediction", Review, Computational and Structural Biotechnology Journal, Jan 22, 2020 sciencedirect.com/science/articl…
Introduction
1D / 2D Protein Structural Annotations
Summary and outlook
153 references
M. Torrisi mirkotorrisi.com
"Deep learning methods in protein structure prediction", Review, Computational and Structural Biotechnology Journal, Jan 22, 2020 sciencedirect.com/science/articl…
Introduction
1D / 2D Protein Structural Annotations
Summary and outlook
153 references
M. Torrisi mirkotorrisi.com


=>
"Benchmarking Graph Neural Networks", Invited, ICML workshop on Graph Representation Learning and Beyond, Jul 17, 2020
32:41 slideslive.com/38930553/bench…
Slides dropbox.com/s/xxzy4wfooeog…
graphdeeplearning.github.io/publication/dw…
arXiv, Jul 3 arxiv.org/abs/2003.00982
Dec 4, 2019
"Benchmarking Graph Neural Networks", Invited, ICML workshop on Graph Representation Learning and Beyond, Jul 17, 2020
32:41 slideslive.com/38930553/bench…
Slides dropbox.com/s/xxzy4wfooeog…
graphdeeplearning.github.io/publication/dw…
arXiv, Jul 3 arxiv.org/abs/2003.00982
Dec 4, 2019
https://twitter.com/ogawa_tter/status/1081244295380660224




=>
"The evolution of citation graphs in Artificial Intelligence research", Nature ML, Feb 11, 2019 PDF web.media.mit.edu/~mrfrank/paper…
"Microsoft Academic Graph to study the bibliometric evolution of AI research and its related fields from 1950 to today."
M. Frank pitt.edu/~mrfrank/
"The evolution of citation graphs in Artificial Intelligence research", Nature ML, Feb 11, 2019 PDF web.media.mit.edu/~mrfrank/paper…
"Microsoft Academic Graph to study the bibliometric evolution of AI research and its related fields from 1950 to today."
M. Frank pitt.edu/~mrfrank/


=>
Next Platform TV for August 6, 2020
Nicolas Sauvage, Managing Director at TDK Ventures
Groq:
Lower power
Predictable latency
@NicoleHemsoth
TDK Ventures adds AI accelerator @GroqInc to its investment portfolio, Aug 4, 2020
Next Platform TV for August 6, 2020
Nicolas Sauvage, Managing Director at TDK Ventures
Groq:
Lower power
Predictable latency
@NicoleHemsoth
TDK Ventures adds AI accelerator @GroqInc to its investment portfolio, Aug 4, 2020
https://twitter.com/ogawa_tter/status/1290727769333051392
=>
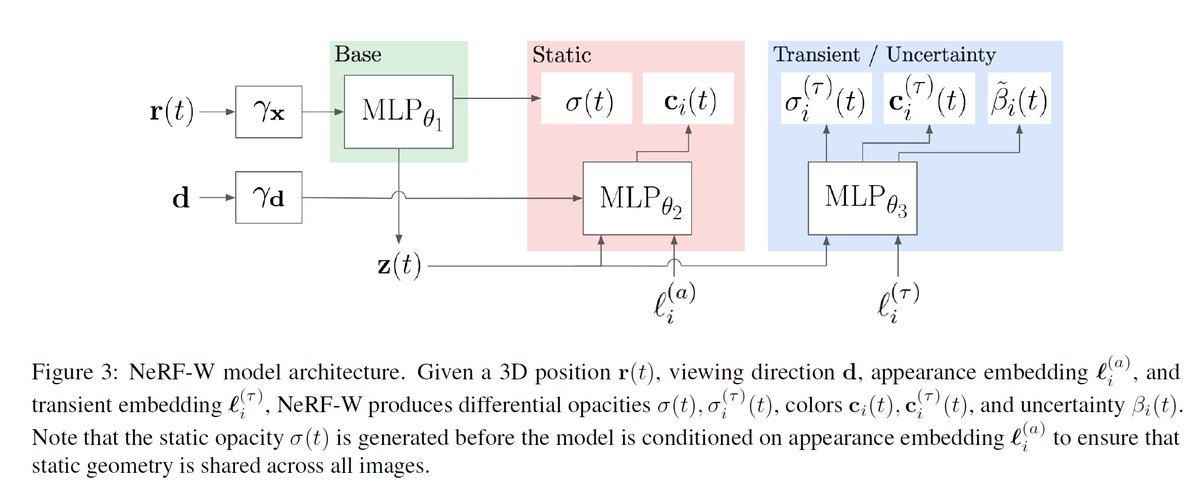
"NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections", Google, arXiv, Aug 5, 2020 arxiv.org/abs/2008.02268
From internet photo collections
able to render novel views under variable lighting conditions
3:41
"NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections", Google, arXiv, Aug 5, 2020 arxiv.org/abs/2008.02268
From internet photo collections
able to render novel views under variable lighting conditions
3:41
https://twitter.com/duck/status/1291310189401059328



=>
"Orchestrating the Development Lifecycle of Machine Learning-Based IoT Applications: A Taxonomy and Survey", arXiv. May 29, 2020 arxiv.org/abs/1910.05433
56 pages
399 references
Rajiv Ranjan rajivranjan.net
"Orchestrating the Development Lifecycle of Machine Learning-Based IoT Applications: A Taxonomy and Survey", arXiv. May 29, 2020 arxiv.org/abs/1910.05433
56 pages
399 references
Rajiv Ranjan rajivranjan.net


=>
"Memory-Latency-Accuracy Trade-offs for Continual Learning on a RISC-V Extreme-Edge Node", @LucaBeniniZhFe , arXiv, Jul 22 2020 arxiv.org/abs/2007.13631
Incrementally improving the decision capabilities based on newly acquired data
Low power RISC-V octa-core @pulp_platform
"Memory-Latency-Accuracy Trade-offs for Continual Learning on a RISC-V Extreme-Edge Node", @LucaBeniniZhFe , arXiv, Jul 22 2020 arxiv.org/abs/2007.13631
Incrementally improving the decision capabilities based on newly acquired data
Low power RISC-V octa-core @pulp_platform




=>
"Intelligent Design Space Exploration for High-Level and System Synthesis", PNNL, Invited, AIDArc 2020, May 30, PDF eecs.oregonstate.edu/aidarc/wp-cont…
DARPA RTML
SODALITE, CIRCT Weekly meeting, Jul 8, 2020 drive.google.com/file/d/1rmdNQW…
CIRCT
"Intelligent Design Space Exploration for High-Level and System Synthesis", PNNL, Invited, AIDArc 2020, May 30, PDF eecs.oregonstate.edu/aidarc/wp-cont…
DARPA RTML
https://twitter.com/ogawa_tter/status/1121514940714475520
SODALITE, CIRCT Weekly meeting, Jul 8, 2020 drive.google.com/file/d/1rmdNQW…
CIRCT
https://twitter.com/ogawa_tter/status/1286144441779019777




=>
"Is network the bottleneck of distributed training?", JHU, AWS, NetAI 2020, Aug 10, 2020 amazon.science/publications/i…
100 Gbps: No need for gradient compression
10 Gbps: 2x – 5x gradients compression ratio to achieve almost linear scale-out
Horovod
ResNet50, ResNet50, VGG16
"Is network the bottleneck of distributed training?", JHU, AWS, NetAI 2020, Aug 10, 2020 amazon.science/publications/i…
100 Gbps: No need for gradient compression
10 Gbps: 2x – 5x gradients compression ratio to achieve almost linear scale-out
Horovod
ResNet50, ResNet50, VGG16




=>
@GroqInc closes round during Covid-19; exceeding expectations, Aug 12, 2020 prnewswire.com/news-releases/…
led by new investor D1 Capital Partners
TDK Ventures
Groq's TSP, IWMLHW, Jun 2020
Revealing more at the AI HW Summit on Sep 29
@GroqInc closes round during Covid-19; exceeding expectations, Aug 12, 2020 prnewswire.com/news-releases/…
led by new investor D1 Capital Partners
TDK Ventures
https://twitter.com/ogawa_tter/status/1291514252906213376
Groq's TSP, IWMLHW, Jun 2020
https://twitter.com/ogawa_tter/status/1275577199014240256
Revealing more at the AI HW Summit on Sep 29
=>
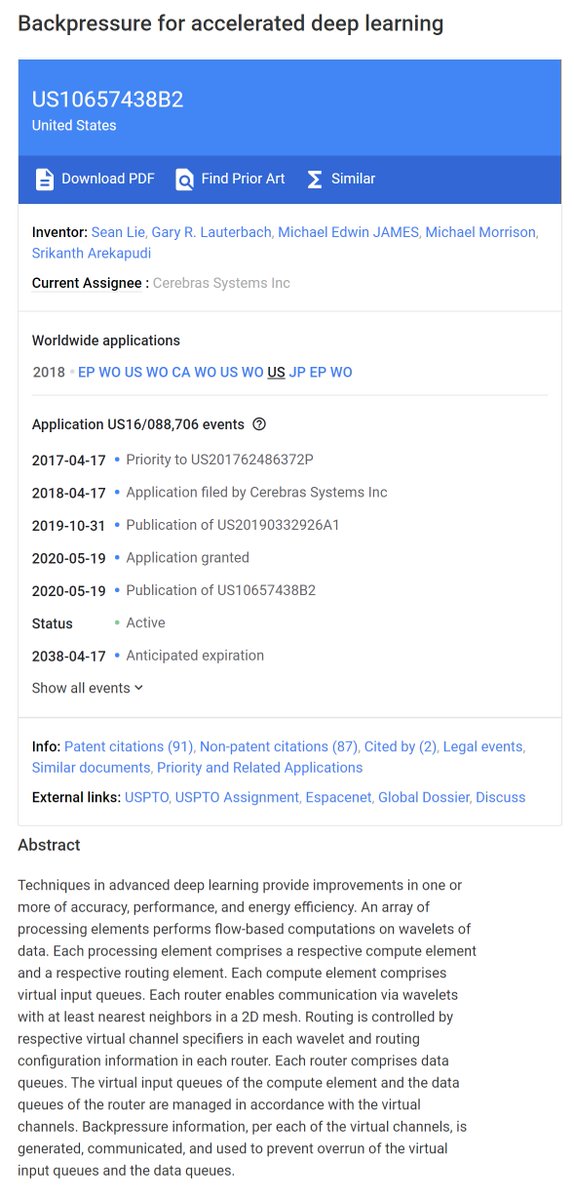
Cerebras, Patents
Accelerated Deep Learning (ADL), Jun 30, 2020 patents.google.com/patent/US10699…
Wavelet Representation for ADL, Dec 24, 2019 patents.google.com/patent/US10515…
Backpressure for ADL, May 5, 20 patents.google.com/patent/US10657…
Dataflow Triggered Tasks for ADL, Apr 7 patents.google.com/patent/US10614…
Cerebras, Patents
Accelerated Deep Learning (ADL), Jun 30, 2020 patents.google.com/patent/US10699…
Wavelet Representation for ADL, Dec 24, 2019 patents.google.com/patent/US10515…
Backpressure for ADL, May 5, 20 patents.google.com/patent/US10657…
Dataflow Triggered Tasks for ADL, Apr 7 patents.google.com/patent/US10614…



=>
Blaize Delivers Breakthrough for AI Edge Computing, Aug 13, 2020 blaize.com/press/blaize-d…
blaize.com/products/ai-ed…
El Cano GSP: 16 TOPS, 7W Typ
Blaize Pathfinder P1600 Embedded SoM
Xplorer X1600E EDSFF Small Form Factor Accelerator Platform
Picasso Software Development Platform
Blaize Delivers Breakthrough for AI Edge Computing, Aug 13, 2020 blaize.com/press/blaize-d…
blaize.com/products/ai-ed…
El Cano GSP: 16 TOPS, 7W Typ
Blaize Pathfinder P1600 Embedded SoM
Xplorer X1600E EDSFF Small Form Factor Accelerator Platform
Picasso Software Development Platform




=>
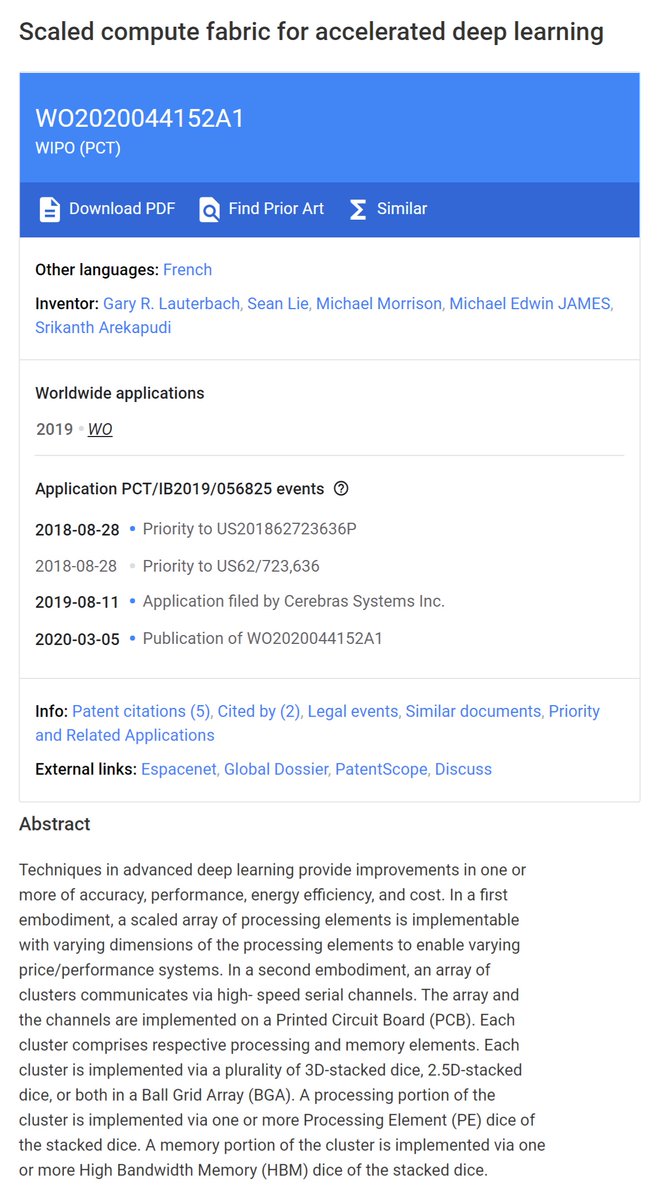
Cerebras, WIPO (PCT), Mar 5, 2020
"Scaled Compute Fabric for Accelerated Deep Learning" patents.google.com/patent/WO20200…
"Processor Element Redundancy for Accelerated Deep Learning" patents.google.com/patent/WO20200…
Granted Patents
Accelerated Deep Learning, Jun 30, 2020
Cerebras, WIPO (PCT), Mar 5, 2020
"Scaled Compute Fabric for Accelerated Deep Learning" patents.google.com/patent/WO20200…
"Processor Element Redundancy for Accelerated Deep Learning" patents.google.com/patent/WO20200…
Granted Patents
https://twitter.com/ogawa_tter/status/1295209243335786496
Accelerated Deep Learning, Jun 30, 2020

=>
342 Transistors for Every Person In the World:
@CerebrasSystems 2nd Gen Wafer Scale Engine Teased, @IanCutress , Aug 18, 2020 10:20 AM EST anandtech.com/show/16000/342…
Hot Chips
"the end of the slide deck, there's a special slide."
WIPO (PCT), Mar 5, 2020
342 Transistors for Every Person In the World:
@CerebrasSystems 2nd Gen Wafer Scale Engine Teased, @IanCutress , Aug 18, 2020 10:20 AM EST anandtech.com/show/16000/342…
Hot Chips
"the end of the slide deck, there's a special slide."
WIPO (PCT), Mar 5, 2020
https://twitter.com/ogawa_tter/status/1295823046364688385
=>
LLNL pairs world's largest computer chip from @CerebrasSystems with Lassen to advance machine learning, AI research, Aug 19, 2020 llnl.gov/news/llnl-pair…
Wafer-scale AI for science and HPC, CS-1, JUn 2020
B Spears. LLNL, May 2020
LLNL pairs world's largest computer chip from @CerebrasSystems with Lassen to advance machine learning, AI research, Aug 19, 2020 llnl.gov/news/llnl-pair…
Wafer-scale AI for science and HPC, CS-1, JUn 2020
https://twitter.com/ogawa_tter/status/1275691244799373316
B Spears. LLNL, May 2020
https://twitter.com/ogawa_tter/status/1263389042999062528
=>
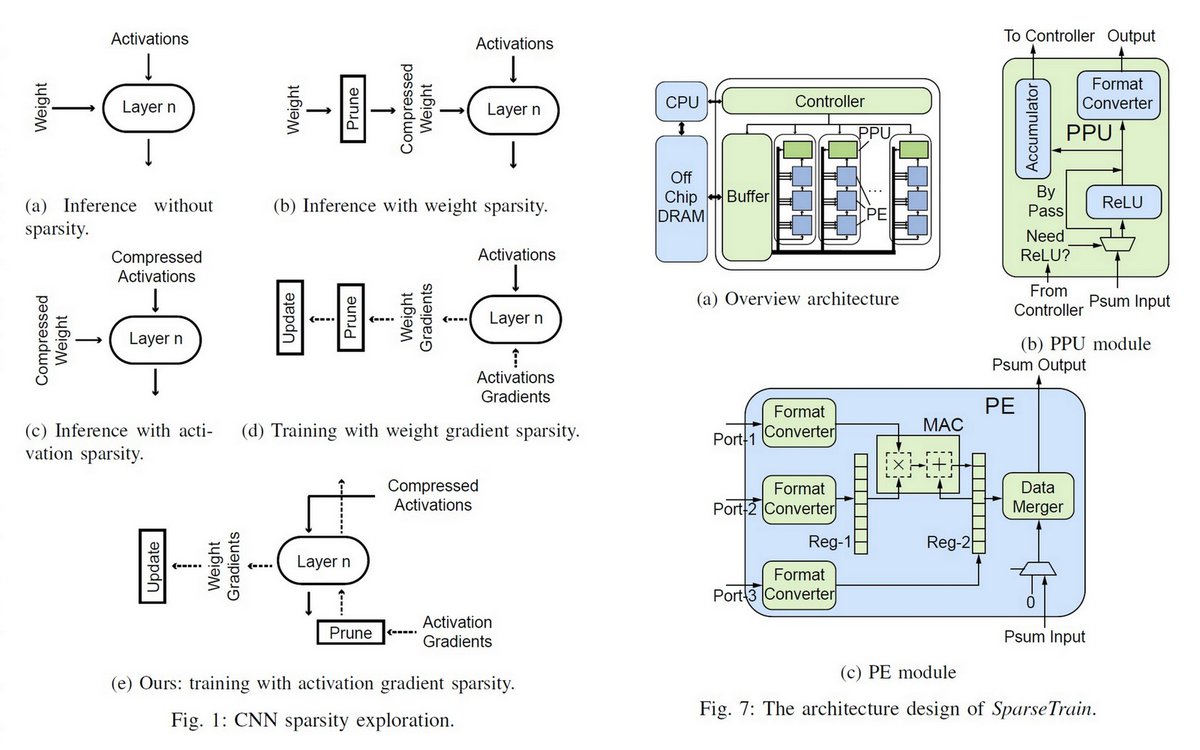
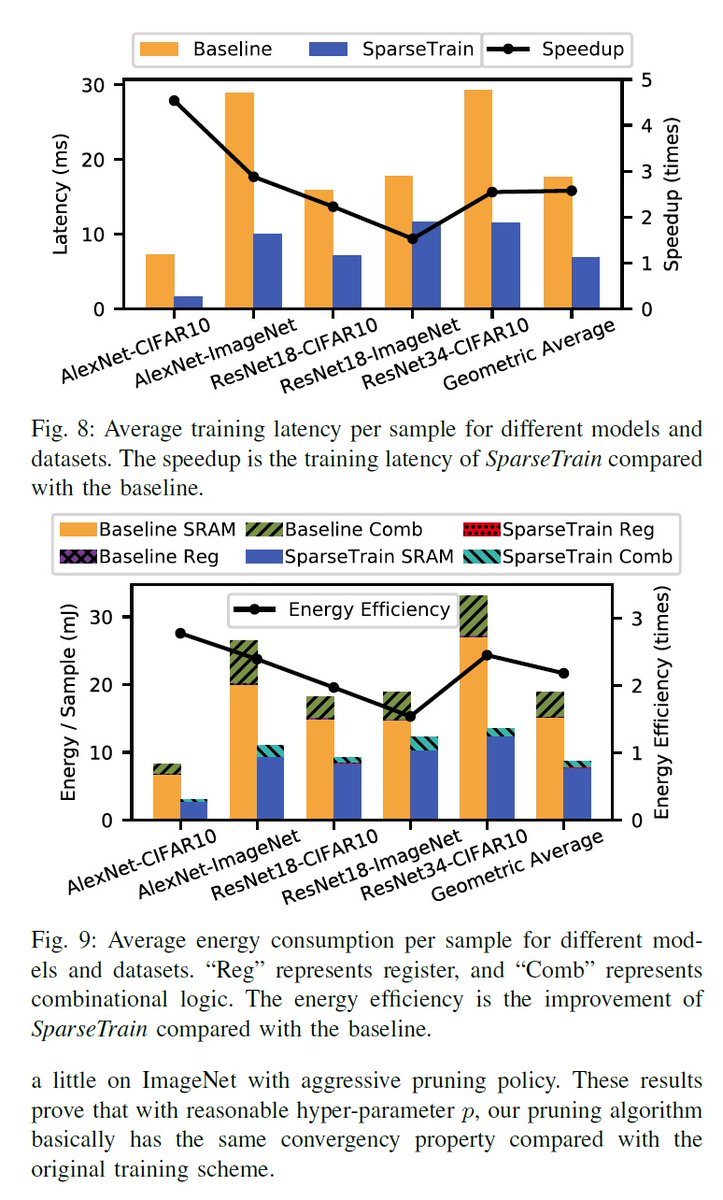
"SparseTrain: Exploiting Dataflow Sparsity for Efficient Convolutional Neural Networks Training", arXiv, Jul 21, 2020 (DAC 2020?) arxiv.org/abs/2007.13595
Activation gradients pruning
Sparse training dataflow
Accelerator
AlexNet/ResNe: 2:7x speedup and 2:2x energy efficiency
"SparseTrain: Exploiting Dataflow Sparsity for Efficient Convolutional Neural Networks Training", arXiv, Jul 21, 2020 (DAC 2020?) arxiv.org/abs/2007.13595
Activation gradients pruning
Sparse training dataflow
Accelerator
AlexNet/ResNe: 2:7x speedup and 2:2x energy efficiency


=>
"Robust Machine Learning Systems: Challenges, Current Trends, Perspectives, and the Road Ahead", IEEE Design & Test, Apr 2020, PDF people.inf.ethz.ch/omutlu/pub/rob…
@_onurmutlu_
Security Threats (Defenses)
Reliability Threats (Mitigation)
Formal Verification for DNNs
22 pp, 184 ref
"Robust Machine Learning Systems: Challenges, Current Trends, Perspectives, and the Road Ahead", IEEE Design & Test, Apr 2020, PDF people.inf.ethz.ch/omutlu/pub/rob…
@_onurmutlu_
Security Threats (Defenses)
Reliability Threats (Mitigation)
Formal Verification for DNNs
22 pp, 184 ref




=>
"Technical Overview of the Cerebras CS-1, the AI Compute Engine for Neocortex", Natalia Vassilieva, @CerebrasSystems , Aug 19, 2020
58:56
Slides (39 MB) cmu.edu/psc/aibd/neoco…
Intro to Neocortex, Jul 15
"Technical Overview of the Cerebras CS-1, the AI Compute Engine for Neocortex", Natalia Vassilieva, @CerebrasSystems , Aug 19, 2020
58:56
Slides (39 MB) cmu.edu/psc/aibd/neoco…
Intro to Neocortex, Jul 15
https://twitter.com/ogawa_tter/status/1285051293967413248
https://twitter.com/ogawa_tter/status/1220152691210346496




=>
"A survey of FPGA design for AI era", J. of Semiconductors, Feb 2020 jos.ac.cn/article/doi/10…
Xilinx Versal AI Core, Hot Chips 2019
Compiling for Xilinx AI Engine using MLIR, Feb 2020
Intel Stratix 10 NX
"A survey of FPGA design for AI era", J. of Semiconductors, Feb 2020 jos.ac.cn/article/doi/10…
Xilinx Versal AI Core, Hot Chips 2019
https://twitter.com/ogawa_tter/status/1208268169875320833
Compiling for Xilinx AI Engine using MLIR, Feb 2020
https://twitter.com/ogawa_tter/status/1257318701944016900
Intel Stratix 10 NX
https://twitter.com/ogawa_tter/status/1273762221714096129


=>
" Merlin: A GPU Accelerated Recommendation Framework", NVIDIA, Oral, Int WS on Industrial Recommendation Systems (IRS 2020), Aug 24
PDF irsworkshop.github.io/2020/publicati…
12;18
Announcing NVIDIA Merlin, May 14, 2020 developer.nvidia.com/blog/announcin…
developer.nvidia.com/nvidia-merlin
" Merlin: A GPU Accelerated Recommendation Framework", NVIDIA, Oral, Int WS on Industrial Recommendation Systems (IRS 2020), Aug 24
PDF irsworkshop.github.io/2020/publicati…
12;18
Announcing NVIDIA Merlin, May 14, 2020 developer.nvidia.com/blog/announcin…
developer.nvidia.com/nvidia-merlin



=>
"Large-Scale Discrete Fourier Transform on TPUs", Google Res, arXiv, Feb 9, 2020 arxiv.org/abs/2002.03260
2D DFT: 128 TPU core
3D DFT: Full TPU Pod with 2048 TPU cores.
TPUv2/v3, CACM, Jul 2020
Live Blog, Hot Chips 2020, Aug 18 anandtech.com/show/16005/hot…
=>
"Large-Scale Discrete Fourier Transform on TPUs", Google Res, arXiv, Feb 9, 2020 arxiv.org/abs/2002.03260
2D DFT: 128 TPU core
3D DFT: Full TPU Pod with 2048 TPU cores.
TPUv2/v3, CACM, Jul 2020
https://twitter.com/ogawa_tter/status/1273962542230982656
Live Blog, Hot Chips 2020, Aug 18 anandtech.com/show/16005/hot…
=>



=>
"Accelerating MRI Reconstruction on TPUs", Google Research and Harvard Medical School, arXiv, Jun 24 2020 (HPEC 2020) arxiv.org/abs/2006.14080
Implemented with precision FP32 (CPU: FP64)
NUFFT on TPUs is on-going
Large-Scale DFT on TPUs,, arXiv, Feb 2020
"Accelerating MRI Reconstruction on TPUs", Google Research and Harvard Medical School, arXiv, Jun 24 2020 (HPEC 2020) arxiv.org/abs/2006.14080
Implemented with precision FP32 (CPU: FP64)
NUFFT on TPUs is on-going
Large-Scale DFT on TPUs,, arXiv, Feb 2020
https://twitter.com/ogawa_tter/status/1297768149605945345




=>
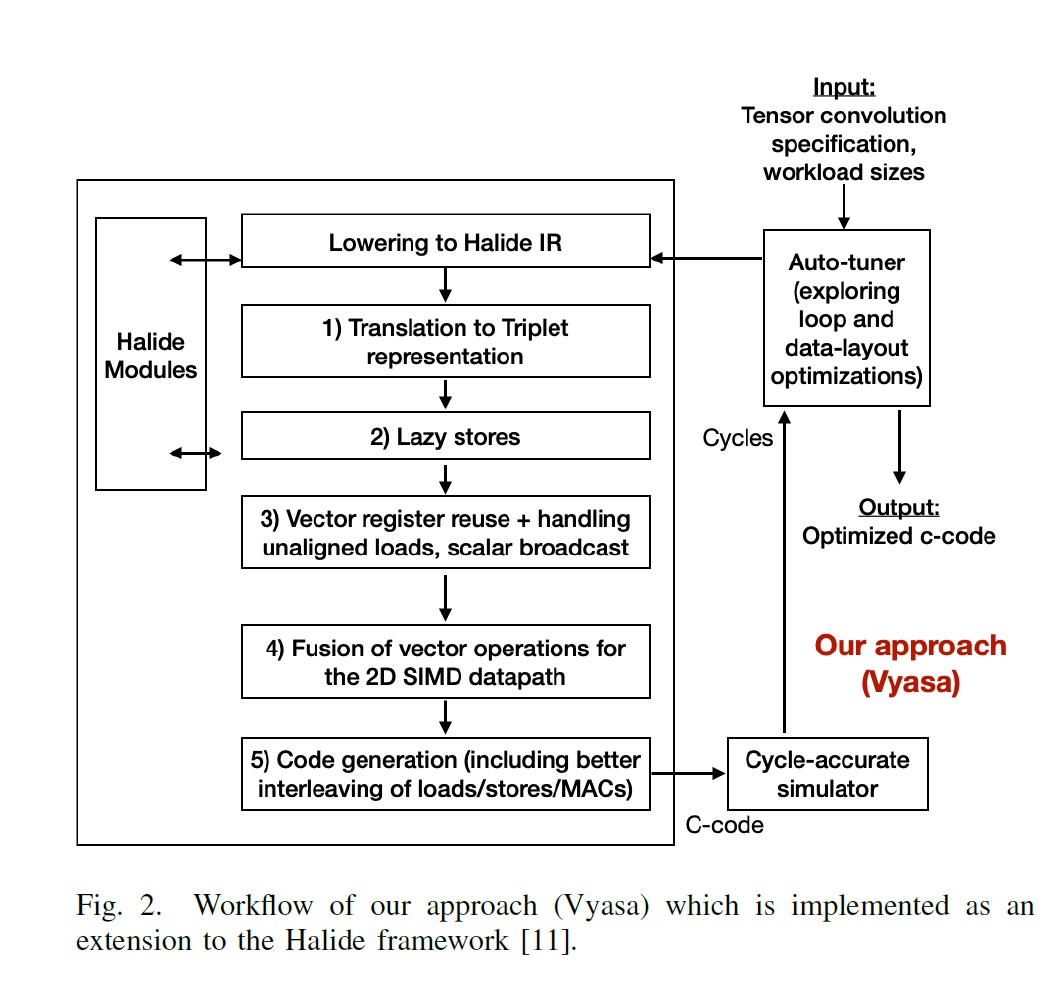
"Vyasa: A High-Performance Vectorizing Compiler for Tensor Convolutions on the Xilinx AI Engine", GaTech, Xilinx, arXiv, Jun 2, 2020 (HPEC 2020) arxiv.org/abs/2006.01331
on the Halide framework
Xilinx AI Engine, Whitepaper, Jul 10 xilinx.com/support/docume…
"Vyasa: A High-Performance Vectorizing Compiler for Tensor Convolutions on the Xilinx AI Engine", GaTech, Xilinx, arXiv, Jun 2, 2020 (HPEC 2020) arxiv.org/abs/2006.01331
on the Halide framework
Xilinx AI Engine, Whitepaper, Jul 10 xilinx.com/support/docume…
https://twitter.com/ogawa_tter/status/1297435086866980864



=>
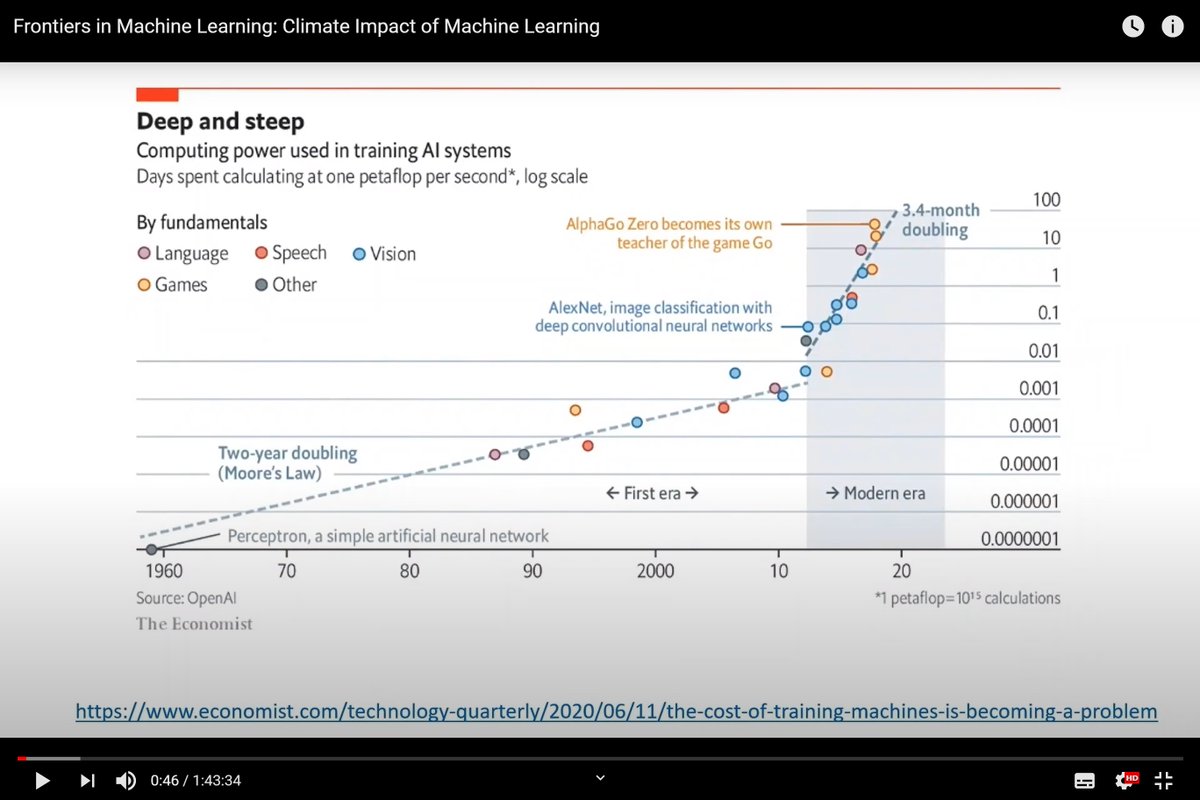
Frontiers in Machine Learning 2020, Jul 20-23, 2020, Microsoft Research microsoft.com/en-us/research…
Climate Impact of Machine Learning, Jul 23,, 2020
1:43:34
Philip Rosenfield, Microsoft
Emma Strubell, CMU
Vivienne Sze, MIT
Diana Marculescu, UT Austin
Frontiers in Machine Learning 2020, Jul 20-23, 2020, Microsoft Research microsoft.com/en-us/research…
Climate Impact of Machine Learning, Jul 23,, 2020
1:43:34
Philip Rosenfield, Microsoft
Emma Strubell, CMU
Vivienne Sze, MIT
Diana Marculescu, UT Austin



=>
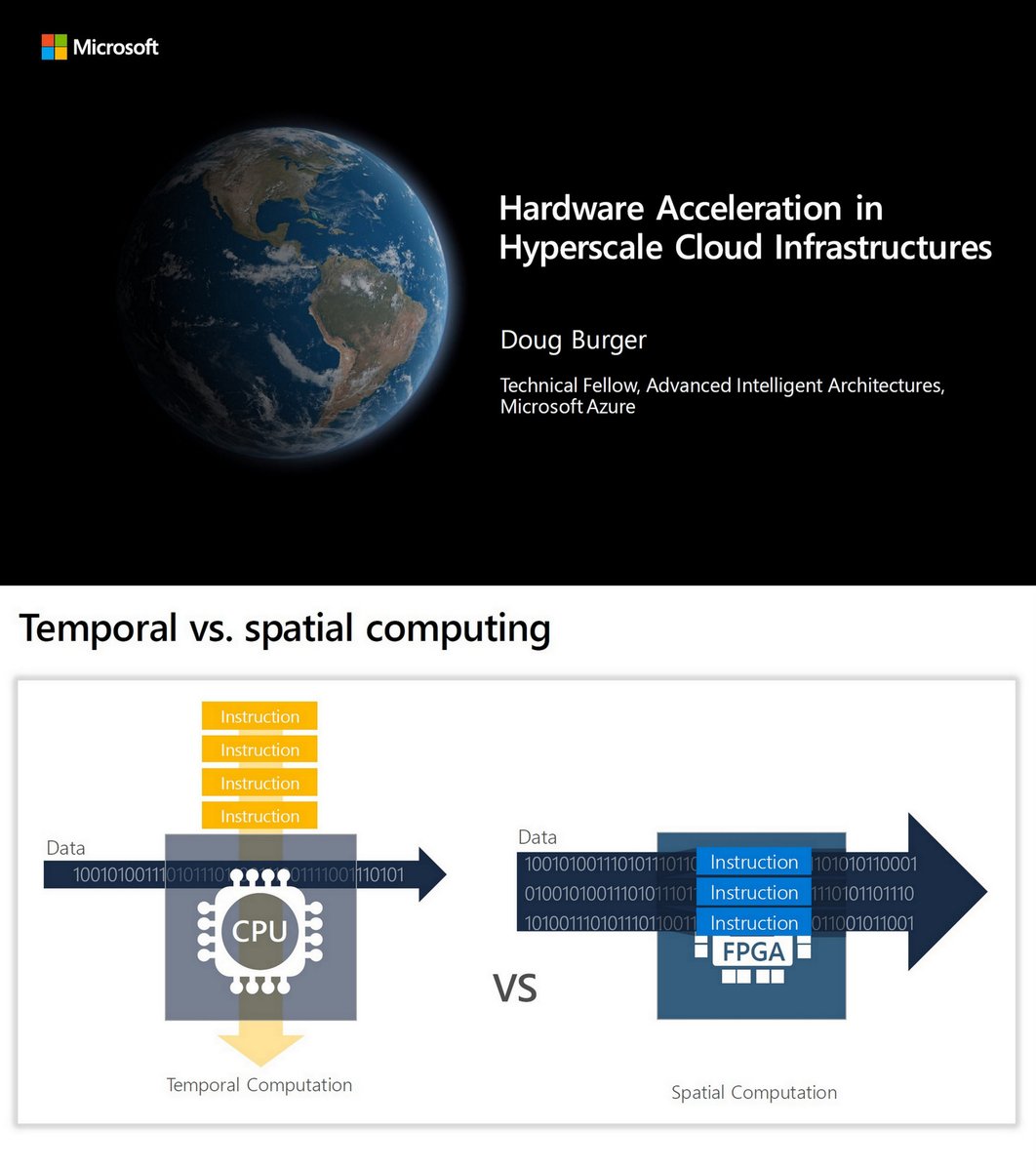
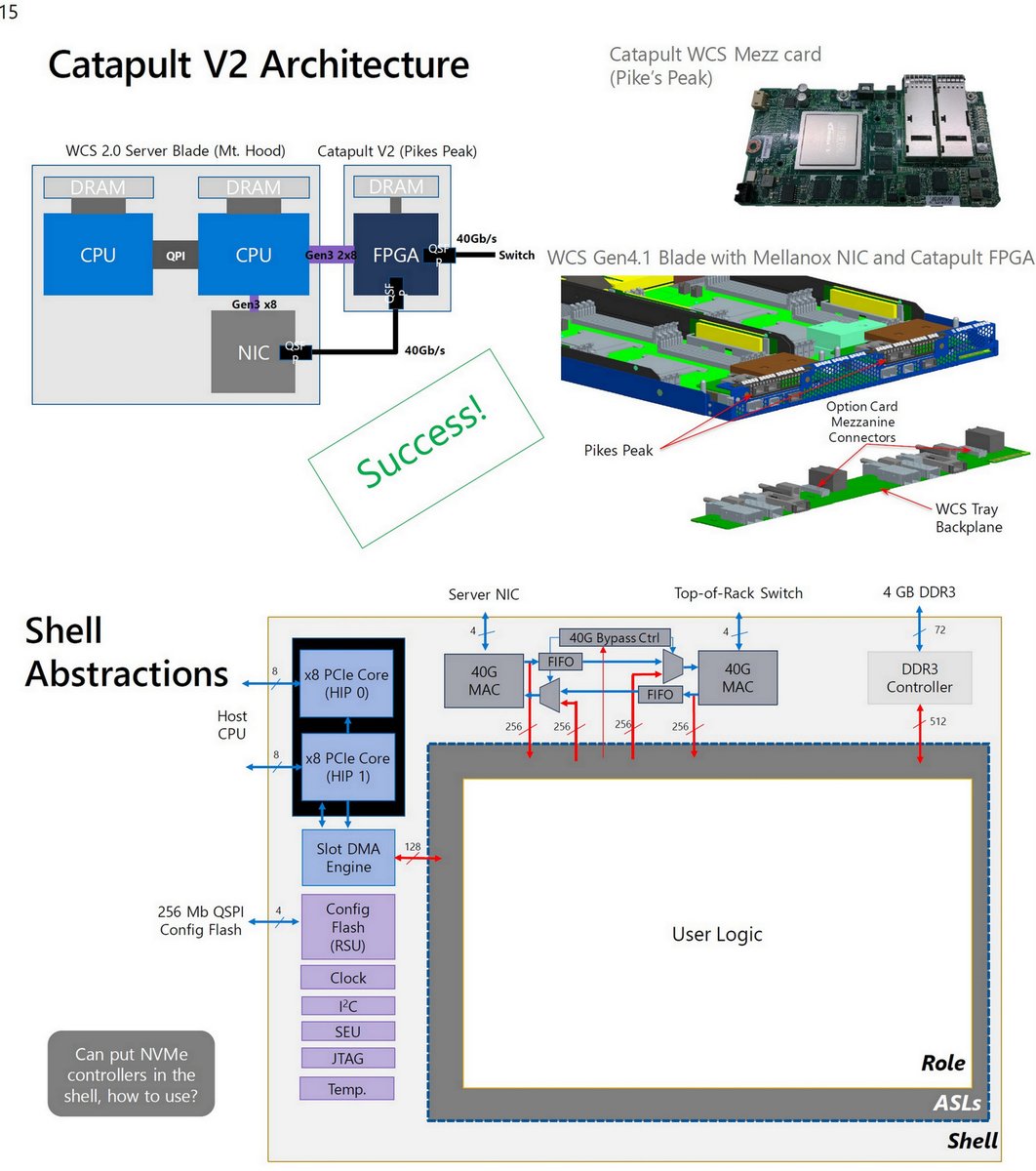
"Hardware Acceleration in Hyperscale Cloud Infrastructures", Doug Burger, Microsoft, Keynote, HPTS 2019, Nov 4, 2019 (68 pp) hpts.ws/papers/2019/bu…
Catapult V0
Catapult V1
No one else wanted the secondary network
No killer infrastructure accelerator
"Hardware Acceleration in Hyperscale Cloud Infrastructures", Doug Burger, Microsoft, Keynote, HPTS 2019, Nov 4, 2019 (68 pp) hpts.ws/papers/2019/bu…
Catapult V0
Catapult V1
No one else wanted the secondary network
No killer infrastructure accelerator
https://twitter.com/ogawa_tter/status/1266777729963143168


=>
"Reducing the Cost of Neural Network Inference with Residue Number Systems", Arm Research Blog, Aug 21, 2020 community.arm.com/developer/rese…
"Efficient Residue Number System Based Winograd Convolution", Arm, ECCV 2020 PDF ecva.net/papers/eccv_20…
Supplementary ecva.net/papers/eccv_20…
"Reducing the Cost of Neural Network Inference with Residue Number Systems", Arm Research Blog, Aug 21, 2020 community.arm.com/developer/rese…
"Efficient Residue Number System Based Winograd Convolution", Arm, ECCV 2020 PDF ecva.net/papers/eccv_20…
Supplementary ecva.net/papers/eccv_20…

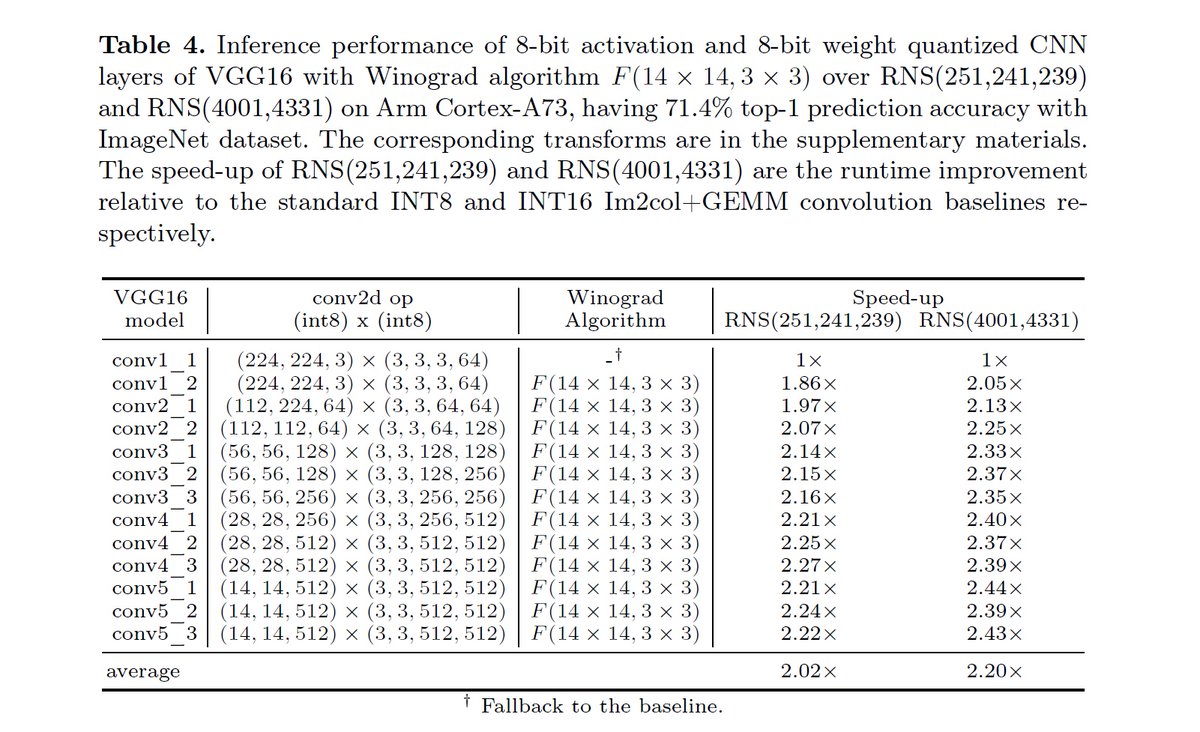

=>
"NSF advances artificial intelligence research with new nationwide institutes", Aug 26, 2020 nsf.gov/news/special_r…
Over the next five years
NSF $100+ million for five
USDA: $40 million for two
beta.nsf.gov/science-matter…
"NSF advances artificial intelligence research with new nationwide institutes", Aug 26, 2020 nsf.gov/news/special_r…
Over the next five years
NSF $100+ million for five
USDA: $40 million for two
beta.nsf.gov/science-matter…
https://twitter.com/ogawa_tter/status/1161203359254106112

=>
ASML: Driving the future of microchips with Google Cloud AI and machine learning capabilities, Case Study, Google Cloud cloud.google.com/customers/asml
A Hubaux, Technical Program Manager AI/ML, ASML ahubaux.com
ML in Computational Lithography, ASML
ASML: Driving the future of microchips with Google Cloud AI and machine learning capabilities, Case Study, Google Cloud cloud.google.com/customers/asml
A Hubaux, Technical Program Manager AI/ML, ASML ahubaux.com
ML in Computational Lithography, ASML
https://twitter.com/ogawa_tter/status/1298602041636319232
=>
" @Tachyum Prodigy Native AI Supports TensorFlow and PyTorch", Aug 26 2020 tachyum.com/pr-2020-08-26.…
Wholly functional FPGA prototype of the chip later this year
AI instruction set demo
10:53
ISC 2020, Jun 24, 2020
" @Tachyum Prodigy Native AI Supports TensorFlow and PyTorch", Aug 26 2020 tachyum.com/pr-2020-08-26.…
Wholly functional FPGA prototype of the chip later this year
AI instruction set demo
10:53
ISC 2020, Jun 24, 2020
https://twitter.com/ogawa_tter/status/1283090218971586560




=>
" @CerebrasSystems Expands Global Footprint with Toronto Office Opening", Aug 26, 2020 businesswire.com/news/home/2020…
15+ engineers currently employed, to plan to triple
[Webinar] Overview of the Cerebras CS-1, PSC, Aug 19
LLNL, Aug 19
" @CerebrasSystems Expands Global Footprint with Toronto Office Opening", Aug 26, 2020 businesswire.com/news/home/2020…
15+ engineers currently employed, to plan to triple
[Webinar] Overview of the Cerebras CS-1, PSC, Aug 19
https://twitter.com/ogawa_tter/status/1297104578941345792
LLNL, Aug 19
https://twitter.com/ogawa_tter/status/1296155173874614272
=>
"Deep Learning for Industrial AI:
Challenges, New Methods and Best Practices", Industrial AI Lab, Hitachi America, Tutorial, KDD 2020, Aug 23, 2020 sites.google.com/view/dl-for-in…
drive.google.com/file/d/1OXVDqt…
What is Industrial AI?
Why Industrial AI?
Future of Industrial AI
105 pp, 52 ref
"Deep Learning for Industrial AI:
Challenges, New Methods and Best Practices", Industrial AI Lab, Hitachi America, Tutorial, KDD 2020, Aug 23, 2020 sites.google.com/view/dl-for-in…
drive.google.com/file/d/1OXVDqt…
What is Industrial AI?
Why Industrial AI?
Future of Industrial AI
105 pp, 52 ref




=>
"ASTRA-SIM: Enabling SW/HW Co-Design Exploration for Distributed DL Training Platforms", ISPASS 2020
PDF cpb-us-w2.wpmucdn.com/sites.gatech.e…
23:09
Slides synergy.ece.gatech.edu/files/2020/08/…
Workload layer
System
Network
Switch-based
Torus-based
github.com/astra-sim/astr…
"ASTRA-SIM: Enabling SW/HW Co-Design Exploration for Distributed DL Training Platforms", ISPASS 2020
PDF cpb-us-w2.wpmucdn.com/sites.gatech.e…
23:09
Slides synergy.ece.gatech.edu/files/2020/08/…
Workload layer
System
Network
Switch-based
Torus-based
github.com/astra-sim/astr…




=>
Univ of Bristol tackle HPC Challenges in Particle Physics with @graphcoreai IPU, Aug 28, 2020 graphcore.ai/posts/universi…
IPUs for applications in Particle Physics, arXiv, Aug 20 2020 arxiv.org/abs/2008.09210
Univ of Bristol, Feb 2020
Univ of Bristol tackle HPC Challenges in Particle Physics with @graphcoreai IPU, Aug 28, 2020 graphcore.ai/posts/universi…
IPUs for applications in Particle Physics, arXiv, Aug 20 2020 arxiv.org/abs/2008.09210
Univ of Bristol, Feb 2020
https://twitter.com/ogawa_tter/status/1229500288286916608

=>
"Machine Learning for Weather and Climate Predictions", Peter Dueben, Summer School on Effective HPC for Climate and Weather, Aug 26, 2020
1:09:10
hps.vi4io.org/_media/events/…
ecmwf.int/en/about/who-w…
16-bit arithmetics, Jul 31, 2020 essoar.org/doi/abs/10.100…
"Machine Learning for Weather and Climate Predictions", Peter Dueben, Summer School on Effective HPC for Climate and Weather, Aug 26, 2020
1:09:10
hps.vi4io.org/_media/events/…
ecmwf.int/en/about/who-w…
16-bit arithmetics, Jul 31, 2020 essoar.org/doi/abs/10.100…




=>
"Deep learning for compilers", Chris Cummins, PhD Thesis, 2020 era.ed.ac.uk/handle/1842/36…
github.com/ChrisCummins/p…
chriscummins.cc
"Machine Learning in Compilers: Past, Present and Future", FDL 2020 PDF chriscummins.cc/pub/2020-fdl.p…
PACT 2017, Best Paper
"Deep learning for compilers", Chris Cummins, PhD Thesis, 2020 era.ed.ac.uk/handle/1842/36…
github.com/ChrisCummins/p…
chriscummins.cc
"Machine Learning in Compilers: Past, Present and Future", FDL 2020 PDF chriscummins.cc/pub/2020-fdl.p…
PACT 2017, Best Paper
https://twitter.com/ogawa_tter/status/912228655207669760




=>
"MLPerf-HPC: A Benchmark Suite for Large-scale ML on HPC Systems", S. Farrell, LBNL, Invited, WS on Benchmarking ML Workload, Aug 23, 2020 drive.google.com/file/d/1FaX-is…
MLPerf HPC v0.5
Oct 19: Deadline
CosmoFlow
DeepCAM
Rules github.com/mlperf/trainin…
@mlperf1 mlperf.org
"MLPerf-HPC: A Benchmark Suite for Large-scale ML on HPC Systems", S. Farrell, LBNL, Invited, WS on Benchmarking ML Workload, Aug 23, 2020 drive.google.com/file/d/1FaX-is…
MLPerf HPC v0.5
Oct 19: Deadline
CosmoFlow
DeepCAM
Rules github.com/mlperf/trainin…
@mlperf1 mlperf.org




=>
"Bosch Deep Learning Hardware Benchmark", Bosch, WS on Benchmarking ML Workloads, Aug 23, 2020
Slides drive.google.com/file/d/1X-tRhD…
arXiv, Aug 24, 2020 arxiv.org/abs/2008.10293
DL HW, specifically developed for inference on embedded HWAs and tasks required for autonomous driving.
"Bosch Deep Learning Hardware Benchmark", Bosch, WS on Benchmarking ML Workloads, Aug 23, 2020
Slides drive.google.com/file/d/1X-tRhD…
arXiv, Aug 24, 2020 arxiv.org/abs/2008.10293
DL HW, specifically developed for inference on embedded HWAs and tasks required for autonomous driving.




=>
Edge AI: Systems Design and ML for IoT Data Analytics, Tutorial, KDD 2020, Aug 23
1: Algorithms drive.google.com/file/d/11h5PGS…
2: Architectures drive.google.com/file/d/1_b0vnm…
3: Applications drive.google.com/file/d/1BcRkR5…
users.ece.utexas.edu/~radum/
users.ece.utexas.edu/~dianam/
elab.engineering.asu.edu
Edge AI: Systems Design and ML for IoT Data Analytics, Tutorial, KDD 2020, Aug 23
1: Algorithms drive.google.com/file/d/11h5PGS…
2: Architectures drive.google.com/file/d/1_b0vnm…
3: Applications drive.google.com/file/d/1BcRkR5…
users.ece.utexas.edu/~radum/
users.ece.utexas.edu/~dianam/
elab.engineering.asu.edu




=>
"Deploying Next Generation Compute for AI and More" @SambaNovaAI SMC 2020, Aug 28
24:02 dropbox.com/s/fu3dp5iwremd…
drive.google.com/file/d/1PRIFTr…
Enabling New Capabilities (0 => 1)
Excelling Beyond AI
Customer System Shipping!
Accelerating Software 2.0, Jul 2020
"Deploying Next Generation Compute for AI and More" @SambaNovaAI SMC 2020, Aug 28
24:02 dropbox.com/s/fu3dp5iwremd…
drive.google.com/file/d/1PRIFTr…
Enabling New Capabilities (0 => 1)
Excelling Beyond AI
Customer System Shipping!
Accelerating Software 2.0, Jul 2020
https://twitter.com/ogawa_tter/status/1289234707821916165




=>
"Exploring Agile Hardware/Software Co-Design Methodology", Heterogeneous Compiler Lab, Huawei Canada, SSHAW, Aug 17, 2020
22:17
Slides jnamaral.github.io/icpp20/slides/…
Challenges of ISA Design
Atlas 900
Ascend 910
"Exploring Agile Hardware/Software Co-Design Methodology", Heterogeneous Compiler Lab, Huawei Canada, SSHAW, Aug 17, 2020
22:17
Slides jnamaral.github.io/icpp20/slides/…
Challenges of ISA Design
Atlas 900
https://twitter.com/ogawa_tter/status/1208629077881413632
Ascend 910
https://twitter.com/ogawa_tter/status/1205326982361145345



=>
"Understanding and Mitigating Gradient Flow Pathologies in Physics-Informed Neural Networks (PINNs)", P. Perdikaris, UPenn, ICERM, Apr 21, 2020
49:42 icerm.brown.edu/video_archive/…
icerm.brown.edu/materials/Slid…
arXiv, Jan 2020 arxiv.org/abs/2001.04536
PINNs, NVIDIA
"Understanding and Mitigating Gradient Flow Pathologies in Physics-Informed Neural Networks (PINNs)", P. Perdikaris, UPenn, ICERM, Apr 21, 2020
49:42 icerm.brown.edu/video_archive/…
icerm.brown.edu/materials/Slid…
arXiv, Jan 2020 arxiv.org/abs/2001.04536
PINNs, NVIDIA
https://twitter.com/ogawa_tter/status/1258863988751732736


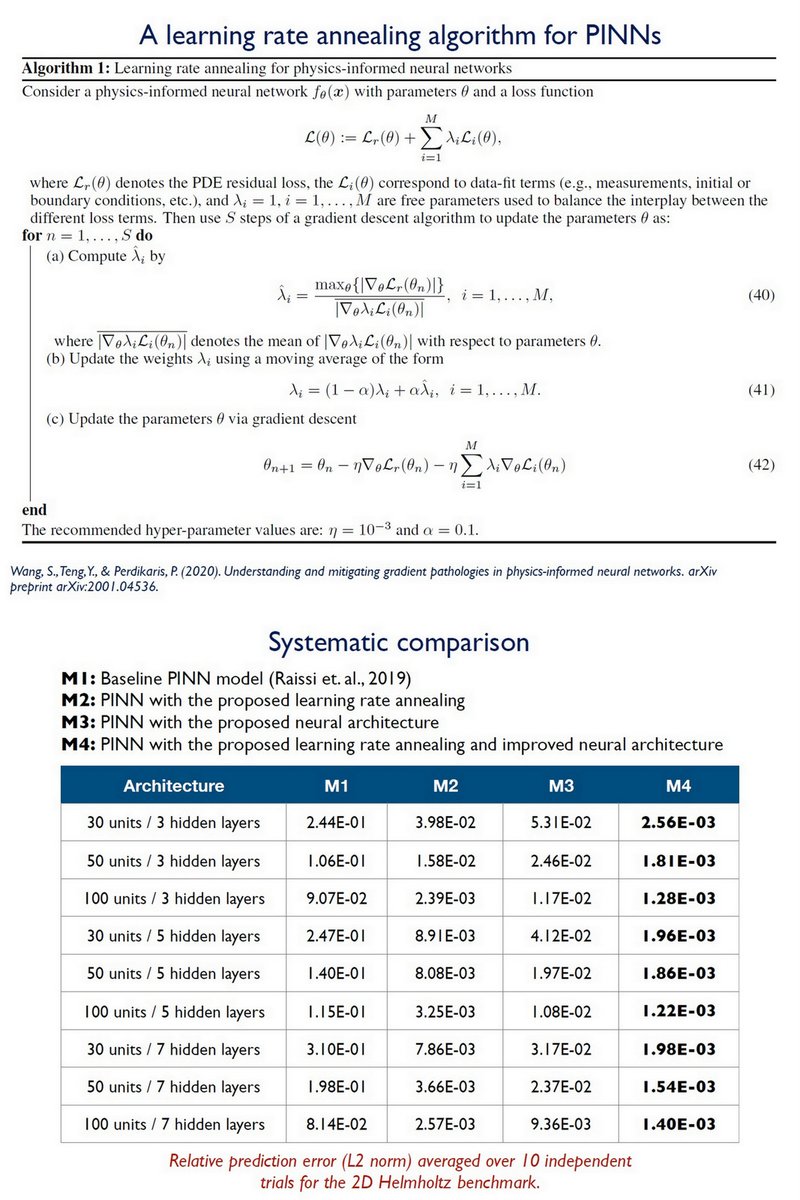
=>
PNNs, JCP, 2019 brown.edu/research/proje…
Science, Feb 2020 science.sciencemag.org/content/367/64…
UPenn, Apr, 2020
"When and why PINNs fail to train: A Neural Tangent Kernel perspective", arXiv, Jul 28 arxiv.org/abs/2007.14527
NVIDIA SimNet v0.2
PNNs, JCP, 2019 brown.edu/research/proje…
Science, Feb 2020 science.sciencemag.org/content/367/64…
UPenn, Apr, 2020
https://twitter.com/ogawa_tter/status/1302229117459333122
"When and why PINNs fail to train: A Neural Tangent Kernel perspective", arXiv, Jul 28 arxiv.org/abs/2007.14527
NVIDIA SimNet v0.2
https://twitter.com/ogawa_tter/status/1302222129161621504



=>
"Challenges and Opportunities in Machine Programming (MP)", J. Gottschlich, Intel, Keynote, PSW, Aug 4, 2020
47:16
Slides prog-synth-science.github.io/2020/pres/Gott…
"The Three Pillars of Machine Programming", arXiv, May 2018 arxiv.org/abs/1803.07244
sites.google.com/view/gottschli…
"Challenges and Opportunities in Machine Programming (MP)", J. Gottschlich, Intel, Keynote, PSW, Aug 4, 2020
47:16
Slides prog-synth-science.github.io/2020/pres/Gott…
"The Three Pillars of Machine Programming", arXiv, May 2018 arxiv.org/abs/1803.07244
sites.google.com/view/gottschli…



=>
GSK ai on London Tech Week, Kim Branson, SVP and Global Head of AI/ML, Sep 2, 2020 gsk.ai/blog/gsk-ai-on…
NVIDIA Comp pathology & Med images
@CerebrasSystems to deploy models of unprecedented complexity
£10 M AI hub, Sep 3 standard.co.uk/business/glaxo…
Sep 5 zdnet.com/article/glaxos…
GSK ai on London Tech Week, Kim Branson, SVP and Global Head of AI/ML, Sep 2, 2020 gsk.ai/blog/gsk-ai-on…
NVIDIA Comp pathology & Med images
@CerebrasSystems to deploy models of unprecedented complexity
£10 M AI hub, Sep 3 standard.co.uk/business/glaxo…
Sep 5 zdnet.com/article/glaxos…

=>
"Intel Nervana Neural Network Processor-T (NNP-T) Fused Floating Point Many-Term Dot Product", Short, ARITH 2020, PDF arith2020.arithsymposium.org/resources/pape…
32x32 BFloat16 matrix multiplication every 32 cycles
Flexpoint
NIPS 2017
ARITH 2018
"Intel Nervana Neural Network Processor-T (NNP-T) Fused Floating Point Many-Term Dot Product", Short, ARITH 2020, PDF arith2020.arithsymposium.org/resources/pape…
32x32 BFloat16 matrix multiplication every 32 cycles
Flexpoint
NIPS 2017
https://twitter.com/ogawa_tter/status/940187979795984384
ARITH 2018
https://twitter.com/ogawa_tter/status/1036940525180350466


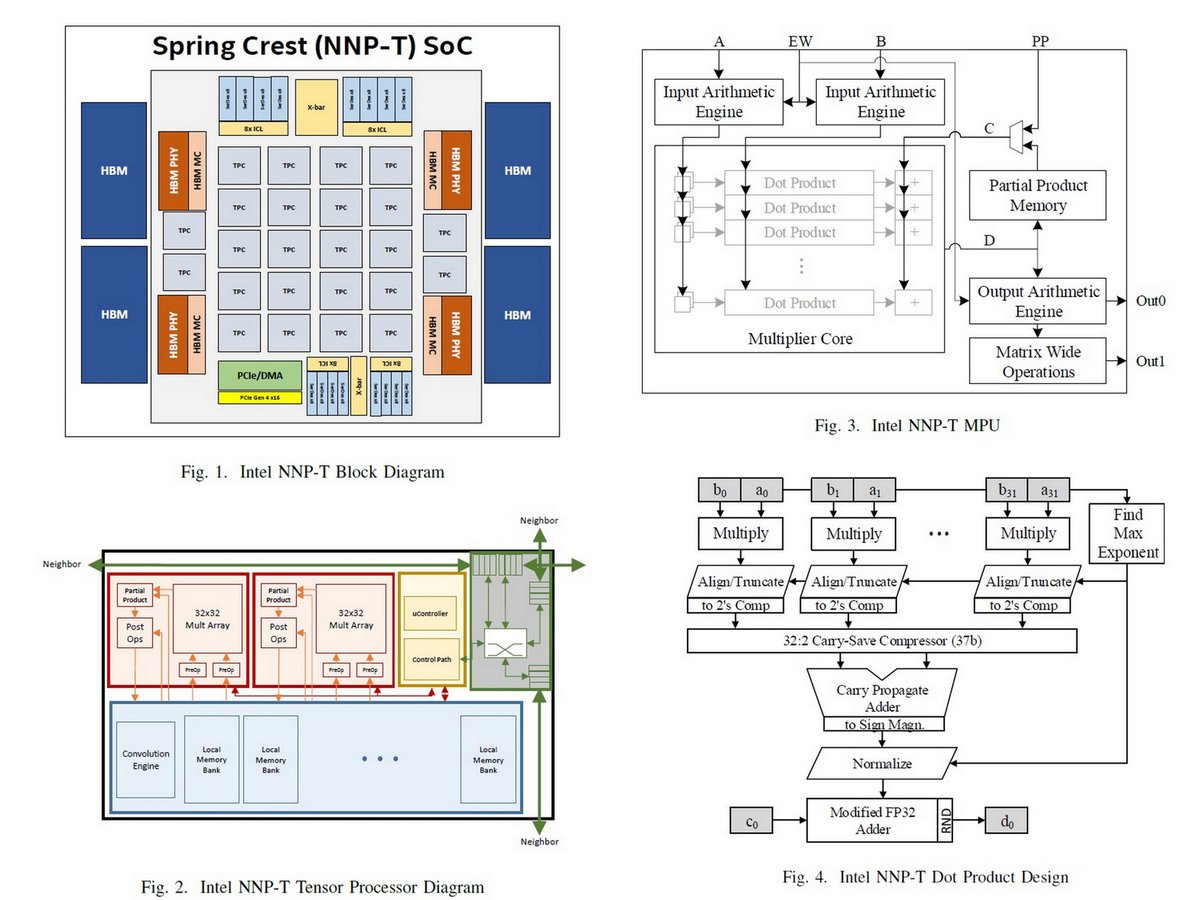

=>
"Fundamental limits of learning in deep neural networks", Helmut Bölcskei, ETH Zürich, One World MINDS Seminar, Aug 20, 2020
58:09
Helmut Bölcskei mins.ee.ethz.ch/people/show/bo…
scholar.google.com/citations?hl=j…
"Fundamental limits of learning in deep neural networks", Helmut Bölcskei, ETH Zürich, One World MINDS Seminar, Aug 20, 2020
58:09
Helmut Bölcskei mins.ee.ethz.ch/people/show/bo…
scholar.google.com/citations?hl=j…

=>
"Data Movement Is All You Need: A Case Study on Optimizing Transformers", .., T. Hoefler, arXiv, Jul 2, 2020 arxiv.org/abs/2007.00072
Training BERT
reduce data movement by up to 22.91%
=> overall achieve a 1.30x performance improvement
2x POWER9+ 4x V100
spcl.inf.ethz.ch
"Data Movement Is All You Need: A Case Study on Optimizing Transformers", .., T. Hoefler, arXiv, Jul 2, 2020 arxiv.org/abs/2007.00072
Training BERT
reduce data movement by up to 22.91%
=> overall achieve a 1.30x performance improvement
2x POWER9+ 4x V100
spcl.inf.ethz.ch




=>
"Blaize Ignites Edge-AI Performance", Microprocessor Report, Sep 9, 2020, PDF blaize.com/wp-content/upl…
El Cano Processor Runs Yolo v3 at 50 fps, Consumes Less Than 7W
Blaize Delivers Breakthrough for AI Edge Computing, Aug 13, 2020
"Blaize Ignites Edge-AI Performance", Microprocessor Report, Sep 9, 2020, PDF blaize.com/wp-content/upl…
El Cano Processor Runs Yolo v3 at 50 fps, Consumes Less Than 7W
Blaize Delivers Breakthrough for AI Edge Computing, Aug 13, 2020
https://twitter.com/ogawa_tter/status/1295560316445528066




=>
"Probabilistic Circuits: Representations, Inference, Learning and Applications", Tutorial, ECML-PKDD 2020, Sep 14, 2020 web.cs.ucla.edu/~guyvdb/talks/…
3:03:01
(11 MB/ 349 pp) web.cs.ucla.edu/~guyvdb/slides…
Lecture Notes starai.cs.ucla.edu/papers/LecNoAA…
starai.cs.ucla.edu
"Probabilistic Circuits: Representations, Inference, Learning and Applications", Tutorial, ECML-PKDD 2020, Sep 14, 2020 web.cs.ucla.edu/~guyvdb/talks/…
3:03:01
(11 MB/ 349 pp) web.cs.ucla.edu/~guyvdb/slides…
Lecture Notes starai.cs.ucla.edu/papers/LecNoAA…
starai.cs.ucla.edu




=>
Cornami Raises over $26 Million Series B Funding", Apr 10, 2020 cornami.com/2020/04/10/cor…
"Dr. Walden Rhines Joins Cornami as President and CEO", Jul 8 cornami.com/2020/07/08/dr-…
holds the position CEO Emeritus at Mentor
en.wikipedia.org/wiki/Wally_Rhi…
Oct/ Nov 2019
Cornami Raises over $26 Million Series B Funding", Apr 10, 2020 cornami.com/2020/04/10/cor…
"Dr. Walden Rhines Joins Cornami as President and CEO", Jul 8 cornami.com/2020/07/08/dr-…
holds the position CEO Emeritus at Mentor
en.wikipedia.org/wiki/Wally_Rhi…
Oct/ Nov 2019
https://twitter.com/ogawa_tter/status/1192135929705533440
=>
"Semiconductor device and data transferring method for semiconductor device", Preferred Networks Inc, Patent Application, Jun 11, 2020 patents.google.com/patent/US20200…
"MN-3が動き出します"、2020年6月1日
"Semiconductor device and data transferring method for semiconductor device", Preferred Networks Inc, Patent Application, Jun 11, 2020 patents.google.com/patent/US20200…
"MN-3が動き出します"、2020年6月1日
https://twitter.com/ogawa_tter/status/1267381488934252544


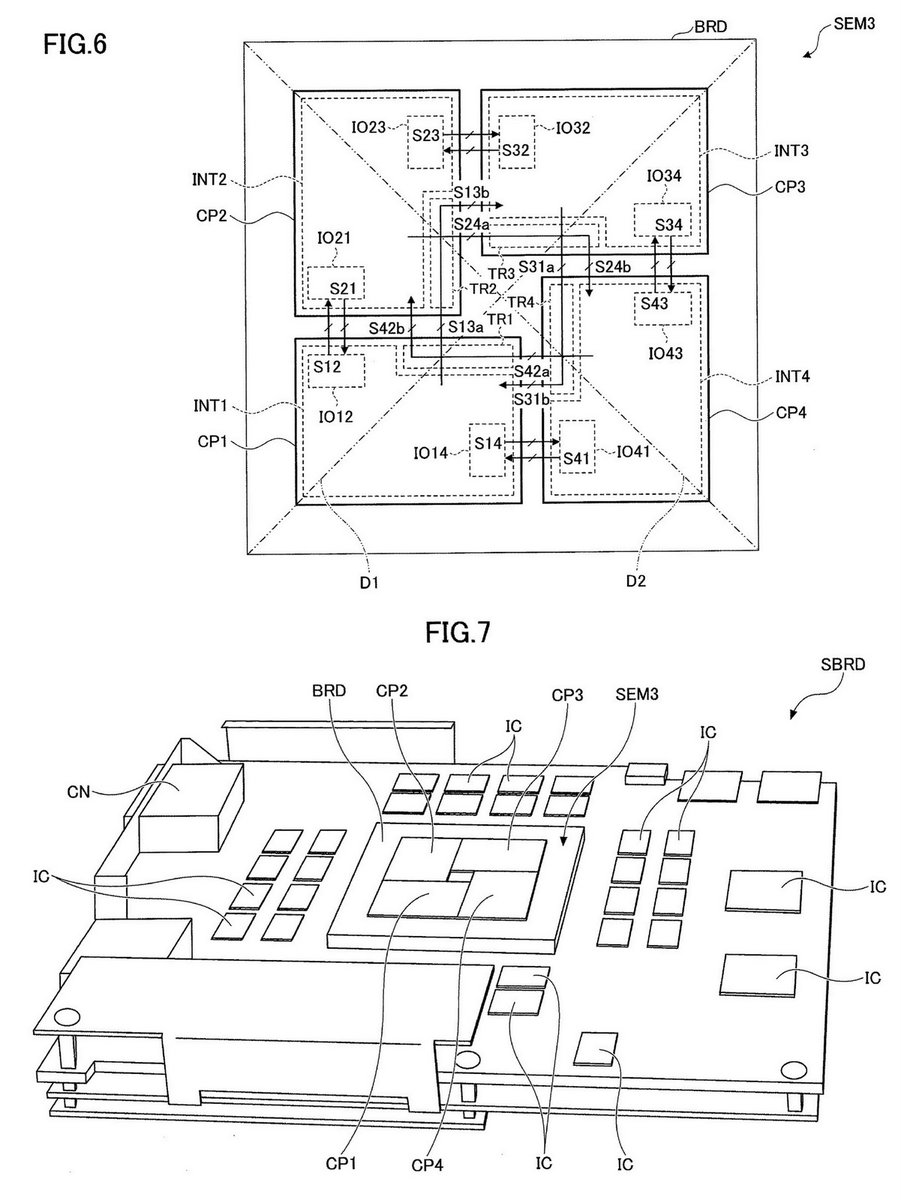
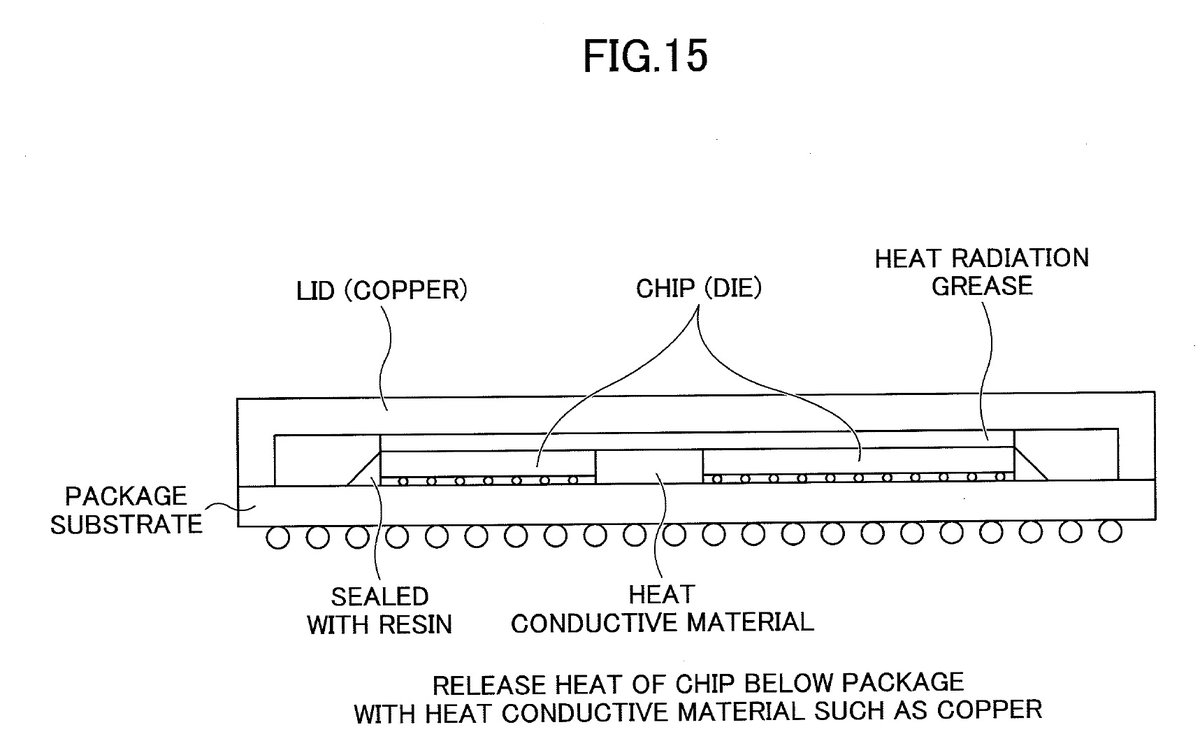
=>
"Rethinking BNN Inference and Training on Embedded FPGAs", Erwei Wang. , George A. Constantinides, Imperial, RCML 2020, Sep 4, 2020, PDF ece.ucy.ac.cy/labs/easoc/RCM…
LUTNet
FCCM 2019
TC, Early Access (Mar 2020) ieeexplore.ieee.org/document/90269…
spatialml.net
"Rethinking BNN Inference and Training on Embedded FPGAs", Erwei Wang. , George A. Constantinides, Imperial, RCML 2020, Sep 4, 2020, PDF ece.ucy.ac.cy/labs/easoc/RCM…
LUTNet
FCCM 2019
https://twitter.com/ogawa_tter/status/1128006758624948224
TC, Early Access (Mar 2020) ieeexplore.ieee.org/document/90269…
spatialml.net

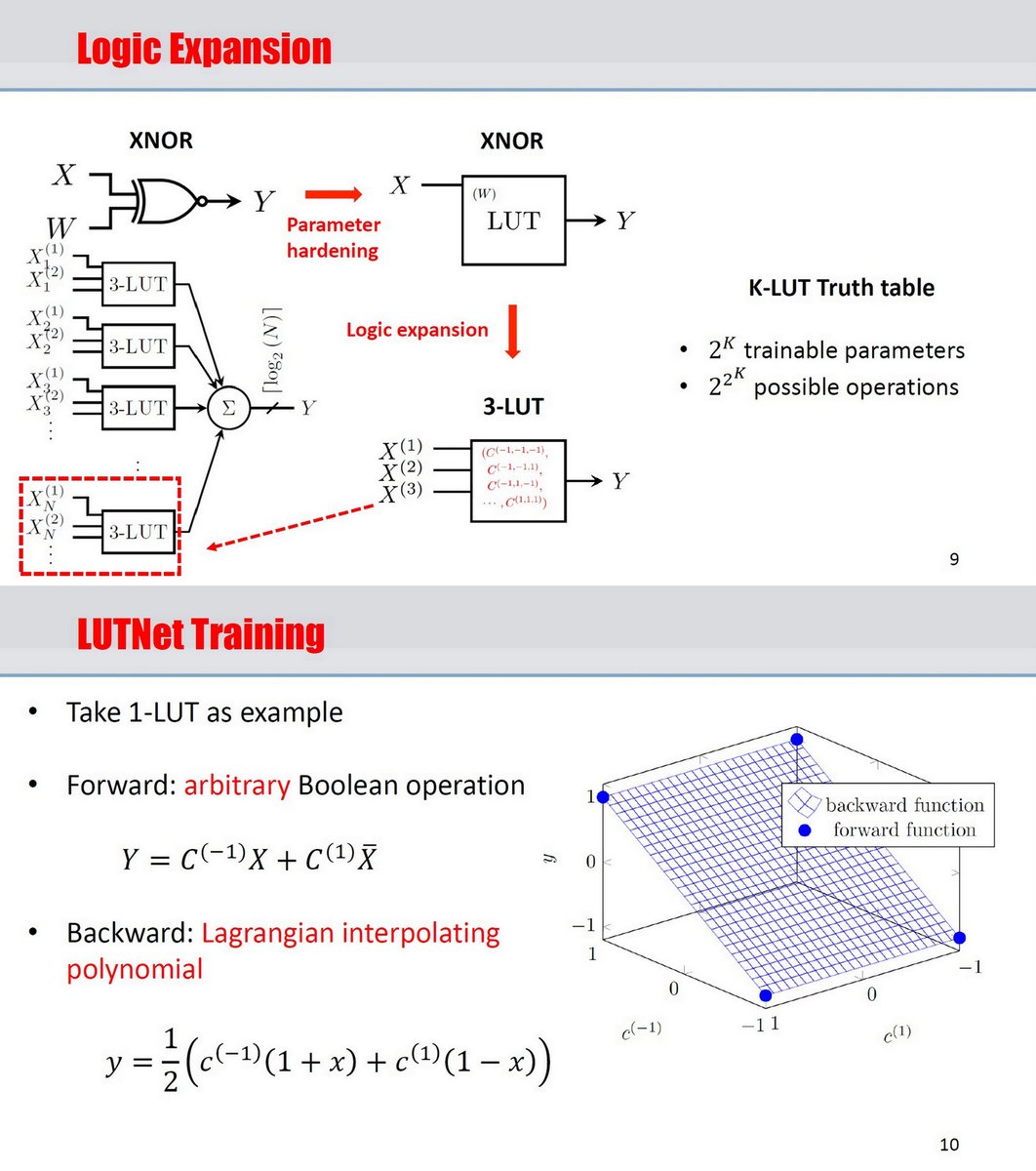


=>
Apple Patent
Scalable NN processing engine, Appl, Nov 11, 2019 patents.google.com/patent/US20190…
Matrix engine, Granted: Mar 17, 2020 patents.google.com/patent/US10592…
Computation engine w/ matrix and vector modes, Granted: Aug 25 patents.google.com/patent/US10754…
A14 Bionic, Sep 15
Apple Patent
Scalable NN processing engine, Appl, Nov 11, 2019 patents.google.com/patent/US20190…
Matrix engine, Granted: Mar 17, 2020 patents.google.com/patent/US10592…
Computation engine w/ matrix and vector modes, Granted: Aug 25 patents.google.com/patent/US10754…
A14 Bionic, Sep 15
https://twitter.com/ogawa_tter/status/1306025250845601793



=>
"Survey of Machine Learning Accelerators", MIT Lincoln Laboratory Supercomputing Center, arXiv, Sep 1, 2020 arxiv.org/abs/2009.00993
135 references
This paper updates the survey, Aug 2019
Image 4
Peak performace vs. power scatter plot
Aug 2019
Sep 2020
"Survey of Machine Learning Accelerators", MIT Lincoln Laboratory Supercomputing Center, arXiv, Sep 1, 2020 arxiv.org/abs/2009.00993
135 references
This paper updates the survey, Aug 2019
https://twitter.com/ogawa_tter/status/1169335826515316736
Image 4
Peak performace vs. power scatter plot
Aug 2019
Sep 2020




=>
"Microsoft teams up with OpenAI to exclusively license GPT-3 language model", Sep 22, 2020 blogs.microsoft.com/blog/2020/09/2…
"OpenAI Licenses GPT-3 Technology to Microsoft" openai.com/blog/openai-li…
"OpenAI has agreed to license GPT-3 to Microsoft for their own products and services."
"Microsoft teams up with OpenAI to exclusively license GPT-3 language model", Sep 22, 2020 blogs.microsoft.com/blog/2020/09/2…
"OpenAI Licenses GPT-3 Technology to Microsoft" openai.com/blog/openai-li…
"OpenAI has agreed to license GPT-3 to Microsoft for their own products and services."
=>
"Scaling Distributed Deep Learning Workloads beyond the Memory Capacity with KARMA", Mohamed Wahib, .., @ProfMatsuoka , SC20 arxiv.org/abs/2008.11421
Fugaku: The First 'Exascale' Supercomputer, Sep 15, 2020
KARMA: Outperforming SoTA NLP models on 2K GPUs
"Scaling Distributed Deep Learning Workloads beyond the Memory Capacity with KARMA", Mohamed Wahib, .., @ProfMatsuoka , SC20 arxiv.org/abs/2008.11421
Fugaku: The First 'Exascale' Supercomputer, Sep 15, 2020
https://twitter.com/ogawa_tter/status/1308974906802085889
KARMA: Outperforming SoTA NLP models on 2K GPUs



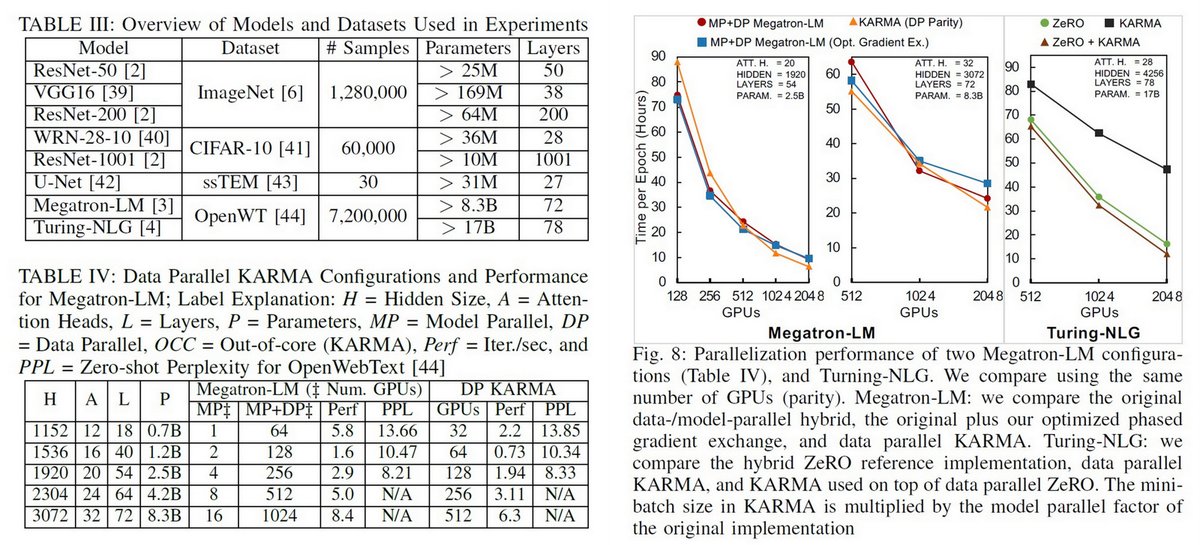
=>
"Estimation of energy consumption in machine learning", J. of Parallel and Distributed Computing, Dec 2019 (Aug 21, 2019) sciencedirect.com/science/articl…
Review, 81 references
Eva García-Martín egarciamartin.github.io
Energy Efficiency in ML, PhD Thesis, 2020 bth.diva-portal.org/smash/record.j…
"Estimation of energy consumption in machine learning", J. of Parallel and Distributed Computing, Dec 2019 (Aug 21, 2019) sciencedirect.com/science/articl…
Review, 81 references
Eva García-Martín egarciamartin.github.io
Energy Efficiency in ML, PhD Thesis, 2020 bth.diva-portal.org/smash/record.j…




=>
"Beyond Floating-Point Ops: CNN Performance Prediction with Critical Datapath Length", University of Pittsburgh, NSF SHREC, IEEE HPEC 2020, Sep 24, 2020
Critical Datapath Length:
Interpretable metric of NN (highly parallel nature) models
vs Total FLOPs
nsf-shrec.org
"Beyond Floating-Point Ops: CNN Performance Prediction with Critical Datapath Length", University of Pittsburgh, NSF SHREC, IEEE HPEC 2020, Sep 24, 2020
Critical Datapath Length:
Interpretable metric of NN (highly parallel nature) models
vs Total FLOPs
nsf-shrec.org


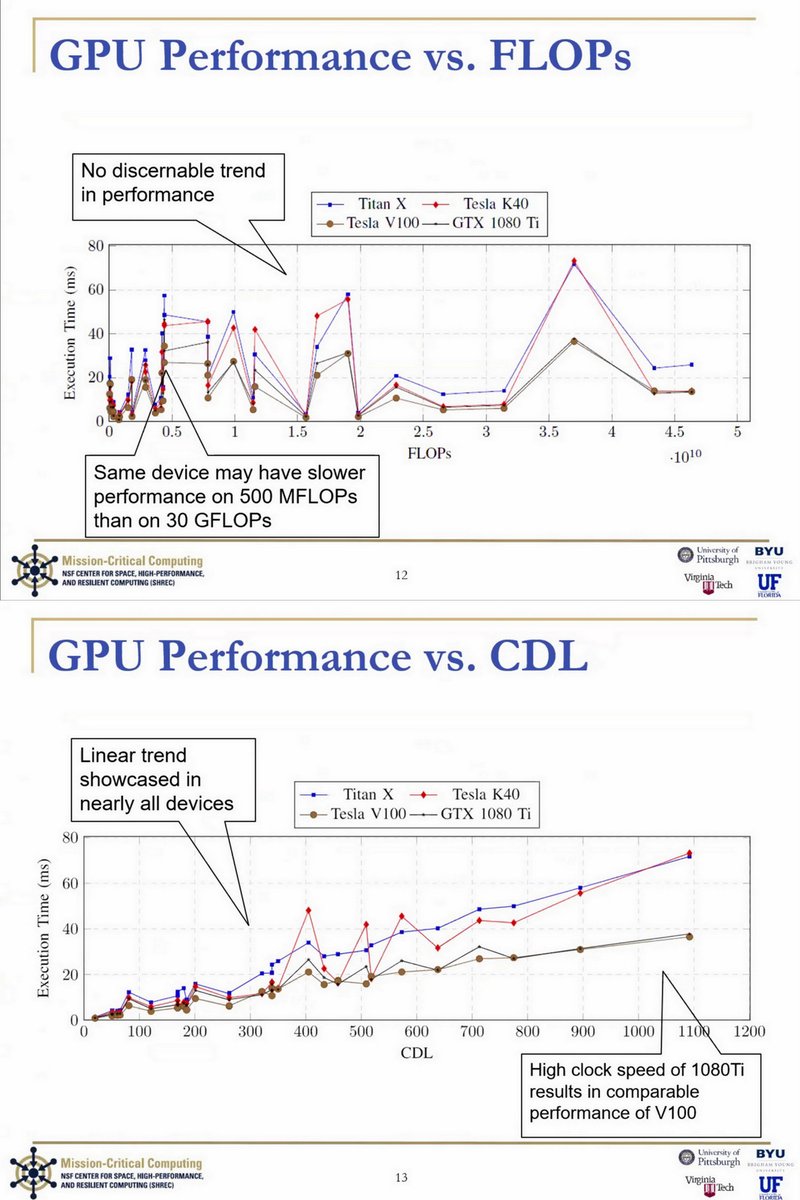
=>
"Domain-Specific Networks for Machine Learning", Dennis Abts, @GroqInc , Keynote, NOCS 2020, Sep 25, 2020 nocs2020.engr.uky.edu/program#keynot…
"ALU is relatively inexpensive - feeding then (wires) at full bandwidth is very expensive."
From Chip to Sysmtes, Jun 2020
"Domain-Specific Networks for Machine Learning", Dennis Abts, @GroqInc , Keynote, NOCS 2020, Sep 25, 2020 nocs2020.engr.uky.edu/program#keynot…
"ALU is relatively inexpensive - feeding then (wires) at full bandwidth is very expensive."
From Chip to Sysmtes, Jun 2020
https://twitter.com/ogawa_tter/status/1275577199014240256




=>
"The Wafer Scale Interconnect in the Wafer Scale Engine", Robert Hesse @CerebrasSystems , Special Session B - Scalable Platforms for Machine Learning: An Industry Perspective, NOCS, Sep 25, 2020
Purpose-built NOC for DL at Wafer Scale
Overview, Aug 2020
"The Wafer Scale Interconnect in the Wafer Scale Engine", Robert Hesse @CerebrasSystems , Special Session B - Scalable Platforms for Machine Learning: An Industry Perspective, NOCS, Sep 25, 2020
Purpose-built NOC for DL at Wafer Scale
Overview, Aug 2020
https://twitter.com/ogawa_tter/status/1297104578941345792




=>
"Vyasa: A High-Performance Vectorizing Compiler for Tensor Convolutions on the Xilinx AI Engine", IEEE HPEC 2020, Sep 24, 2020
10;26
PDF pchath.github.io/gatech-webpage…
Slides pchath.github.io/gatech-webpage…
Versal AI Core xilinx.com/products/silic…
integrated AI engines
"Vyasa: A High-Performance Vectorizing Compiler for Tensor Convolutions on the Xilinx AI Engine", IEEE HPEC 2020, Sep 24, 2020
10;26
PDF pchath.github.io/gatech-webpage…
Slides pchath.github.io/gatech-webpage…
Versal AI Core xilinx.com/products/silic…
integrated AI engines




=>
Explainable AI for Deep Networks: Basics & Extensions, Tutorial, ECML-PKDD 2020, Sep 18 interpretable-ml.org/ecml2020tutori…
Part1 (14M/ 58 pp) interpretable-ml.org/ecml2020tutori…
Part2 (41 pp) interpretable-ml.org/ecml2020tutori…
Part3 (39 pp) interpretable-ml.org/ecml2020tutori…
Part4 (20M/ 65 pp) interpretable-ml.org/ecml2020tutori…
Explainable AI for Deep Networks: Basics & Extensions, Tutorial, ECML-PKDD 2020, Sep 18 interpretable-ml.org/ecml2020tutori…
Part1 (14M/ 58 pp) interpretable-ml.org/ecml2020tutori…
Part2 (41 pp) interpretable-ml.org/ecml2020tutori…
Part3 (39 pp) interpretable-ml.org/ecml2020tutori…
Part4 (20M/ 65 pp) interpretable-ml.org/ecml2020tutori…




=>
Declaration of the US and UK on Cooperation in Artificial Intelligence Research and Development: A Shared Vision for Driving Technological Breakthroughs in Artificial Intelligence, Media Note, Department of State, Sep 25, 2020 state.gov/declaration-of…
whitehouse.gov/briefings-stat…
Declaration of the US and UK on Cooperation in Artificial Intelligence Research and Development: A Shared Vision for Driving Technological Breakthroughs in Artificial Intelligence, Media Note, Department of State, Sep 25, 2020 state.gov/declaration-of…
whitehouse.gov/briefings-stat…
=>
"Graphcore announces support for ODLA", Sep 29, 2020 graphcore.ai/posts/graphcor…
Alibaba Cloud's Open Deep Learning API, a unified heterogeneous hardware programming interface for accelerating deep learning.
2020云栖大会、2020年9月18日
Qualcomm Cloud AI 100
"Graphcore announces support for ODLA", Sep 29, 2020 graphcore.ai/posts/graphcor…
Alibaba Cloud's Open Deep Learning API, a unified heterogeneous hardware programming interface for accelerating deep learning.
2020云栖大会、2020年9月18日
Qualcomm Cloud AI 100
https://twitter.com/ogawa_tter/status/1115870979241185281


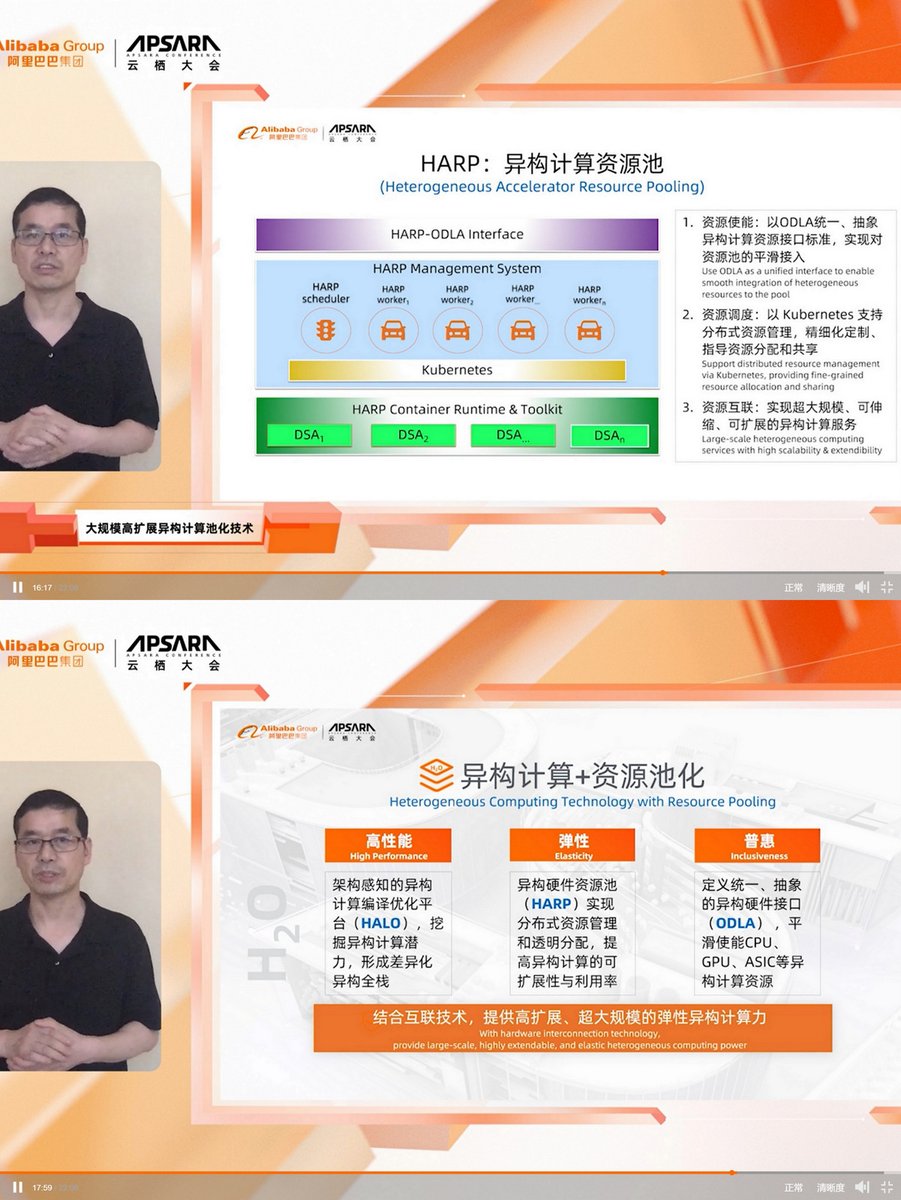

=>
"The Fastest Path to Performance", Jonathan Ross, Co-Founder and CEO, @GroqInc , AI Hardware Summit 2020, Sep 29, 2020
15;44
Groq announces product shipments to customers, Sep 29 prnewswire.com/news-releases/…
Keynote, NOCS 2020, Sep 25
"The Fastest Path to Performance", Jonathan Ross, Co-Founder and CEO, @GroqInc , AI Hardware Summit 2020, Sep 29, 2020
15;44
Groq announces product shipments to customers, Sep 29 prnewswire.com/news-releases/…
Keynote, NOCS 2020, Sep 25
https://twitter.com/ogawa_tter/status/1309553118271516672




=>
State of AI Report 2020, Oct 1, 2020 stateof.ai
177 pages
Research
Talent
Industry
Politics
Facial recognition
AI Nationalism
Predictions
AI Talent, Jun 2020
CHIPS Act
ITIF (SIA), Sep 2020
State of AI Report 2020, Oct 1, 2020 stateof.ai
177 pages
Research
Talent
Industry
Politics
Facial recognition
AI Nationalism
Predictions
AI Talent, Jun 2020
https://twitter.com/ogawa_tter/status/1270444794246909953
CHIPS Act
https://twitter.com/ogawa_tter/status/1297806664804884480
ITIF (SIA), Sep 2020
https://twitter.com/ogawa_tter/status/1310010022017916929



=>
"Hailo challenges Intel and Google with its new AI modules for edge devices", Sep 30, 2020 techcrunch.com/2020/09/30/hai…
Hailo-8 M.2 AI Acceleration Module hailo.ai/product-hailo/…
26 TOPS Hailo-8
3 TOPS/W
Dataflow Compiler hailo.ai/product-hailo/…
Mar 2020
"Hailo challenges Intel and Google with its new AI modules for edge devices", Sep 30, 2020 techcrunch.com/2020/09/30/hai…
Hailo-8 M.2 AI Acceleration Module hailo.ai/product-hailo/…
26 TOPS Hailo-8
3 TOPS/W
Dataflow Compiler hailo.ai/product-hailo/…
Mar 2020
https://twitter.com/ogawa_tter/status/1235556537872994304

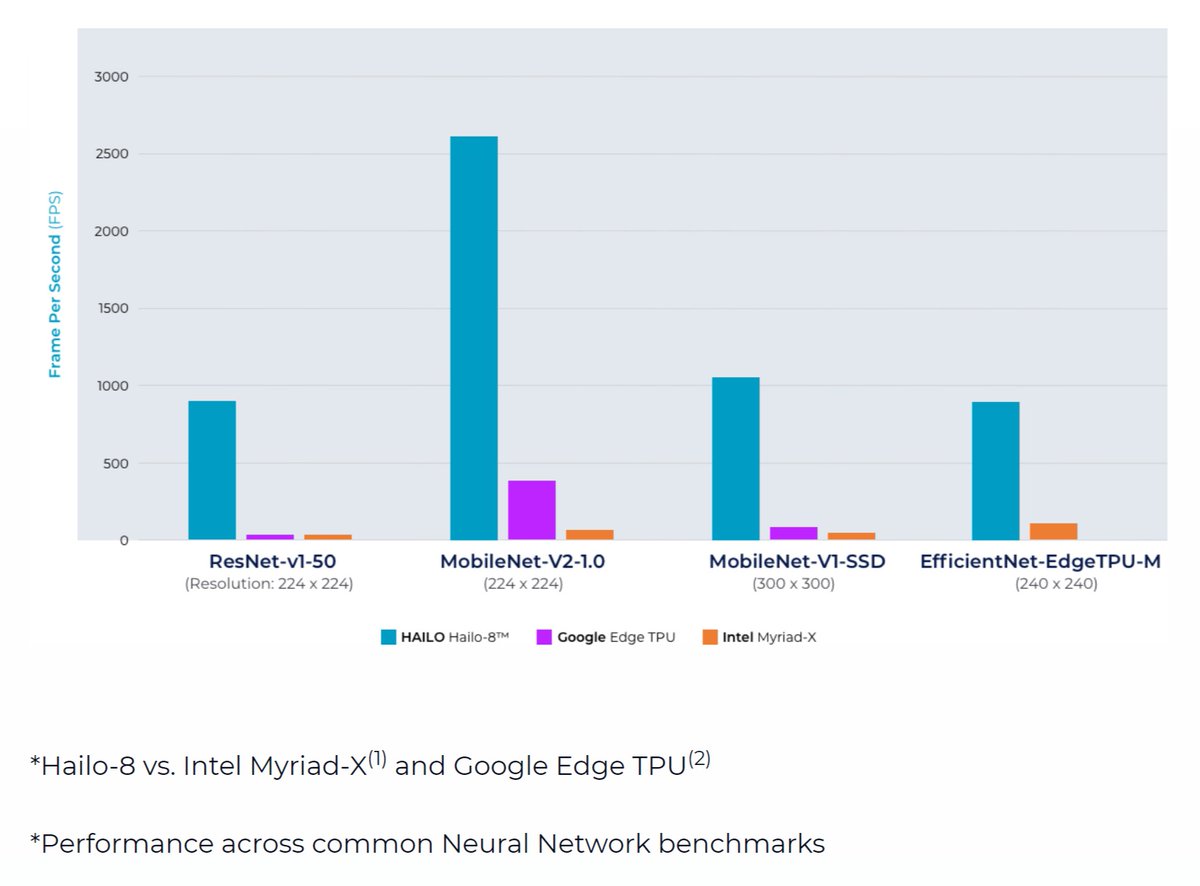
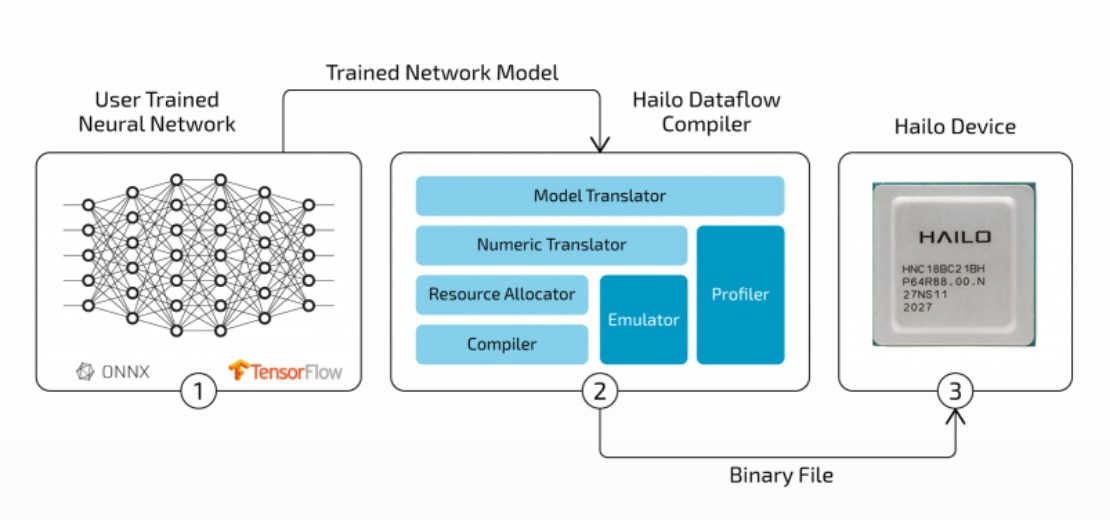
=>
"Marvell Enabling the Next Generation of Data Center and Automotive AI Accelerator ASICs", Sep 29 2020 marvell.com/company/newsro…
AI accelerator solutions for DC & Automotive
Industry’s first Peta Operations/second (POP/s) AI Accelerator-on-a-Chip
@GroqInc
"Marvell Enabling the Next Generation of Data Center and Automotive AI Accelerator ASICs", Sep 29 2020 marvell.com/company/newsro…
AI accelerator solutions for DC & Automotive
Industry’s first Peta Operations/second (POP/s) AI Accelerator-on-a-Chip
@GroqInc
https://twitter.com/ogawa_tter/status/1310981140686073856
=>
PCIe 64x MyriadX Board, ComBox Technology combox.io/projects/A-6/?…
8 blades (8 Myriad X MA2485)
PLX 12x PCIe lane SW
1 for eatch blade => 1 lane to 8x USB (Myriad X)
4 for PCIe bus
Not exceed 100W
Patent, Granted (?): Sep 21, 2020 fips.ru/registers-doc-…
PCIe 64x MyriadX Board, ComBox Technology combox.io/projects/A-6/?…
8 blades (8 Myriad X MA2485)
PLX 12x PCIe lane SW
1 for eatch blade => 1 lane to 8x USB (Myriad X)
4 for PCIe bus
Not exceed 100W
https://twitter.com/ComBoxTech/status/1312770751313981440
Patent, Granted (?): Sep 21, 2020 fips.ru/registers-doc-…
=>
"Security 101 for Artificial Intelligence SoCs", Synopsys, D&R IP SoC Day, Apr 8, 2020
17:30
design-reuse-embedded.com/servlet/public…
Rambus
Securing Architecture
Robust ML
"Security 101 for Artificial Intelligence SoCs", Synopsys, D&R IP SoC Day, Apr 8, 2020
17:30
design-reuse-embedded.com/servlet/public…
Rambus
https://twitter.com/ogawa_tter/status/1222419829996437504
Securing Architecture
https://twitter.com/ogawa_tter/status/1267813913581637638
Robust ML
https://twitter.com/ogawa_tter/status/1296752613937909760
https://twitter.com/ogawa_tter/status/1311600211685330944



=>
"AR/VR Silicon Research and Challenges", Edith Beigne, Silicon Research Manager @ Facebook, Keynote, VLSI-SoC, Oct 7, 2020 vlsisoc2020.eng.utah.edu/keynote-3-inte…
Smart AR Glasses
Security & Privacy
Challenges for AR Silicon
Embedded CV HW through the Eyes of AR/VR
"AR/VR Silicon Research and Challenges", Edith Beigne, Silicon Research Manager @ Facebook, Keynote, VLSI-SoC, Oct 7, 2020 vlsisoc2020.eng.utah.edu/keynote-3-inte…
Smart AR Glasses
Security & Privacy
Challenges for AR Silicon
Embedded CV HW through the Eyes of AR/VR
https://twitter.com/ogawa_tter/status/1265644915037372417




=>
"SafeTPU: A Verifiably Secure Hardware Accelerator for Deep Neural Networks", IEEE VLSI Test Symposium (VTS), Apr 2020 ieeexplore.ieee.org/document/91075…
Safe-TPU on an FPGA
Area overhead: 28%
3.15x faster than state-of-the-art
wp.nyu.edu/ensure_group/
Synopsys
"SafeTPU: A Verifiably Secure Hardware Accelerator for Deep Neural Networks", IEEE VLSI Test Symposium (VTS), Apr 2020 ieeexplore.ieee.org/document/91075…
Safe-TPU on an FPGA
Area overhead: 28%
3.15x faster than state-of-the-art
wp.nyu.edu/ensure_group/
Synopsys
https://twitter.com/ogawa_tter/status/1313445855014252545
=>
"A Survey on Bayesian Deep Learning", ACM Computing Surveys, Sep 2020 dl.acm.org/doi/10.1145/34…
37 pages, 136 references
Open Access
Hao Wang wanghao.in
Dit-Yan Yeung sites.google.com/view/dyyeung/h…
"A Survey on Bayesian Deep Learning", ACM Computing Surveys, Sep 2020 dl.acm.org/doi/10.1145/34…
37 pages, 136 references
Open Access
Hao Wang wanghao.in
Dit-Yan Yeung sites.google.com/view/dyyeung/h…


=>
Qualcomm: First Shipments of Qualcomm Cloud AI 100 Accelerator and Edge Development Kit, Sep 16, 2020 qualcomm.com/news/releases/…
Qualcomm Cloud AI 100 qualcomm.com/products/cloud…
2:06
Alibaba Cloud's ODLA,, Sep 18
Cloud AI 100, Apr 2019
Qualcomm: First Shipments of Qualcomm Cloud AI 100 Accelerator and Edge Development Kit, Sep 16, 2020 qualcomm.com/news/releases/…
Qualcomm Cloud AI 100 qualcomm.com/products/cloud…
2:06
Alibaba Cloud's ODLA,, Sep 18
https://twitter.com/ogawa_tter/status/1310974706778951680
Cloud AI 100, Apr 2019




=>
"Qualcomm Cloud AI 100 Announcement", Sep 16, 2020, PDF qualcomm.com/media/document…
7 nm
DM.2e: >50 TOPS, 15W
DM.2: 200 TOPS, 25W
PCIe (HHHL): 400 TOPS, 75W
Up to 16 cores (SRAM: 9 MB))
Up to 144 MB on die SRAM
Up to 32GB on card DRAM
Press, Sep 16, etc
"Qualcomm Cloud AI 100 Announcement", Sep 16, 2020, PDF qualcomm.com/media/document…
7 nm
DM.2e: >50 TOPS, 15W
DM.2: 200 TOPS, 25W
PCIe (HHHL): 400 TOPS, 75W
Up to 16 cores (SRAM: 9 MB))
Up to 144 MB on die SRAM
Up to 32GB on card DRAM
Press, Sep 16, etc
https://twitter.com/ogawa_tter/status/1314906748331814915




=>
"CFDNet: A deep learning-based accelerator for fluid simulations", ICS 2020
19:09
arxiv.org/abs/2005.04485
HPC Forge, UC Irvine hpcforge.eng.uci.edu/#home
AI and HPC: The Drivers of Tomorrow's Science, A. Chandramowlishwaran, Oct 1 sinews.siam.org/Details-Page/a…
"CFDNet: A deep learning-based accelerator for fluid simulations", ICS 2020
19:09
arxiv.org/abs/2005.04485
HPC Forge, UC Irvine hpcforge.eng.uci.edu/#home
AI and HPC: The Drivers of Tomorrow's Science, A. Chandramowlishwaran, Oct 1 sinews.siam.org/Details-Page/a…




=>
"Data Science Applications in Industry", BOSCH, Guest Talk, CERN School of Computing 2019, Sep 27, 2019 indico.cern.ch/event/769356/c…
Data science use cases from industry
Descriptive analytics
Diagnostic analytics
Predictive analytics
Prescriptive analytics
"Data Science Applications in Industry", BOSCH, Guest Talk, CERN School of Computing 2019, Sep 27, 2019 indico.cern.ch/event/769356/c…
Data science use cases from industry
Descriptive analytics
Diagnostic analytics
Predictive analytics
Prescriptive analytics
https://twitter.com/ogawa_tter/status/1300829399751602176

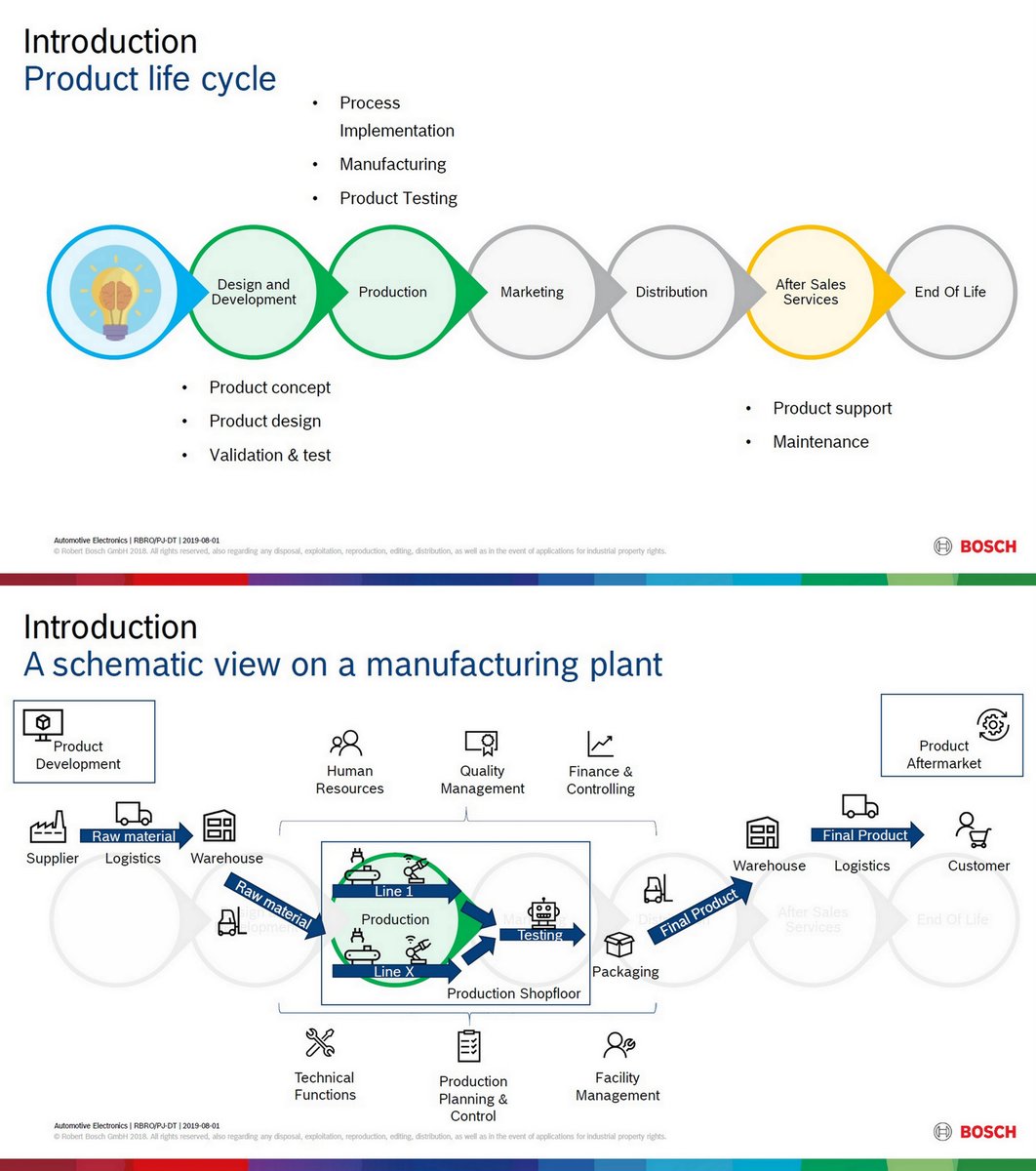
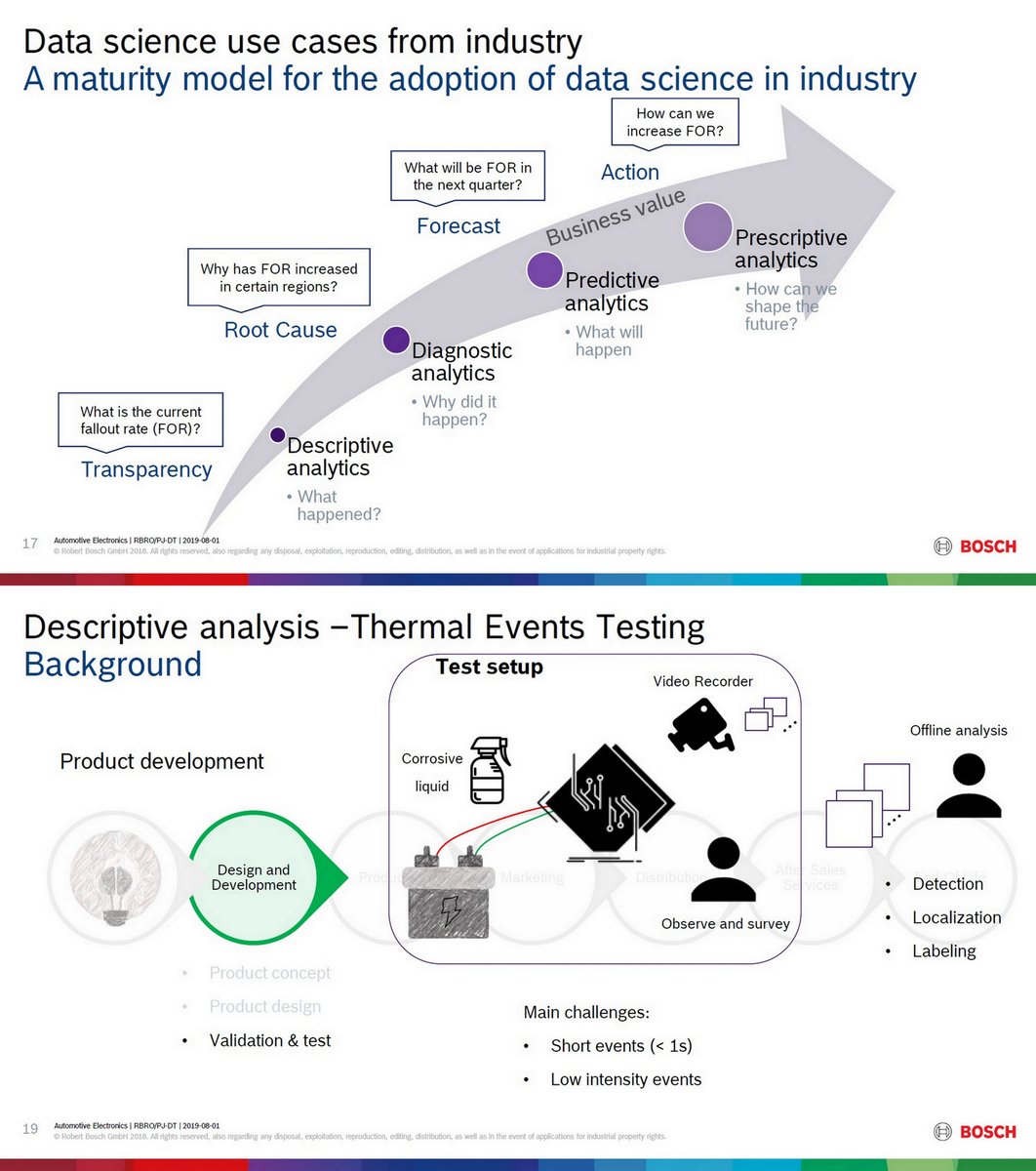
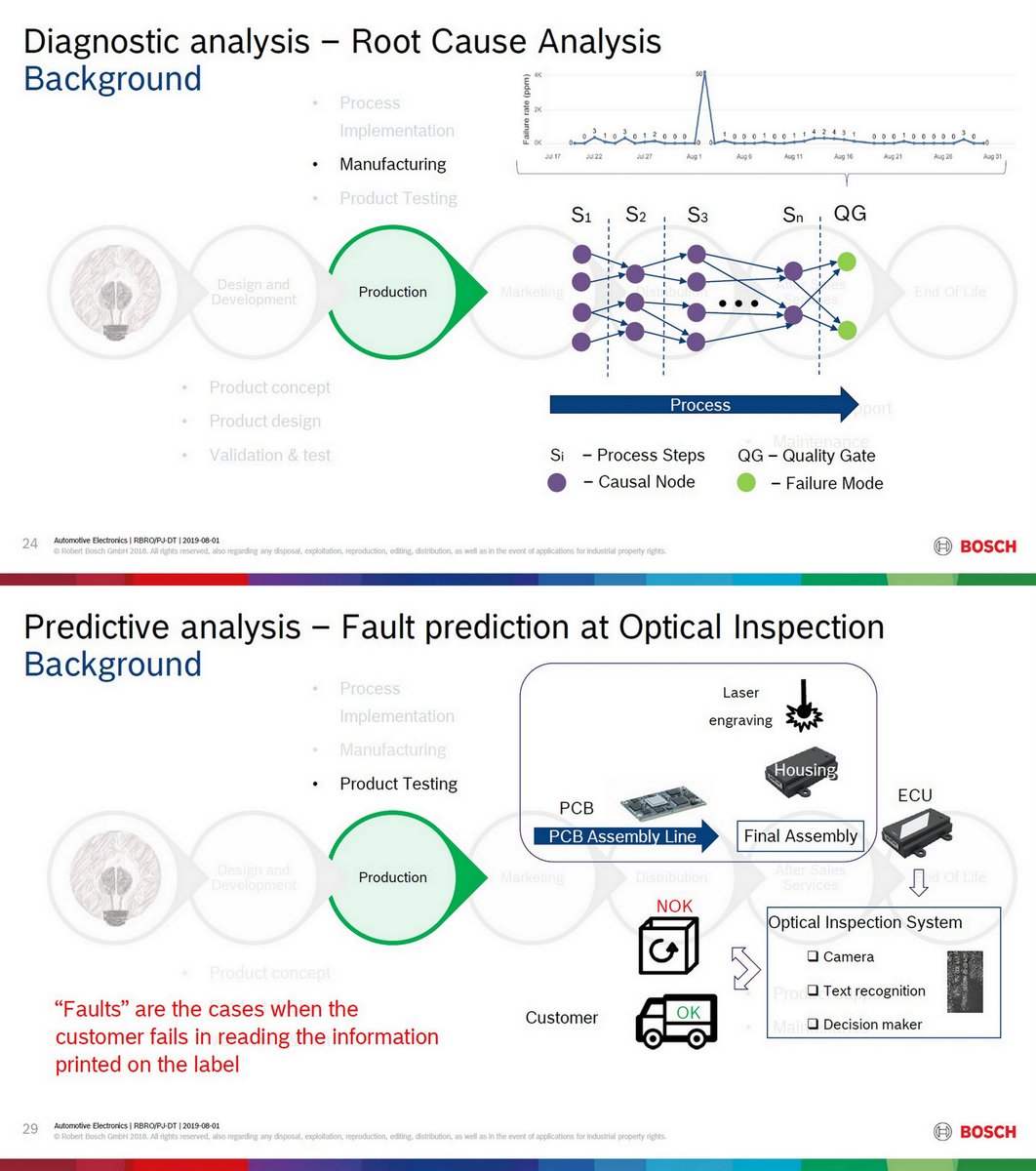
=>
"A Survey of Multilingual Neural Machine Translation", ACM Computing Surveys, Sep 2020 dl.acm.org/doi/10.1145/34…
38 pages, 170 references
Raj Dabre, NICT prajdabre.wixsite.com/prajdabre
scholar.google.com/citations?user…
PhD Thesis, 2018 repository.kulib.kyoto-u.ac.jp/dspace/handle/…
"A Survey of Multilingual Neural Machine Translation", ACM Computing Surveys, Sep 2020 dl.acm.org/doi/10.1145/34…
38 pages, 170 references
Raj Dabre, NICT prajdabre.wixsite.com/prajdabre
scholar.google.com/citations?user…
PhD Thesis, 2018 repository.kulib.kyoto-u.ac.jp/dspace/handle/…




=>
"Systems and methods for powering an integrated circuit having multiple interconnected die", @CerebrasSystems Patent Appl, Sep 10, 2020 patents.google.com/patent/US20200…
Vertical Power Delivery, Vicor
Cerebras 2019
"Systems and methods for powering an integrated circuit having multiple interconnected die", @CerebrasSystems Patent Appl, Sep 10, 2020 patents.google.com/patent/US20200…
Vertical Power Delivery, Vicor
https://twitter.com/ogawa_tter/status/1286916091017457665
https://twitter.com/ogawa_tter/status/1200694836384260096
Cerebras 2019




=>
Valavan Manohararajah, @CerebrasSystems Virtual Kanata 2020 FPGA Seminar, Oct 9, 2020
1:05/20
via @nachiketkapre
IMPACT 2020
ISPD 2020
ATPESC 2020
CFD @ SC20
Valavan Manohararajah, @CerebrasSystems Virtual Kanata 2020 FPGA Seminar, Oct 9, 2020
1:05/20
via @nachiketkapre
IMPACT 2020
https://twitter.com/ogawa_tter/status/1220152691210346496
ISPD 2020
https://twitter.com/ogawa_tter/status/1277701520167862272
ATPESC 2020
https://twitter.com/ogawa_tter/status/1289232122922729479
CFD @ SC20
https://twitter.com/ogawa_tter/status/1314492318129348608




=>
"Intel India, Government, Academics Launch AI Research Center", Oct 12, 2020 newsroom.intel.com/news/intel-ind…
INAI, the Applied AI Research Center in Hyderabad
IIIT Hyderabad iiit.ac.in
all ai 2020 Virtual Summit, Oct 12-16, 2020 all-ai.in
Free event
"Intel India, Government, Academics Launch AI Research Center", Oct 12, 2020 newsroom.intel.com/news/intel-ind…
INAI, the Applied AI Research Center in Hyderabad
IIIT Hyderabad iiit.ac.in
all ai 2020 Virtual Summit, Oct 12-16, 2020 all-ai.in
Free event
=>
"Apple on designing the A14 Bionic for the iPad Air and beyond", Oct 12, 2020 engadget.com/apple-a14-bion…
Tim Millet, VP of Platform Architecture
Tom Boger, Sr Director of Mac and iPad Product Marketing
Neural Engine
Apple Patents
A14 Bionic, Sep 15
"Apple on designing the A14 Bionic for the iPad Air and beyond", Oct 12, 2020 engadget.com/apple-a14-bion…
Tim Millet, VP of Platform Architecture
Tom Boger, Sr Director of Mac and iPad Product Marketing
Neural Engine
Apple Patents
https://twitter.com/ogawa_tter/status/1307936299953696769
A14 Bionic, Sep 15
=>
"Look-Up Table based Energy Efficient Processing in Cache Support for Neural Network Acceleration", PSU and Intel, MICRO 2020 microarch.org/micro53/papers…
Look-Up Table based Processing-In-Memory
Re-configurable, supporting RNNs and transformer models
LUTNet
"Look-Up Table based Energy Efficient Processing in Cache Support for Neural Network Acceleration", PSU and Intel, MICRO 2020 microarch.org/micro53/papers…
Look-Up Table based Processing-In-Memory
Re-configurable, supporting RNNs and transformer models
LUTNet
https://twitter.com/ogawa_tter/status/1306493814106775552



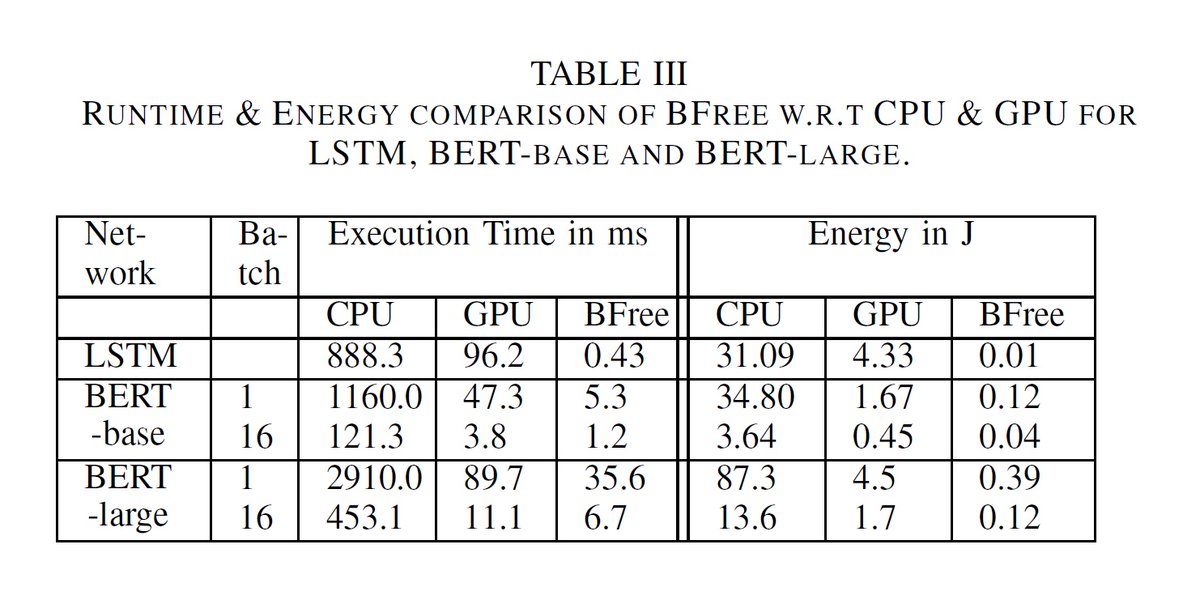
=>
"新iPad Airの心臓部「A14」から見える「次期iPhone」「次期Mac」の姿"、2020年9月23日 businessinsider.jp/post-220618
10年間「半導体の自社設計」
多数の製品に使う
高速化と低消費電力
後藤さん、9月30日
Tim Millet & Tom Boger, Oct 12
Patents
"新iPad Airの心臓部「A14」から見える「次期iPhone」「次期Mac」の姿"、2020年9月23日 businessinsider.jp/post-220618
10年間「半導体の自社設計」
多数の製品に使う
高速化と低消費電力
後藤さん、9月30日
https://twitter.com/ogawa_tter/status/1311568789855596544
Tim Millet & Tom Boger, Oct 12
https://twitter.com/ogawa_tter/status/1316149468207616000
Patents
=>
"GREENWAVES TECHNOLOGIES Announces Next Generation GAP9 Hearables Platform Using @GLOBALFOUNDRIES 22FDX Solution", Oct 15, 2020 globalfoundries.com/news-events/pr…
GAP9: 0.33 mW/GOP
greenwaves-technologies.com/gap8_gap9/
Adaptive body bias (ABB)
2MB eMRAM
eMRAM on 22FDX, Feb 2020
"GREENWAVES TECHNOLOGIES Announces Next Generation GAP9 Hearables Platform Using @GLOBALFOUNDRIES 22FDX Solution", Oct 15, 2020 globalfoundries.com/news-events/pr…
GAP9: 0.33 mW/GOP
greenwaves-technologies.com/gap8_gap9/
Adaptive body bias (ABB)
2MB eMRAM
eMRAM on 22FDX, Feb 2020
https://twitter.com/ogawa_tter/status/1234432238948737024


"Super-resolution scanning display for near-eye displays", Facebook, Patent Granted: Jun 23, 2020 patents.google.com/patent/US10690…
LNS, ARITH 2020
Novel alternative for low power, high precision hardened LA in CV & ML
Smart AR Glasses, FB
LNS, ARITH 2020
https://twitter.com/ogawa_tter/status/1316961397079760896
Novel alternative for low power, high precision hardened LA in CV & ML
Smart AR Glasses, FB
https://twitter.com/ogawa_tter/status/1313876924117118976



=>
hls4ml hands-on tutorial (3 hours), IEEE Real Time Conference, Oct 15, 2020
Slides (34 pages) indico.cern.ch/event/737461/c…
Tutorial notebooks for hls4ml github.com/hls-fpga-machi…
Part 1: Model Conversion
Part 2: Advanced Configuration
Part 3: Compression
Part 4: Quantization
hls4ml hands-on tutorial (3 hours), IEEE Real Time Conference, Oct 15, 2020
Slides (34 pages) indico.cern.ch/event/737461/c…
Tutorial notebooks for hls4ml github.com/hls-fpga-machi…
Part 1: Model Conversion
Part 2: Advanced Configuration
Part 3: Compression
Part 4: Quantization

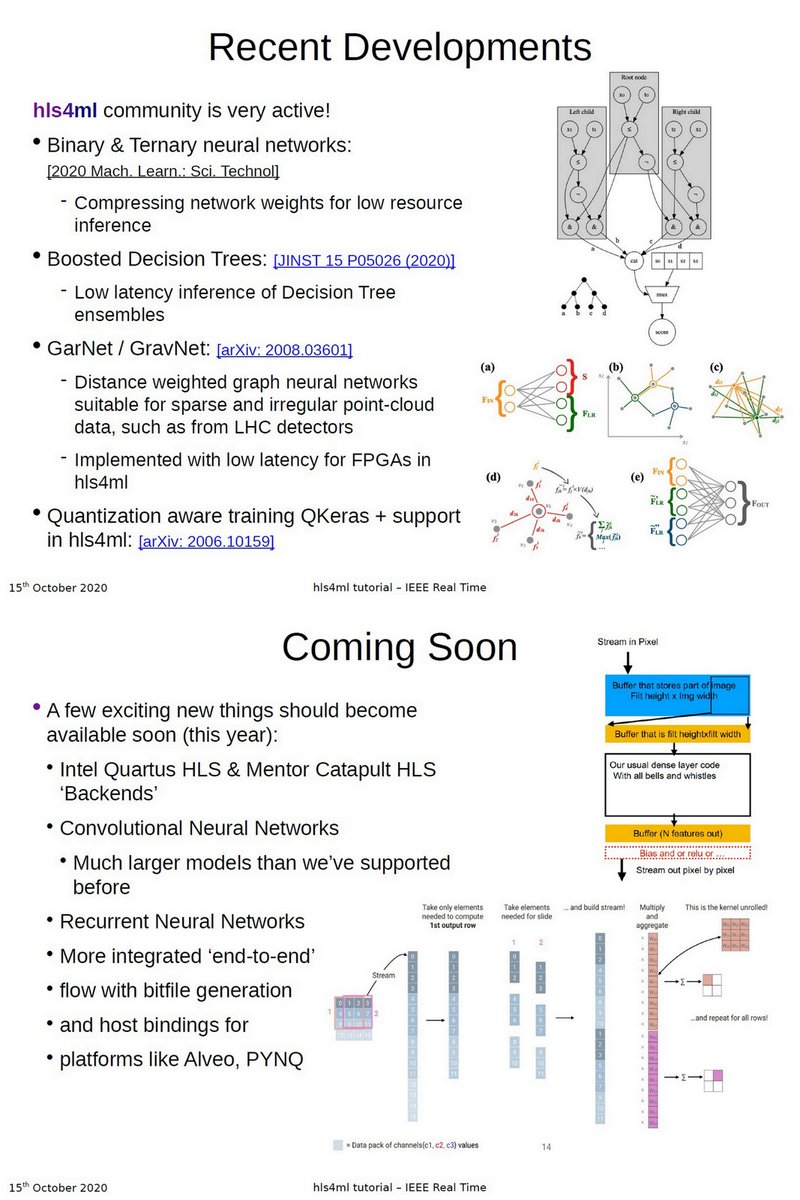
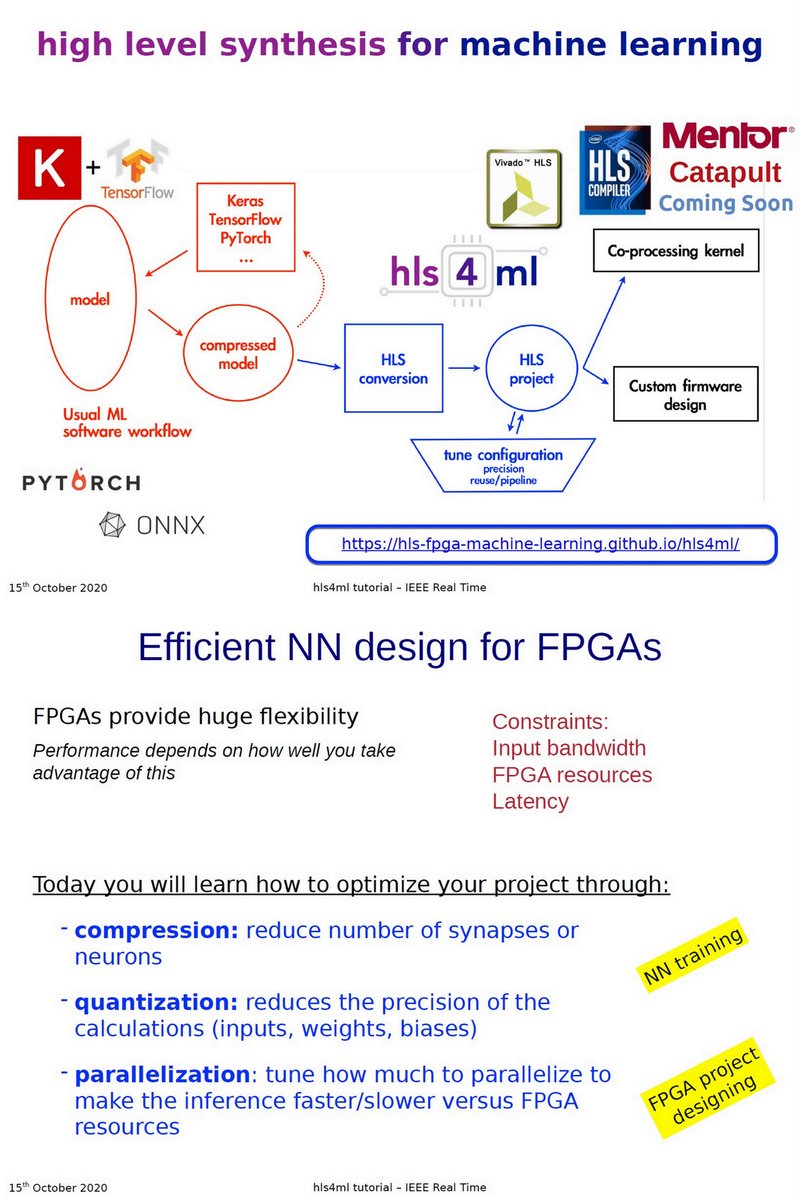

=>
"Implementing Machine Learning on Massively Parallel Hardware", Patrick Groeneveld, @CerebrasSystems , EDPS, Oct 1, 2020
24:35 ieee-edps.com/archives/2020/…
PDF ieee-edps.com/archives/2020/…
CS-1
Seminar, Oct 9
Placement Contest, ISPD 2020
"Implementing Machine Learning on Massively Parallel Hardware", Patrick Groeneveld, @CerebrasSystems , EDPS, Oct 1, 2020
24:35 ieee-edps.com/archives/2020/…
PDF ieee-edps.com/archives/2020/…
CS-1
https://twitter.com/ogawa_tter/status/1200694836384260096
Seminar, Oct 9
https://twitter.com/ogawa_tter/status/1315732265347936257
Placement Contest, ISPD 2020


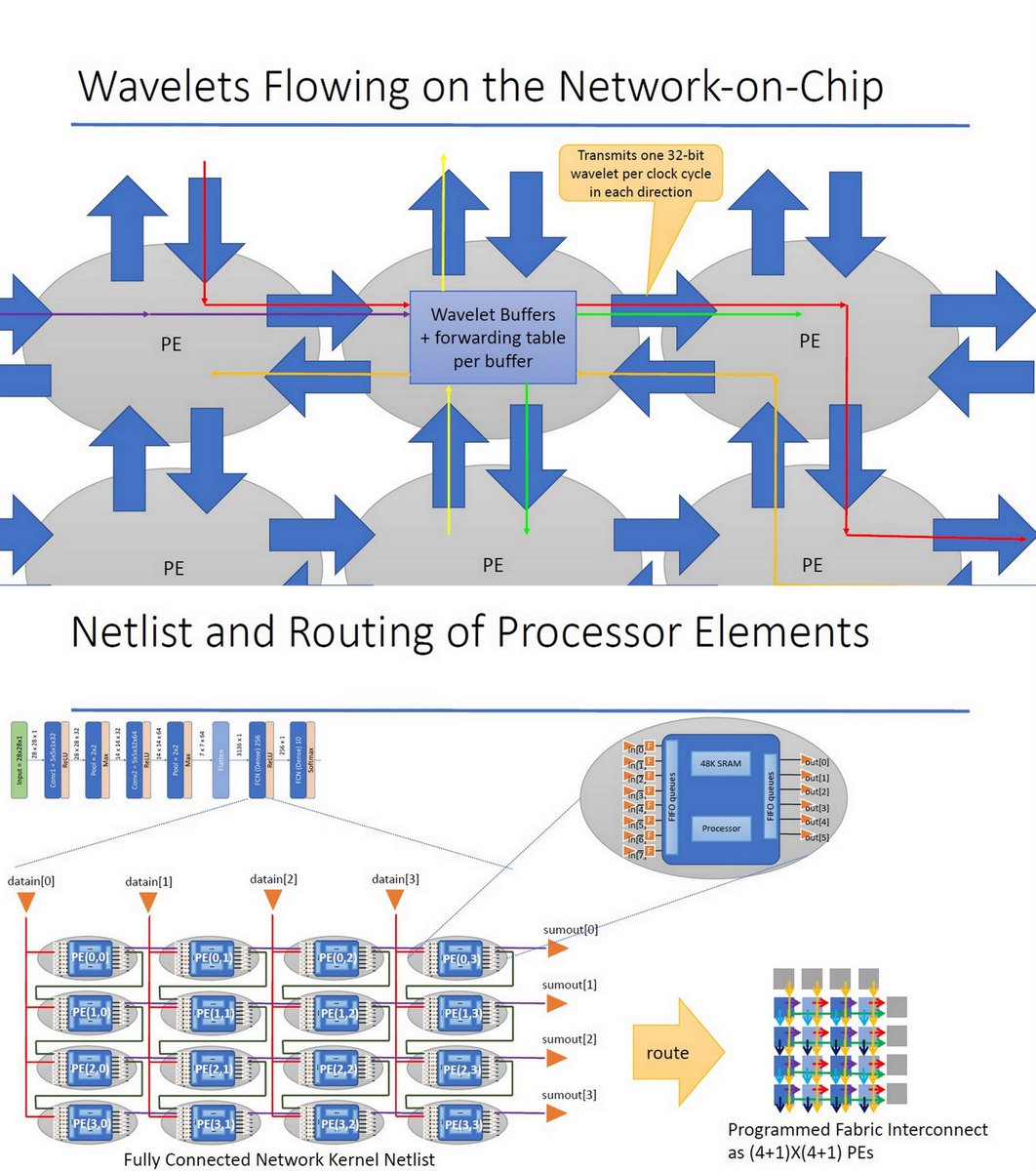

=>
Nat. Lab Supercomputing Sites Pick @SambaNovaAI for AI System Dance, Oct 19, 2020 nextplatform.com/2020/10/19/nat…
SambaNova is currently attached to the Corona supercomputer, LLNL
Corona supercomputer
Oct 7 llnl.gov/news/corona-su…
Aug 28
Nat. Lab Supercomputing Sites Pick @SambaNovaAI for AI System Dance, Oct 19, 2020 nextplatform.com/2020/10/19/nat…
SambaNova is currently attached to the Corona supercomputer, LLNL
Corona supercomputer
Oct 7 llnl.gov/news/corona-su…
https://twitter.com/ogawa_tter/status/1198562827495043073
Aug 28
https://twitter.com/ogawa_tter/status/1301515293773234178

=>
"TensorFlow Lite Micro: Embedded Machine Learning on TinyML Systems", Google, arXiv, Oct 17, 2020 arxiv.org/abs/2010.08678
explains the design decisions behind TF Micro and describes its implementation details.
Benchmark Performance
Arm CPU Cortex-M4
Xtensa DSP HiFi Mini
"TensorFlow Lite Micro: Embedded Machine Learning on TinyML Systems", Google, arXiv, Oct 17, 2020 arxiv.org/abs/2010.08678
explains the design decisions behind TF Micro and describes its implementation details.
Benchmark Performance
Arm CPU Cortex-M4
Xtensa DSP HiFi Mini




=>
"AI gets a boost via LLNL, @SambaNovaAI collaboration", Oct 19, 2020 llnl.gov/news/ai-gets-b…
Integrating the SambaNova Systems DataScale, into the NNSA's Corona supercomputing cluster
"cognitive simulation"
+ into LANL's Darwin: Quantum Chemistry
ANL??
"AI gets a boost via LLNL, @SambaNovaAI collaboration", Oct 19, 2020 llnl.gov/news/ai-gets-b…
Integrating the SambaNova Systems DataScale, into the NNSA's Corona supercomputing cluster
"cognitive simulation"
+ into LANL's Darwin: Quantum Chemistry
https://twitter.com/ogawa_tter/status/1318256927281799169
ANL??

=>
"Livermore Computing Integrates Advanced Cognitive Simulation Resource", Jun 24, 2020 osti.gov/biblio/1643766
Preparing the way for advanced cognitive simulation (CogSim)
@CerebrasSystems CS-1 into Lassen
CS-1, Nov 2019
Aug 19
"Livermore Computing Integrates Advanced Cognitive Simulation Resource", Jun 24, 2020 osti.gov/biblio/1643766
Preparing the way for advanced cognitive simulation (CogSim)
@CerebrasSystems CS-1 into Lassen
CS-1, Nov 2019
https://twitter.com/ogawa_tter/status/1200694836384260096
Aug 19
https://twitter.com/ogawa_tter/status/1296155173874614272


=>
"Intel Powers First Satellite with AI on Board", Oct 20, 2020 newsroom.intel.com/news/intel-pow…
1:40
Intel Movidius Myriad 2 Vision Processing Unit (VPU)
Ubotica, PDF enterprise-ireland.com/en/Research-In…
PhiSat-1 directory.eoportal.org/web/eoportal/s…
Hot Chips 2014
"Intel Powers First Satellite with AI on Board", Oct 20, 2020 newsroom.intel.com/news/intel-pow…
1:40
Intel Movidius Myriad 2 Vision Processing Unit (VPU)
Ubotica, PDF enterprise-ireland.com/en/Research-In…
PhiSat-1 directory.eoportal.org/web/eoportal/s…
Hot Chips 2014
https://twitter.com/ogawa_tter/status/692907360101146624


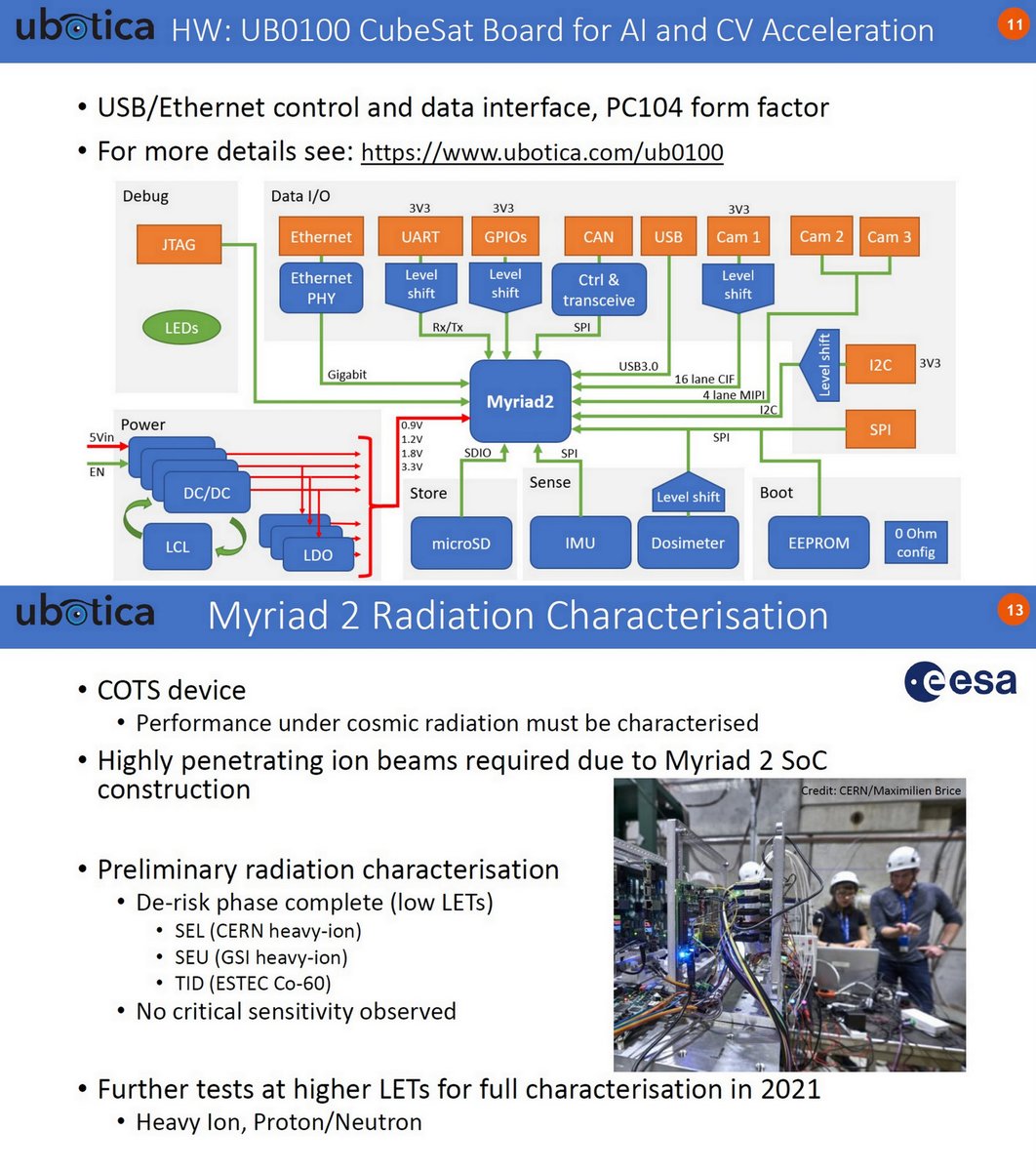

=>
"CloudScout: A Deep Neural Network for On-Board Cloud Detection on Hyperspectral Images", Remote Sensing, Jul 10, 2020 mdpi.com/2072-4292/12/1…
CloudScout: to select images eligible for transmission to ground
PhiSat-1
Intel Movidius Myriad 2 VPU, Oct 20
"CloudScout: A Deep Neural Network for On-Board Cloud Detection on Hyperspectral Images", Remote Sensing, Jul 10, 2020 mdpi.com/2072-4292/12/1…
CloudScout: to select images eligible for transmission to ground
PhiSat-1
Intel Movidius Myriad 2 VPU, Oct 20
https://twitter.com/ogawa_tter/status/1318567382101553152


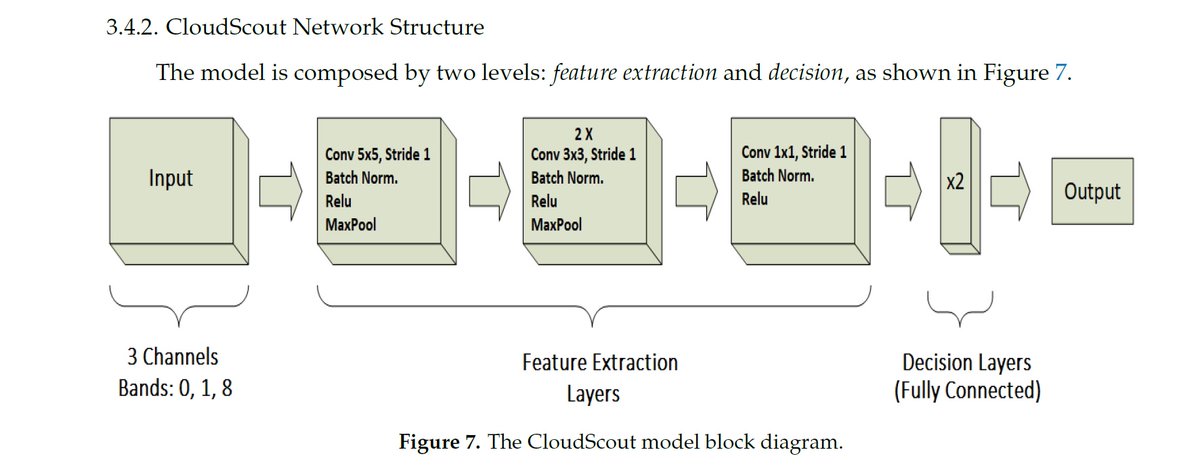

=>
"Homomorphic Encryption for Machine Learning in Medicine and Bioinformatics", ACM Computing Surveys, Aug 2020 eprints.whiterose.ac.uk/151333/
Fully Homomorphic Encryption
208 refs
Najarian Lab najarianlab.ccmb.med.umich.edu
D. Kahrobaei sites.google.com/a/nyu.edu/dela…
FHE
"Homomorphic Encryption for Machine Learning in Medicine and Bioinformatics", ACM Computing Surveys, Aug 2020 eprints.whiterose.ac.uk/151333/
Fully Homomorphic Encryption
208 refs
Najarian Lab najarianlab.ccmb.med.umich.edu
D. Kahrobaei sites.google.com/a/nyu.edu/dela…
FHE
https://twitter.com/ogawa_tter/status/1317720404845240321



=>
"Hardware-based Fast Real-time Image Classification with Stochastic Computing", ICCD 2020
10:20
Zynq-7000
P. K. Muthappa Wins Xilinx Open HW Competition, Sep 2019 uni-stuttgart.de/en/university/…
I. Polian polian.de/ilia/
J. Hayes web.eecs.umich.edu/~jhayes/
"Hardware-based Fast Real-time Image Classification with Stochastic Computing", ICCD 2020
10:20
Zynq-7000
P. K. Muthappa Wins Xilinx Open HW Competition, Sep 2019 uni-stuttgart.de/en/university/…
I. Polian polian.de/ilia/
J. Hayes web.eecs.umich.edu/~jhayes/



=>
"Flex Logix Announces Working Silicon Of Fastest And Most Efficient AI Edge Inference Chip", Oct 20, 2020 prnewswire.com/news-releases/…
"InferX X1: An AI Inference Accelerator With High Throughput/mm^2", Linley Conf, Oct 20, 2020, PDF flex-logix.com/wp-content/upl…
flex-logix.com/inference/
"Flex Logix Announces Working Silicon Of Fastest And Most Efficient AI Edge Inference Chip", Oct 20, 2020 prnewswire.com/news-releases/…
"InferX X1: An AI Inference Accelerator With High Throughput/mm^2", Linley Conf, Oct 20, 2020, PDF flex-logix.com/wp-content/upl…
flex-logix.com/inference/




=>
@mlperf1 Inference v0.7 results, Oct 21, 2020 mlperf.org/press#mlperf-i…
4 new benchmarks for data center & edge systems
BERT, DLRM, 3D U-Net, RNN-T
MLPerf Mobile
MobileNetEdgeTPU, SSD-MobileNetV2, DeepLabv3, MobileBERT
Benchmarks mlperf.org/inference-over…
@mlperf1 Inference v0.7 results, Oct 21, 2020 mlperf.org/press#mlperf-i…
4 new benchmarks for data center & edge systems
BERT, DLRM, 3D U-Net, RNN-T
MLPerf Mobile
MobileNetEdgeTPU, SSD-MobileNetV2, DeepLabv3, MobileBERT
Benchmarks mlperf.org/inference-over…
https://twitter.com/ogawa_tter/status/1234893886222241792

=>
"Microchip Acquires High-Level Synthesis Tool Provider LegUp to Simplify Development of PolarFire FPGA-based Edge Compute Solutions", Oct 21, 2020 microchip.com/en/pressreleas…
Andrew Canis (Co-Founder & CEO, LegUp), Oct 9, 2020 legupcomputing.com/blog/index.php…
LegUp legupcomputing.com
"Microchip Acquires High-Level Synthesis Tool Provider LegUp to Simplify Development of PolarFire FPGA-based Edge Compute Solutions", Oct 21, 2020 microchip.com/en/pressreleas…
Andrew Canis (Co-Founder & CEO, LegUp), Oct 9, 2020 legupcomputing.com/blog/index.php…
LegUp legupcomputing.com
=>
"Experiences with ML-Driven Design: A NoC Case Study", AMD, HPCA 2020 jiemingyin.github.io/docs/HPCA2020.…
New arbitration scheme that is effective for NoCs under heavy contention
"Modular Routing Design for Chiplet-based Systems", ISCA 2018 jiemingyin.github.io/docs/ISCA2018.…
"Experiences with ML-Driven Design: A NoC Case Study", AMD, HPCA 2020 jiemingyin.github.io/docs/HPCA2020.…
New arbitration scheme that is effective for NoCs under heavy contention
"Modular Routing Design for Chiplet-based Systems", ISCA 2018 jiemingyin.github.io/docs/ISCA2018.…
https://twitter.com/ogawa_tter/status/1017024552675602437




=>
"Scaling a reconfigurable dataflow accelerator", Yaqi Zhang, PhD Thesis, 2020 searchworks.stanford.edu/view/13596600
SARA: Spatial applications to Plasticine
Gorgon 2020
Scalable Interconnects 2019 (Plasticine)
SambaNova
"Scaling a reconfigurable dataflow accelerator", Yaqi Zhang, PhD Thesis, 2020 searchworks.stanford.edu/view/13596600
SARA: Spatial applications to Plasticine
Gorgon 2020
https://twitter.com/ogawa_tter/status/1267849004487815171
Scalable Interconnects 2019 (Plasticine)
https://twitter.com/ogawa_tter/status/1193265054004604928
SambaNova
https://twitter.com/ogawa_tter/status/1301515293773234178




=>
"Non-Blocking Simultaneous Multithreading: Embracing the Resiliency of Deep Neural Networks", Gil Shomron, Uri Weiser, Technion, MICRO 2020, PDF microarch.org/micro53/papers…
SySMT: NB-SMT-enabled output-stationary Systolic
Array
Patent Appl, Jun 18, 2020 patents.google.com/patent/US20200…
"Non-Blocking Simultaneous Multithreading: Embracing the Resiliency of Deep Neural Networks", Gil Shomron, Uri Weiser, Technion, MICRO 2020, PDF microarch.org/micro53/papers…
SySMT: NB-SMT-enabled output-stationary Systolic
Array
Patent Appl, Jun 18, 2020 patents.google.com/patent/US20200…




=>
"Dynamic Energy and Thermal Management of Multi-Core Mobile Platforms: A Survey", IEEE Design and Test, Oct 2020 repository.essex.ac.uk/27441/
50 references
Amit Kumar Singh aksingh.co.uk
"A Survey on Energy Management for Mobile and IoT Devices"
"Dynamic Energy and Thermal Management of Multi-Core Mobile Platforms: A Survey", IEEE Design and Test, Oct 2020 repository.essex.ac.uk/27441/
50 references
Amit Kumar Singh aksingh.co.uk
"A Survey on Energy Management for Mobile and IoT Devices"
https://twitter.com/ogawa_tter/status/1280967152158171136


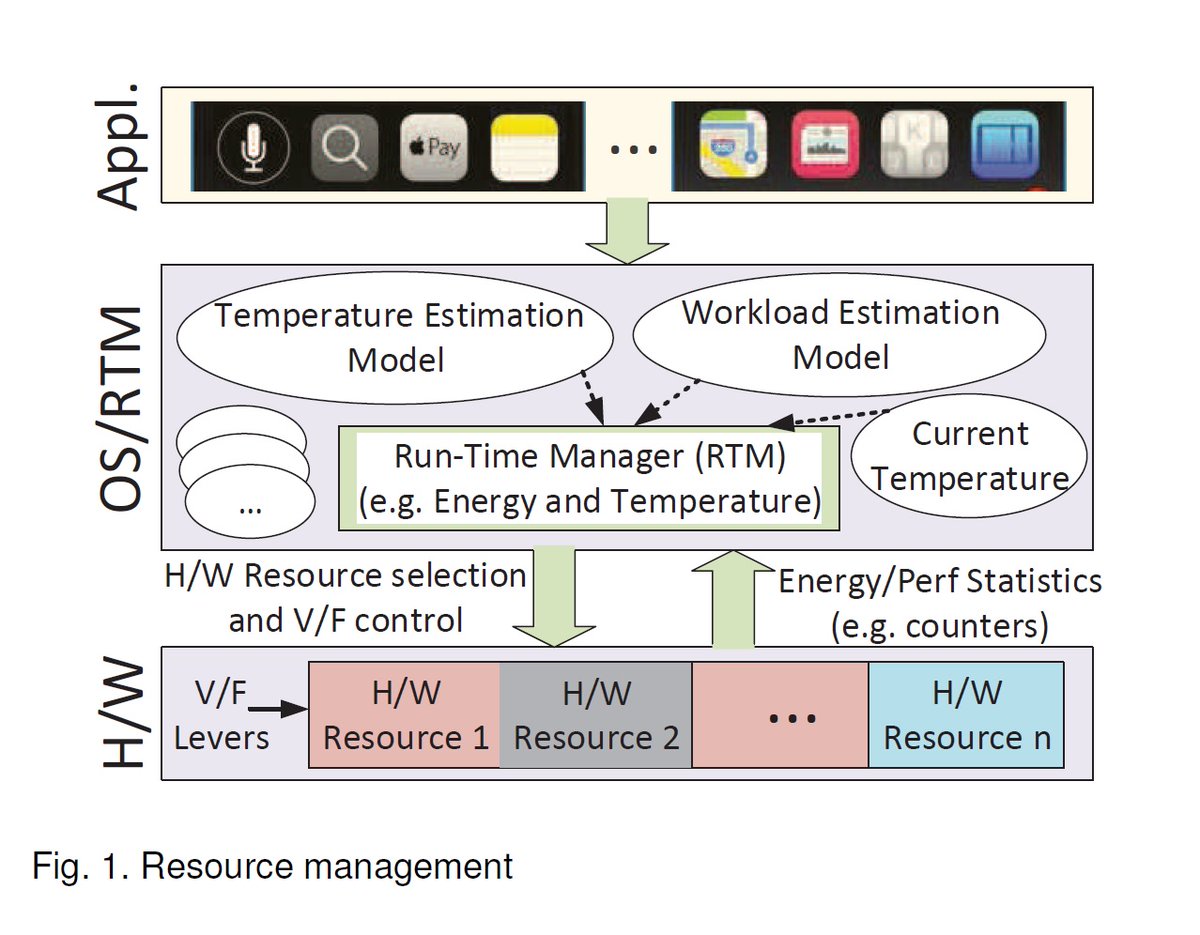
=>
"Coprocessors with Bypass Optimization, Variable Grid Architecture, and Fused Vector Operations", Apple, Patent Appl, Aug 27, 2020 patents.google.com/patent/US20200…
Coprocessor ..., Patent Appl
Aug 27 patents.google.com/patent/US20200…
Jul 9 patents.google.com/patent/US20200…
Jun 11 patents.google.com/patent/US20200…
"Coprocessors with Bypass Optimization, Variable Grid Architecture, and Fused Vector Operations", Apple, Patent Appl, Aug 27, 2020 patents.google.com/patent/US20200…
Coprocessor ..., Patent Appl
Aug 27 patents.google.com/patent/US20200…
Jul 9 patents.google.com/patent/US20200…
Jun 11 patents.google.com/patent/US20200…

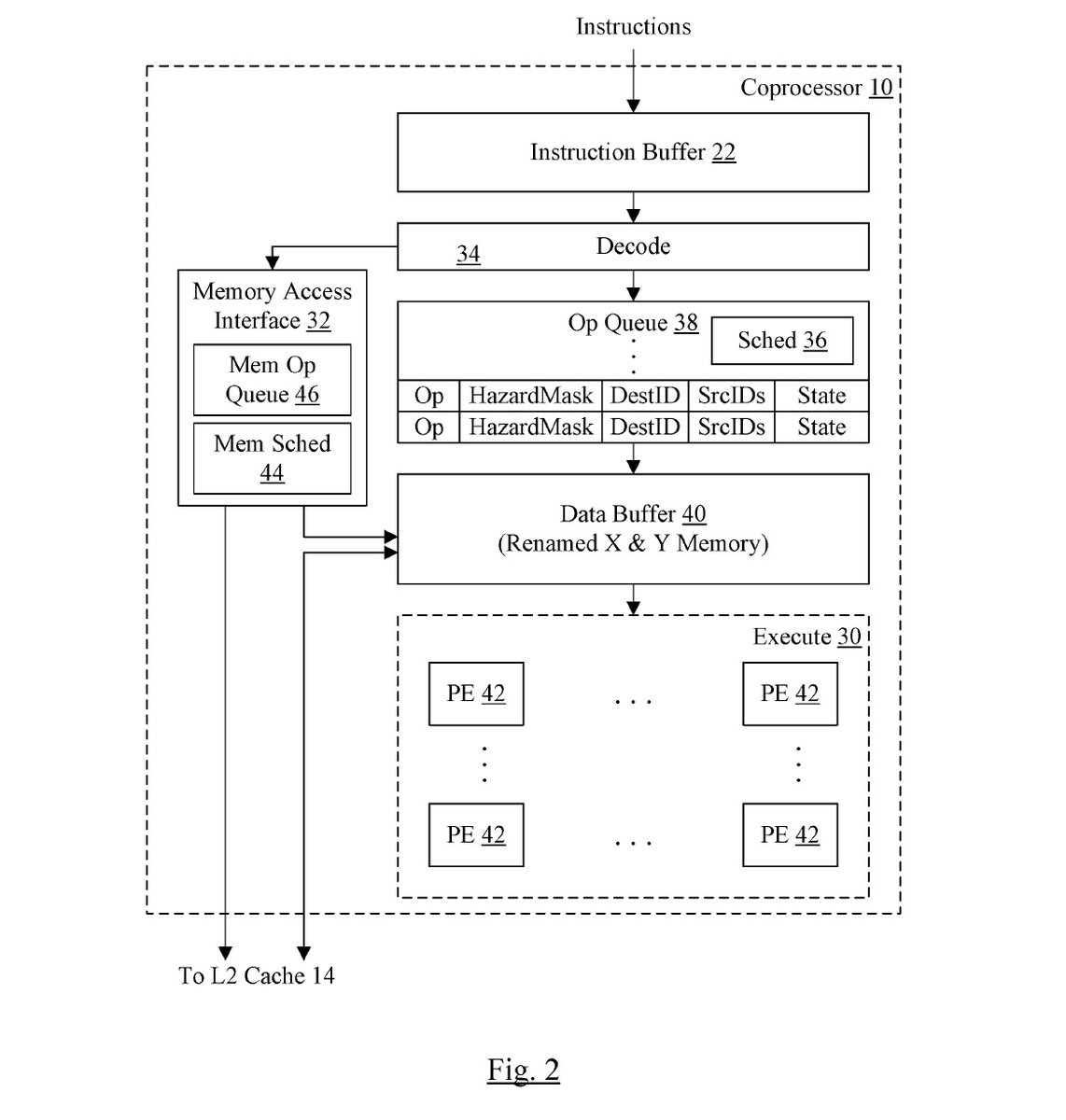

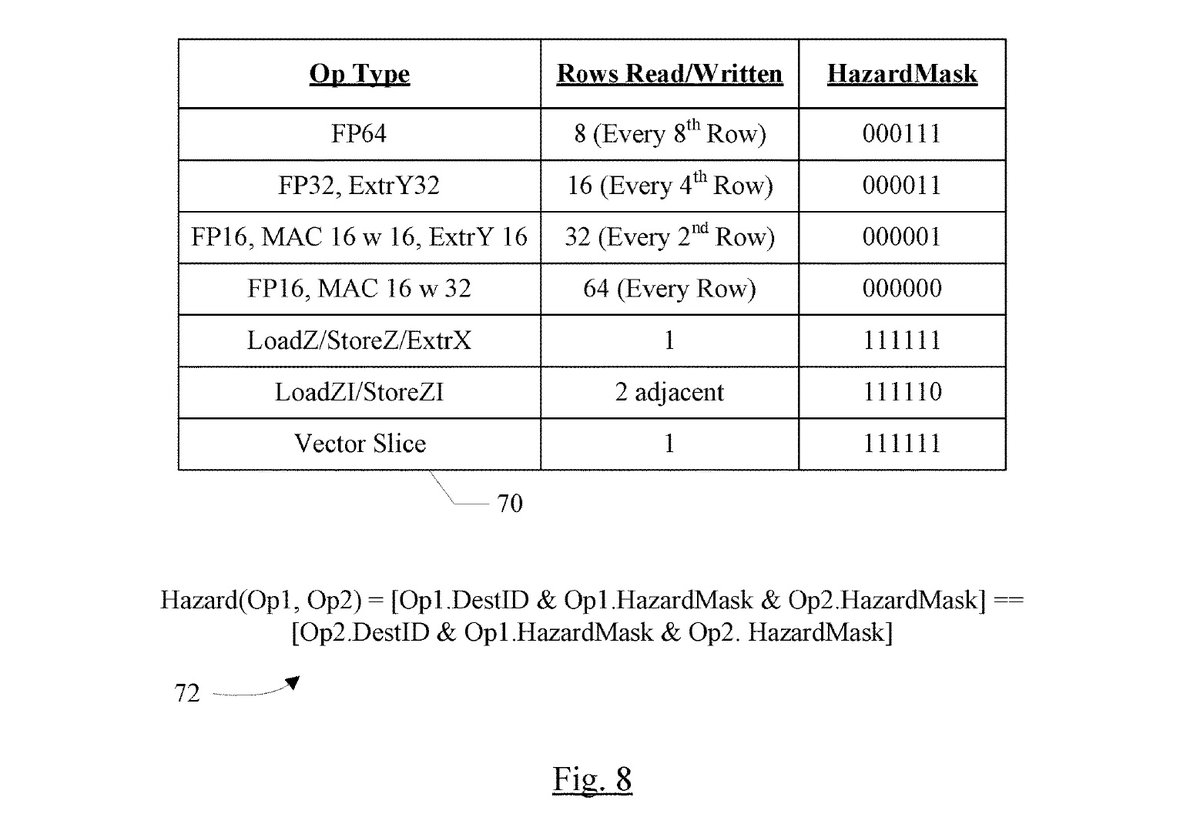
=>
"The Wafer Scale Interconnect in the Wafer Scale Engine", Robert Hesse @CerebrasSystems , Special Session - Scalable Platforms for ML: An Industry Perspective, NOCS 2020, Sep 25
32:04
Purpose-built NOC for DL at Wafer Scale
"The Wafer Scale Interconnect in the Wafer Scale Engine", Robert Hesse @CerebrasSystems , Special Session - Scalable Platforms for ML: An Industry Perspective, NOCS 2020, Sep 25
32:04
Purpose-built NOC for DL at Wafer Scale
https://twitter.com/ogawa_tter/status/1318167129712066561

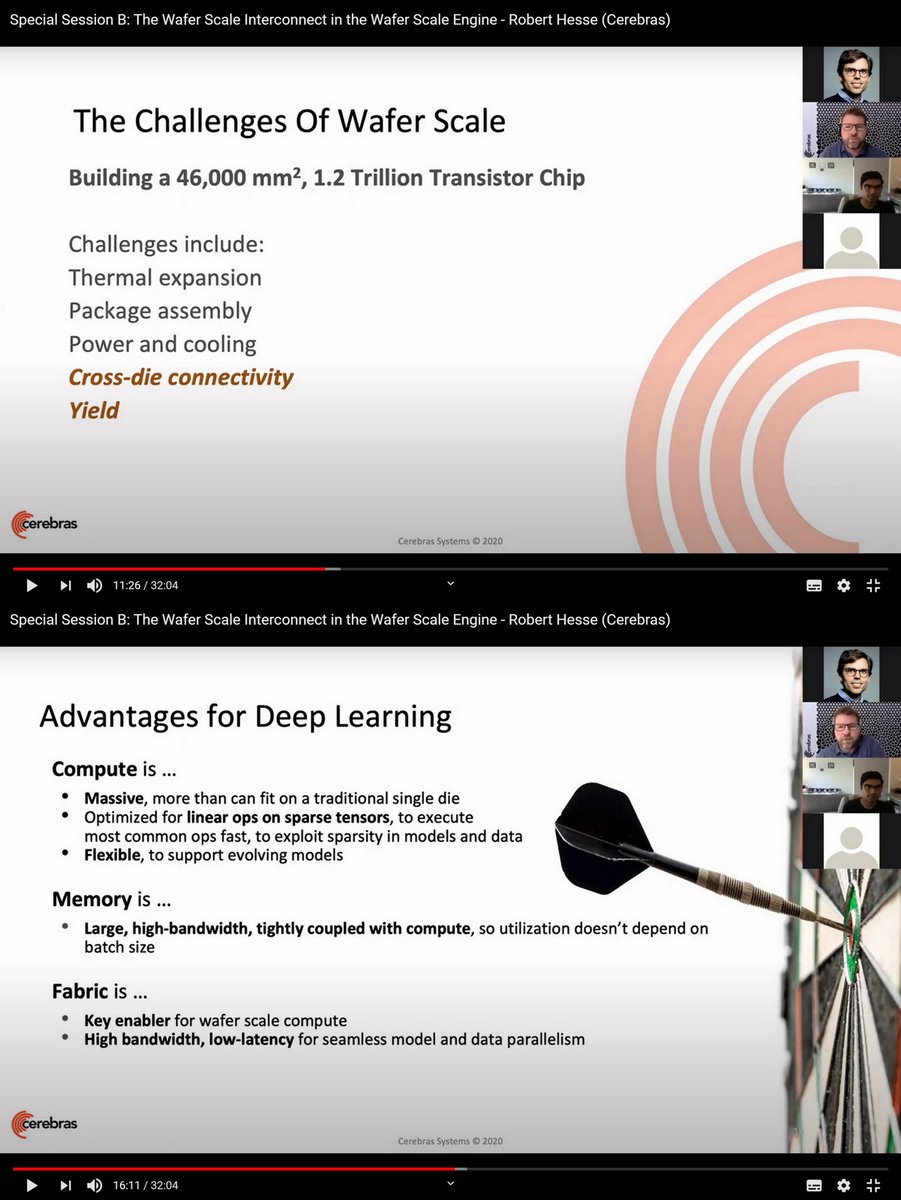
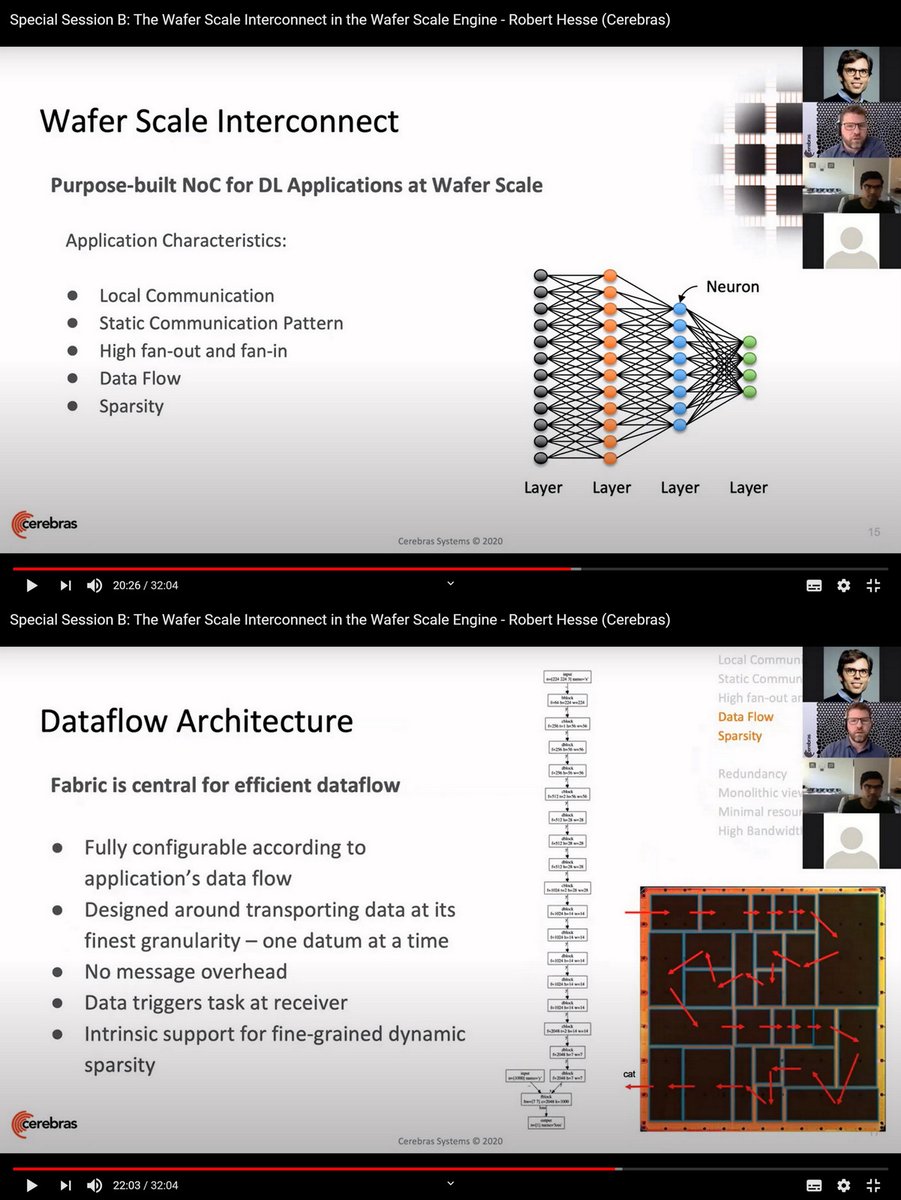

=>
"Domain-Specific Networks for Machine Learning", Dennis Abts, @GroqInc , Keynote, NOCS 2020, Sep 25, 2020
Wide variety of NW topologies
Fully-connection/ 3D Torus, etc
Jun 25
Sep 29
marvell.com/company/newsro…
"Domain-Specific Networks for Machine Learning", Dennis Abts, @GroqInc , Keynote, NOCS 2020, Sep 25, 2020
Wide variety of NW topologies
Fully-connection/ 3D Torus, etc
Jun 25
https://twitter.com/ogawa_tter/status/1275577199014240256
Sep 29
https://twitter.com/ogawa_tter/status/1310981140686073856
marvell.com/company/newsro…




=>
"iPIM: Programmable In-Memory Image Processing Accelerator Using Near-Bank Architecture", UCSB, Alibaba Cloud / DAMO, ISCA 2020
miglopst.github.io/files/gu_isca2…
miglopst.github.io/files/gu_isca2…
Technology Trends in 2020
"iPIM: Programmable In-Memory Image Processing Accelerator Using Near-Bank Architecture", UCSB, Alibaba Cloud / DAMO, ISCA 2020
miglopst.github.io/files/gu_isca2…
miglopst.github.io/files/gu_isca2…
Technology Trends in 2020
https://twitter.com/ogawa_tter/status/1214512284753518594
https://twitter.com/ogawa_tter/status/1177262991324020736


=>
"Esperanto Accelerates Machine Learning With RISC-V", Art Swift, CEO, Esperanto, RISC-V Summit, Dec 8, 2020 tmt.knect365.com/risc-v-summit/…
Ditzelさんの講演じゃなくて気になっていた…
web.archive.org/web/2019121019…
esperanto.ai/executive_team/
Espasaさんの名前も消えている。
"Esperanto Accelerates Machine Learning With RISC-V", Art Swift, CEO, Esperanto, RISC-V Summit, Dec 8, 2020 tmt.knect365.com/risc-v-summit/…
Ditzelさんの講演じゃなくて気になっていた…
https://twitter.com/david_schor/status/1321328771258081280
web.archive.org/web/2019121019…
esperanto.ai/executive_team/
Espasaさんの名前も消えている。
=>
"Flex Logix Announces Availability and Roadmap of InferX X1 Boards and Software Tools", Oct 28 2020 flex-logix.com/wp-content/upl…
InferX X1P1: $399 - $499
InferX X1P4: $649 - $999
Linley Fall Processor Conf, Oct 28 flex-logix.com/wp-content/upl…
InferX X1, Oct 20
"Flex Logix Announces Availability and Roadmap of InferX X1 Boards and Software Tools", Oct 28 2020 flex-logix.com/wp-content/upl…
InferX X1P1: $399 - $499
InferX X1P4: $649 - $999
Linley Fall Processor Conf, Oct 28 flex-logix.com/wp-content/upl…
InferX X1, Oct 20
https://twitter.com/ogawa_tter/status/1319022592305451008



=>
2nd ACM/IEEE Workshop on Machine Learning for CAD (MLCAD), Nov 16-20, 2020 mlcad.itec.kit.edu/index.html
Virtual Workshop
Registration mlcad.itec.kit.edu/page7.html
By Nov 8: ACM or IEEE: $59/Non: $79
After Nov 8: $74/$99
MLCAD 2019, Sep 3-4 mlcad.itec.kit.edu/MLCAD_Program_…
2nd ACM/IEEE Workshop on Machine Learning for CAD (MLCAD), Nov 16-20, 2020 mlcad.itec.kit.edu/index.html
Virtual Workshop
Registration mlcad.itec.kit.edu/page7.html
By Nov 8: ACM or IEEE: $59/Non: $79
After Nov 8: $74/$99
MLCAD 2019, Sep 3-4 mlcad.itec.kit.edu/MLCAD_Program_…

=>
"Intel to Acquire SigOpt to Scale AI Productivity and Performance", Oct 29, 2020 newsroom.intel.com/news/intel-to-…
sigopt.com
Scott Clark, Co-Founder & CEO sigopt.com/team/scott-cla…
scholar.google.com/citations?hl=e…
Patrick Hayes, Co-Founder & CTO sigopt.com/team/patrick-h…
"Intel to Acquire SigOpt to Scale AI Productivity and Performance", Oct 29, 2020 newsroom.intel.com/news/intel-to-…
sigopt.com
Scott Clark, Co-Founder & CEO sigopt.com/team/scott-cla…
scholar.google.com/citations?hl=e…
Patrick Hayes, Co-Founder & CTO sigopt.com/team/patrick-h…
=>
"Big-Data Science in Porous Materials: Materials Genomics and Machine Learning", Review, Chemical Reviews, Jun 10, 2020 pubs.acs.org/doi/10.1021/ac…
10 chapters. 64 pages
576 references
Berend Smit epfl.ch/labs/lsmo/smit/
"Big-Data Science in Porous Materials: Materials Genomics and Machine Learning", Review, Chemical Reviews, Jun 10, 2020 pubs.acs.org/doi/10.1021/ac…
10 chapters. 64 pages
576 references
Berend Smit epfl.ch/labs/lsmo/smit/



=>
"Apple A14 Die Annotation and Analysis – Terrifying Implications For The Industry", Oct 30, 2020 semianalysis.com/apple-a14-die-…
Oct 27 semianalysis.com/apples-a14-pac…
Tim Millet & Tom Boger, Oct 12
A14 Bionic, Sep 15
"Apple A14 Die Annotation and Analysis – Terrifying Implications For The Industry", Oct 30, 2020 semianalysis.com/apple-a14-die-…
Oct 27 semianalysis.com/apples-a14-pac…
Tim Millet & Tom Boger, Oct 12
https://twitter.com/ogawa_tter/status/1316149468207616000
A14 Bionic, Sep 15
https://twitter.com/ogawa_tter/status/1306025250845601793
https://twitter.com/ogawa_tter/status/1311568789855596544

=>
"Advancing Fusion with Machine Learning Research Needs Workshop Report", Journal of Fusion Energy, Sep 26, 2020 link.springer.com/article/10.100…
Seven Priority Research Opportunities (PRO's) for application of ML/AI methods
Full report, PDF science.osti.gov/-/media/fes/pd…
"Advancing Fusion with Machine Learning Research Needs Workshop Report", Journal of Fusion Energy, Sep 26, 2020 link.springer.com/article/10.100…
Seven Priority Research Opportunities (PRO's) for application of ML/AI methods
Full report, PDF science.osti.gov/-/media/fes/pd…




=>
"In-Memory Acceleration for Big Data", Jul 2020, Linley Group, PDF gsitechnology.com/sites/default/…
Associative Processing Unit (APU)
In-Place Associative Computing, GSI Technology gsitechnology.com/APU
Similarity Search, PDF gsitechnology.com/sites/default/…
Oct 29 ir.gsitechnology.com/news-releases/…
"In-Memory Acceleration for Big Data", Jul 2020, Linley Group, PDF gsitechnology.com/sites/default/…
Associative Processing Unit (APU)
In-Place Associative Computing, GSI Technology gsitechnology.com/APU
Similarity Search, PDF gsitechnology.com/sites/default/…
Oct 29 ir.gsitechnology.com/news-releases/…



=>
"Untether AI Ushers in the PetaOps Era with At-Memory Computation for AI Inference Workloads", Oct 29, 2020 untether.ai/press-releases…
2 PetaOps in a PCI-Express card untether.ai/products
"Server Inference Chip Startup Untethered from AI Data Movement" nextplatform.com/2020/10/29/ser…
"Untether AI Ushers in the PetaOps Era with At-Memory Computation for AI Inference Workloads", Oct 29, 2020 untether.ai/press-releases…
2 PetaOps in a PCI-Express card untether.ai/products
"Server Inference Chip Startup Untethered from AI Data Movement" nextplatform.com/2020/10/29/ser…

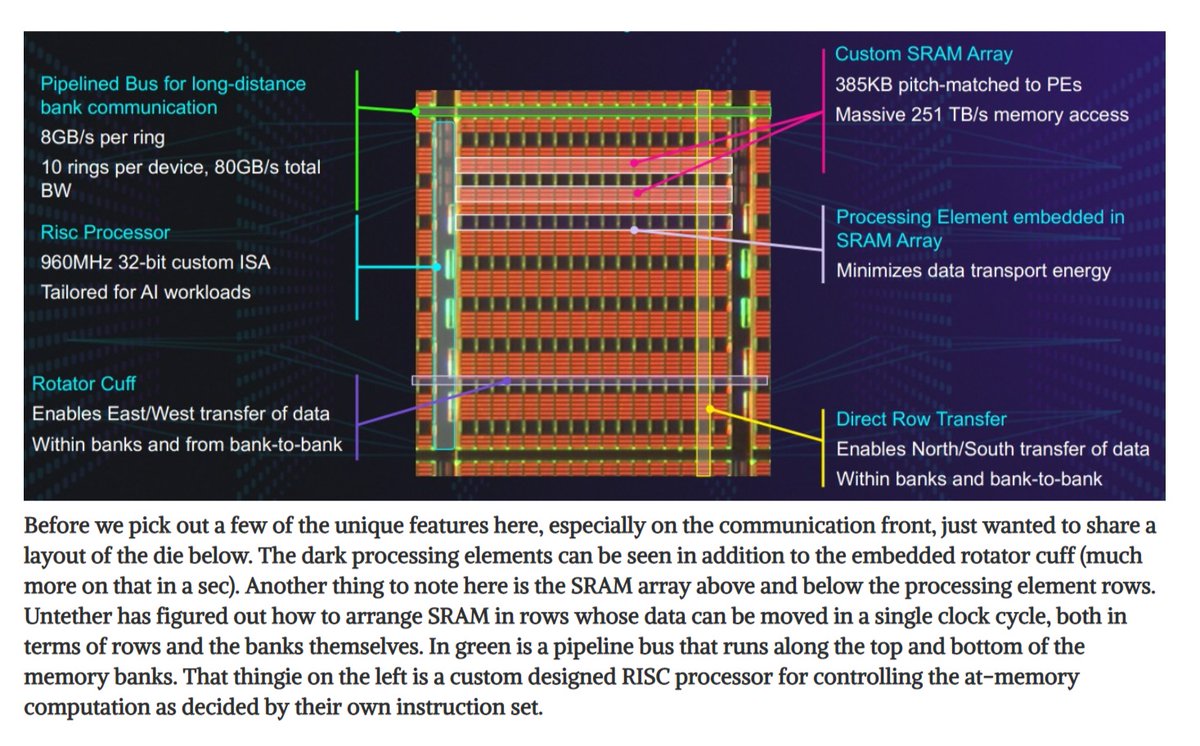
=>
"Data- and communication-centric approaches to model and design flexible deep neural network accelerators", Kwon, Hyouk Jun, PhD Thesis, 2020 smartech.gatech.edu/handle/1853/63…
MAESTRO, MICRO 2019, Top Picks
Microswitches
MAERI, ASPLOS 2018, Top Picks
Herald
hyoukjunkwon.com
"Data- and communication-centric approaches to model and design flexible deep neural network accelerators", Kwon, Hyouk Jun, PhD Thesis, 2020 smartech.gatech.edu/handle/1853/63…
MAESTRO, MICRO 2019, Top Picks
Microswitches
MAERI, ASPLOS 2018, Top Picks
Herald
hyoukjunkwon.com




=>
"Accelerating Chip Design With Machine Learning", Brucek Khailany, ..., William Dally, NVIDIA, IEEE Micro, Nov/Dec 2020 ieeexplore.ieee.org/document/92056…
Future vision of an AI-assisted automated chip design workflow
research.nvidia.com/publication/20…
B. Khailany, Jul 2019
"Accelerating Chip Design With Machine Learning", Brucek Khailany, ..., William Dally, NVIDIA, IEEE Micro, Nov/Dec 2020 ieeexplore.ieee.org/document/92056…
Future vision of an AI-assisted automated chip design workflow
research.nvidia.com/publication/20…
B. Khailany, Jul 2019
https://twitter.com/ogawa_tter/status/1152004749752848384
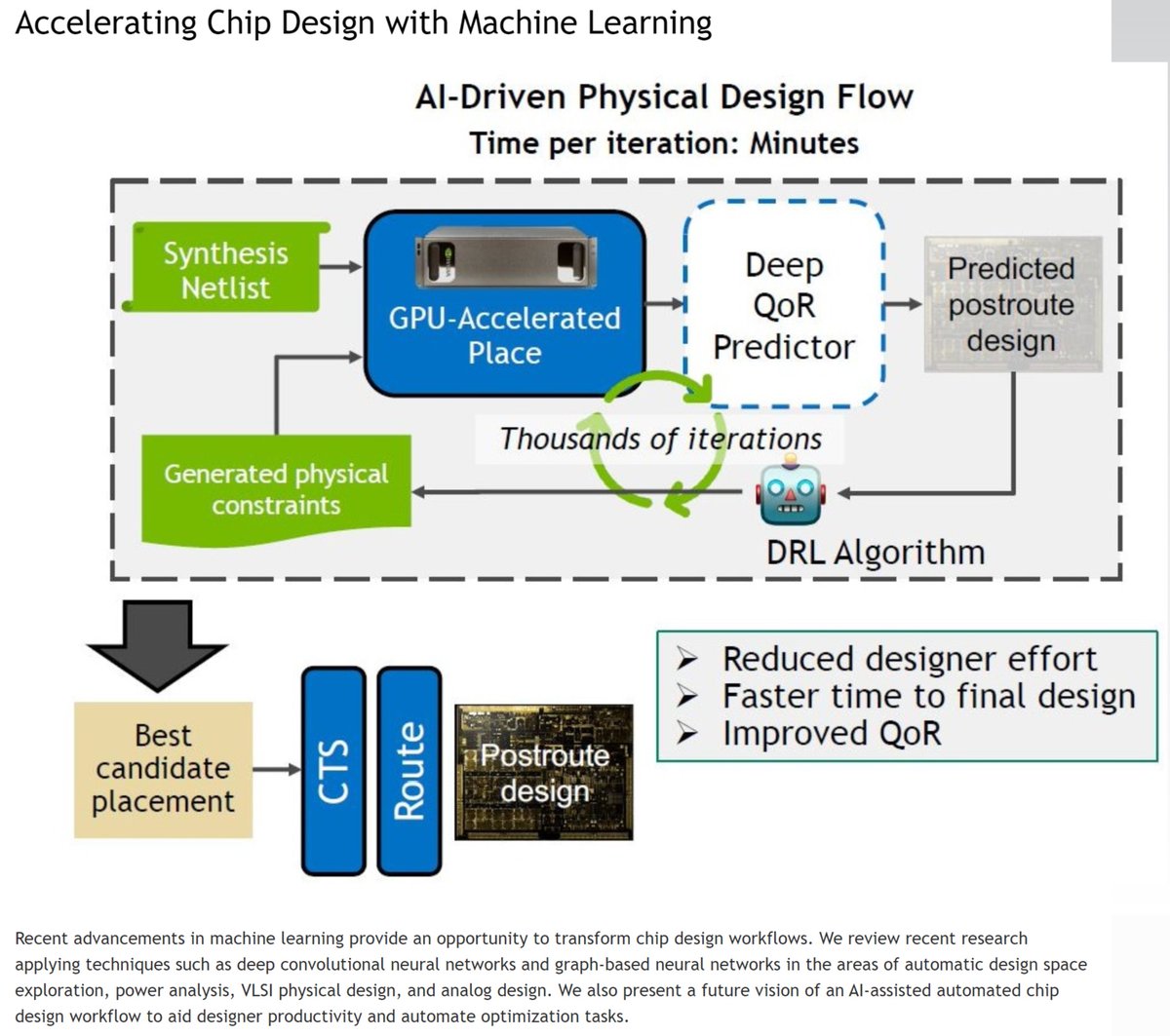
=>
MLCAD, Nov 16-20, 2020 mlcad.itec.kit.edu/index.html
Program mlcad.itec.kit.edu/assets/files/p…
Keynote
A. Kahng, UCSD
W. Ecker, Infineon
R, Jain, Qualcomm
E. Fallon, Cadence
Plenary
B. Khailany, NVIDIA
I. Bustany, Xilinx
M. Leung, Huawei
V. Khandelwal, Synopsys
MLCAD, Nov 16-20, 2020 mlcad.itec.kit.edu/index.html
Program mlcad.itec.kit.edu/assets/files/p…
Keynote
A. Kahng, UCSD
W. Ecker, Infineon
R, Jain, Qualcomm
E. Fallon, Cadence
Plenary
B. Khailany, NVIDIA
https://twitter.com/ogawa_tter/status/1323116937329565700
I. Bustany, Xilinx
M. Leung, Huawei
V. Khandelwal, Synopsys



=>
Russian Conference on Artificial Intelligence (RCAI) 2020, Oct 12-16, 2020 caics.ru/en_raai
Program easychair.org/smart-program/…
Proceedings of RCAI-2020 springer.com/gp/book/978303…
27 full & 8 short papers
"Russian AI Research 2010-2018", Oct 2020, CSET
Russian Conference on Artificial Intelligence (RCAI) 2020, Oct 12-16, 2020 caics.ru/en_raai
Program easychair.org/smart-program/…
Proceedings of RCAI-2020 springer.com/gp/book/978303…
27 full & 8 short papers
"Russian AI Research 2010-2018", Oct 2020, CSET
https://twitter.com/ogawa_tter/status/1325523958049906688
=>
" @tenstorrent 's Holistic Stack Of AI Innovation", Oct 22, 2020, Moor Insights & Strategy moorinsightsstrategy.com/research-paper…
2019: Jawbridge
2020: Grayskull, 65W, 368-TOPS (8-bit FP)
2021: Wormhole, + NW Switch
Synopsys, Jul 15, 2020 news.synopsys.com/2020-07-15-Ten…
" @tenstorrent 's Holistic Stack Of AI Innovation", Oct 22, 2020, Moor Insights & Strategy moorinsightsstrategy.com/research-paper…
2019: Jawbridge
2020: Grayskull, 65W, 368-TOPS (8-bit FP)
2021: Wormhole, + NW Switch
Synopsys, Jul 15, 2020 news.synopsys.com/2020-07-15-Ten…
https://twitter.com/ogawa_tter/status/1289190569348984835
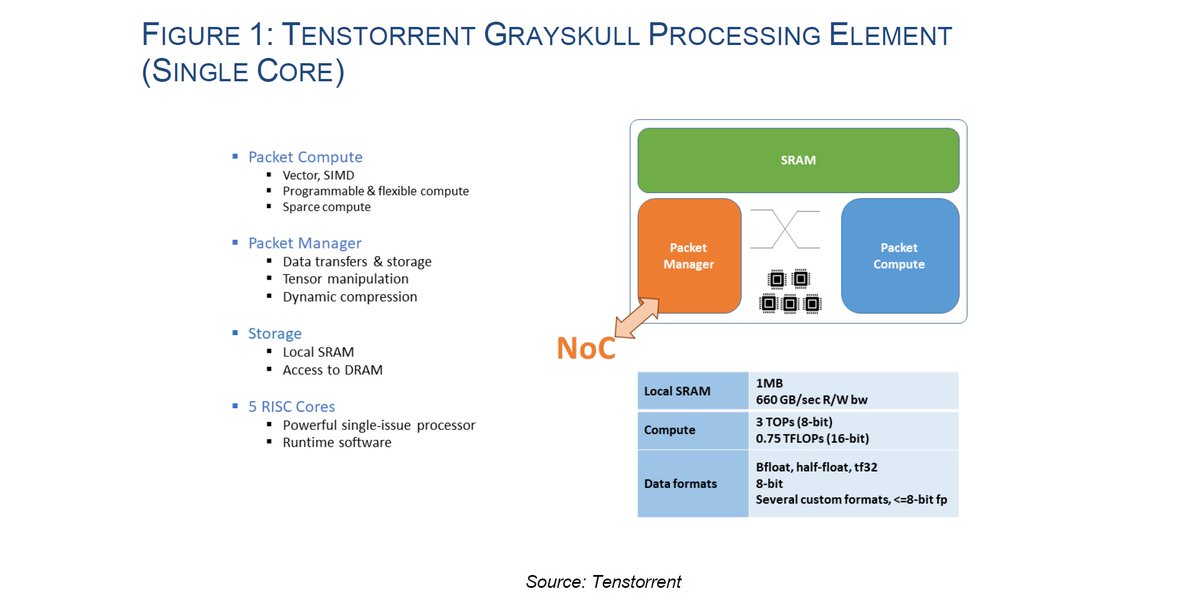



=>
"ZeRO: Memory Optimizations Toward Training Trillion Parameter Models", Microsoft, SC20 sc20.supercomputing.org/presentation/?…
DeepSpeed
github.com/microsoft/Deep…
Webinar, Aug 6, 2020 note.microsoft.com/MSR-Webinar-De…
"DeepSpeed: Extreme-scale model training for everyone", Sep 10 microsoft.com/en-us/research…
"ZeRO: Memory Optimizations Toward Training Trillion Parameter Models", Microsoft, SC20 sc20.supercomputing.org/presentation/?…
DeepSpeed
github.com/microsoft/Deep…
Webinar, Aug 6, 2020 note.microsoft.com/MSR-Webinar-De…
"DeepSpeed: Extreme-scale model training for everyone", Sep 10 microsoft.com/en-us/research…


=>
ETRI Journal, Vol 42, No 4, Aug 2020
Youngsu Kwon, ETRI etri.re.kr/eng/sub6/sub6_…
40 TF AI processor for ISO26262 ASIL‐D onlinelibrary.wiley.com/doi/full/10.42…
Neural processor for inference onlinelibrary.wiley.com/doi/10.4218/et…
Memory‐efficient high‐performance DNN Accelerators onlinelibrary.wiley.com/doi/10.4218/et…
ETRI Journal, Vol 42, No 4, Aug 2020
Youngsu Kwon, ETRI etri.re.kr/eng/sub6/sub6_…
40 TF AI processor for ISO26262 ASIL‐D onlinelibrary.wiley.com/doi/full/10.42…
Neural processor for inference onlinelibrary.wiley.com/doi/10.4218/et…
Memory‐efficient high‐performance DNN Accelerators onlinelibrary.wiley.com/doi/10.4218/et…




=>
"More details on the Intel Stratix 10 NX FPGA, the first AI-optimized Intel FPGA, now available in a new White Paper", Nov 9, 2020 blogs.intel.com/psg/more-detai…
Pushing AI Boundaries with Scalable Compute-Focused FPGAs intel.com/content/www/us…
Stratix 10 NX intel.com/content/www/us…
"More details on the Intel Stratix 10 NX FPGA, the first AI-optimized Intel FPGA, now available in a new White Paper", Nov 9, 2020 blogs.intel.com/psg/more-detai…
Pushing AI Boundaries with Scalable Compute-Focused FPGAs intel.com/content/www/us…
Stratix 10 NX intel.com/content/www/us…




=>
"Numenta Demonstrates 50x Speed Improvements on Deep Learning Networks Using Brain-Derived Algorithms", Nov 10, 2020 numenta.com/press/2020/11/…
Google Speech Commands dataset
Xilinx Alveo and Zynq FPGA
numenta.com/neuroscience-r…
PDF numenta.com/assets/pdf/res…
"Numenta Demonstrates 50x Speed Improvements on Deep Learning Networks Using Brain-Derived Algorithms", Nov 10, 2020 numenta.com/press/2020/11/…
Google Speech Commands dataset
Xilinx Alveo and Zynq FPGA
numenta.com/neuroscience-r…
PDF numenta.com/assets/pdf/res…


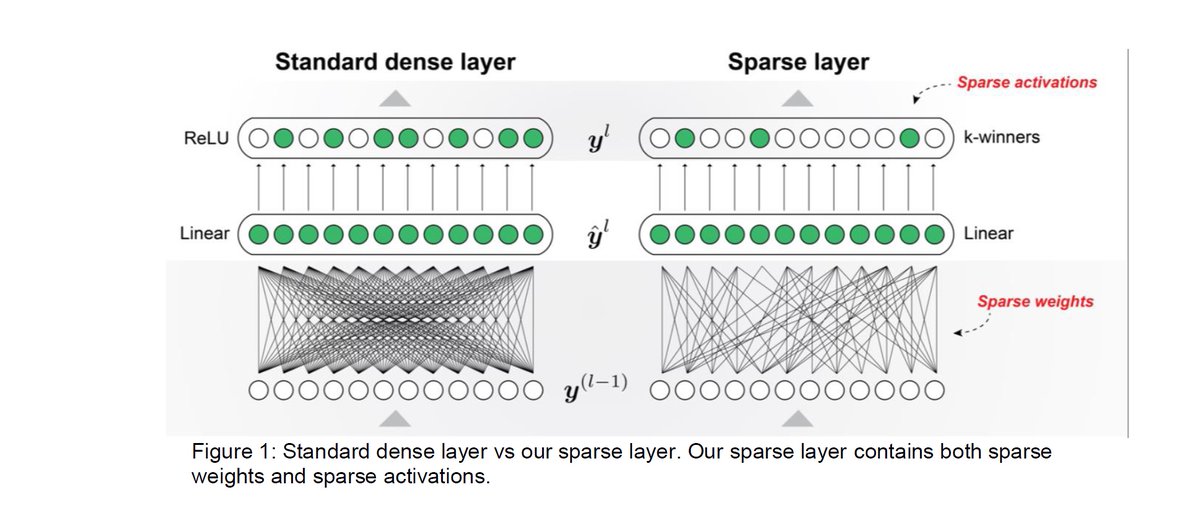
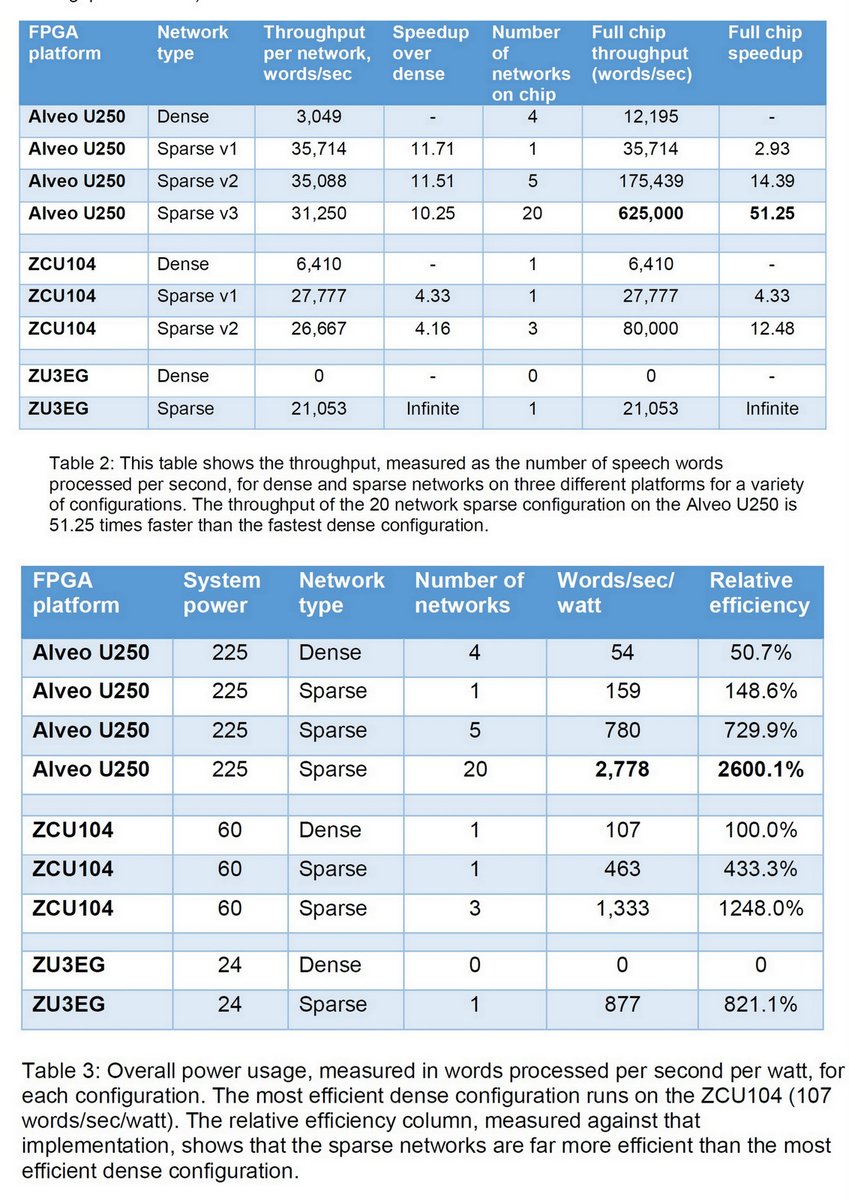
=>
"New ABR Technology Lowers Power Consumption by 94% for Always-On Devices", Applied Brain Research, Sep 14, 2020 appliedbrainresearch.com/press/2020-09-…
"Hardware Aware Training for Efficient Keyword Spotting on General Purpose and Specialized Hardware", arXiv, Sep 23, arxiv.org/abs/2009.04465
"New ABR Technology Lowers Power Consumption by 94% for Always-On Devices", Applied Brain Research, Sep 14, 2020 appliedbrainresearch.com/press/2020-09-…
"Hardware Aware Training for Efficient Keyword Spotting on General Purpose and Specialized Hardware", arXiv, Sep 23, arxiv.org/abs/2009.04465



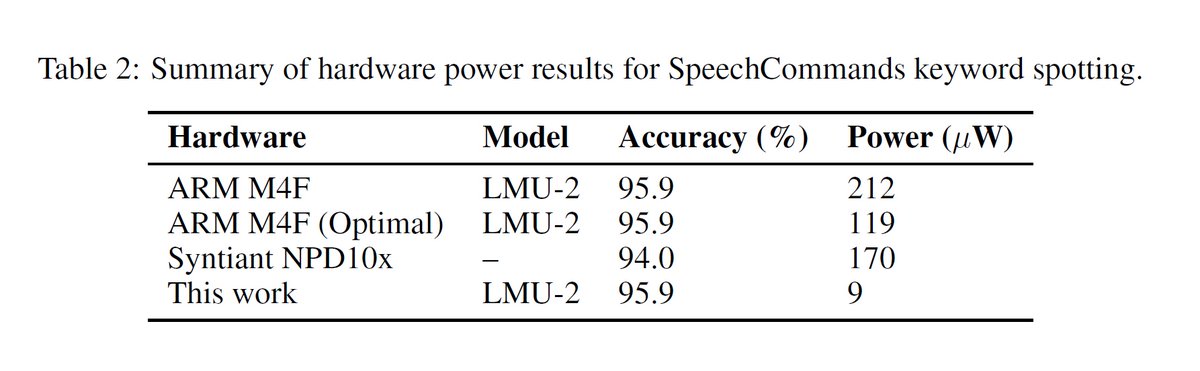
=>
"Accelerating Sparse DNN Models Without Hardware-Support via Tile-wise Sparsity", SJTU, NVIDIA and Rochester, SC20 cs.rochester.edu/horizon/pubs/s…
Slides cs.rochester.edu/horizon/pubs/s…
Tiling and Pruning Co-design achieving a 1:95x speedup over the dense model on V100
github.com/clevercool/Til…
"Accelerating Sparse DNN Models Without Hardware-Support via Tile-wise Sparsity", SJTU, NVIDIA and Rochester, SC20 cs.rochester.edu/horizon/pubs/s…
Slides cs.rochester.edu/horizon/pubs/s…
Tiling and Pruning Co-design achieving a 1:95x speedup over the dense model on V100
github.com/clevercool/Til…



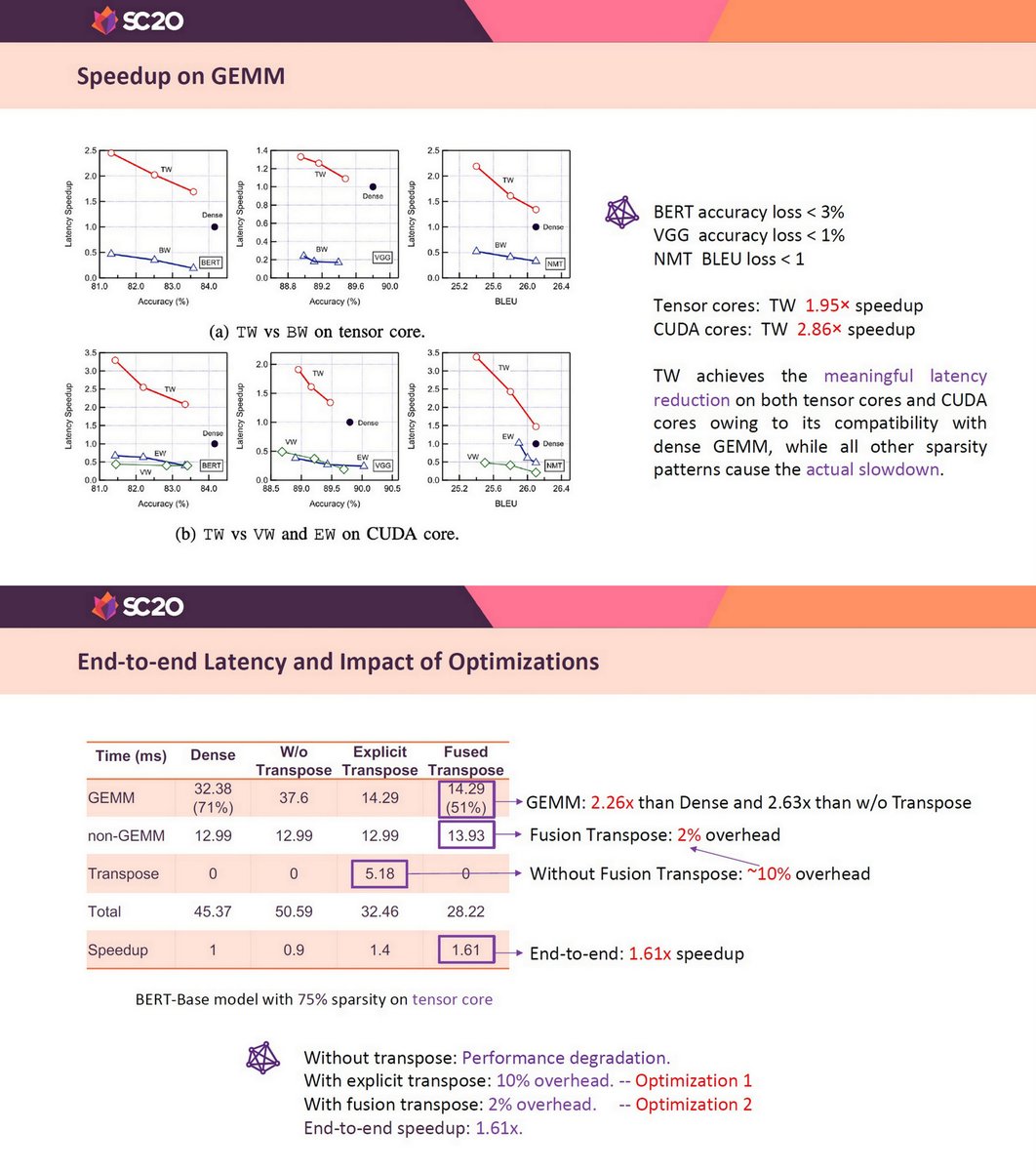
=>
"Amazon Alexa adopts Amazon EC2 Inf1 instances powered by AWS Inferentia", Nov 12, 2020
2:51
migrated a majority of GPU-based ML inference workloads to Amazon EC2 Inf1 instances
30% cost saving, lower latency
Inferentia
"Amazon Alexa adopts Amazon EC2 Inf1 instances powered by AWS Inferentia", Nov 12, 2020
2:51
migrated a majority of GPU-based ML inference workloads to Amazon EC2 Inf1 instances
30% cost saving, lower latency
Inferentia
https://twitter.com/ogawa_tter/status/1234550051520708608
=>
Intel AI Blog
"Deep Learning Performance Boost by Intel VNNI", Oct 13, 2020 intel.com/content/www/us…
"Intel Low Precision Optimization Tool", Sep 16 intel.com/content/www/us…
github.com/intel/lp-opt-t…
Roofline Model for DL Performance Optimizations, Sep 15 intel.com/content/www/us…
Intel AI Blog
"Deep Learning Performance Boost by Intel VNNI", Oct 13, 2020 intel.com/content/www/us…
"Intel Low Precision Optimization Tool", Sep 16 intel.com/content/www/us…
github.com/intel/lp-opt-t…
Roofline Model for DL Performance Optimizations, Sep 15 intel.com/content/www/us…
=>
"SMAUG: End-to-End Full-Stack Simulation Infrastructure for Deep Learning Workloads", Harvard, ACM TACO, Nov 2020 dl.acm.org/doi/10.1145/34…
Simulating ML Appls Using gem5-Aladdin vlsiarch.eecs.harvard.edu/research/accel…
S Xi, PhD Thesis, 2018 dash.harvard.edu/handle/1/41121…
Y Yao scholar.google.com/citations?hl=e…
"SMAUG: End-to-End Full-Stack Simulation Infrastructure for Deep Learning Workloads", Harvard, ACM TACO, Nov 2020 dl.acm.org/doi/10.1145/34…
Simulating ML Appls Using gem5-Aladdin vlsiarch.eecs.harvard.edu/research/accel…
S Xi, PhD Thesis, 2018 dash.harvard.edu/handle/1/41121…
Y Yao scholar.google.com/citations?hl=e…




=>
"Accelerating Chip Design with Machine Learning", Brucek Khailany, NVIDIA, Plenary, MLCAD 2020
MAGNet, ICCAD 2019
GRANNITE, DAC 2020 research.nvidia.com/publication/20…
ParaGraph, DAC 2020 research.nvidia.com/publication/20…
IEEE Micro, Nov/Dec 2020
"Accelerating Chip Design with Machine Learning", Brucek Khailany, NVIDIA, Plenary, MLCAD 2020
MAGNet, ICCAD 2019
https://twitter.com/ogawa_tter/status/1220568022017953793
GRANNITE, DAC 2020 research.nvidia.com/publication/20…
ParaGraph, DAC 2020 research.nvidia.com/publication/20…
IEEE Micro, Nov/Dec 2020
https://twitter.com/ogawa_tter/status/1323116937329565700




=>
"New deep learning models require fewer neurons", MIT CSAIL News, Oct 13, 2020 csail.mit.edu/news/new-deep-…
Learning from nature
"to reduce the size of the networks by two orders of magnitude"
19 neurons
nature.com/articles/s4225…
Neural Circuit Policies (NCPs) github.com/mlech26l/keras…
"New deep learning models require fewer neurons", MIT CSAIL News, Oct 13, 2020 csail.mit.edu/news/new-deep-…
Learning from nature
"to reduce the size of the networks by two orders of magnitude"
19 neurons
nature.com/articles/s4225…
Neural Circuit Policies (NCPs) github.com/mlech26l/keras…




=>
MLCAD 2020 mlcad.itec.kit.edu/index.html
Nov 17
Keynote
SoC Design Automation with ML – It's Time for Research
W. Ecker, Infineon scholar.google.com/citations?hl=e…
Plenary
From Tuning to Learning: Why the FPGA PD flow offers a compelling case for ML?
I. Bustany, Xilinx scholar.google.com/citations?hl=e…
MLCAD 2020 mlcad.itec.kit.edu/index.html
Nov 17
Keynote
SoC Design Automation with ML – It's Time for Research
W. Ecker, Infineon scholar.google.com/citations?hl=e…
Plenary
From Tuning to Learning: Why the FPGA PD flow offers a compelling case for ML?
I. Bustany, Xilinx scholar.google.com/citations?hl=e…




=>
"Guidance for Regulation of Artificial Intelligence Applications ", Memorandum, Office of Management and Budget, The White House, Nov 17, 2020, PDF whitehouse.gov/wp-content/upl…
Executive Order 13859, Feb, 11 2019
Encouraging Innovation and Growth in AI
"Guidance for Regulation of Artificial Intelligence Applications ", Memorandum, Office of Management and Budget, The White House, Nov 17, 2020, PDF whitehouse.gov/wp-content/upl…
Executive Order 13859, Feb, 11 2019
https://twitter.com/ogawa_tter/status/1161927581597237248
Encouraging Innovation and Growth in AI

=>
"Data-driven CAD or Algorithm-Driven CAD: Competitors or Collaborators?", Rajeev Jain, Qualcomm, Keynote, MLCAD 2020, Nov 18
Keynote (Infineon) & Plenary (Xilinx), Nov 17
Accelerating Chip Design with ML, NVIDIA, Plenary, Nov 16
"Data-driven CAD or Algorithm-Driven CAD: Competitors or Collaborators?", Rajeev Jain, Qualcomm, Keynote, MLCAD 2020, Nov 18
Keynote (Infineon) & Plenary (Xilinx), Nov 17
https://twitter.com/ogawa_tter/status/1328767134718066688
Accelerating Chip Design with ML, NVIDIA, Plenary, Nov 16
https://twitter.com/ogawa_tter/status/1328413046281105409




=>
"Design Challenges on post Moore's Law Era", Matthew Leung, Director, Huawei Hong Kong Research Center, Plenary, MLCAD 2020, Nov 18
Open source EDA
Keynote, Nov 18
Nov 17
Nov 16
"Design Challenges on post Moore's Law Era", Matthew Leung, Director, Huawei Hong Kong Research Center, Plenary, MLCAD 2020, Nov 18
Open source EDA
https://twitter.com/ogawa_tter/status/1317587974243057664
Keynote, Nov 18
https://twitter.com/ogawa_tter/status/1328851756315336704
Nov 17
https://twitter.com/ogawa_tter/status/1328767134718066688
Nov 16
https://twitter.com/ogawa_tter/status/1328413046281105409




=>
"MLCAD Today and Tomorrow: Learning, Optimization and Scaling", Prof. Kahng, Keynote, MLCAD 2020, Nov 16, PPTX (39 MB / 64 pp) vlsicad.ucsd.edu/NEWS20/MLCAD-K…
Keynote / Plenary, Nov 17-18
Accelerating Chip Design with ML, NVIDIA, Nov 16
"MLCAD Today and Tomorrow: Learning, Optimization and Scaling", Prof. Kahng, Keynote, MLCAD 2020, Nov 16, PPTX (39 MB / 64 pp) vlsicad.ucsd.edu/NEWS20/MLCAD-K…
Keynote / Plenary, Nov 17-18
https://twitter.com/ogawa_tter/status/1328886260530782209
Accelerating Chip Design with ML, NVIDIA, Nov 16
https://twitter.com/ogawa_tter/status/1328413046281105409




=>
@mlperf1 HPC v0.7 results, Nov 18, 2020 mlperf.org/press#mlperf-h…
MLPerf Releases Inaugural Results for Leading High-Performance ML Training Systems
mlperf.org/training-resul…
富岳: TensorFlow 2.2.0 + Mesh TensorFlow
8192/512x FUJITSU A64FX (Closed)
16384/1024x FUJITSU A64FX (Open)
@mlperf1 HPC v0.7 results, Nov 18, 2020 mlperf.org/press#mlperf-h…
MLPerf Releases Inaugural Results for Leading High-Performance ML Training Systems
mlperf.org/training-resul…
富岳: TensorFlow 2.2.0 + Mesh TensorFlow
8192/512x FUJITSU A64FX (Closed)
16384/1024x FUJITSU A64FX (Open)




=>
"Accelerating TensorFlow Performance on Mac", Nov 18, 2020 blog.tensorflow.org/2020/11/accele…
github.com/apple/tensorfl…
Native hardware acceleration is supported on Macs with M1 and Intel-based Macs through Apple's ML Compute framework.
r2.4rc0
Addons 0.11.2
M1
"Accelerating TensorFlow Performance on Mac", Nov 18, 2020 blog.tensorflow.org/2020/11/accele…
github.com/apple/tensorfl…
Native hardware acceleration is supported on Macs with M1 and Intel-based Macs through Apple's ML Compute framework.
r2.4rc0
Addons 0.11.2
M1
https://twitter.com/ogawa_tter/status/1328816423519494145
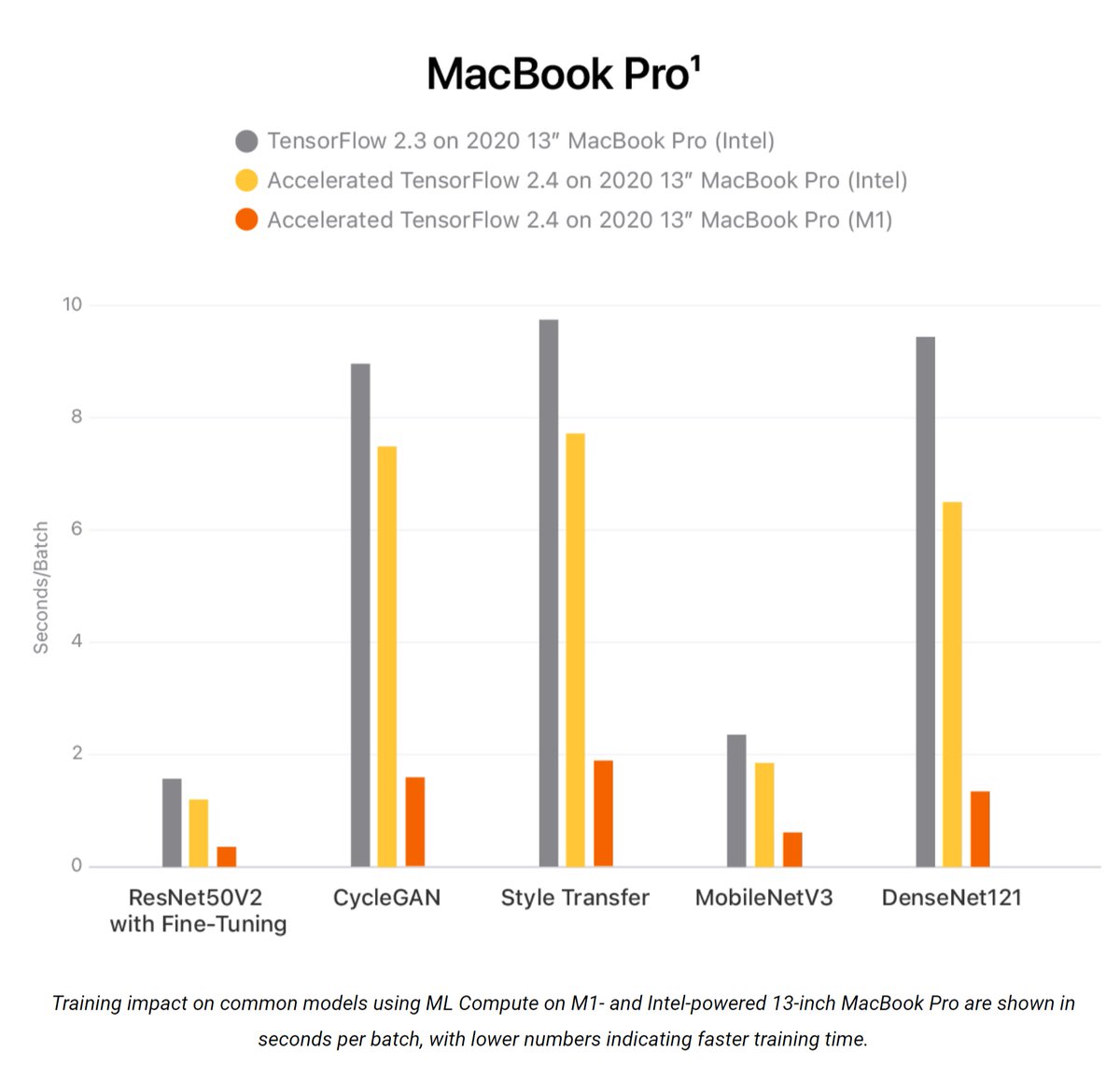
=>
"AIPerf500人工智能算力榜新鲜出炉 鹏城云脑II高居榜首"、2020年11月18日 zhuanlan.zhihu.com/p/299554605
Huawei Atlas 900
4096x Ascend910 (32GB): 1 EFLOPS (FP16)
最大構成で来たか
e.huawei.com/en/products/cl…
2019年11月29日 huawei.com/cn/news/2019/1…
"AIPerf500人工智能算力榜新鲜出炉 鹏城云脑II高居榜首"、2020年11月18日 zhuanlan.zhihu.com/p/299554605
Huawei Atlas 900
4096x Ascend910 (32GB): 1 EFLOPS (FP16)
最大構成で来たか
e.huawei.com/en/products/cl…
https://twitter.com/ogawa_tter/status/1208629077881413632
2019年11月29日 huawei.com/cn/news/2019/1…
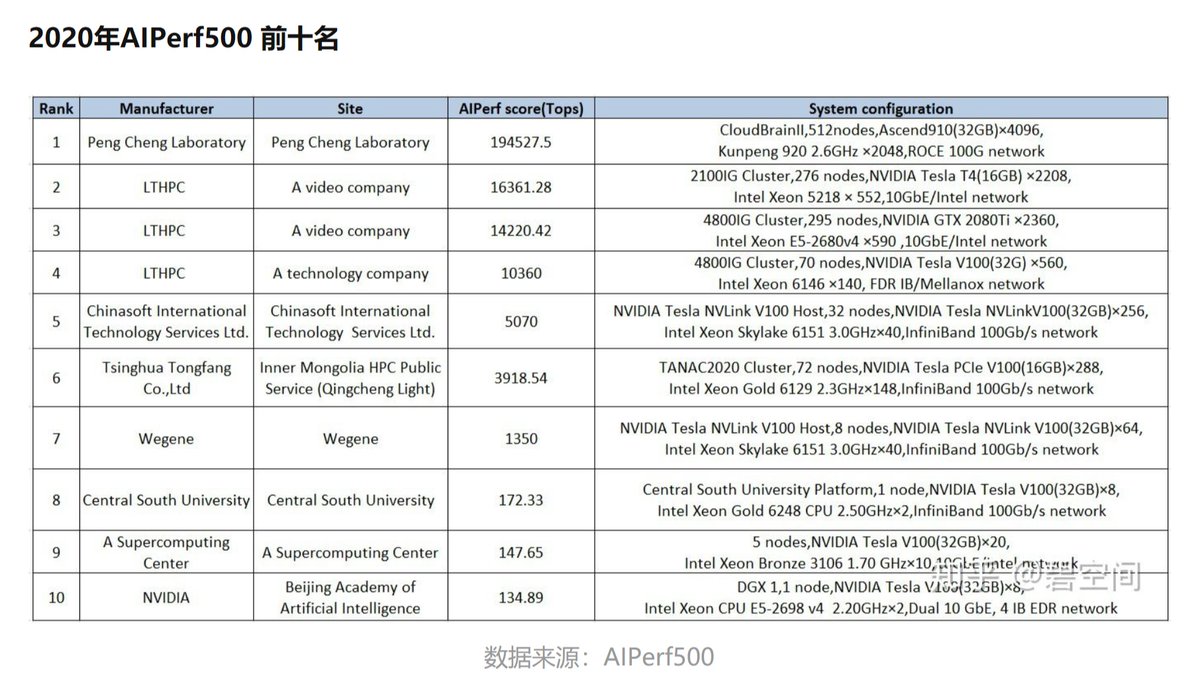



=>
2020中国高性能计算机TOP100榜单揭晓 (China HPC Top100), 2020年11月16日 (15日) news.sciencenet.cn/htmlnews/2020/…
No. 1: 神威·太湖之光, 93/ 125 PF
No. 2: 天河二号, 61/ 100 PF
No. 3: 北京超级云计算中心, 3.7/ 7.0 PF, Dell AMD EPYC7452
xueqiu.com/5983518614/163…
AIPerf500
2020中国高性能计算机TOP100榜单揭晓 (China HPC Top100), 2020年11月16日 (15日) news.sciencenet.cn/htmlnews/2020/…
No. 1: 神威·太湖之光, 93/ 125 PF
No. 2: 天河二号, 61/ 100 PF
No. 3: 北京超级云计算中心, 3.7/ 7.0 PF, Dell AMD EPYC7452
xueqiu.com/5983518614/163…
AIPerf500
https://twitter.com/ogawa_tter/status/1329236318576996354
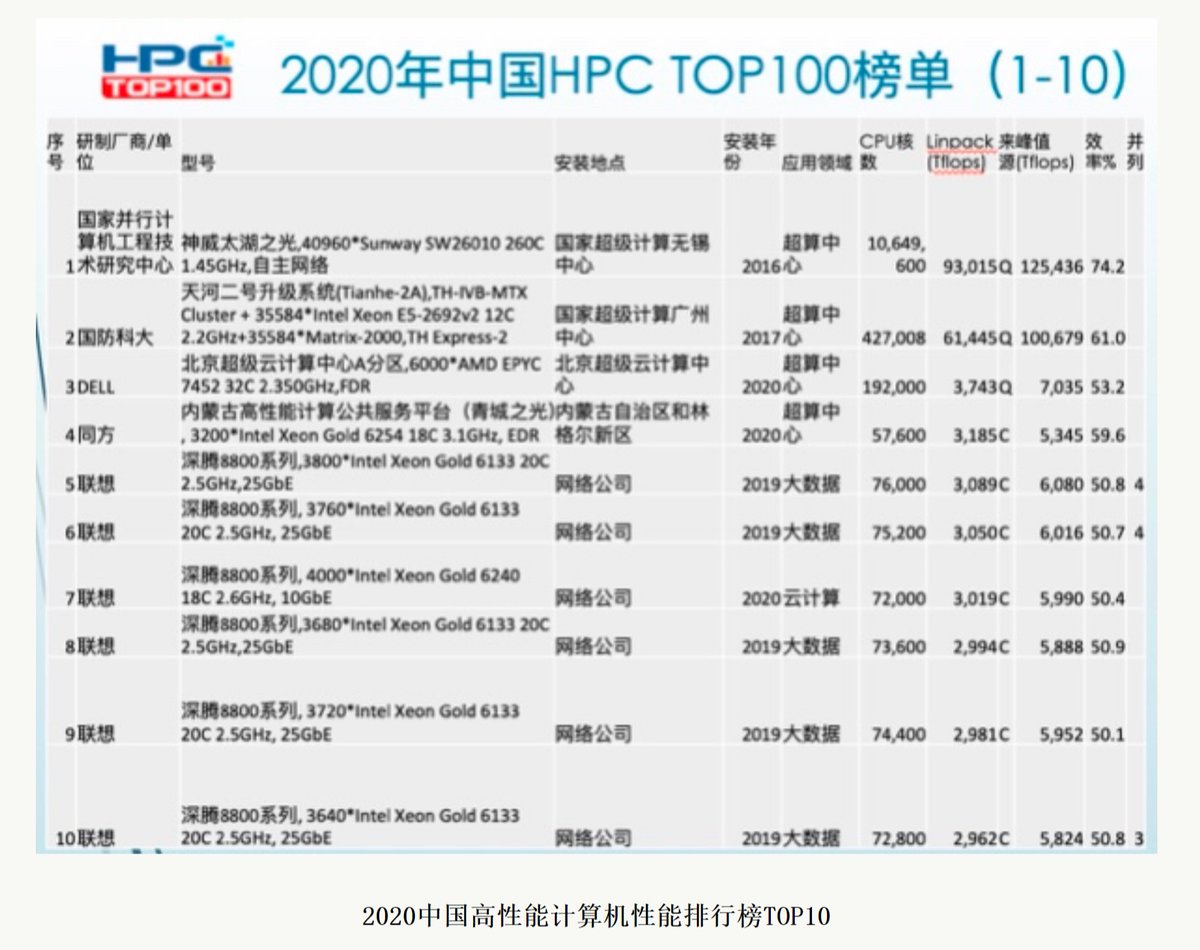



=>
鹏城实验室为国家实验室种子队 鹏城云脑Ⅱ冲刺全球IO500榜单、2020-11-17 elecfans.com/d/1383323.html
"“鹏城云脑II”获世界 #IO500 排行榜冠军"、2020-11-19 pcl.ac.cn/index.php/home…
AIPerf500
Peng Cheng Lab Ecosystem Practice, Huawei, Sep 2019 e.huawei.com/jp/material/ev…
鹏城实验室为国家实验室种子队 鹏城云脑Ⅱ冲刺全球IO500榜单、2020-11-17 elecfans.com/d/1383323.html
"“鹏城云脑II”获世界 #IO500 排行榜冠军"、2020-11-19 pcl.ac.cn/index.php/home…
AIPerf500
https://twitter.com/ogawa_tter/status/1329236318576996354
Peng Cheng Lab Ecosystem Practice, Huawei, Sep 2019 e.huawei.com/jp/material/ev…




=>
"Machine Learning in EDA: Opportunities and Challenges", Elias Fallon, Engineering Group Director, Cadence Design Systems, Keynote, MLCAD 2020, Nov 19
"Machine Learning for Future System Designs", Elias Fallon, Oct 29 nextplatform.com/2020/10/29/mac…
MLCAD 2020
"Machine Learning in EDA: Opportunities and Challenges", Elias Fallon, Engineering Group Director, Cadence Design Systems, Keynote, MLCAD 2020, Nov 19
"Machine Learning for Future System Designs", Elias Fallon, Oct 29 nextplatform.com/2020/10/29/mac…
MLCAD 2020
https://twitter.com/ogawa_tter/status/1329119608712753152

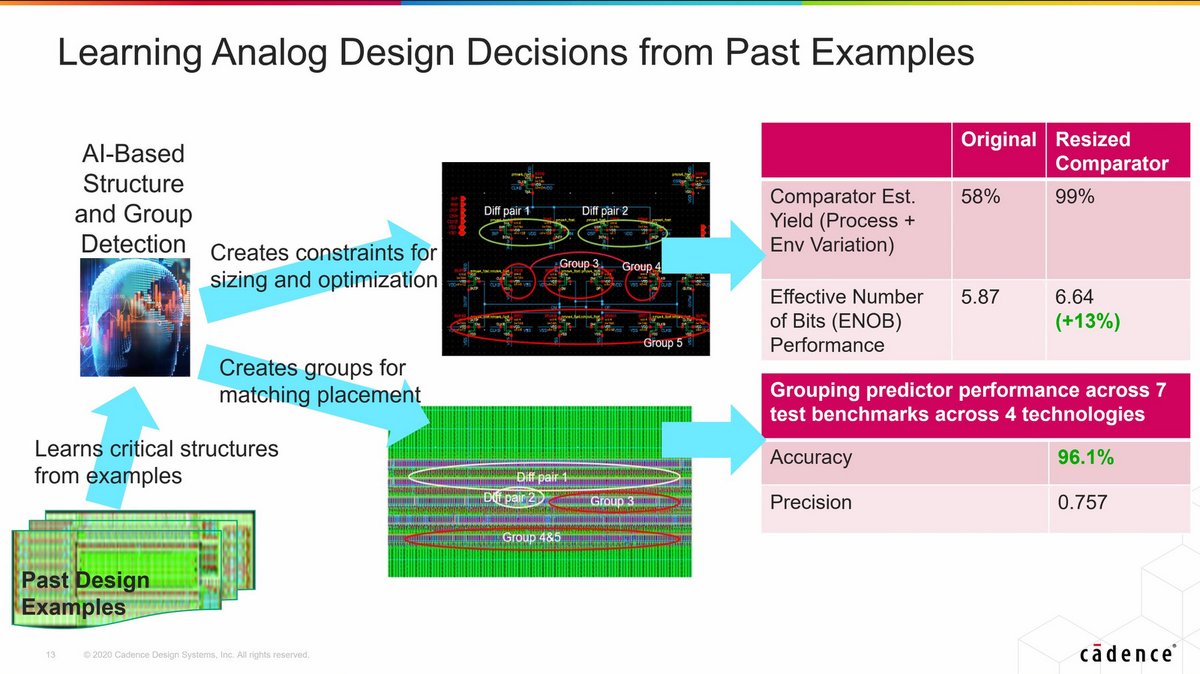
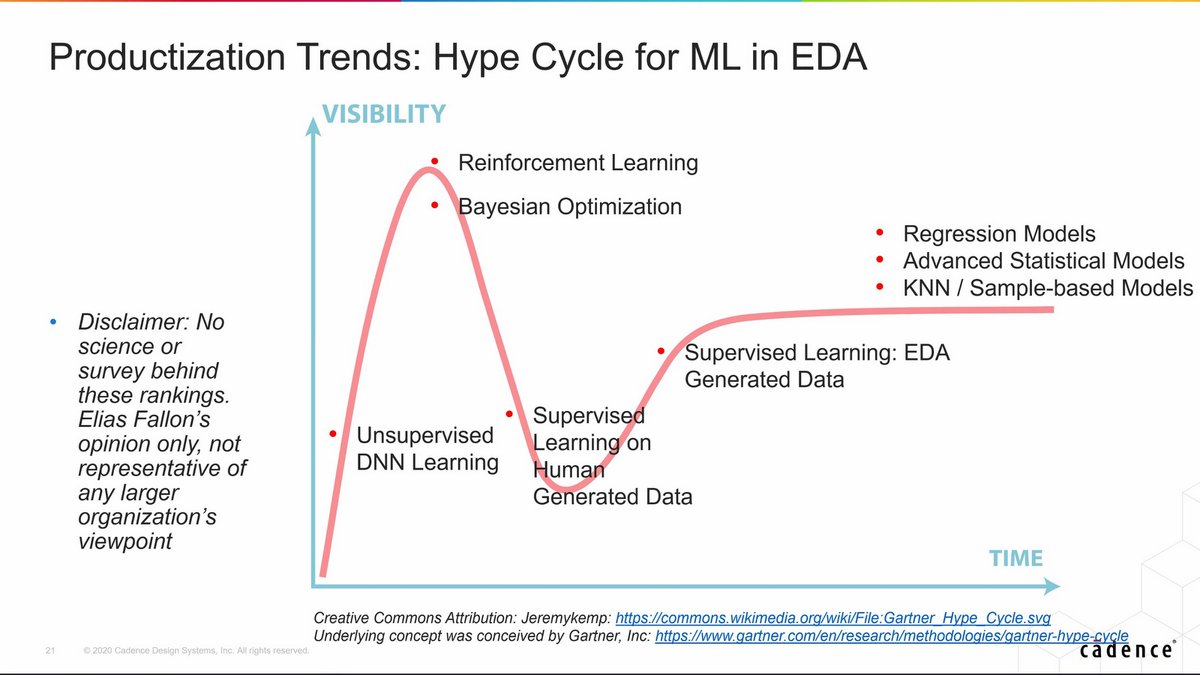
=>
"Machine-Learning Enabled Next-Generation Physical Design – An EDA Perspective", Vishal Khandelwal, Synopsys, Plenary, MLCAD 2020, Nov 19
2nd ACM/IEEE Workshop on Machine Learning for CAD (MLCAD), Nov 16-20, 2020 mlcad.itec.kit.edu
Keynote/Plenary
"Machine-Learning Enabled Next-Generation Physical Design – An EDA Perspective", Vishal Khandelwal, Synopsys, Plenary, MLCAD 2020, Nov 19
2nd ACM/IEEE Workshop on Machine Learning for CAD (MLCAD), Nov 16-20, 2020 mlcad.itec.kit.edu
Keynote/Plenary
https://twitter.com/ogawa_tter/status/1329486189259223040




=>
@MythicInc Products
M1108 Analog Matrix Processor mythic-ai.com/product/analog…
MM1108 / ME1108 M.2 mythic-ai.com/product/m-2-ca…
PCIe Evaluation Card mythic-ai.com/product/pcie-e…
Evaluation System mythic-ai.com/product/eval-s…
"The Era of Analog Compute has Arrived!", Oct 29
@MythicInc Products
M1108 Analog Matrix Processor mythic-ai.com/product/analog…
MM1108 / ME1108 M.2 mythic-ai.com/product/m-2-ca…
PCIe Evaluation Card mythic-ai.com/product/pcie-e…
Evaluation System mythic-ai.com/product/eval-s…
"The Era of Analog Compute has Arrived!", Oct 29
https://twitter.com/ogawa_tter/status/1323318169734279168




=>
@CerebrasSystems-Lambda Webinar, Nov 19 2020
Mitesh Agrawal, COO, Lambda
Andy Hock, Sr Director, Head of Product, Celebras
Purpose-built NoC
Oct 1
Oct 9
SC20
netl.doe.gov/node/10321
@CerebrasSystems-Lambda Webinar, Nov 19 2020
Mitesh Agrawal, COO, Lambda
Andy Hock, Sr Director, Head of Product, Celebras
Purpose-built NoC
https://twitter.com/ogawa_tter/status/1320358769226776577
Oct 1
https://twitter.com/ogawa_tter/status/1318167129712066561
Oct 9
https://twitter.com/ogawa_tter/status/1315732265347936257
SC20
https://twitter.com/ogawa_tter/status/1314492318129348608
netl.doe.gov/node/10321




=>
"AI for Computer Architecture Principles, Practice, and Prospects", Lizhong Chen (OSU), Drew Penney (OSU),
Daniel Jiménez (Texas A&M), Nov 2020 (2021) morganclaypoolpublishers.com/catalog_Orig/p…
D. Penney and L. Chen, AIDArc 2020
Daniel Jiménez scholar.google.com/citations?hl=e…
"AI for Computer Architecture Principles, Practice, and Prospects", Lizhong Chen (OSU), Drew Penney (OSU),
Daniel Jiménez (Texas A&M), Nov 2020 (2021) morganclaypoolpublishers.com/catalog_Orig/p…
D. Penney and L. Chen, AIDArc 2020
https://twitter.com/ogawa_tter/status/1266827317512298496
Daniel Jiménez scholar.google.com/citations?hl=e…

=>
"Recommendations for Leveraging Cloud Computing Resources for Federally Funded Artificial Intelligence Research and Development", National Science and Technology Council, Nov 17, 2020, PDF whitehouse.gov/wp-content/upl…
Executive Order, Feb 11, 2019 whitehouse.gov/presidential-a…
"Recommendations for Leveraging Cloud Computing Resources for Federally Funded Artificial Intelligence Research and Development", National Science and Technology Council, Nov 17, 2020, PDF whitehouse.gov/wp-content/upl…
Executive Order, Feb 11, 2019 whitehouse.gov/presidential-a…




=>
"High Performance Natural Language Processing", U of Washington and Google Res, Tutorial, EMNLP 2020, Nov 19
3:04:21 slideslive.com/38940826
(12.8 MB / 274 pp) gabrielilharco.com/publications/E…
U of Washington
Gabriel Ilharco gabrielilharco.com
Tim Dettmers
"High Performance Natural Language Processing", U of Washington and Google Res, Tutorial, EMNLP 2020, Nov 19
3:04:21 slideslive.com/38940826
(12.8 MB / 274 pp) gabrielilharco.com/publications/E…
U of Washington
Gabriel Ilharco gabrielilharco.com
Tim Dettmers
https://twitter.com/ogawa_tter/status/1315771074429161472




=>
"Fast, Scalable Quantized Neural Network Inference on FPGAs with FINN & LogicNets", Xilinx, Invited, H2RC 2020 (SC20) h2rc.cse.sc.edu/slides/04_Umur…
LogicNets:
Sparse + Quantized topology converts directly to LUT
Best Paper, FPL 2020
scholar.google.com/citations?user…
"Fast, Scalable Quantized Neural Network Inference on FPGAs with FINN & LogicNets", Xilinx, Invited, H2RC 2020 (SC20) h2rc.cse.sc.edu/slides/04_Umur…
LogicNets:
Sparse + Quantized topology converts directly to LUT
Best Paper, FPL 2020
https://twitter.com/maltanar/status/1301452560625213440
scholar.google.com/citations?user…



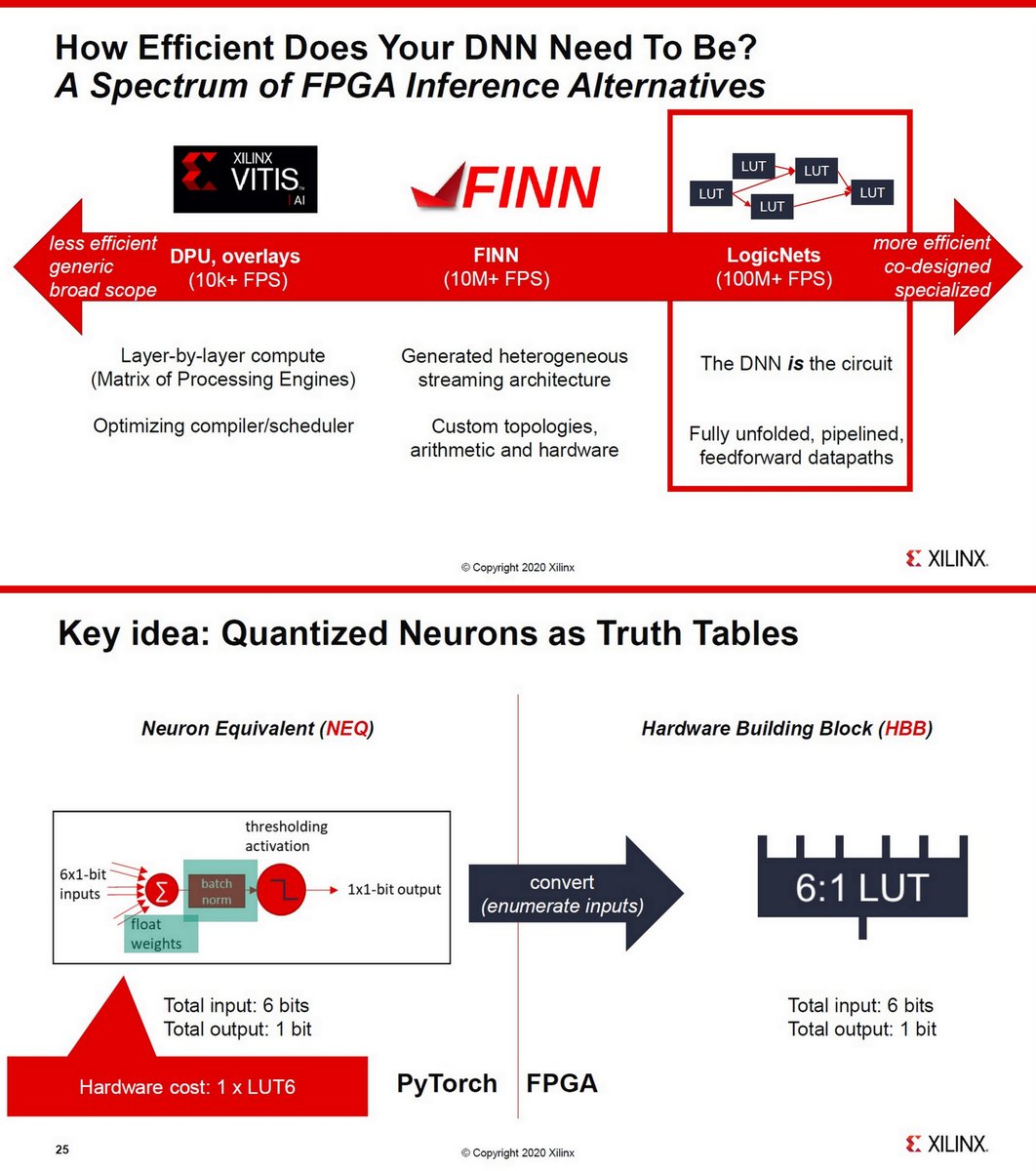
=>
Call For Participation
ISPD Benchmark Contest 2021
Wafer-Scale Physics Modeling
PDF secureservercdn.net/198.12.145.239…
Oct 29 2020 cerebras.net/ispd-2021-cont…
Team Registration: Until Jan 27, 2021
Wafer Scale Engine Placement Contest, ISPD 2020
@CerebrasSystems
Call For Participation
ISPD Benchmark Contest 2021
Wafer-Scale Physics Modeling
PDF secureservercdn.net/198.12.145.239…
Oct 29 2020 cerebras.net/ispd-2021-cont…
Team Registration: Until Jan 27, 2021
Wafer Scale Engine Placement Contest, ISPD 2020
https://twitter.com/ogawa_tter/status/1277701520167862272
@CerebrasSystems




=>
"CU POKer: Placing DNNs on Wafer-Scale AI Accelerator with Optimal Kernel Sizing", ICCAD 2020 infamousmega.github.io/archive/iccad2…
Slides infamousmega.github.io/archive/iccad2…
infamousmega.github.io
First Place Award at Contest on Wafer Scale Engine Placement Contest, ISPD 2020
"CU POKer: Placing DNNs on Wafer-Scale AI Accelerator with Optimal Kernel Sizing", ICCAD 2020 infamousmega.github.io/archive/iccad2…
Slides infamousmega.github.io/archive/iccad2…
infamousmega.github.io
First Place Award at Contest on Wafer Scale Engine Placement Contest, ISPD 2020
https://twitter.com/ogawa_tter/status/1277701520167862272

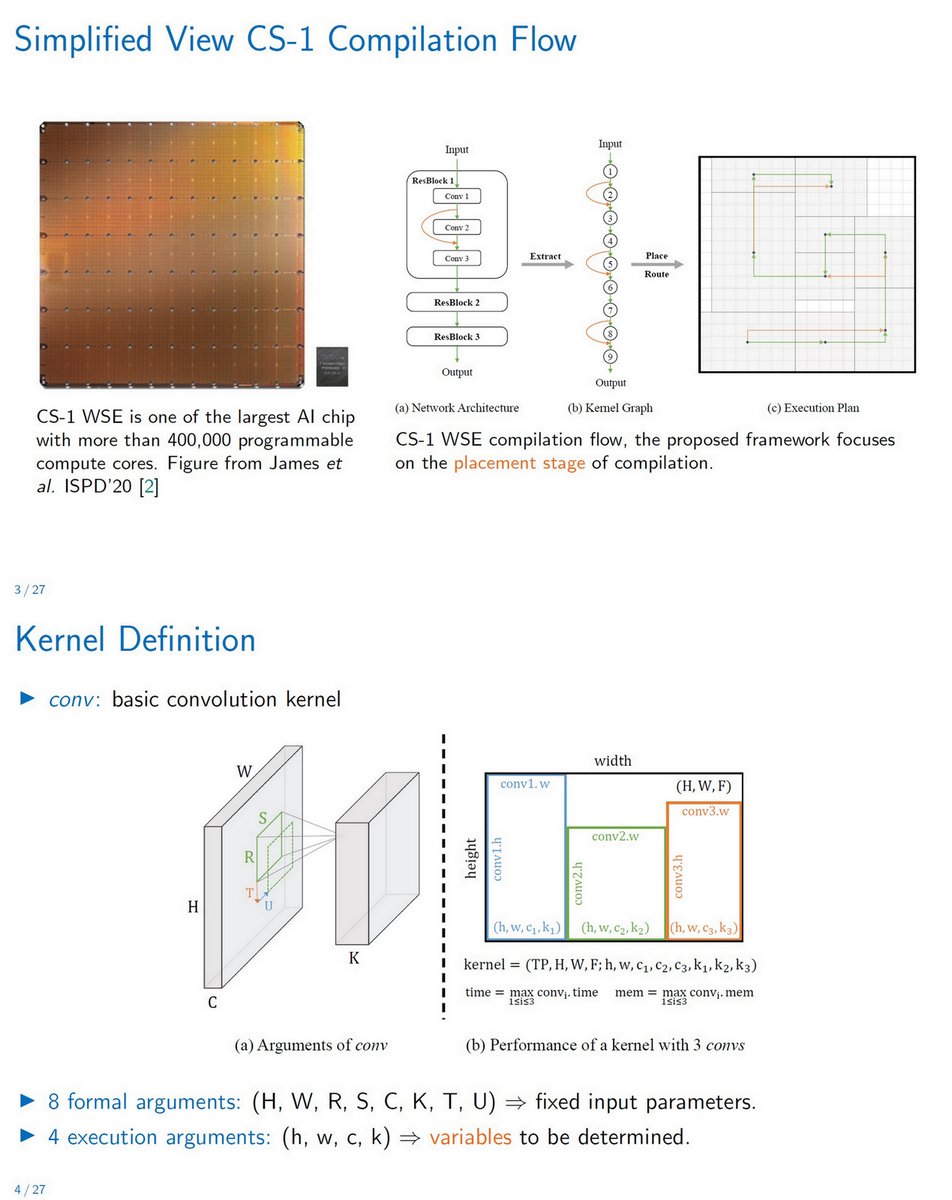


=>
"Advances and Trends in Computing Architectures for Deep Learning", M. Blott, Xilinx Res, FastML for Science WS, Nov 30, 2020 PDF indico.cern.ch/event/924283/c…
xilinx.github.io/finn/
M. Blott scholar.google.com/citations?hl=e…
H2RC 2020
LogicNets. Best Paper, FPL 2020
"Advances and Trends in Computing Architectures for Deep Learning", M. Blott, Xilinx Res, FastML for Science WS, Nov 30, 2020 PDF indico.cern.ch/event/924283/c…
xilinx.github.io/finn/
M. Blott scholar.google.com/citations?hl=e…
H2RC 2020
https://twitter.com/ogawa_tter/status/1331150017306869766
LogicNets. Best Paper, FPL 2020

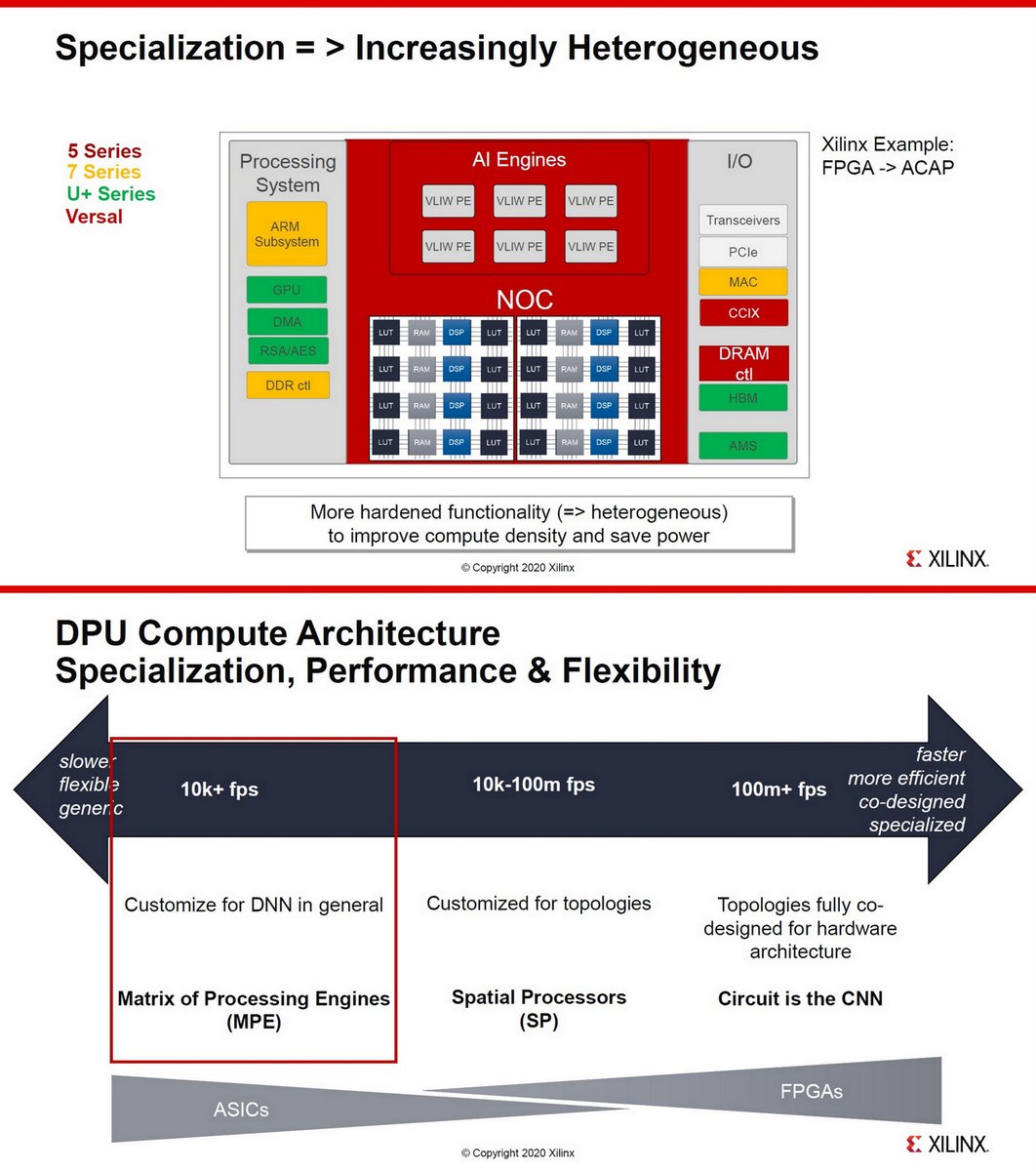
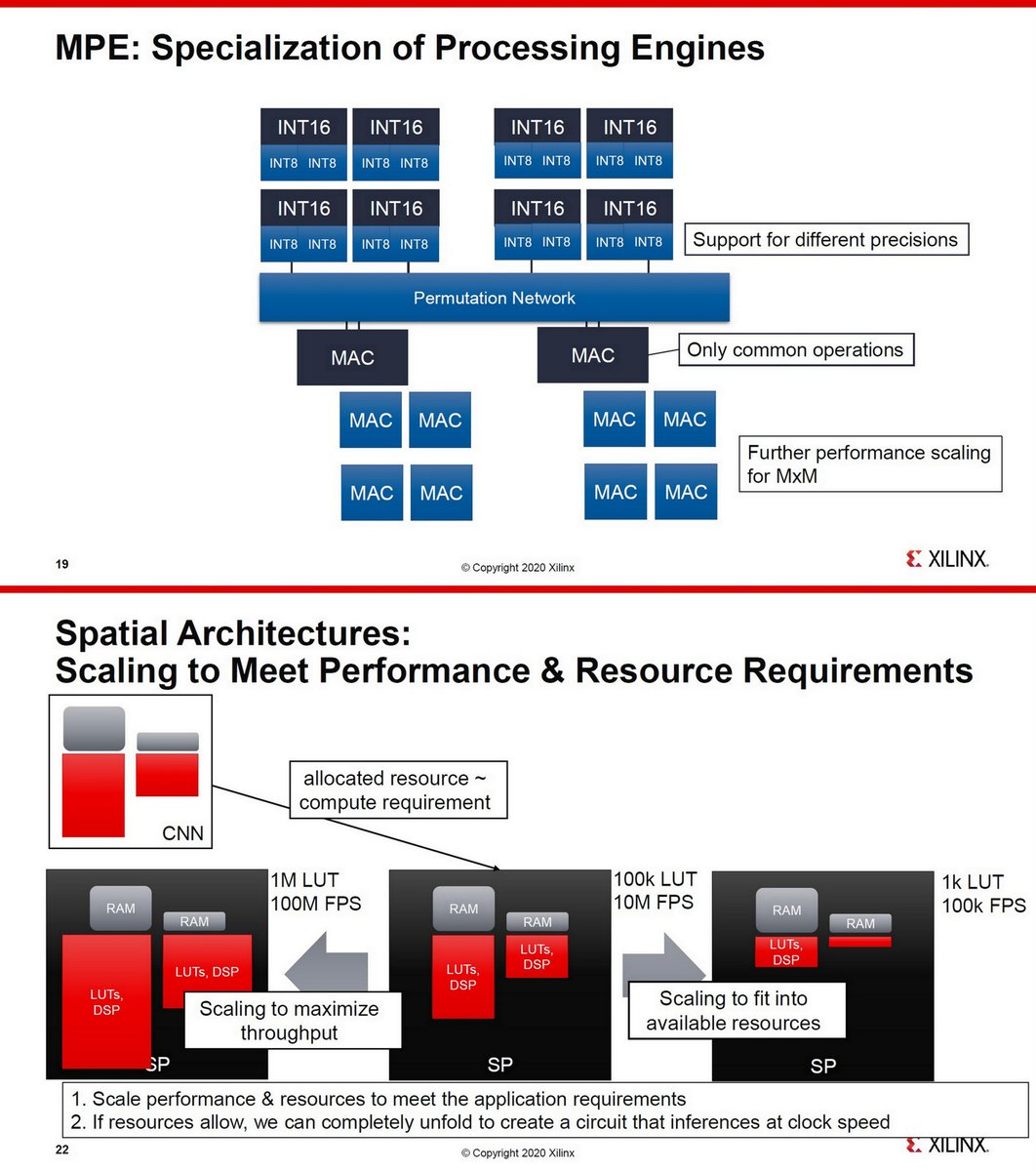
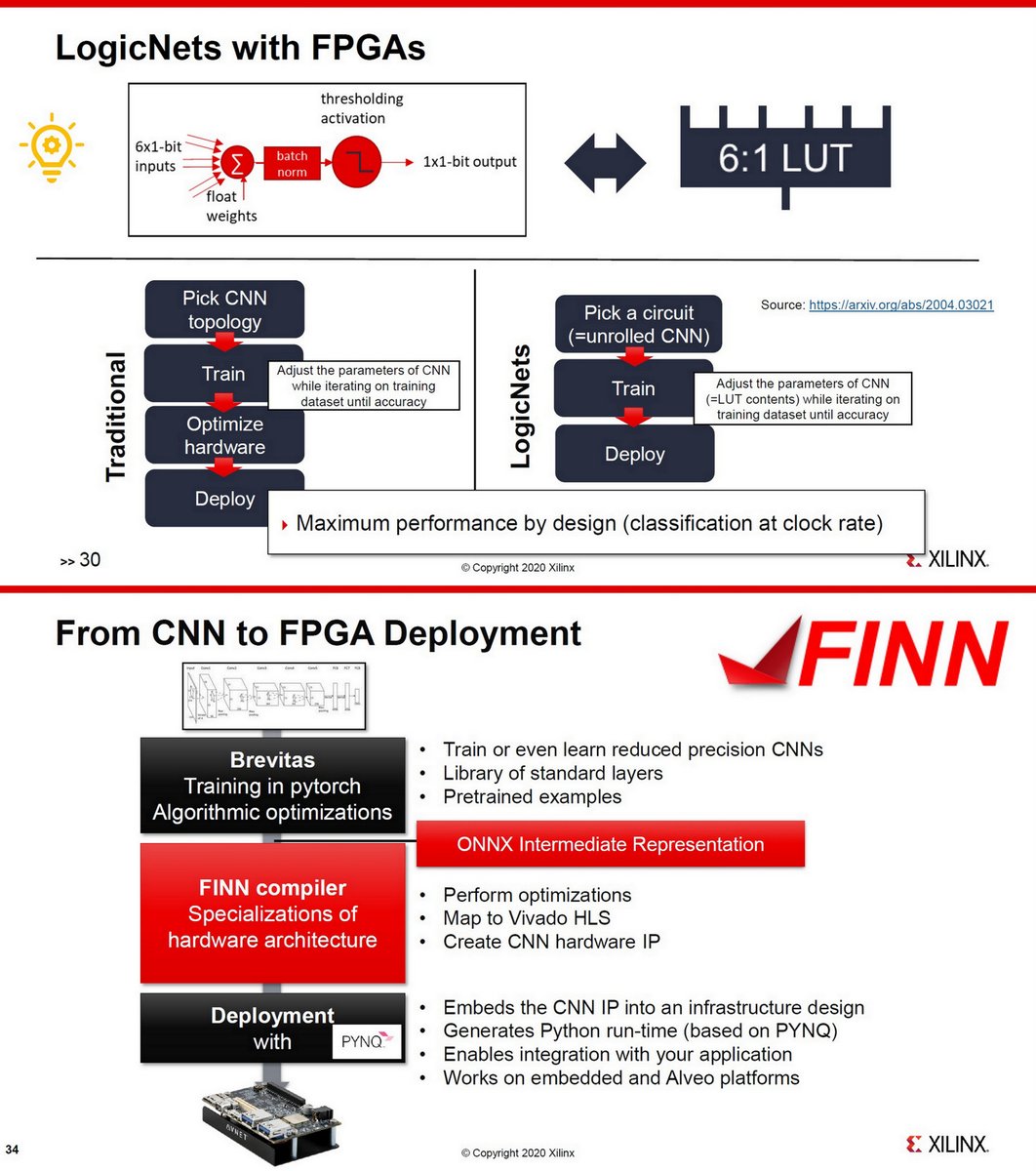
=>
Foundations of Probabilistic Programming, Nov 2020 doi.org/10.1017/978110…
What does a probabilistic program actually compute?
How can one formally reason about such probabilistic programs?
5 parts
Semantics, Verification, Logic, Security, Programming
languages
15 chap
584 pp
Foundations of Probabilistic Programming, Nov 2020 doi.org/10.1017/978110…
What does a probabilistic program actually compute?
How can one formally reason about such probabilistic programs?
5 parts
Semantics, Verification, Logic, Security, Programming
languages
15 chap
584 pp




=>
@HabanaLabs Gaudi AI Processors to bring lower cost-to-train to Amazon EC2 customers, Dec 1, 2020 habana.ai/habana-gaudi-a…
8 Gaudi
Gaudi2: Next-gen TSMC 7nm
PDF habana.ai/wp-content/upl…
Aug 2019
Dec 16, 2019
@HabanaLabs Gaudi AI Processors to bring lower cost-to-train to Amazon EC2 customers, Dec 1, 2020 habana.ai/habana-gaudi-a…
8 Gaudi
Gaudi2: Next-gen TSMC 7nm
PDF habana.ai/wp-content/upl…
Aug 2019
https://twitter.com/ogawa_tter/status/1182394387835146240
Dec 16, 2019
https://twitter.com/ogawa_tter/status/1206583083991855104



=>
AWS Trainium aws.amazon.com/jp/machine-lea…
High performance machine learning training chip, custom designed by AWS
AWS Trainium shares the same AWS Neuron SDK as AWS Inferentia
EC2 instances or Amazon SageMaker
available in 2021
AWS Trainium aws.amazon.com/jp/machine-lea…
High performance machine learning training chip, custom designed by AWS
AWS Trainium shares the same AWS Neuron SDK as AWS Inferentia
https://twitter.com/ogawa_tter/status/1327041811265699840
EC2 instances or Amazon SageMaker
available in 2021
https://twitter.com/karlfreund/status/1333845870517710848
=>
"NIST AI System Discovers New Material", Nov 24, 2020 nist.gov/news-events/ne…
CAMEO algorithm identifies new compound potentially ...
"On-the-fly closed-loop materials discovery via Bayesian active learning", Nature Comm, Nov 24 nature.com/articles/s4146…
github.com/KusneNIST/CAME…
"NIST AI System Discovers New Material", Nov 24, 2020 nist.gov/news-events/ne…
CAMEO algorithm identifies new compound potentially ...
"On-the-fly closed-loop materials discovery via Bayesian active learning", Nature Comm, Nov 24 nature.com/articles/s4146…
github.com/KusneNIST/CAME…

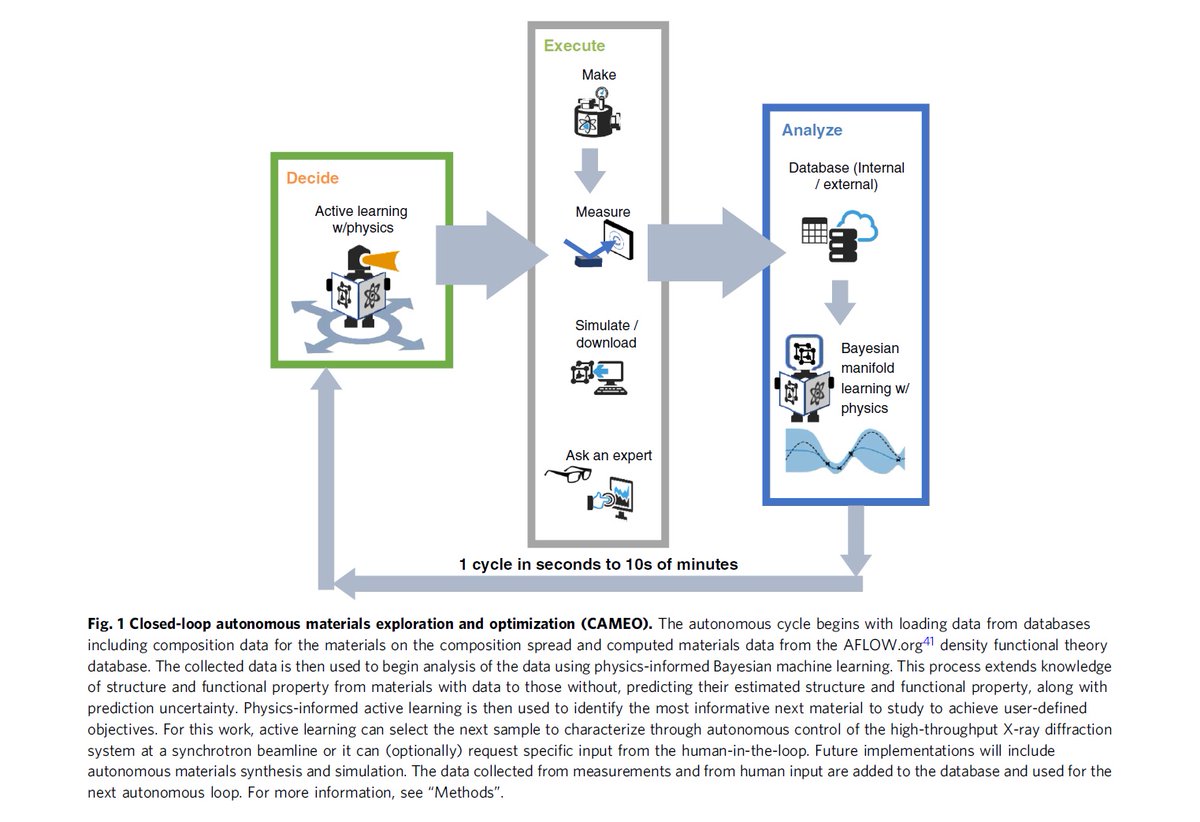


=>
"HAWQV3: Dyadic Neural Network Quantization", arXiv, Nov 20, 2020 arxiv.org/abs/2011.10680
Only integer multiplication, addition, and bit shifting in INT4/8 mixed precision
github.com/zhen-dong/hawq
HAWQ-V3, Lightning Talk in TVM Conference, Dec 2020
06:11
"HAWQV3: Dyadic Neural Network Quantization", arXiv, Nov 20, 2020 arxiv.org/abs/2011.10680
Only integer multiplication, addition, and bit shifting in INT4/8 mixed precision
github.com/zhen-dong/hawq
HAWQ-V3, Lightning Talk in TVM Conference, Dec 2020
06:11



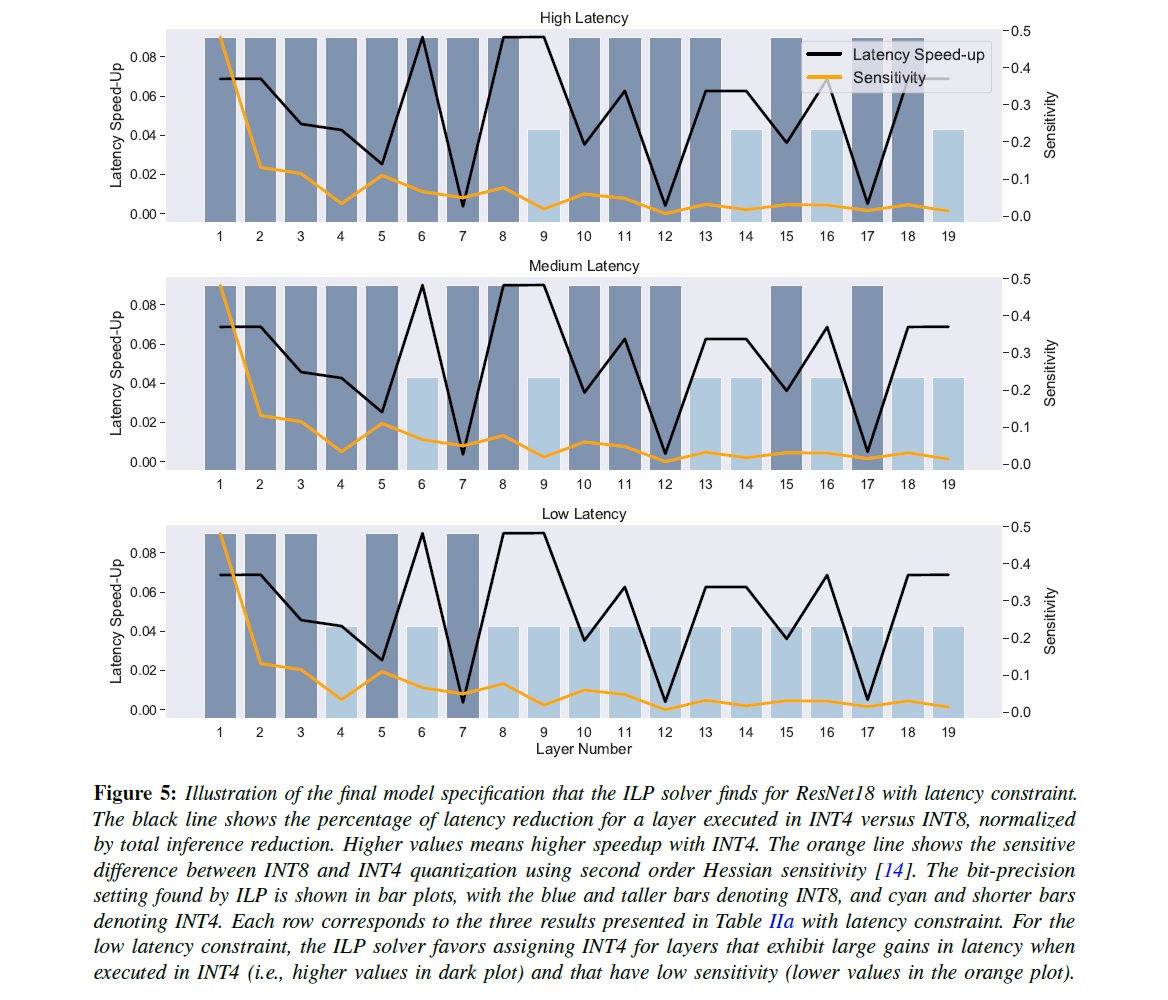
=>
"Deep Learning Acceleration of Progress in Fusion Energy Research", William Tang, PPPL, FastML for Sci WS, Dec 1, 2020, PDF indico.cern.ch/event/924283/c…
scholar.google.com/citations?hl=e…
GTC-P on TaihuLight with OpenACC, JCR&D, Apr 2018 crad.ict.ac.cn/EN/abstract/ab…
"Deep Learning Acceleration of Progress in Fusion Energy Research", William Tang, PPPL, FastML for Sci WS, Dec 1, 2020, PDF indico.cern.ch/event/924283/c…
scholar.google.com/citations?hl=e…
GTC-P on TaihuLight with OpenACC, JCR&D, Apr 2018 crad.ict.ac.cn/EN/abstract/ab…
https://twitter.com/ogawa_tter/status/1322207078006489088



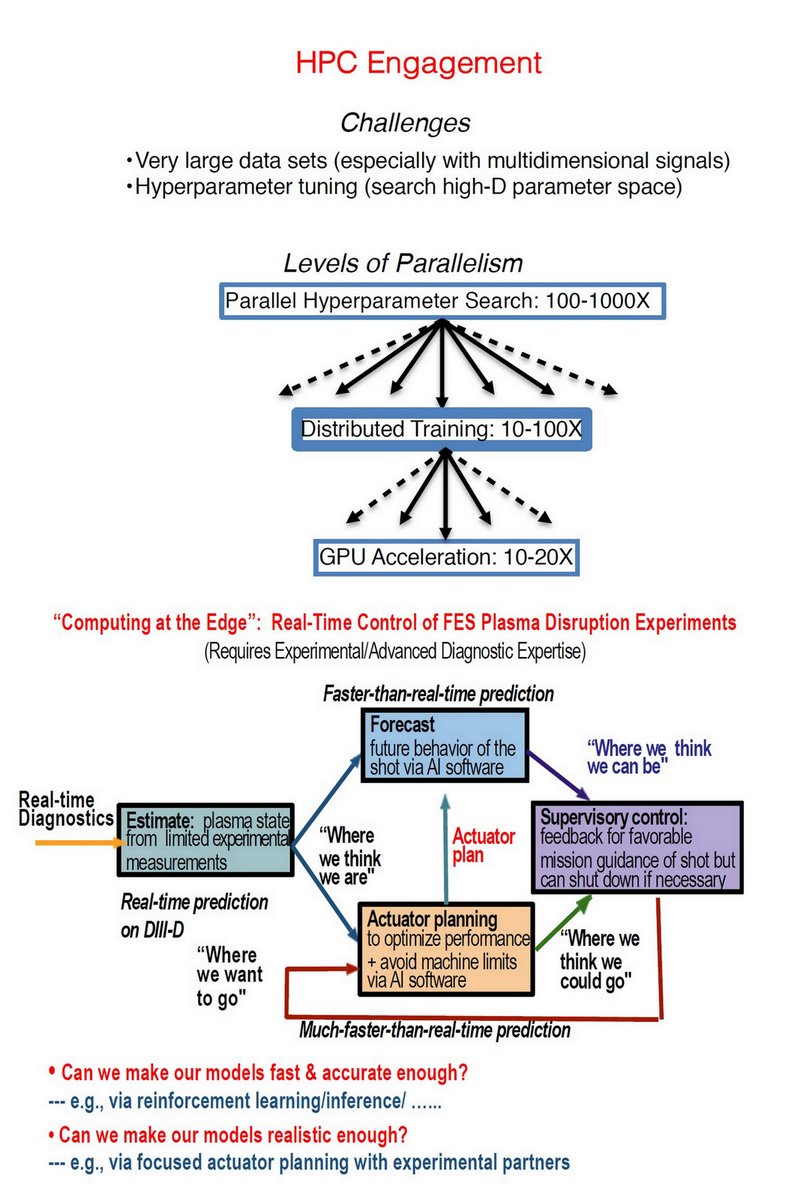
=>
Qualcomm Snapdragon Tech Summit
888 5G Mobile Platform
Dec 1, 2020 qualcomm.com/news/releases/…
Keynote
Dec 1
Dec 2
Intro qualcomm.com/media/document…
AI qualcomm.com/media/document…
Camera qualcomm.com/media/document…
Gaming qualcomm.com/media/document…
Qualcomm Snapdragon Tech Summit
888 5G Mobile Platform
Dec 1, 2020 qualcomm.com/news/releases/…
Keynote
Dec 1
Dec 2
Intro qualcomm.com/media/document…
AI qualcomm.com/media/document…
Camera qualcomm.com/media/document…
Gaming qualcomm.com/media/document…




=>
"Fast Machine Learning at the Large Hadron Collider", Jennifer Ngadiuba, Caltech, Fast ML for Science WS, Nov 30, 2020 PDF (24 MB / 36 pages) indico.cern.ch/event/924283/c…
Data reduction at the LHC
From collisions to data
The need for fast ML
J. Ngadiuba scholar.google.com/citations?hl=e…
"Fast Machine Learning at the Large Hadron Collider", Jennifer Ngadiuba, Caltech, Fast ML for Science WS, Nov 30, 2020 PDF (24 MB / 36 pages) indico.cern.ch/event/924283/c…
Data reduction at the LHC
From collisions to data
The need for fast ML
J. Ngadiuba scholar.google.com/citations?hl=e…




=>
MSFP: Microsoft custom data type, Dec 2, 2020 microsoft.com/en-us/research…
A single shared exponent
Hardening MSFP in Intel Stratix 10 NX FPGA
NeurIPS 2020 proceedings.neurips.cc/paper/2020/has…
Brainwave
Flexpoint
Achronix
MSFP: Microsoft custom data type, Dec 2, 2020 microsoft.com/en-us/research…
A single shared exponent
Hardening MSFP in Intel Stratix 10 NX FPGA
NeurIPS 2020 proceedings.neurips.cc/paper/2020/has…
Brainwave
https://twitter.com/ogawa_tter/status/1266777729963143168
Flexpoint
https://twitter.com/ogawa_tter/status/1036940525180350466
Achronix
https://twitter.com/ogawa_tter/status/1287026743174283269




=>
"Block-floating vectors and matrices", J. H Wilkinson, Rounding Errors in Algebraic Processes, 1963 books.google.co.jp/books?id=yFogU…
Block FP on TMS320C54x DSP, Dec 1999 ti.com/lit/an/spra610…
IEEE VLSI Aug 2019 xiangyangji.com/uploadfile/upl…
5-b shared exp & 8-b
MSFP
"Block-floating vectors and matrices", J. H Wilkinson, Rounding Errors in Algebraic Processes, 1963 books.google.co.jp/books?id=yFogU…
Block FP on TMS320C54x DSP, Dec 1999 ti.com/lit/an/spra610…
IEEE VLSI Aug 2019 xiangyangji.com/uploadfile/upl…
5-b shared exp & 8-b
MSFP
https://twitter.com/ogawa_tter/status/1334747224169836547




=>
James H. Wilkinson en.wikipedia.org/wiki/James_H._…
1970 ACM Turing award amturing.acm.org/award_winners/…
Numerical analysis to facilitiate the use of the high-speed digital computer, having received special recognition for his work in computations in linear algebra ...
James H. Wilkinson en.wikipedia.org/wiki/James_H._…
1970 ACM Turing award amturing.acm.org/award_winners/…
Numerical analysis to facilitiate the use of the high-speed digital computer, having received special recognition for his work in computations in linear algebra ...
https://twitter.com/ogawa_tter/status/1335202520604397569
• • •
Missing some Tweet in this thread? You can try to
force a refresh