=>
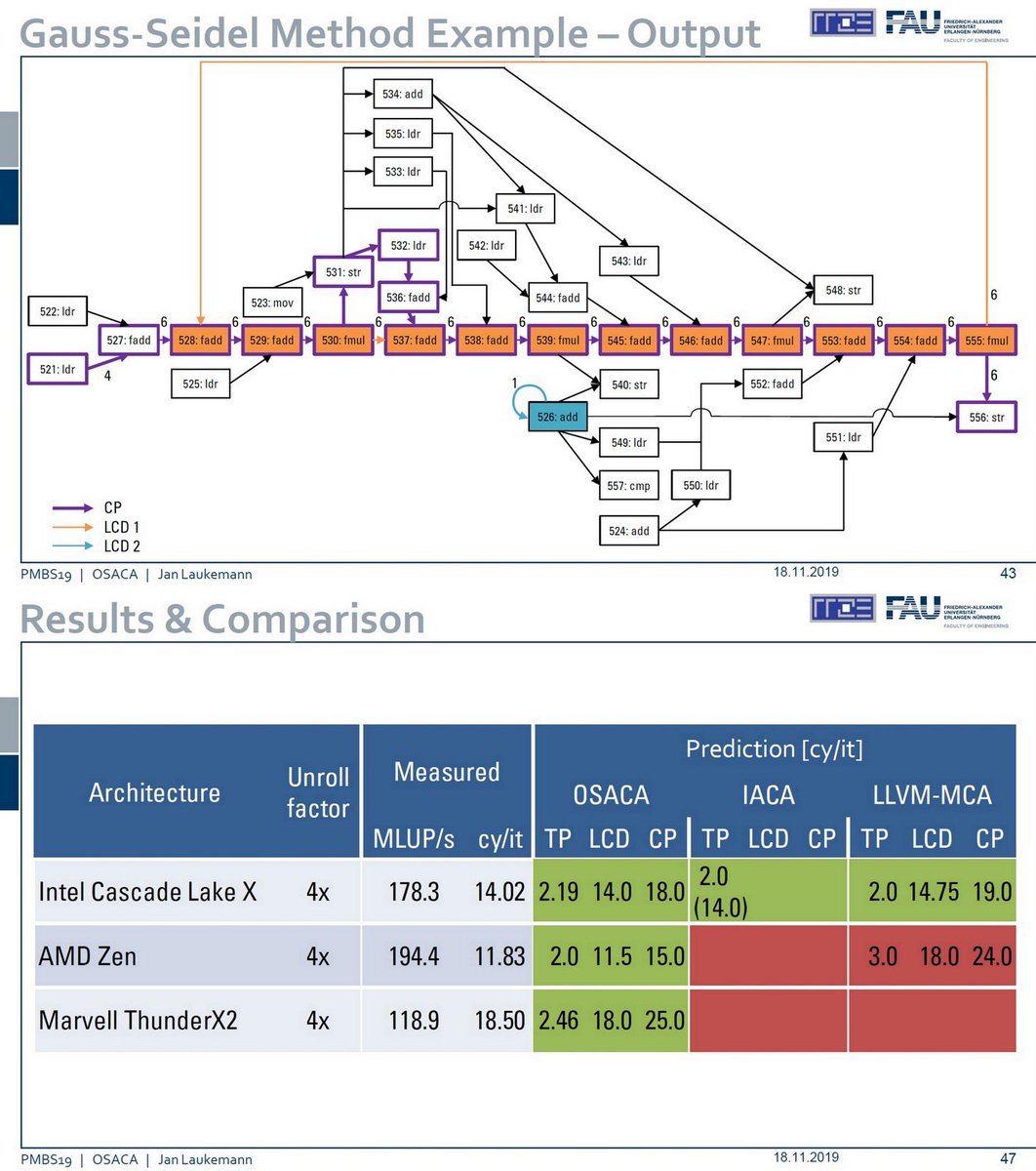
"Automatic Throughput and Critical Path Analysis of x86 and ARM Assembly Kernels", PMBS 2019 conferences.computer.org/sc19w/2019/pdf…
Slides dcs.warwick.ac.uk/pmbs/pmbs19/PM…
Open Source Architecture Code Analyzer github.com/RRZE-HPC/OSACA
x86 and ARM
Best Late-Breaking Paper Award blogs.fau.de/hager/archives…
"Automatic Throughput and Critical Path Analysis of x86 and ARM Assembly Kernels", PMBS 2019 conferences.computer.org/sc19w/2019/pdf…
Slides dcs.warwick.ac.uk/pmbs/pmbs19/PM…
Open Source Architecture Code Analyzer github.com/RRZE-HPC/OSACA
x86 and ARM
Best Late-Breaking Paper Award blogs.fau.de/hager/archives…



=>
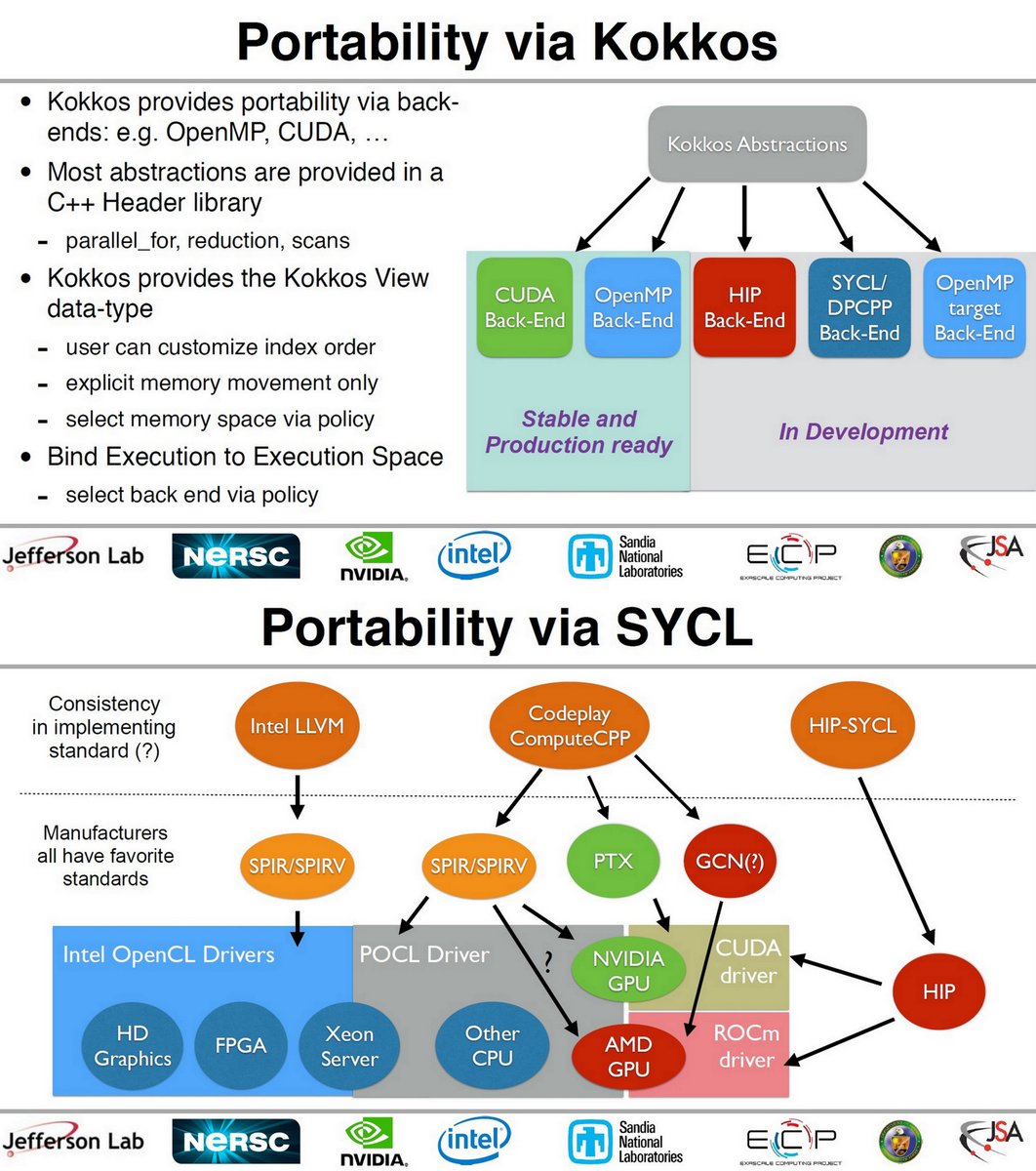
"Performance Portability of a Wilson Dslash Stencil Operator Mini-App Using Kokkos and SYCL", Jefferson Lab, NVIDIA, Intel, Sandia, NERSC, P3HPC 2019
PDF conferences.computer.org/sc19w/2019/pdf…
Slides drive.google.com/file/d/1rBIzzd…
V100, K80
Skylake
KNL
Intel Gen9 GPU
oneAPI
"Performance Portability of a Wilson Dslash Stencil Operator Mini-App Using Kokkos and SYCL", Jefferson Lab, NVIDIA, Intel, Sandia, NERSC, P3HPC 2019
PDF conferences.computer.org/sc19w/2019/pdf…
Slides drive.google.com/file/d/1rBIzzd…
V100, K80
Skylake
KNL
Intel Gen9 GPU
oneAPI



=>
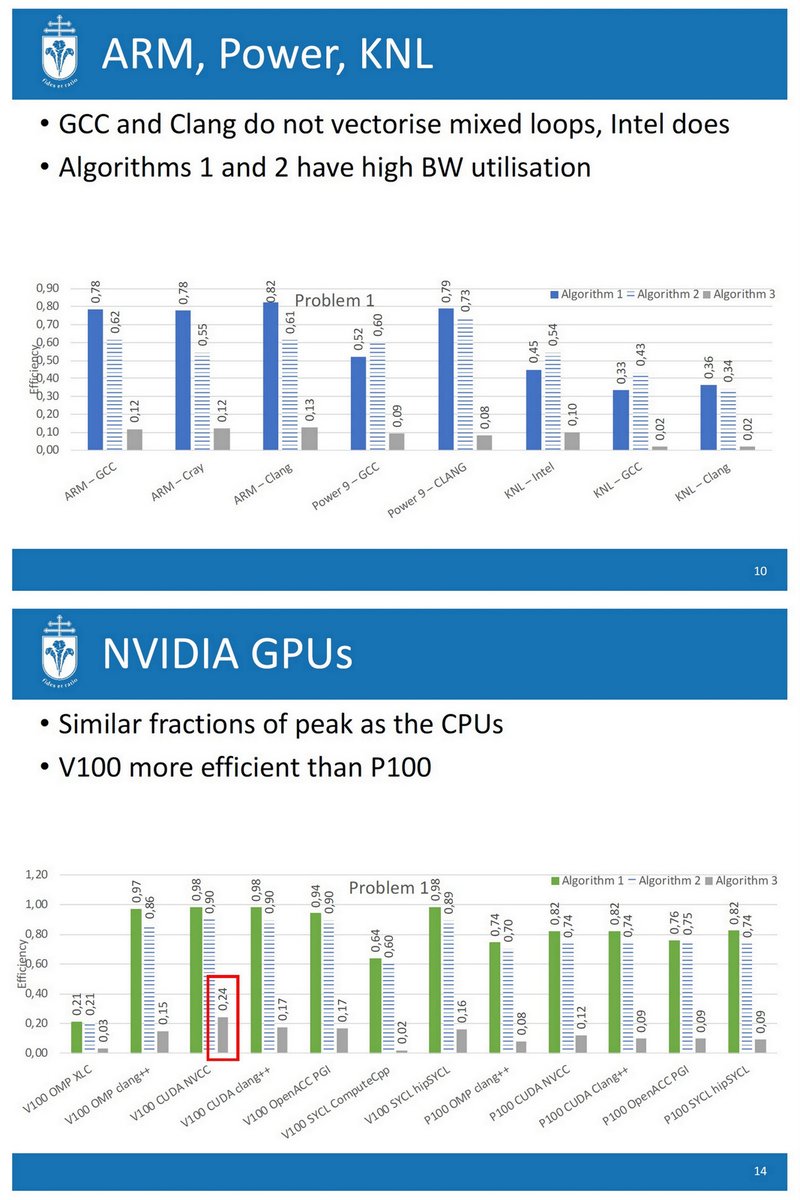
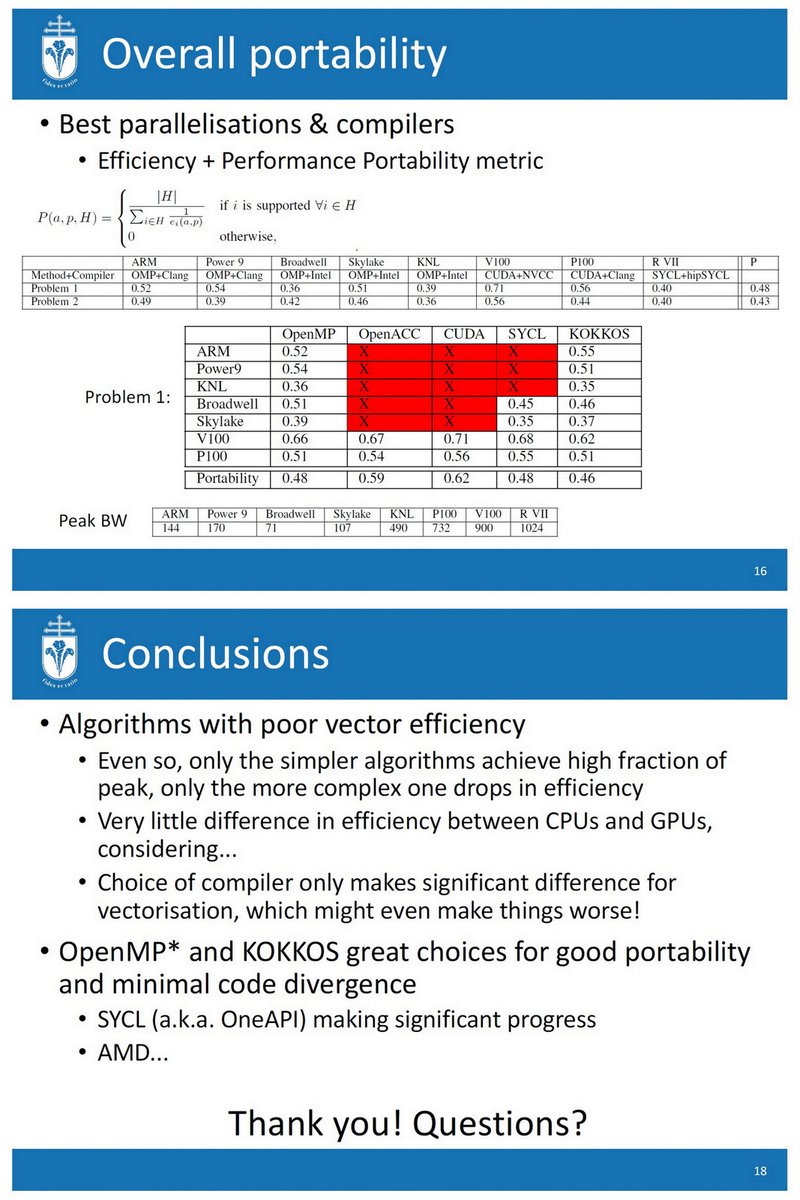
"Performance Portability of Multi-Material Kernels", P3HPC 2019
conferences.computer.org/sc19w/2019/pdf…
Slides drive.google.com/file/d/12asEc4…
OpenMP, OpenACC, CUDA, SYCL, KOKKOS,
ThunderX2
POWER9
Broadwell, Skylake, KNL
P100, V100
(Radeon VII)
scholar.google.co.uk/citations?hl=e…
oneAPI
"Performance Portability of Multi-Material Kernels", P3HPC 2019
conferences.computer.org/sc19w/2019/pdf…
Slides drive.google.com/file/d/12asEc4…
OpenMP, OpenACC, CUDA, SYCL, KOKKOS,
ThunderX2
POWER9
Broadwell, Skylake, KNL
P100, V100
(Radeon VII)
scholar.google.co.uk/citations?hl=e…
oneAPI


=>
Intel oneAPI
Raja Koduri (+ Xe) Nov 17, 2019
Performance Portability, P3HPC 2019
Codeplay, SC19: supporting SYCL, Data Parallel C++ & oneAPI on NVIDIA GPUs
Intel oneAPI
Raja Koduri (+ Xe) Nov 17, 2019
Performance Portability, P3HPC 2019
Codeplay, SC19: supporting SYCL, Data Parallel C++ & oneAPI on NVIDIA GPUs
=>
"Performance Portability Across Diverse Computer Architectures", University of Bristol, P3HPC 2019
Paper sc19.supercomputing.org/proceedings/wo…
Slides drive.google.com/file/d/1VcF5YB…
@simonmcs , Opening Keynote, DoE PPP, Apr 2, 2019 drive.google.com/file/d/127YwGA…
HPC - U of Bristol uob-hpc.github.io
"Performance Portability Across Diverse Computer Architectures", University of Bristol, P3HPC 2019
Paper sc19.supercomputing.org/proceedings/wo…
Slides drive.google.com/file/d/1VcF5YB…
@simonmcs , Opening Keynote, DoE PPP, Apr 2, 2019 drive.google.com/file/d/127YwGA…
HPC - U of Bristol uob-hpc.github.io




=>
*) Loop back ...
*) Loop back ...
=>
On Demand, Dec 2019
Introducing oneAPI: A Single Programming Model to Deliver Cross Architecture Performance techdecoded.intel.io/essentials/int…
PDF simplecore-ger.intel.com/techdecoded/wp…
Introducing Data Parallel C++ (DPC++ Part 1) techdecoded.intel.io/essentials/dpc…
simplecore-ger.intel.com/techdecoded/wp…
On Demand, Dec 2019
Introducing oneAPI: A Single Programming Model to Deliver Cross Architecture Performance techdecoded.intel.io/essentials/int…
PDF simplecore-ger.intel.com/techdecoded/wp…
Introducing Data Parallel C++ (DPC++ Part 1) techdecoded.intel.io/essentials/dpc…
simplecore-ger.intel.com/techdecoded/wp…




=>
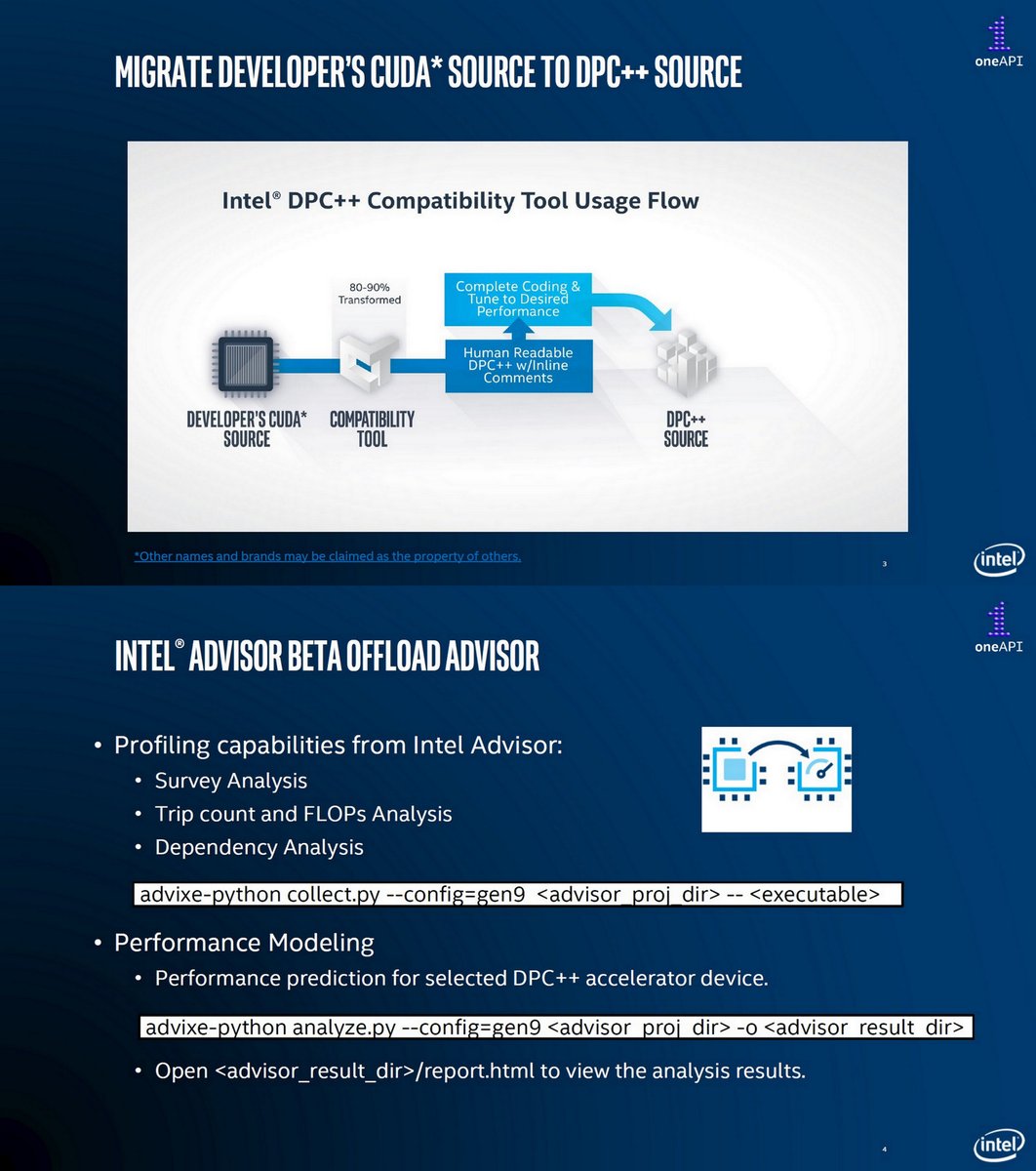
Intel DPC++ Compatibility tool (Beta)
Minimizes code migration time
Assists developers migrating code written in CUDA to DPC++ once, generating human readable code wherever possible
~80 - 90% of code migrates automatically
Introducing oneAPI, Dec 2019
Intel DPC++ Compatibility tool (Beta)
Minimizes code migration time
Assists developers migrating code written in CUDA to DPC++ once, generating human readable code wherever possible
~80 - 90% of code migrates automatically
Introducing oneAPI, Dec 2019
=>
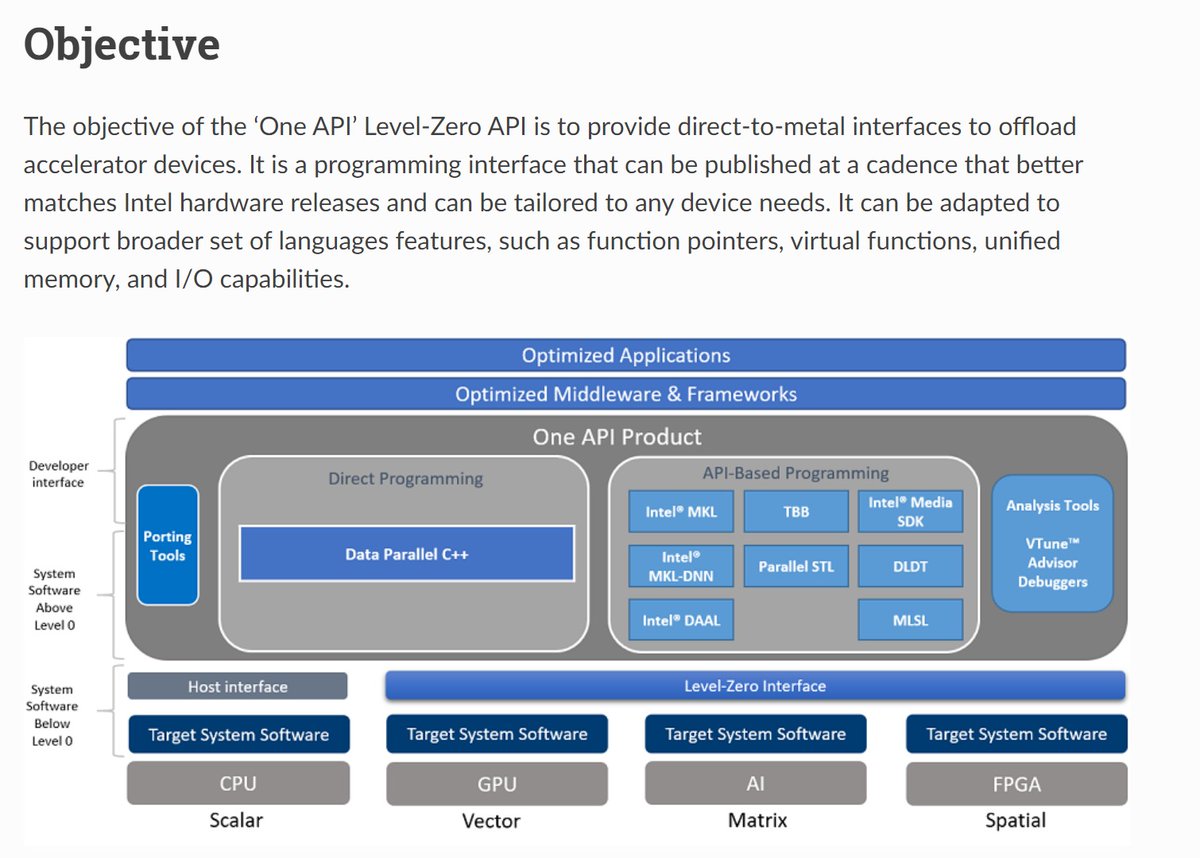
oneAPI Level 0 Specification spec.oneapi.com/oneL0/
Objective spec.oneapi.com/oneL0/core_INT…
Level-Zero API is to provide direct-to-metal interfaces to offload accelerator devices.
GPU, Accelerator, FPGA
oneAPI, Ondemand Webinars, Dec 2019
oneAPI Level 0 Specification spec.oneapi.com/oneL0/
Objective spec.oneapi.com/oneL0/core_INT…
Level-Zero API is to provide direct-to-metal interfaces to offload accelerator devices.
GPU, Accelerator, FPGA
oneAPI, Ondemand Webinars, Dec 2019


=>
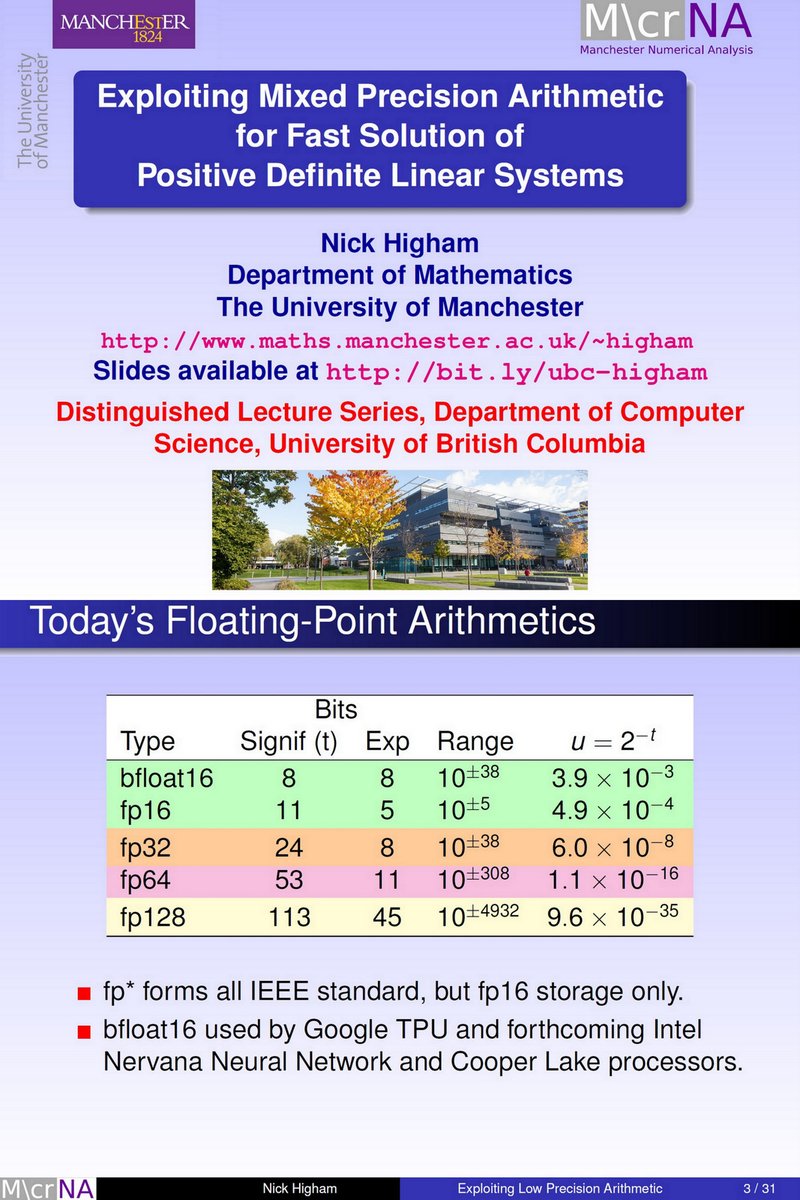
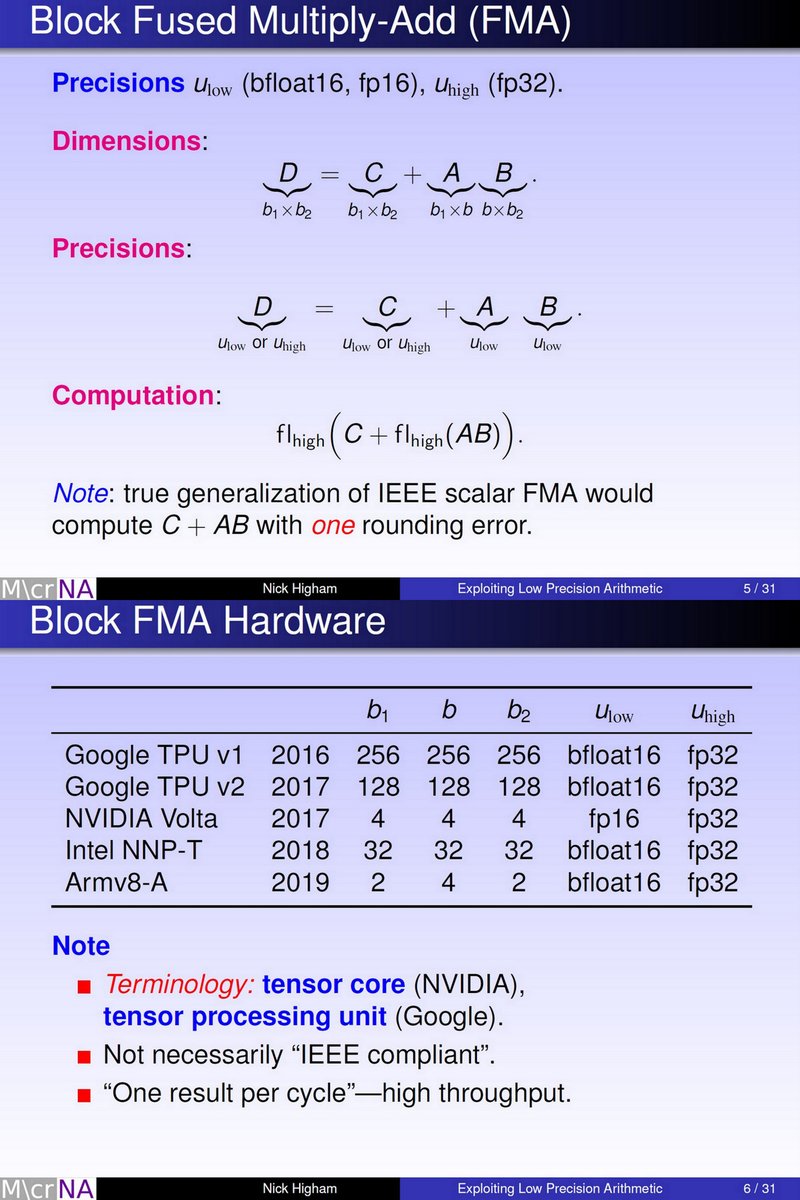
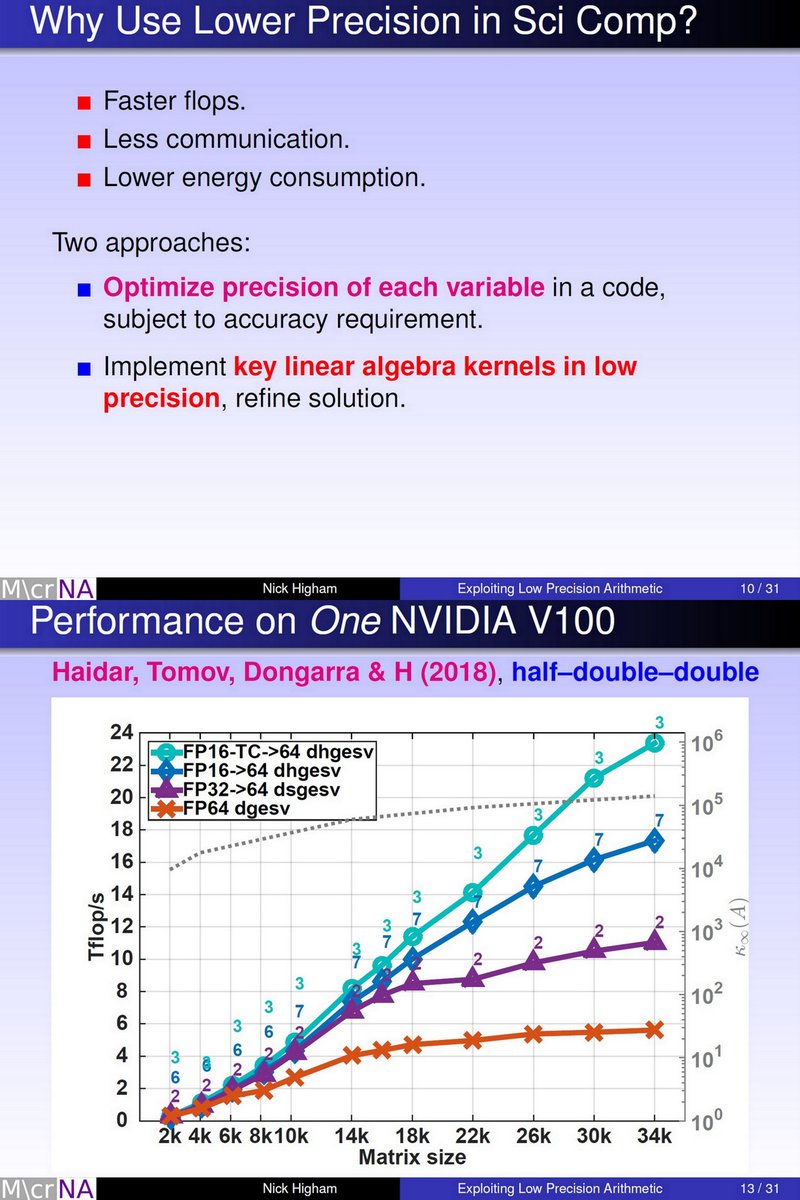
"Exploiting Mixed Precision Arithmetic for Fast Solution of Positive Definite Linear Systems", Nicholas Higham, Manchester, UBC Distinguished Lectur, Dec 5 2019 youtube.com/watch?v=wLr62q…
dropbox.com/s/mt004qqa7qut…
bf16, Intel
TPUv2/v3
"Exploiting Mixed Precision Arithmetic for Fast Solution of Positive Definite Linear Systems", Nicholas Higham, Manchester, UBC Distinguished Lectur, Dec 5 2019 youtube.com/watch?v=wLr62q…
dropbox.com/s/mt004qqa7qut…
bf16, Intel
TPUv2/v3

=>
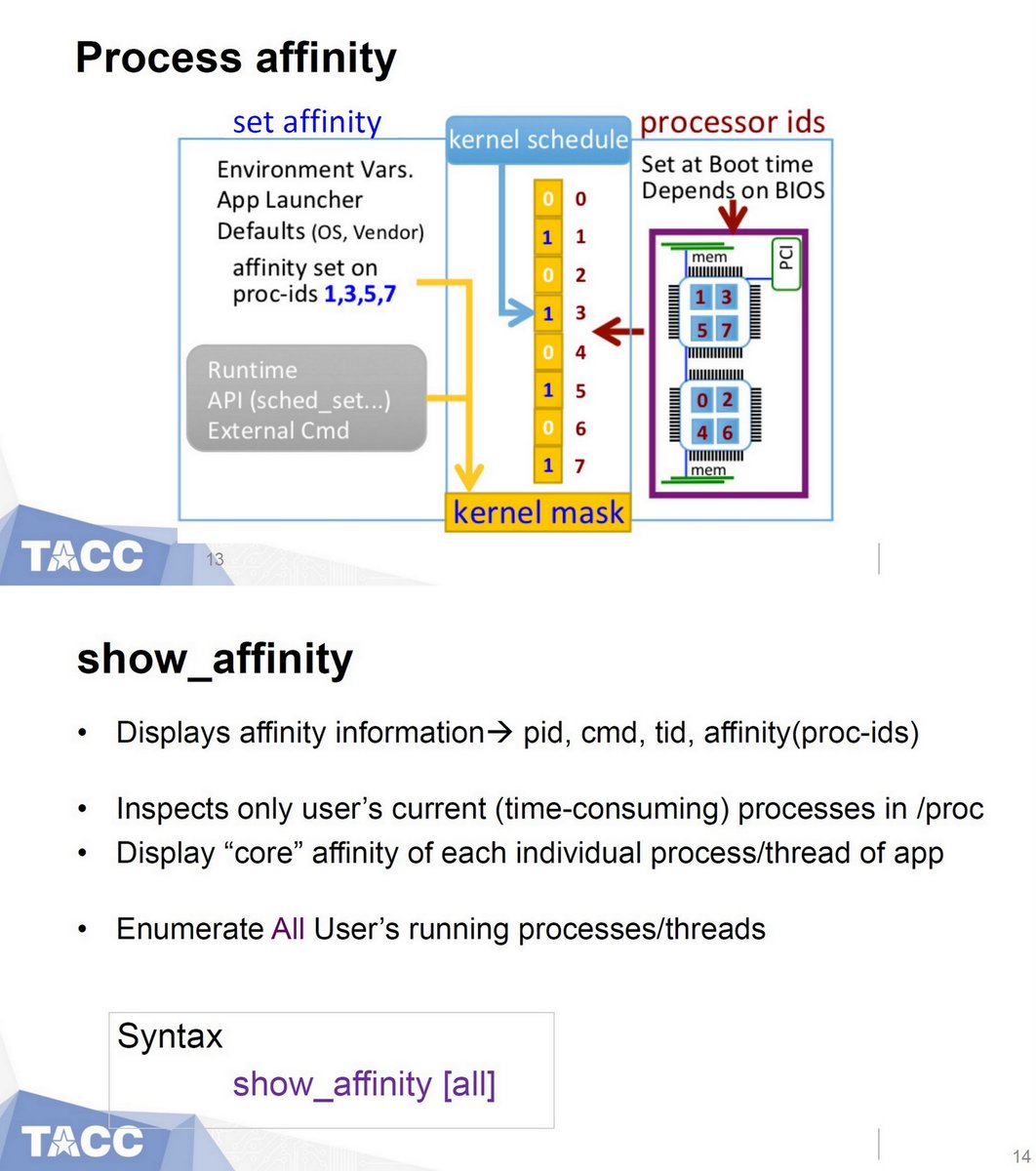
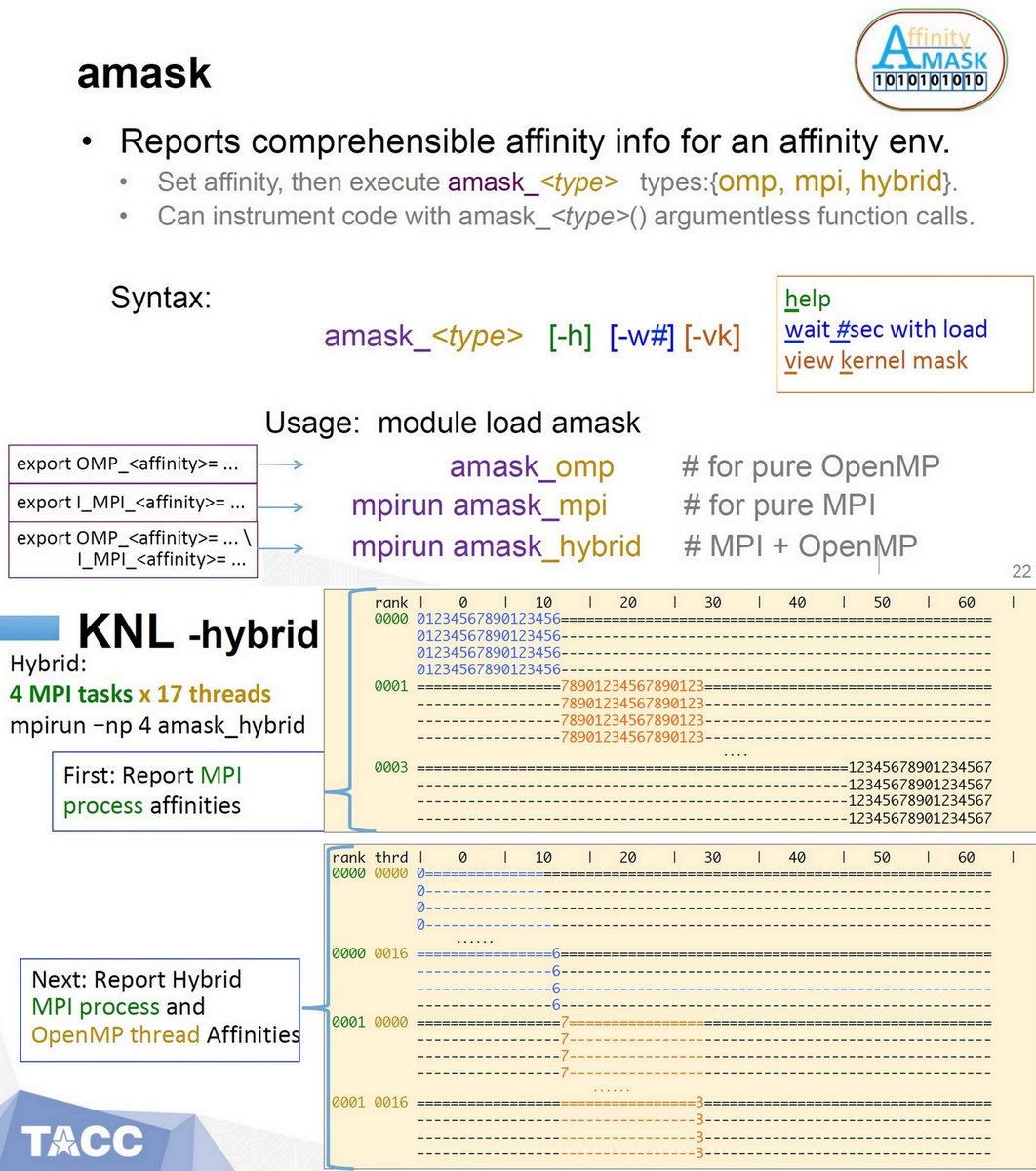
"Tools for Monitoring CPU Usage and Affinity in Multicore Supercomputers", TACC, HUST 2019 (SC19)
PDF sc19.supercomputing.org/proceedings/wo…
Slides hust-workshop.github.io/2019_presentat…
core_usage github.com/TACC/core_usage
show_affinity github.com/TACC/show_affi…
amask github.com/tacc/amask
"Tools for Monitoring CPU Usage and Affinity in Multicore Supercomputers", TACC, HUST 2019 (SC19)
PDF sc19.supercomputing.org/proceedings/wo…
Slides hust-workshop.github.io/2019_presentat…
core_usage github.com/TACC/core_usage
show_affinity github.com/TACC/show_affi…
amask github.com/tacc/amask


=>
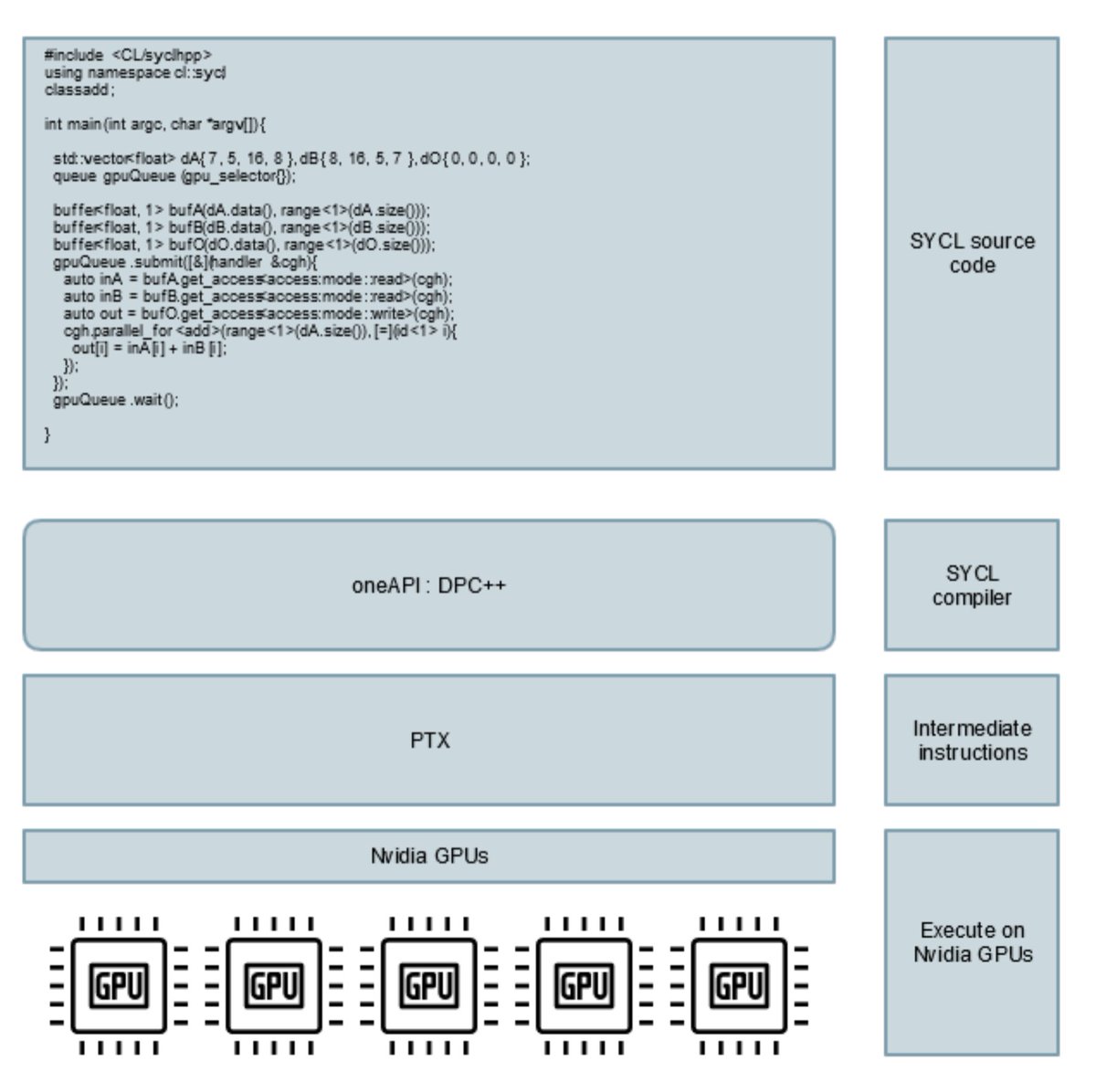
"Bringing NVIDIA GPU support to SYCL developers", Dec 16, 2019 codeplay.com/portal/12-16-1…
"experimental" support for NVIDIA with ComputeCpp using CUDA
=> In 2020, Codeplay will be releasing a fully open source project supporting for NVIDIA devices to SYCL developers
with oneAPI
"Bringing NVIDIA GPU support to SYCL developers", Dec 16, 2019 codeplay.com/portal/12-16-1…
"experimental" support for NVIDIA with ComputeCpp using CUDA
=> In 2020, Codeplay will be releasing a fully open source project supporting for NVIDIA devices to SYCL developers
with oneAPI
=>
[ oneAPI Ondemand Webinar ]
Dec 3, 4, 2019
Introducing oneAPI
DPC++ Part 1: Intro
Dec 11, 2019
DPC++ Part 2: Programming Model: Best Practices techdecoded.intel.io/essentials/dpc…
Slides simplecore-ger.intel.com/techdecoded/wp…
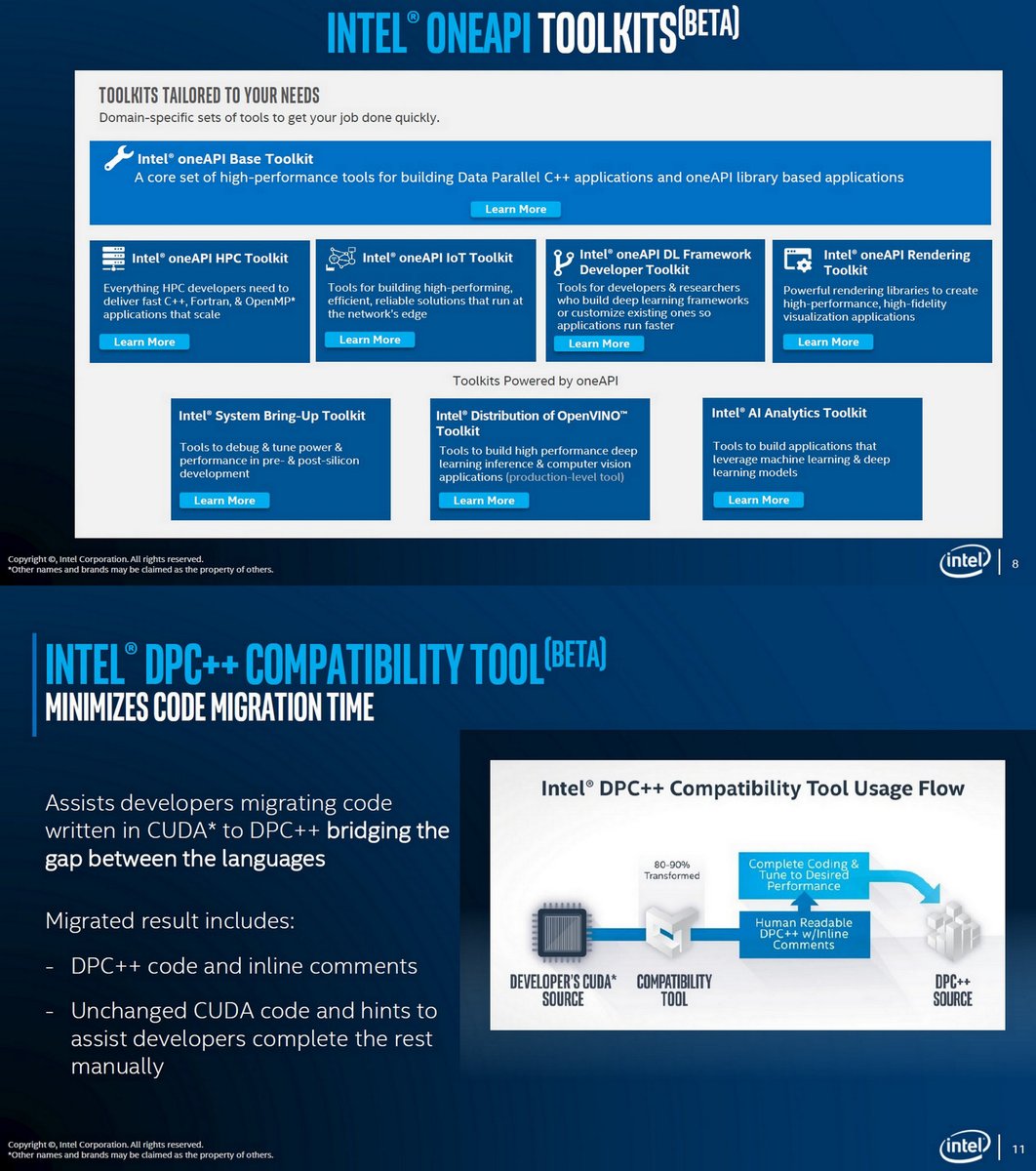
Intel oneAPI Toolkits (Beta) software.intel.com/en-us/oneapi
[ oneAPI Ondemand Webinar ]
Dec 3, 4, 2019
Introducing oneAPI
DPC++ Part 1: Intro
Dec 11, 2019
DPC++ Part 2: Programming Model: Best Practices techdecoded.intel.io/essentials/dpc…
Slides simplecore-ger.intel.com/techdecoded/wp…
Intel oneAPI Toolkits (Beta) software.intel.com/en-us/oneapi



=>
A European Dialect For Exascale Programming, Jan 6 2020 nextplatform.com/2020/01/06/a-e…
Euro joint Effort toward a Highly Productive Programming Environment for Heterogeneous Exascale Computing epeec-project.eu
Productivity at Exascale, PRACE booth, SC19 prace-ri.eu/IMG/pdf/EPEEC_…
A European Dialect For Exascale Programming, Jan 6 2020 nextplatform.com/2020/01/06/a-e…
Euro joint Effort toward a Highly Productive Programming Environment for Heterogeneous Exascale Computing epeec-project.eu
Productivity at Exascale, PRACE booth, SC19 prace-ri.eu/IMG/pdf/EPEEC_…


=>
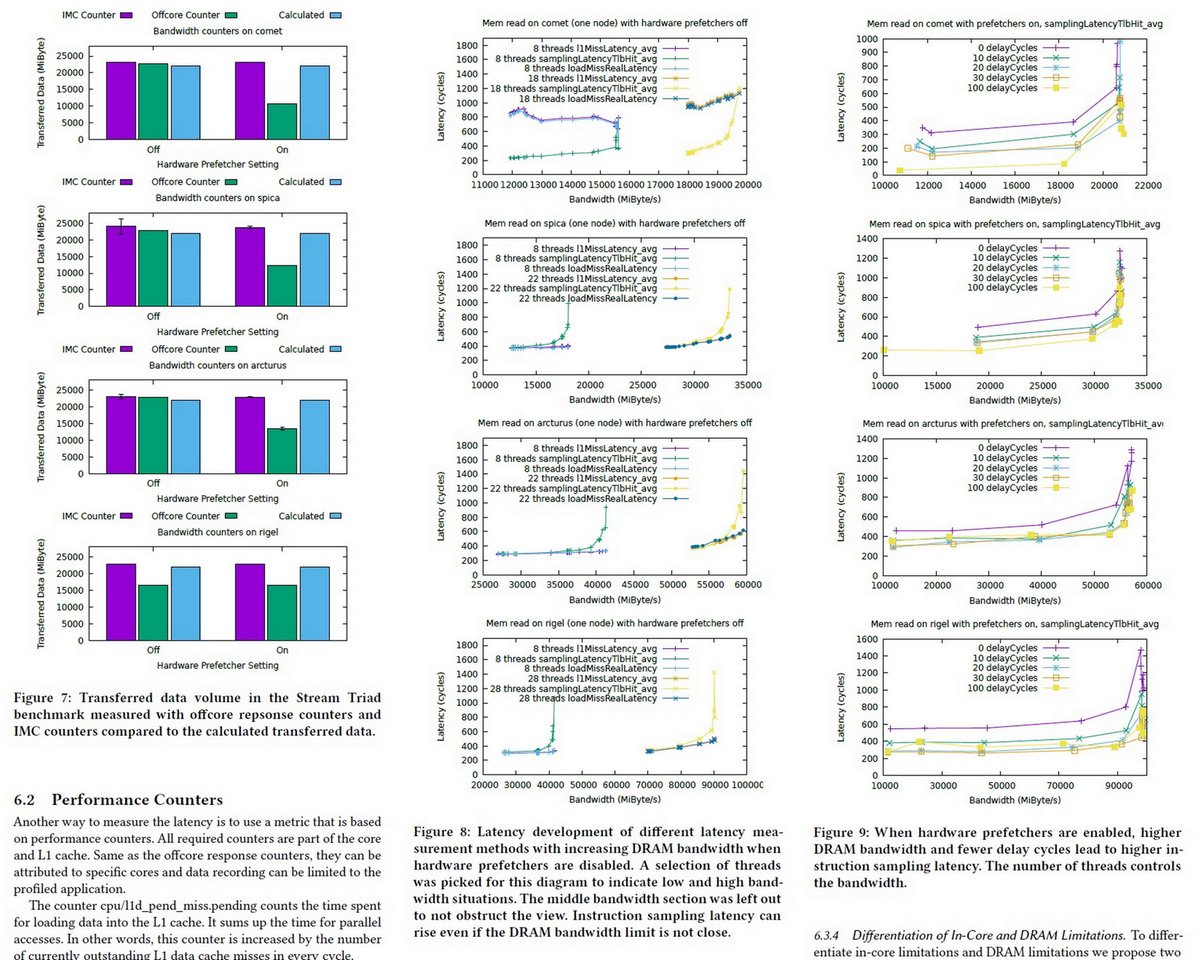
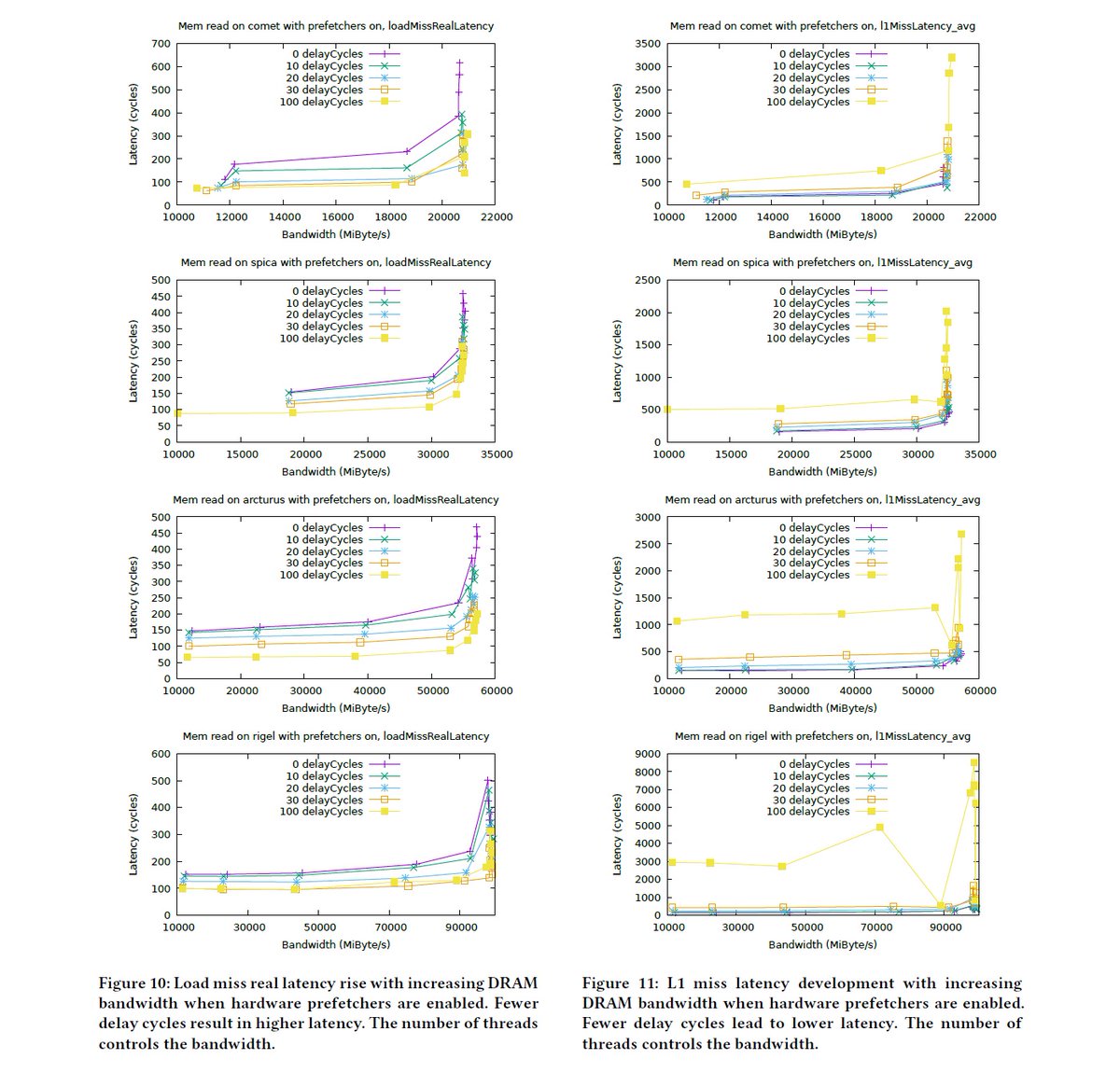
"On the Correct Measurement of Application Memory Bandwidth and Memory Access Latency", HPC Asia 2020 dl.acm.org/doi/abs/10.114…
github.com/helchr/perfMem…
comet: HWL, E5-2699v3, 1847Mhz
spica BWL, E7-8890v4, 1600Mhz
arcturus: BWL, E5-2699v4, 2400Mhz
rigel: SKL, Xeon 8176, 2666Mhz
"On the Correct Measurement of Application Memory Bandwidth and Memory Access Latency", HPC Asia 2020 dl.acm.org/doi/abs/10.114…
github.com/helchr/perfMem…
comet: HWL, E5-2699v3, 1847Mhz
spica BWL, E7-8890v4, 1600Mhz
arcturus: BWL, E5-2699v4, 2400Mhz
rigel: SKL, Xeon 8176, 2666Mhz


=>
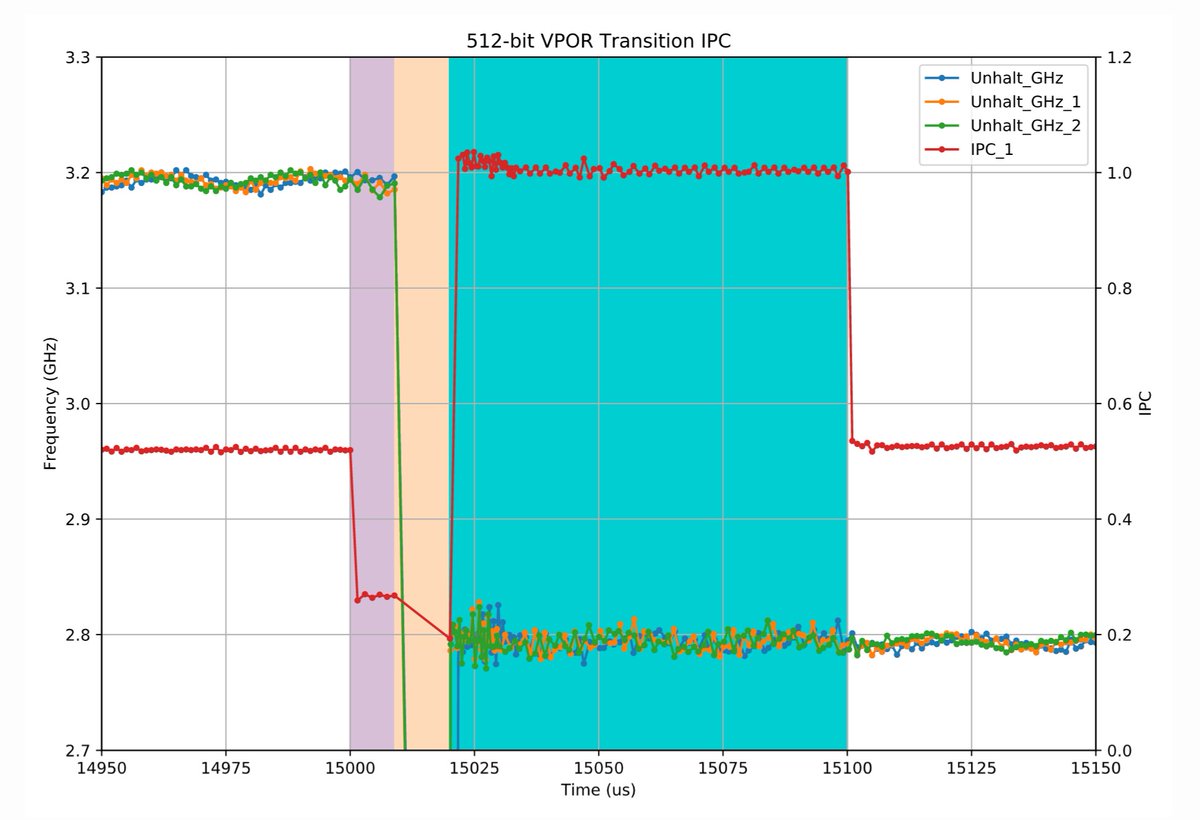
"Gathering Intel on Intel AVX-512 Transitions", Jan 17, 2020 travisdowns.github.io/blog/2020/01/1…
"examine the AVX-512 downclocking behavior using target tests"
Xeon W-2104
3.2, 2.8, 2.4 GHz
CPU & DRAM
Myth of Peak Performance (Cascade Lake)
"Gathering Intel on Intel AVX-512 Transitions", Jan 17, 2020 travisdowns.github.io/blog/2020/01/1…
"examine the AVX-512 downclocking behavior using target tests"
Xeon W-2104
3.2, 2.8, 2.4 GHz
CPU & DRAM
Myth of Peak Performance (Cascade Lake)

=>
"AsmDB: Understanding and Mitigating Front-end Stalls in Warehouse-Scale Computers", ..., Parthasarathy Ranganathan (Google), ISCA 2019, PDF liberty.princeton.edu/Publications/i…
∗Work performed while these authors were at Google.
Memory Hierarchy for .,, HPCA 2018,
"AsmDB: Understanding and Mitigating Front-end Stalls in Warehouse-Scale Computers", ..., Parthasarathy Ranganathan (Google), ISCA 2019, PDF liberty.princeton.edu/Publications/i…
∗Work performed while these authors were at Google.
Memory Hierarchy for .,, HPCA 2018,


=>
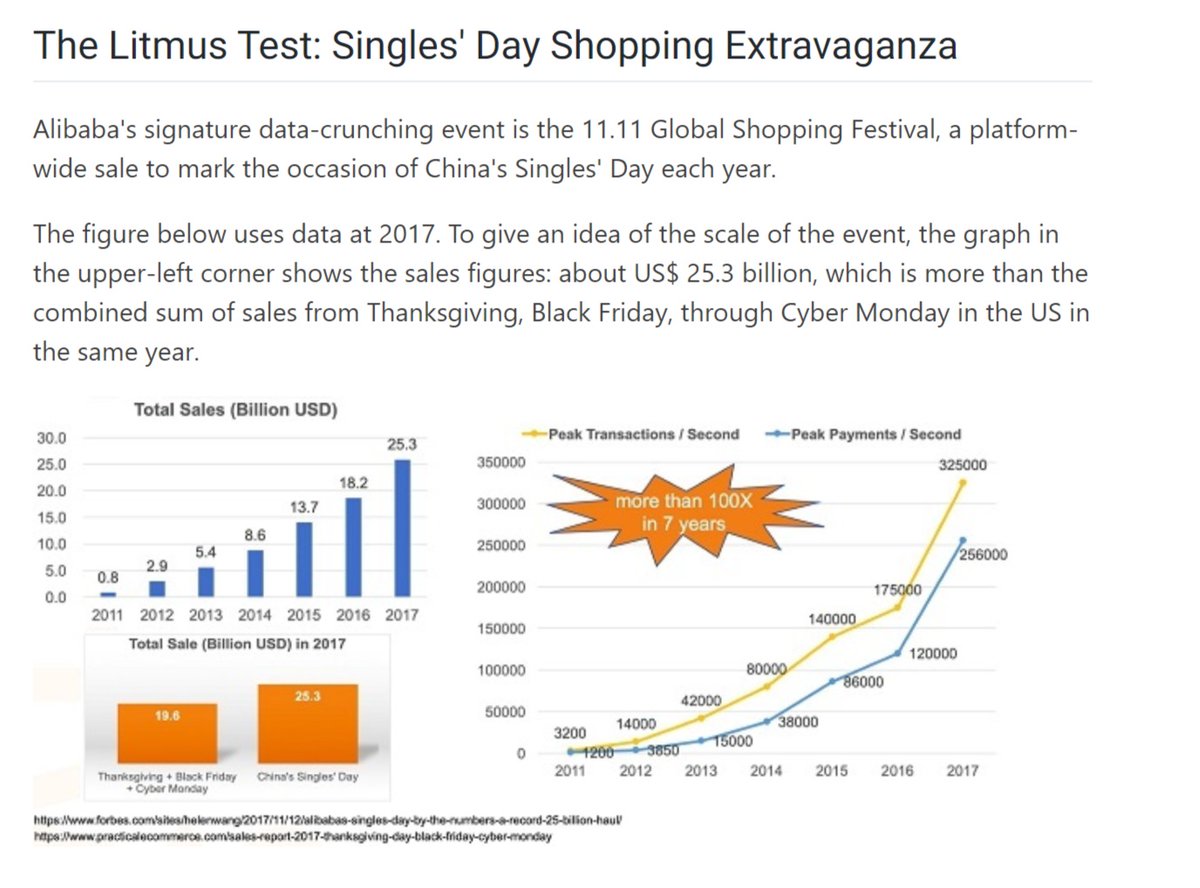
"Avoiding Mistakes in Large Scale Performance Analysis", Kingsum Chow, Alibaba, IMPACT 2019, Feb 21, 2019 slideslive.com/38913881/avoid…
"Performance Analysis of Alibaba Large-Scale Data Center", Jianmei Guo, Senior technical expert, Alibaba Blog, Apr 11, 2019 alibabacloud.com/blog/performan…
"Avoiding Mistakes in Large Scale Performance Analysis", Kingsum Chow, Alibaba, IMPACT 2019, Feb 21, 2019 slideslive.com/38913881/avoid…
"Performance Analysis of Alibaba Large-Scale Data Center", Jianmei Guo, Senior technical expert, Alibaba Blog, Apr 11, 2019 alibabacloud.com/blog/performan…



=>
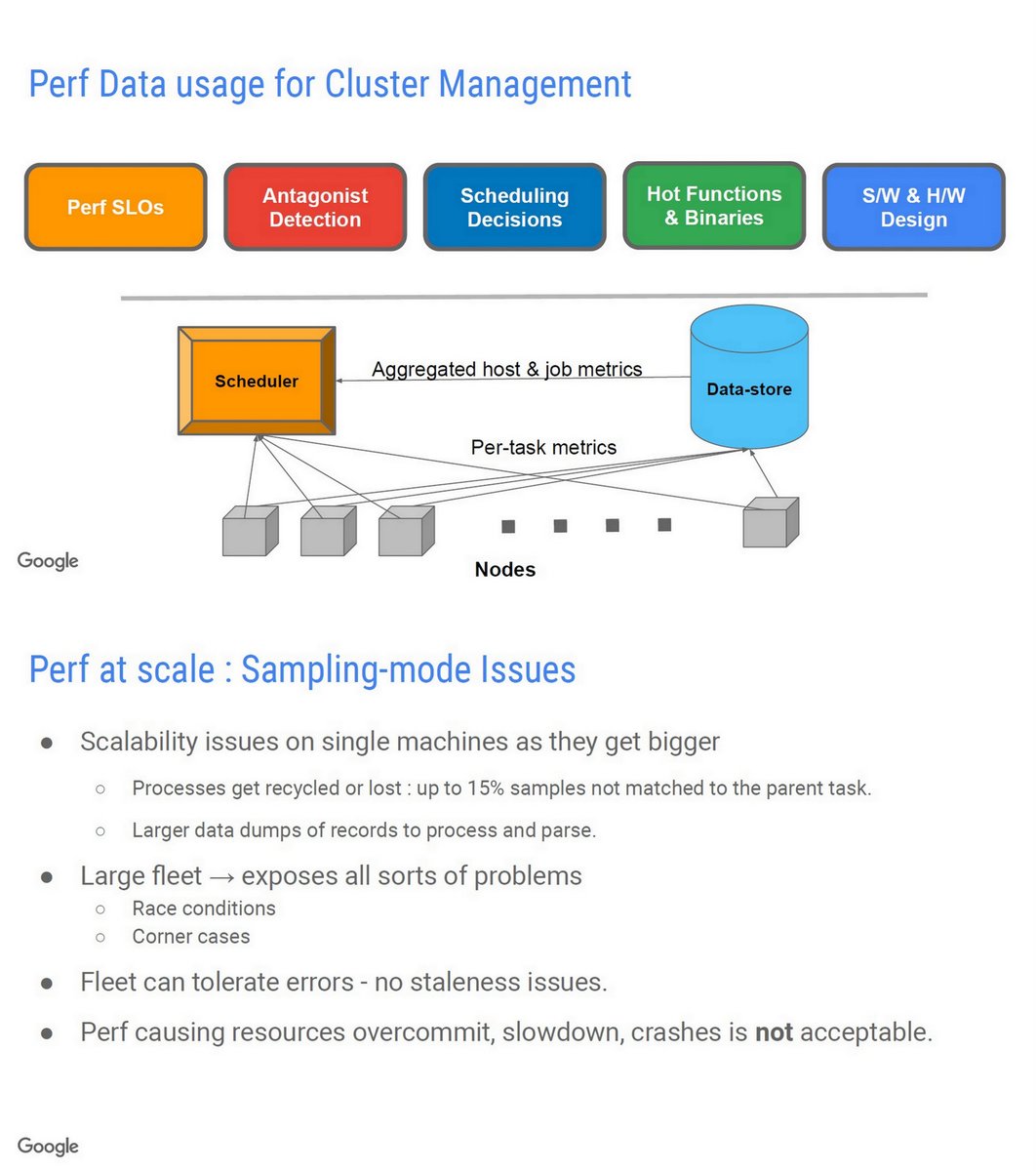
"Scalability of performance monitoring", Google, Linux Plumbers Conference 2019, PDF linuxplumbersconf.org/event/4/contri…
Borg, EuroSys'15
"Google Flex", John Wilkes, May 2018
Google-Wide Profiling, IEEE Micro 2010 PDF storage.googleapis.com/pub-tools-publ…
"Scalability of performance monitoring", Google, Linux Plumbers Conference 2019, PDF linuxplumbersconf.org/event/4/contri…
Borg, EuroSys'15
"Google Flex", John Wilkes, May 2018
Google-Wide Profiling, IEEE Micro 2010 PDF storage.googleapis.com/pub-tools-publ…



=>
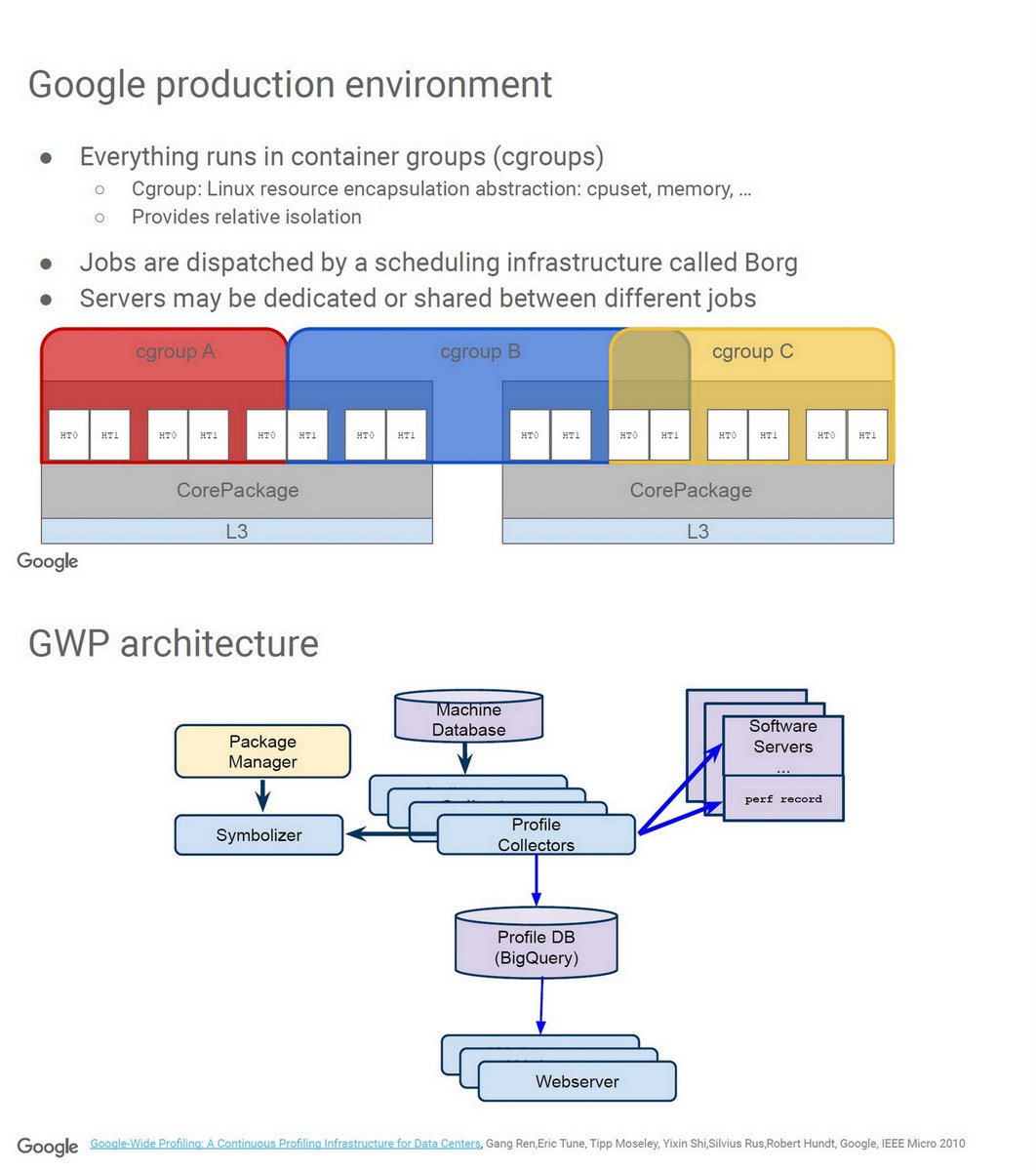
"Hardware Performance Monitoring Landscape", Stephane Eranian, Google, Keynote, ProTools19 protools19.github.io/slides/Eranian…
Scalability of performance monitoring
Google-Wide Profiling, Borg
AsmDB, ISCA 2019
Alibaba
"Hardware Performance Monitoring Landscape", Stephane Eranian, Google, Keynote, ProTools19 protools19.github.io/slides/Eranian…
Scalability of performance monitoring
Google-Wide Profiling, Borg
AsmDB, ISCA 2019
Alibaba



=>
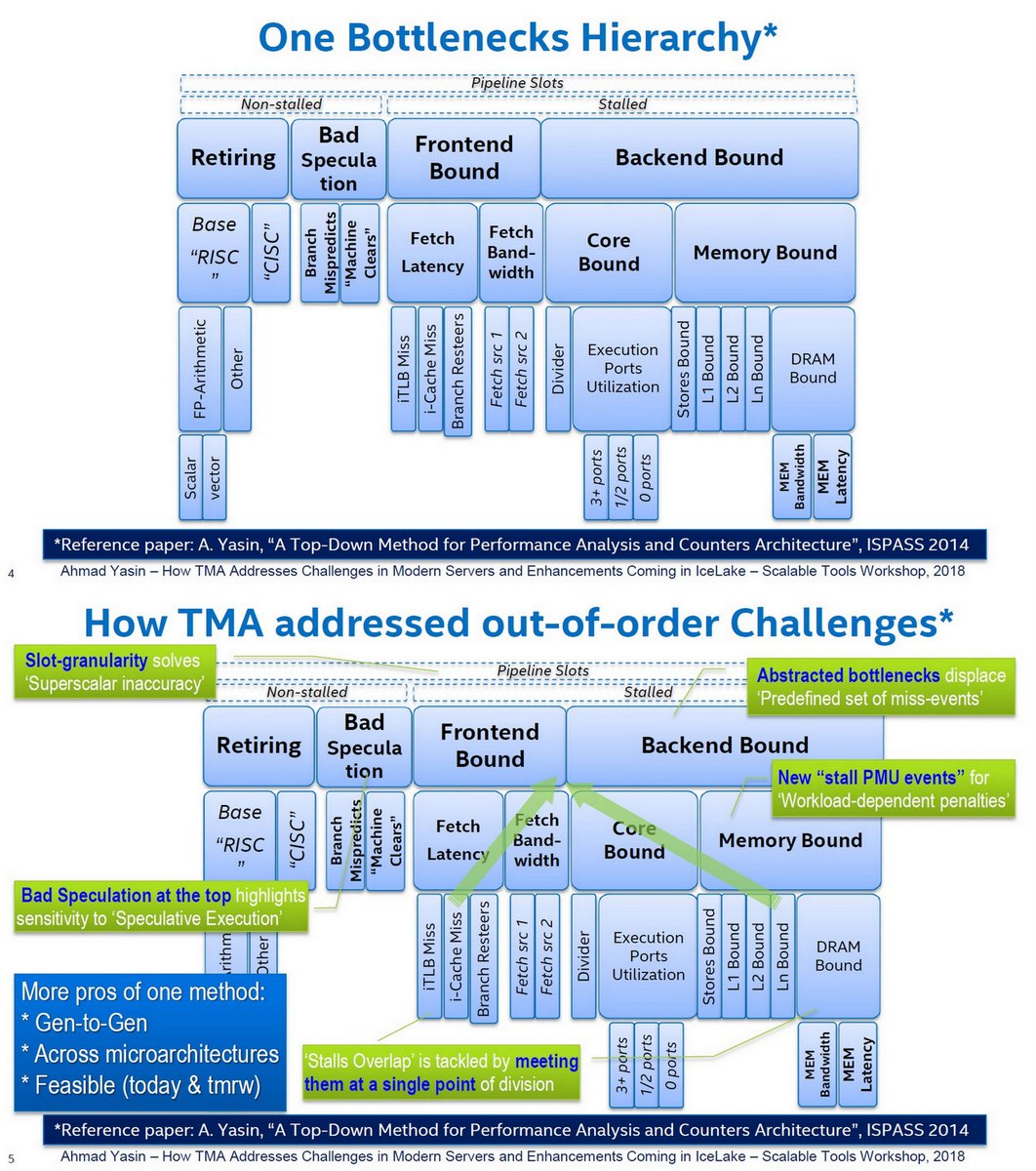
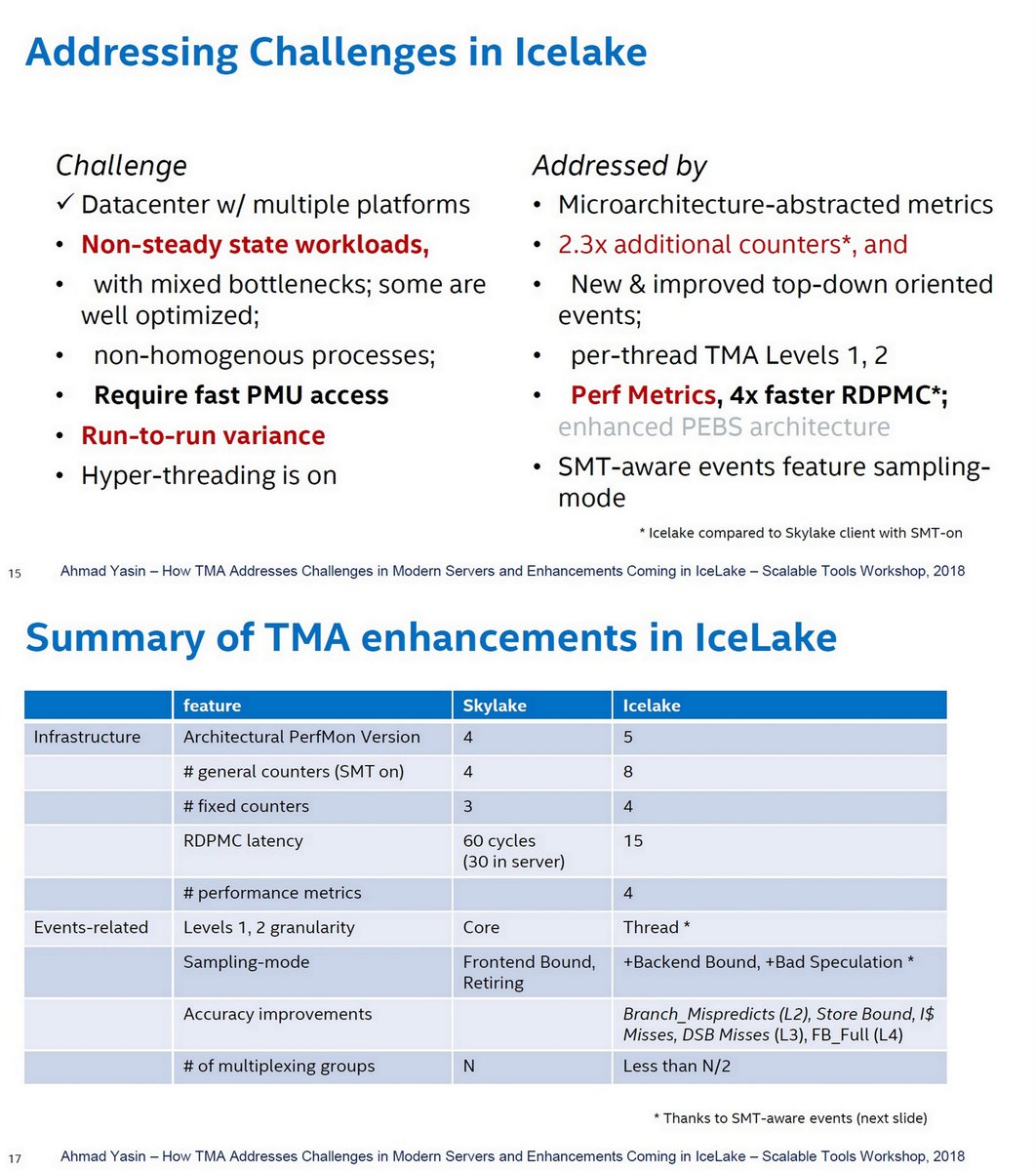
"How TMA (Top-down Microarchitecture Analysis) Addresses Challenges in Modern Servers and Enhancements Coming in IceLake", Ahmad Yasin, Intel, Scalable Tools WS, Jul 10, 2018 dyninst.github.io/scalable_tools…
Reversim Summit, Jun 17, 2019 youtube.com/watch?v=NabAgE…
"How TMA (Top-down Microarchitecture Analysis) Addresses Challenges in Modern Servers and Enhancements Coming in IceLake", Ahmad Yasin, Intel, Scalable Tools WS, Jul 10, 2018 dyninst.github.io/scalable_tools…
Reversim Summit, Jun 17, 2019 youtube.com/watch?v=NabAgE…


=>
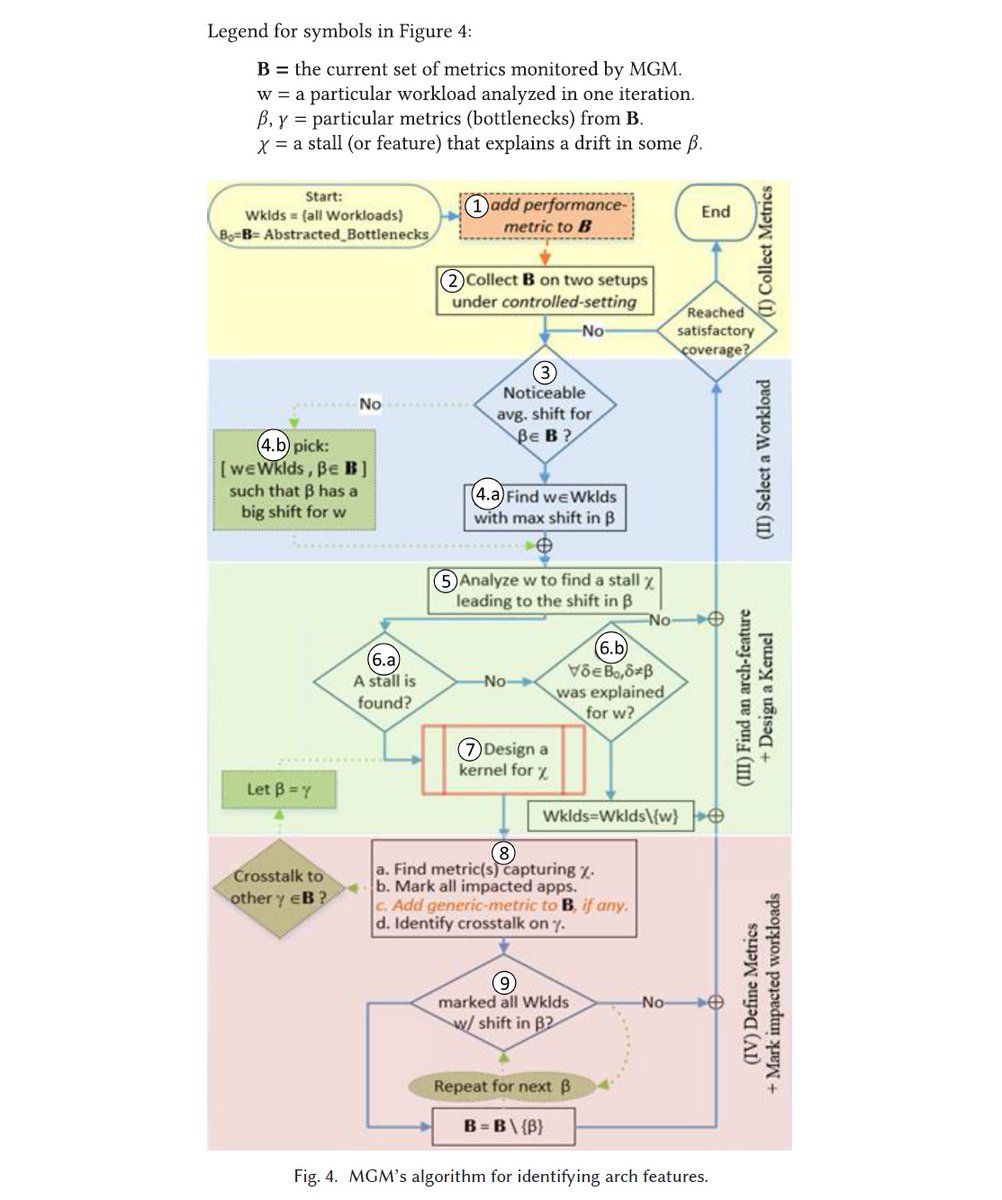
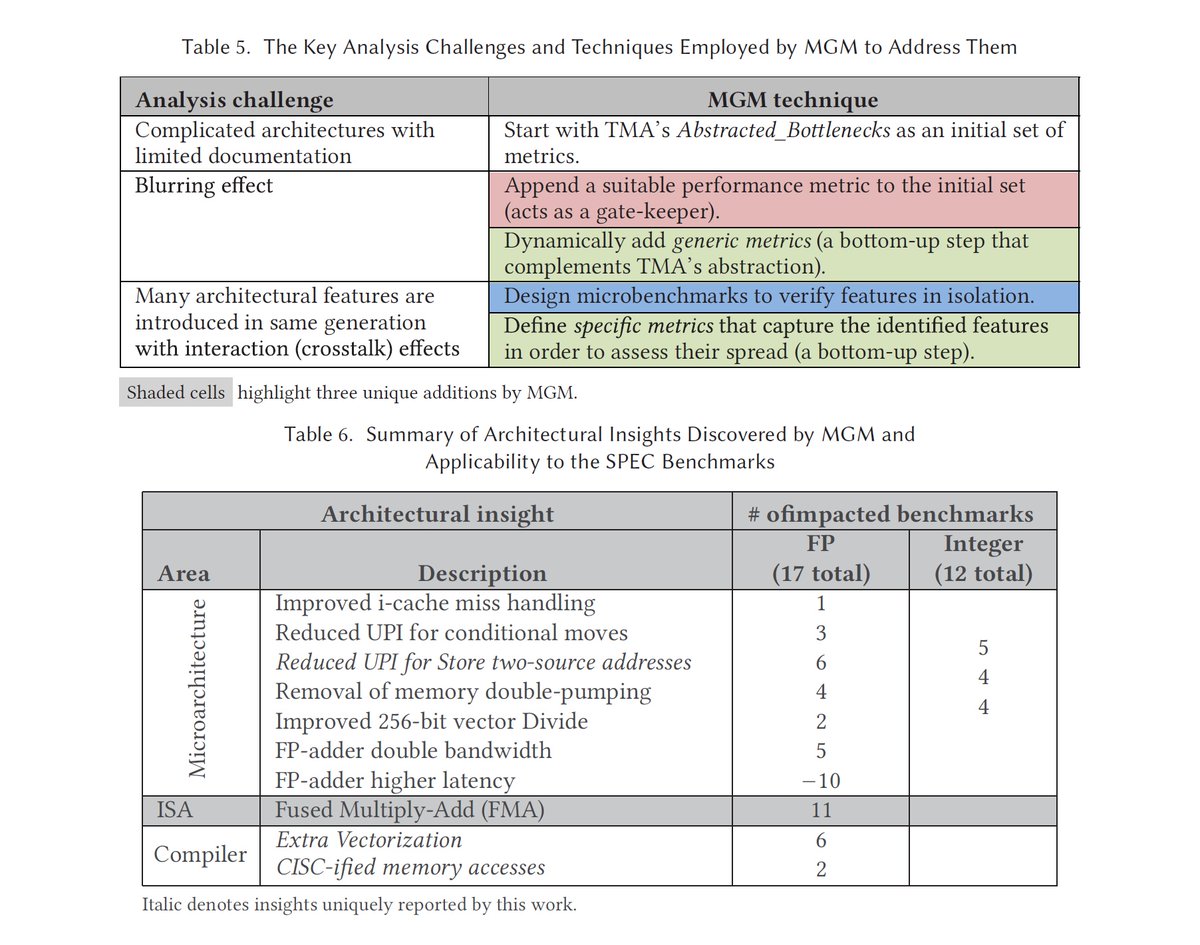
"A Metric-Guided Method (MGM) for Discovering Impactful Features and Architectural Insights for Skylake-Based Processors", A. Yasin (U of Haifa and Intel), et al., ACM TACO, Dec 2019 dl.acm.org/doi/abs/10.114…
Top-down Microarchitecture Analysis, A. Yasin
"A Metric-Guided Method (MGM) for Discovering Impactful Features and Architectural Insights for Skylake-Based Processors", A. Yasin (U of Haifa and Intel), et al., ACM TACO, Dec 2019 dl.acm.org/doi/abs/10.114…
Top-down Microarchitecture Analysis, A. Yasin


=>
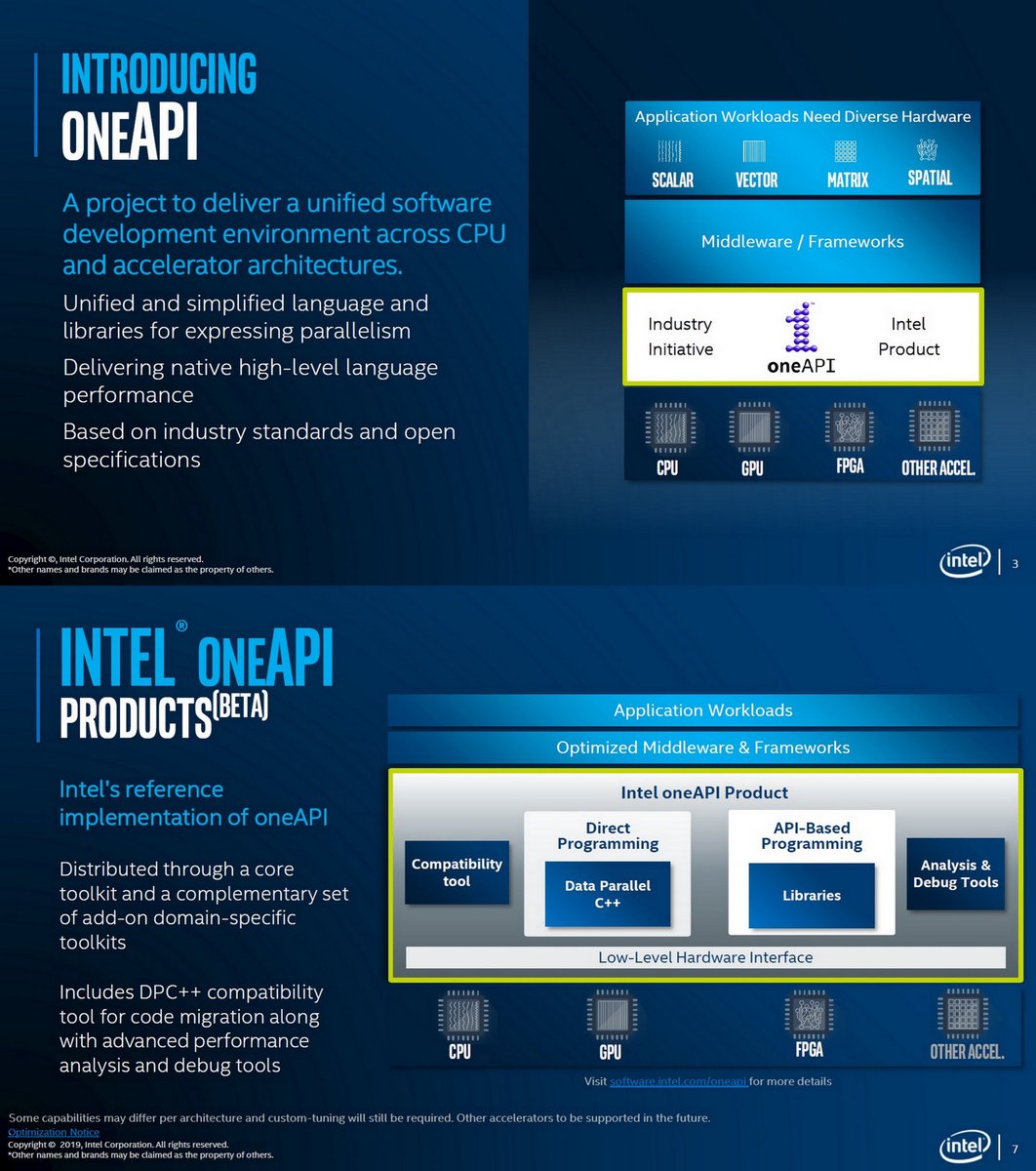
Intel oenAPI, CERN openlab Technical Workshop, Jan 23, 2020 indico.cern.ch/event/853334/c…
Single Programming Model to Deliver Cross-Architecture Performance
Ondemand Webinars, Dec 2029
"Exascale for Everyone", @Rajaontheedge Nov 2019
Intel oenAPI, CERN openlab Technical Workshop, Jan 23, 2020 indico.cern.ch/event/853334/c…
Single Programming Model to Deliver Cross-Architecture Performance
Ondemand Webinars, Dec 2029
"Exascale for Everyone", @Rajaontheedge Nov 2019


@Rajaontheedge =>
"First experience of CMS reconstruction with OneAPI", CERN, CERN openlab Technical Workshop, Jan 23, 2020 indico.cern.ch/event/853334/c…
Host Emulation device: 5888.52 us
Core i9-9900K, 3.60GHz: 5728.53 us
Gen9 HD Graphics NEO: 1653.66 us
oneAPI, Jan 23, 2020
"First experience of CMS reconstruction with OneAPI", CERN, CERN openlab Technical Workshop, Jan 23, 2020 indico.cern.ch/event/853334/c…
Host Emulation device: 5888.52 us
Core i9-9900K, 3.60GHz: 5728.53 us
Gen9 HD Graphics NEO: 1653.66 us
oneAPI, Jan 23, 2020




=>
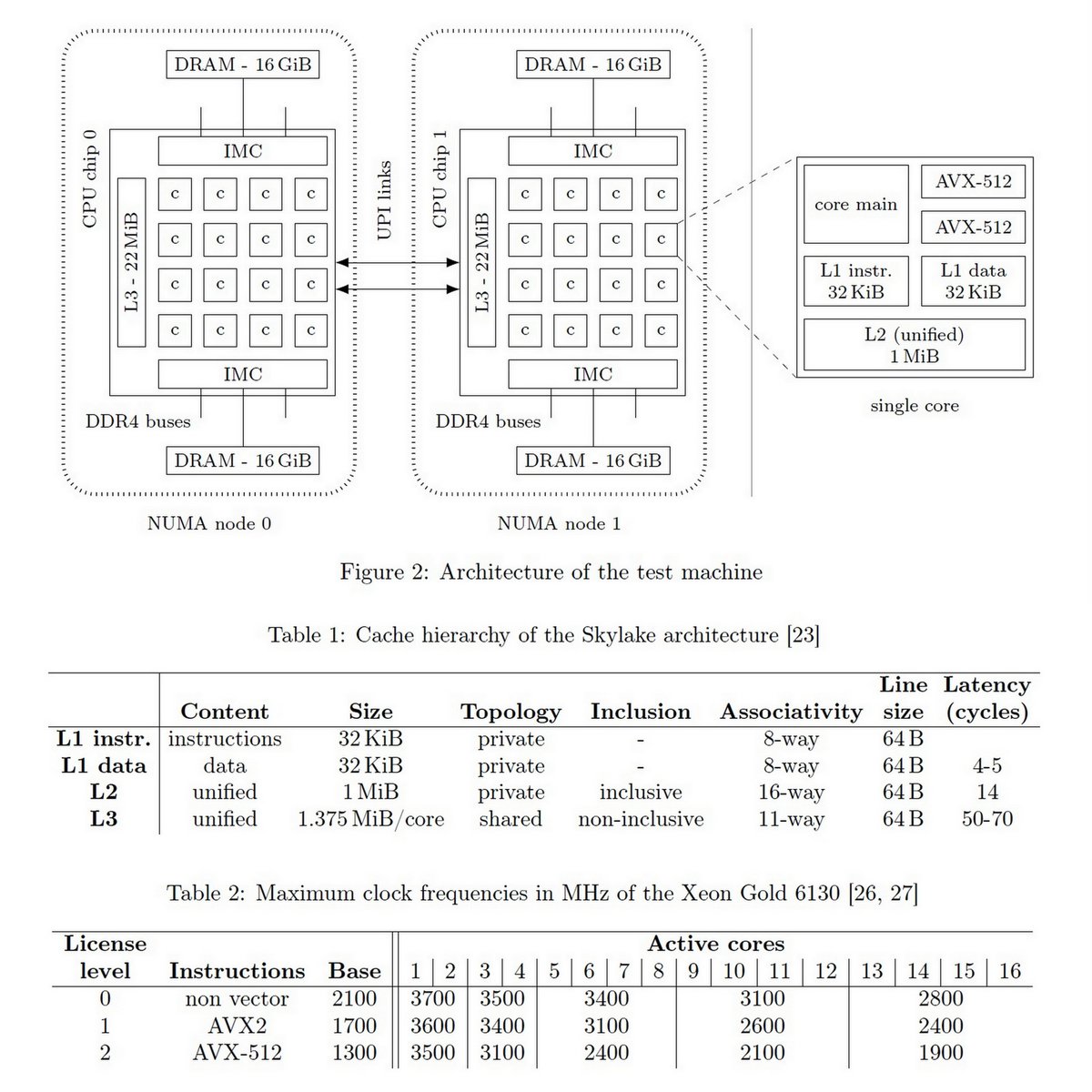
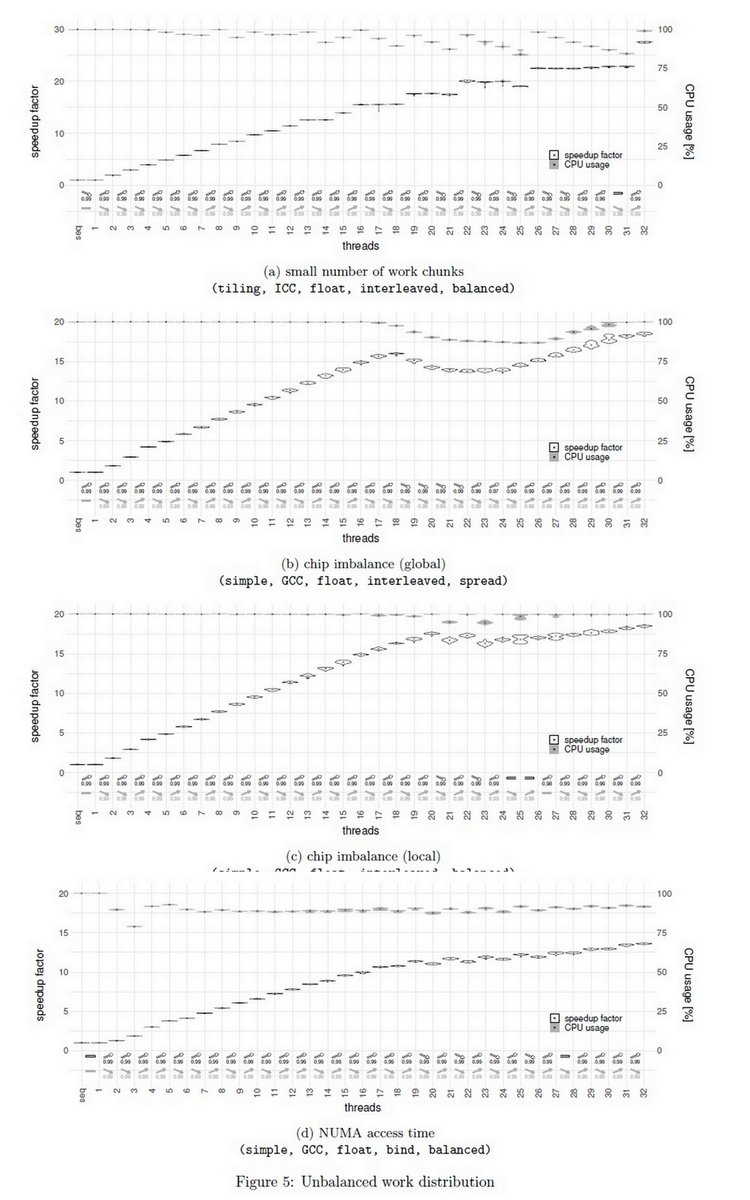
"Empirical study of Amdahl's law on multicore processors", Research Report, Dec 11, 2019 hal.inria.fr/hal-02404346
2x [Xeon Gold 6130 + (2x 16 GiB DDR4 (2666 MT/s)]
Peak: 85:33GB/s
GCC, ICC & Clang, OpenMP
Kairos team.inria.fr/kairos/
Energy Efficiency
"Empirical study of Amdahl's law on multicore processors", Research Report, Dec 11, 2019 hal.inria.fr/hal-02404346
2x [Xeon Gold 6130 + (2x 16 GiB DDR4 (2666 MT/s)]
Peak: 85:33GB/s
GCC, ICC & Clang, OpenMP
Kairos team.inria.fr/kairos/
Energy Efficiency


=>
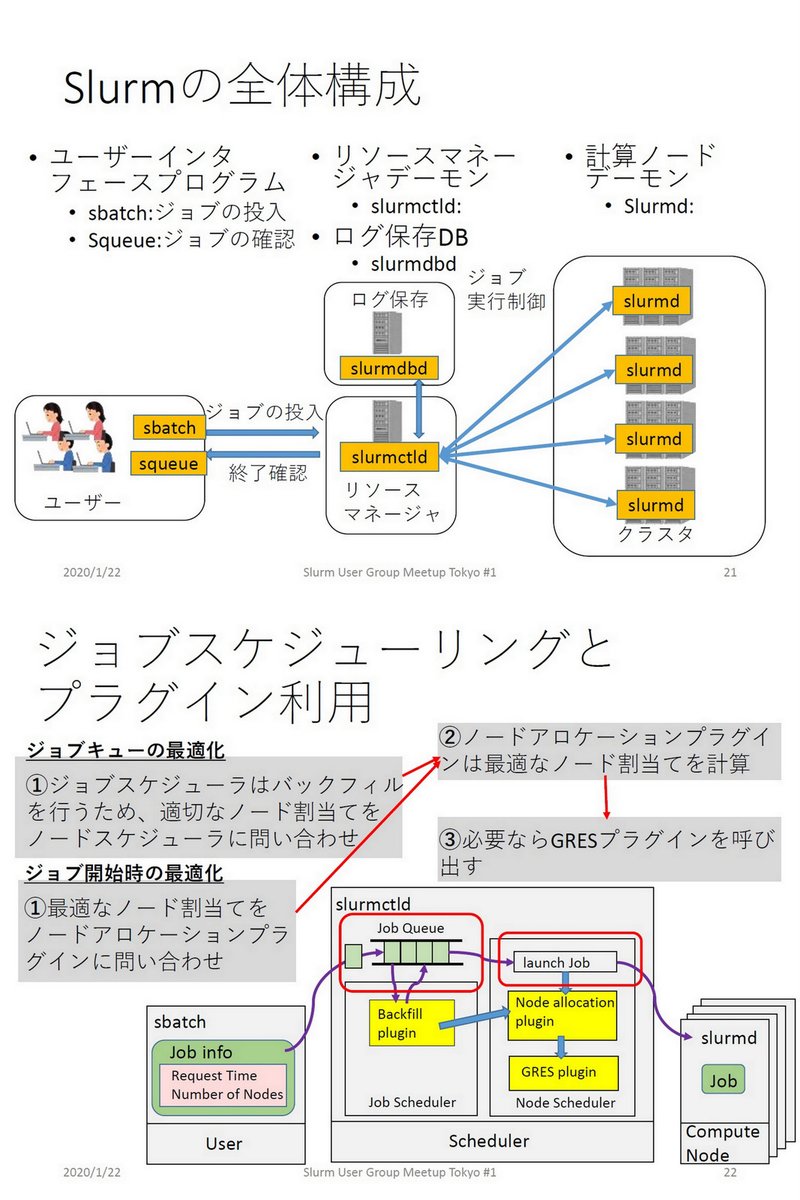
"Slurmのジョブスケジューリングと実装"、東京大学 坂本龍一、Slurm User Group Meetup Tokyo #SUGMT 、2020年1月22日 slideshare.net/RyuichiSakamot…
Presentations from Slurm UG Meeting slurm.schedmd.com/publications.h…
Slurm on GCP, Mar 2019
IPDPS 2017
"Slurmのジョブスケジューリングと実装"、東京大学 坂本龍一、Slurm User Group Meetup Tokyo #SUGMT 、2020年1月22日 slideshare.net/RyuichiSakamot…
Presentations from Slurm UG Meeting slurm.schedmd.com/publications.h…
Slurm on GCP, Mar 2019
IPDPS 2017



=>
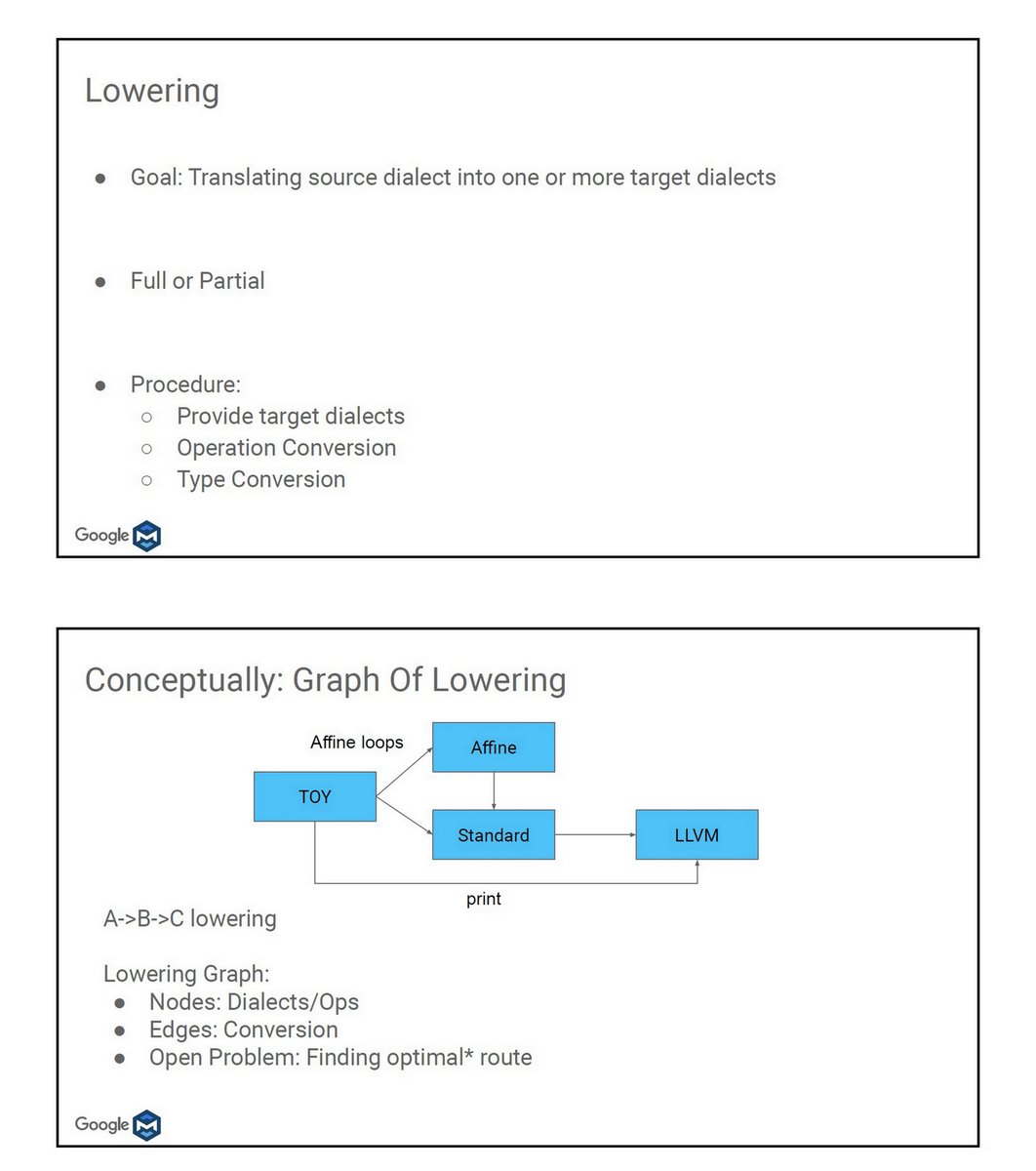
"MLIR Tutorial: Building a Compiler with MLIR", Google, WS on MLIR for HPC, Oct 21, 2019, PDF cs.utah.edu/~mhall/mlir4hp…
github.com/tensorflow/mlir
=> mlir.llvm.org
github.com/llvm/llvm-proj…
High-Performance Compilation Opportunities in MLIR, Jan 2020
"MLIR Tutorial: Building a Compiler with MLIR", Google, WS on MLIR for HPC, Oct 21, 2019, PDF cs.utah.edu/~mhall/mlir4hp…
github.com/tensorflow/mlir
=> mlir.llvm.org
github.com/llvm/llvm-proj…
High-Performance Compilation Opportunities in MLIR, Jan 2020



=>
"Flang: The Fortran Frontend of LLVM", FOSDEM, Feb 1, 2020 fosdem.org/2020/schedule/…
PDF fosdem.org/2020/schedule/…
New Flang/F18 github.com/flang-compiler…
"An MLIR Dialect for High-Level Optimization of Fortran", NVIDIA, Oct 2019 youtube.com/watch?v=ff3ngd…
MLIR
"Flang: The Fortran Frontend of LLVM", FOSDEM, Feb 1, 2020 fosdem.org/2020/schedule/…
PDF fosdem.org/2020/schedule/…
New Flang/F18 github.com/flang-compiler…
"An MLIR Dialect for High-Level Optimization of Fortran", NVIDIA, Oct 2019 youtube.com/watch?v=ff3ngd…
MLIR




=>
"Codeplay contribution to DPC++ brings SYCL support for NVIDIA GPUs", Feb 3, 2020 codeplay.com/portal/02-03-2…
Adding to the DPC++ compiler is based directly on NVIDIA's CUDA, rather than OpenCL
oneAPI, Jan 2020
Ondemand Webinars, Dec 2019
Intro, DPC++ 1 & 2
"Codeplay contribution to DPC++ brings SYCL support for NVIDIA GPUs", Feb 3, 2020 codeplay.com/portal/02-03-2…
Adding to the DPC++ compiler is based directly on NVIDIA's CUDA, rather than OpenCL
oneAPI, Jan 2020
Ondemand Webinars, Dec 2019
Intro, DPC++ 1 & 2
=>
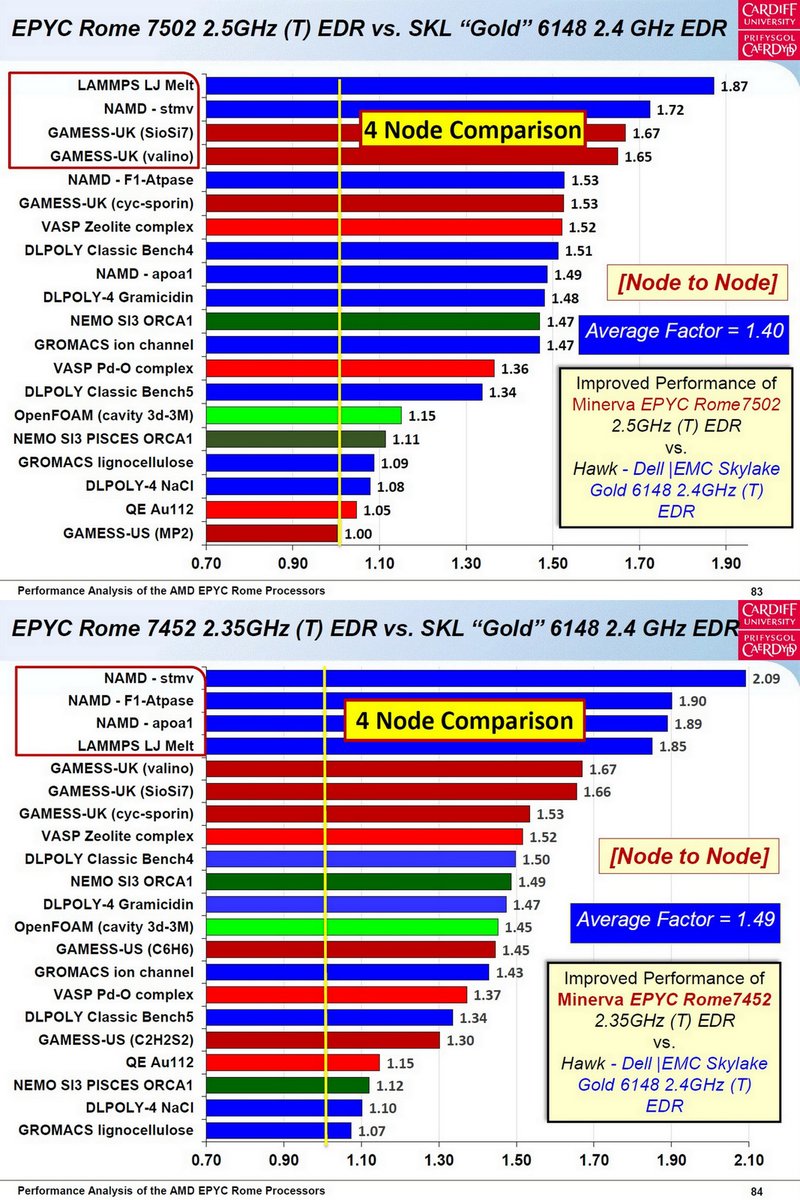
Performance Analysis of the AMD EPYC Rome, J. Munoz, Cardiff U, CIUK 2019, Dec 5, 2019, (91 pp) scd.stfc.ac.uk/SiteAssets/Pag…
AMD EPYC 7452 / 7502 / (7742)
Skylake Gold 6148
Molecular Dynamics: 5s
Quantum Espressoand, VASP
GAMESS-UK/US
OpenFOAM
NEMO
CIUK 2018
Performance Analysis of the AMD EPYC Rome, J. Munoz, Cardiff U, CIUK 2019, Dec 5, 2019, (91 pp) scd.stfc.ac.uk/SiteAssets/Pag…
AMD EPYC 7452 / 7502 / (7742)
Skylake Gold 6148
Molecular Dynamics: 5s
Quantum Espressoand, VASP
GAMESS-UK/US
OpenFOAM
NEMO
CIUK 2018



=>
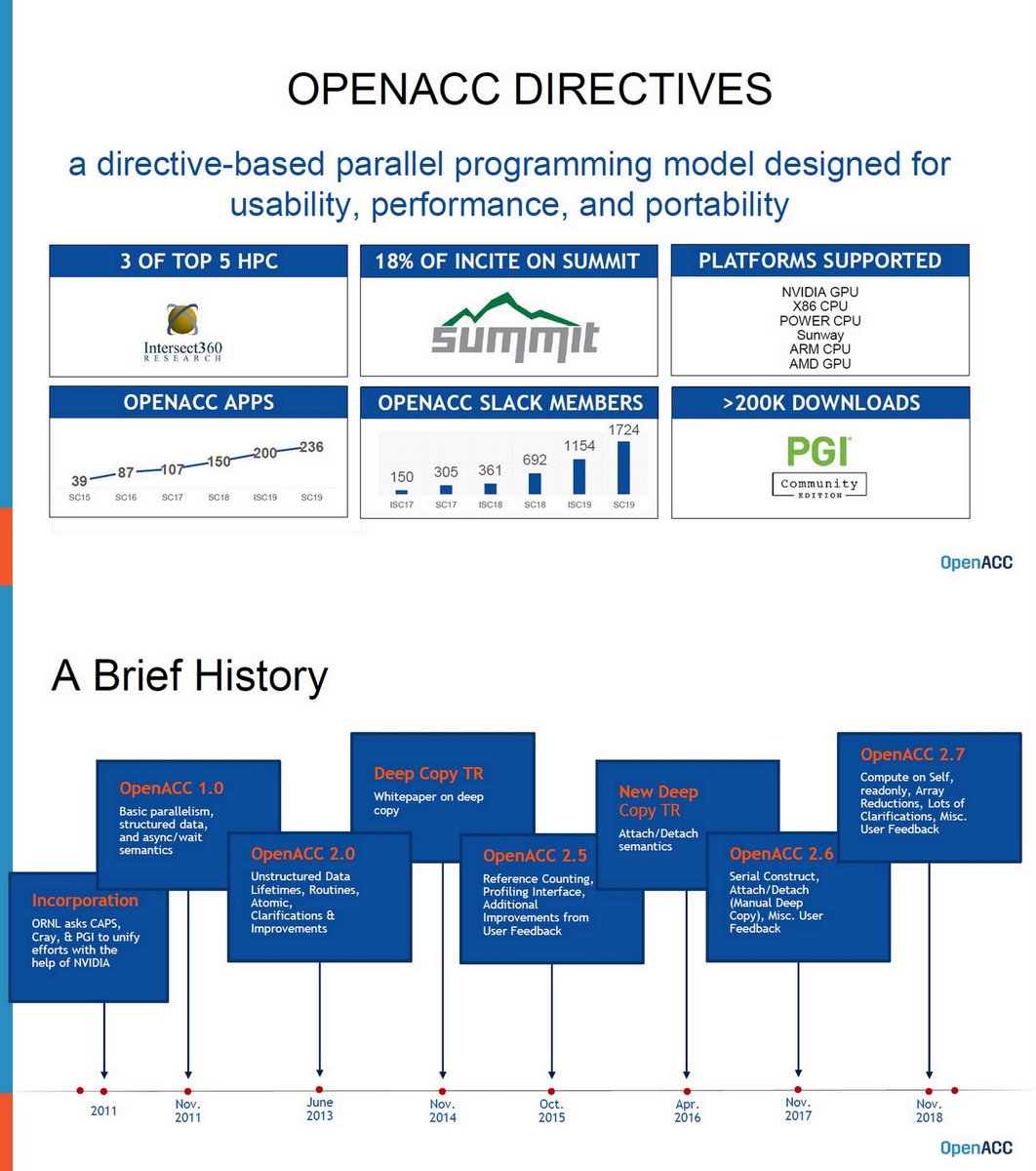
"To OpenACC 3.0, and Beyond!", Jeff Larkin, NVIDIA and OpenACC Technical Committee Chair, UTK ICL Lunch Seminar, Jan 24, 2020, PDF icl.cs.utk.edu/newsletter/pre…
OpenACC, Ver 3.0, Dec 18, 2019 openacc.org/blog/openacc-30
Spec, Nov 2019, PDF openacc.org/sites/default/…
devblogs.nvidia.com/author/jlarkin/
"To OpenACC 3.0, and Beyond!", Jeff Larkin, NVIDIA and OpenACC Technical Committee Chair, UTK ICL Lunch Seminar, Jan 24, 2020, PDF icl.cs.utk.edu/newsletter/pre…
OpenACC, Ver 3.0, Dec 18, 2019 openacc.org/blog/openacc-30
Spec, Nov 2019, PDF openacc.org/sites/default/…
devblogs.nvidia.com/author/jlarkin/



=>
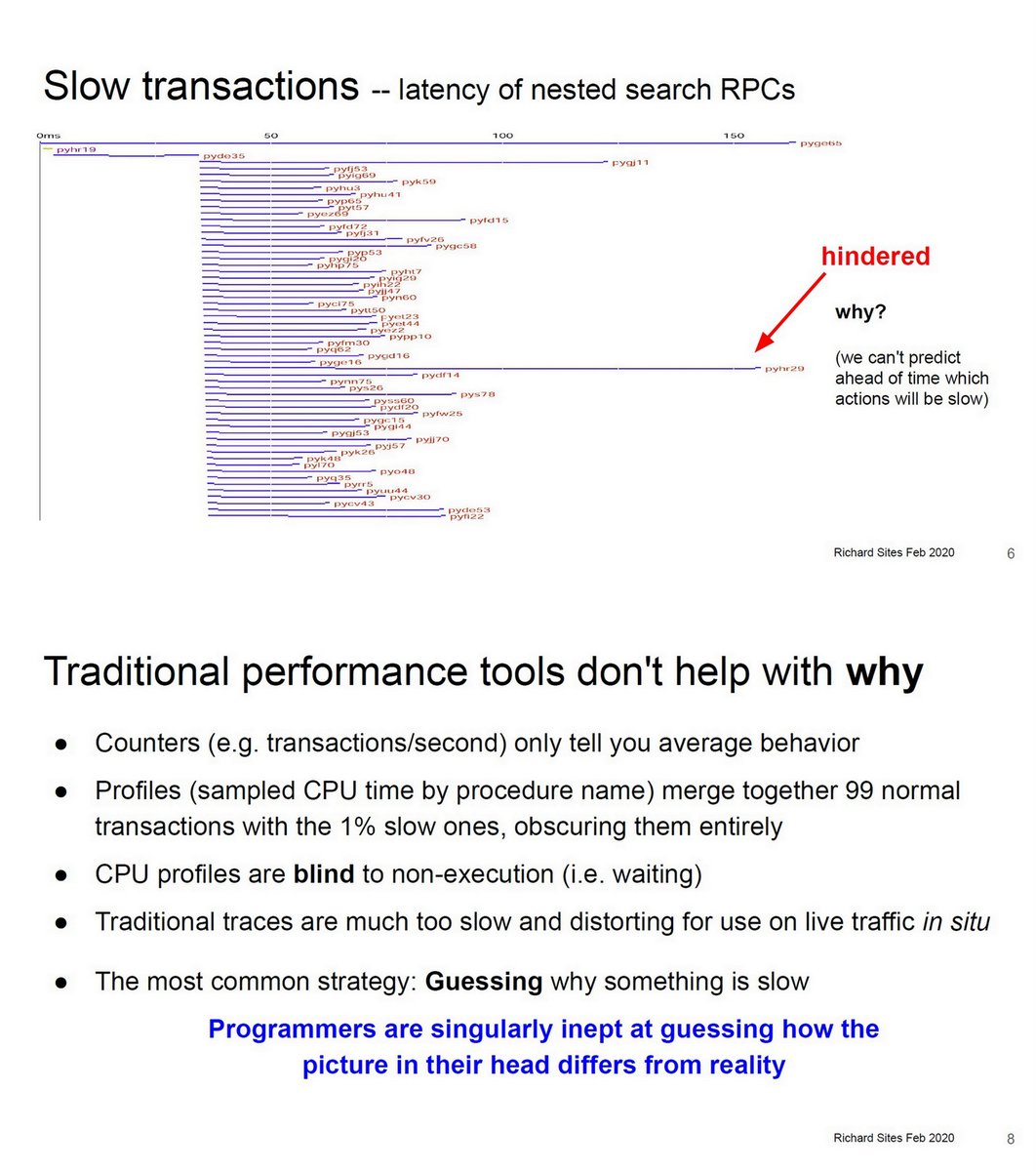
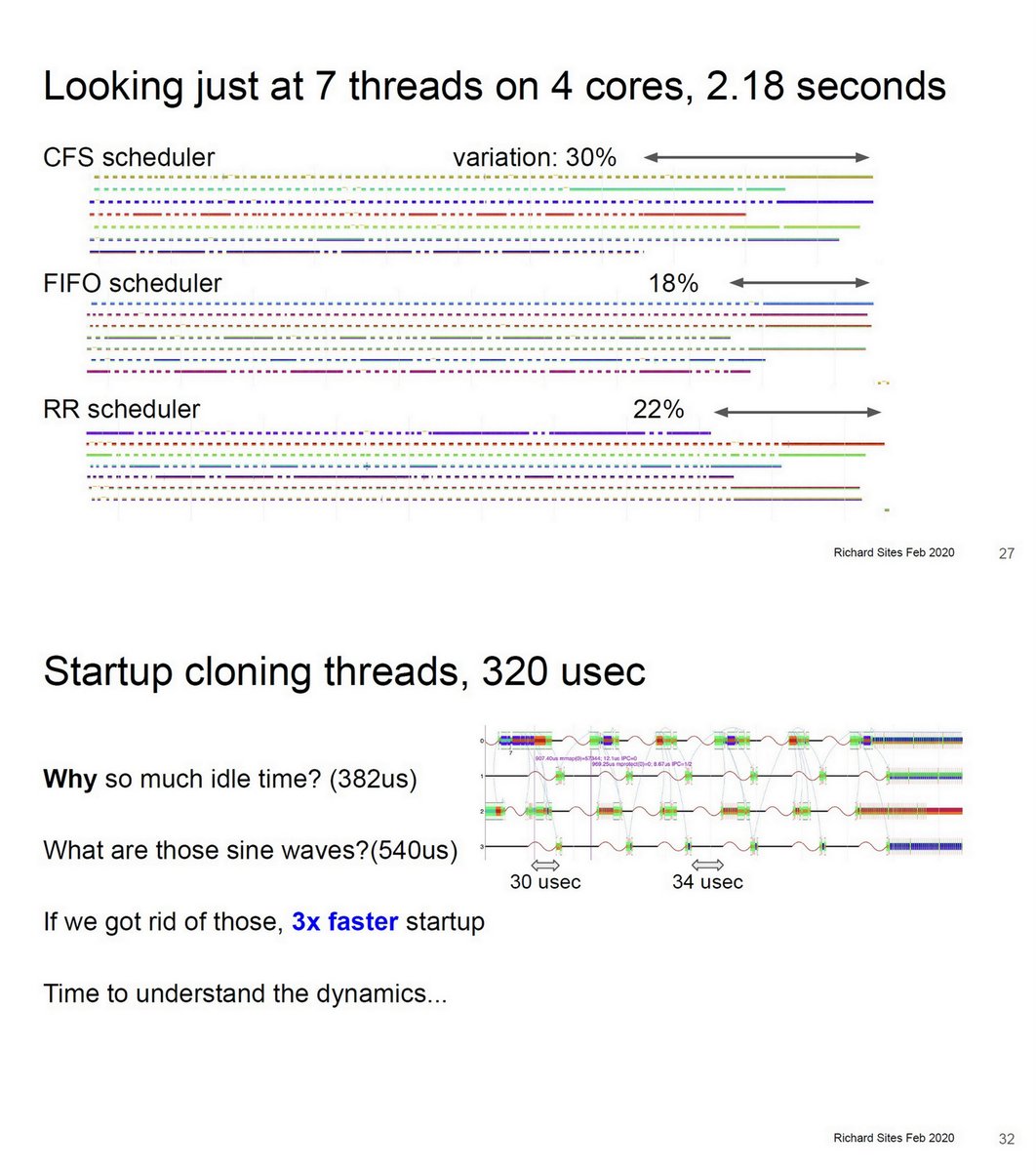
"KUtrace 2020", Richard L. Sites, Stanford EE380, Feb 5 2020 youtube.com/watch?v=2HE7tS…
web.stanford.edu/class/ee380/Ab…
github.com/dicksites/KUtr…
Low-overhead tracing of all Linux kernel-user transitions
Alpha, Apr 1992
DC Computers, Feb 2015
"KUtrace 2020", Richard L. Sites, Stanford EE380, Feb 5 2020 youtube.com/watch?v=2HE7tS…
web.stanford.edu/class/ee380/Ab…
github.com/dicksites/KUtr…
Low-overhead tracing of all Linux kernel-user transitions
Alpha, Apr 1992
DC Computers, Feb 2015


=>
SIAM Conference on Parallel Processing for Scientific Computing (PP20), Feb 12-15, 2020 siam.org/conferences/cm…
Advances in Algorithms Exploiting Low Precision Floating-Point Arithmetic
I of II, Feb 12 meetings.siam.org/sess/dsp_progr…
II of II, Feb 13 meetings.siam.org/sess/dsp_progr…
SIAM Conference on Parallel Processing for Scientific Computing (PP20), Feb 12-15, 2020 siam.org/conferences/cm…
Advances in Algorithms Exploiting Low Precision Floating-Point Arithmetic
I of II, Feb 12 meetings.siam.org/sess/dsp_progr…
II of II, Feb 13 meetings.siam.org/sess/dsp_progr…
=>
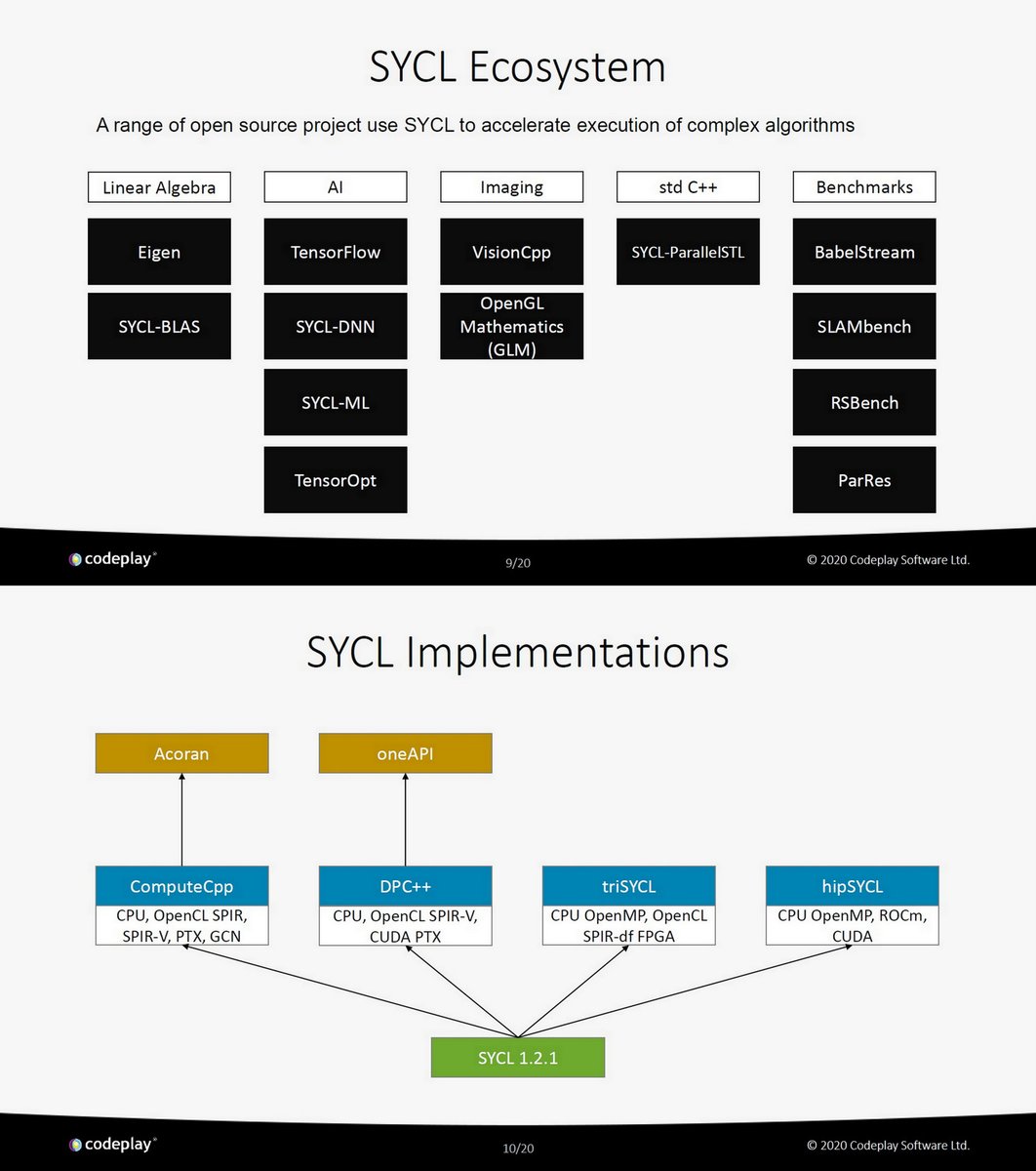
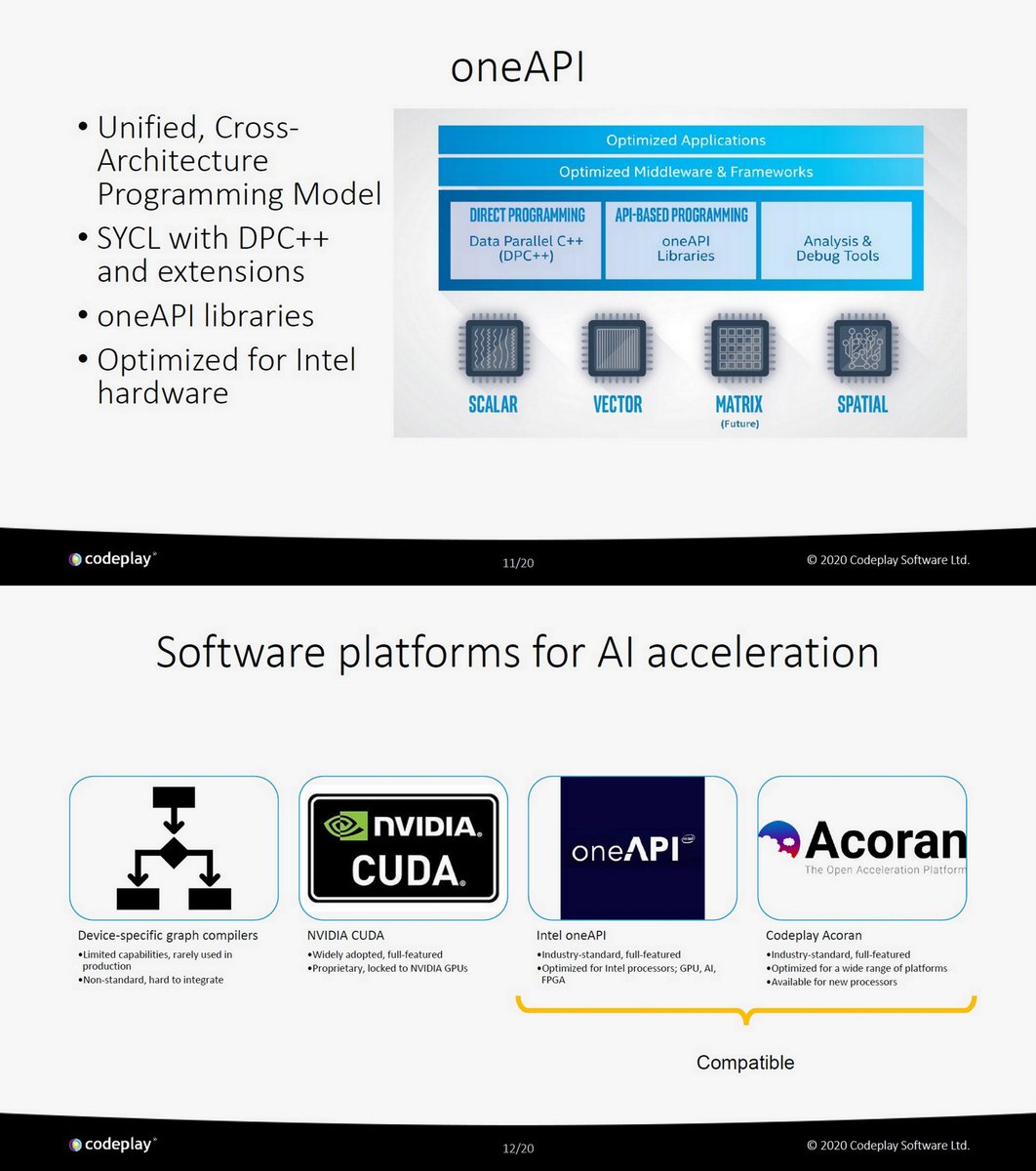
"SYCL in HPC", @codeplaysoft , WS on Efficient Computing for HEP. Feb 18, 2020, PDF indico.ph.ed.ac.uk/event/66/contr…
Acoran
codeplay.com/products/acora…
Codeplay contribution to DPC++ (oneAPI) brings SYCL support for NVIDIA GPUs, Feb 3, 2020
"SYCL in HPC", @codeplaysoft , WS on Efficient Computing for HEP. Feb 18, 2020, PDF indico.ph.ed.ac.uk/event/66/contr…
Acoran
codeplay.com/products/acora…
Codeplay contribution to DPC++ (oneAPI) brings SYCL support for NVIDIA GPUs, Feb 3, 2020


=>
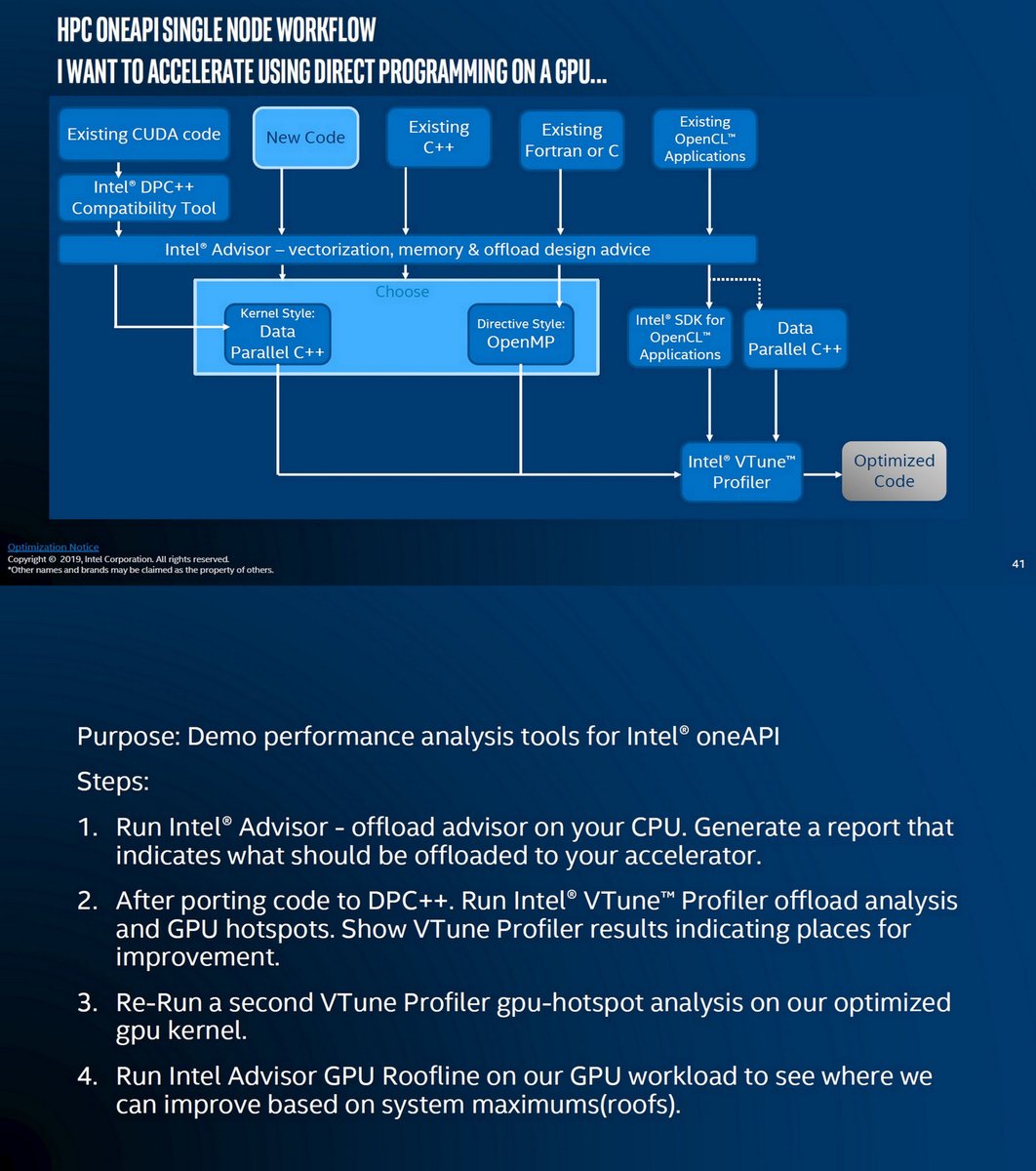
[ Webinar ] Intel oneAPI, Analyzer Training, IXPUB, Feb 20, 2020 ixpug.org/resources/perf…
Slides ixpug.org/resources/down…
Intel Advisor
Offload Advisor
GPU Roofline Analysis
Intel VTune Profiler
GPU Analysis
Analyzing GPU
oenAPI, Jan 23, 2020
Webinars
[ Webinar ] Intel oneAPI, Analyzer Training, IXPUB, Feb 20, 2020 ixpug.org/resources/perf…
Slides ixpug.org/resources/down…
Intel Advisor
Offload Advisor
GPU Roofline Analysis
Intel VTune Profiler
GPU Analysis
Analyzing GPU
oenAPI, Jan 23, 2020
Webinars



=>
"AVX-512 Auto-Vectorization in MSVC", Feb 27, 2020 devblogs.microsoft.com/cppblog/avx-51…
"In Visual Studio 2019 version 16.3 we added AVX-512 support to the auto-vectorizer of the MSVC compiler."
What is the auto vectorizer?
What is AVX-512?
How to enable AVX-512 vectorization?
"AVX-512 Auto-Vectorization in MSVC", Feb 27, 2020 devblogs.microsoft.com/cppblog/avx-51…
"In Visual Studio 2019 version 16.3 we added AVX-512 support to the auto-vectorizer of the MSVC compiler."
What is the auto vectorizer?
What is AVX-512?
How to enable AVX-512 vectorization?
=>
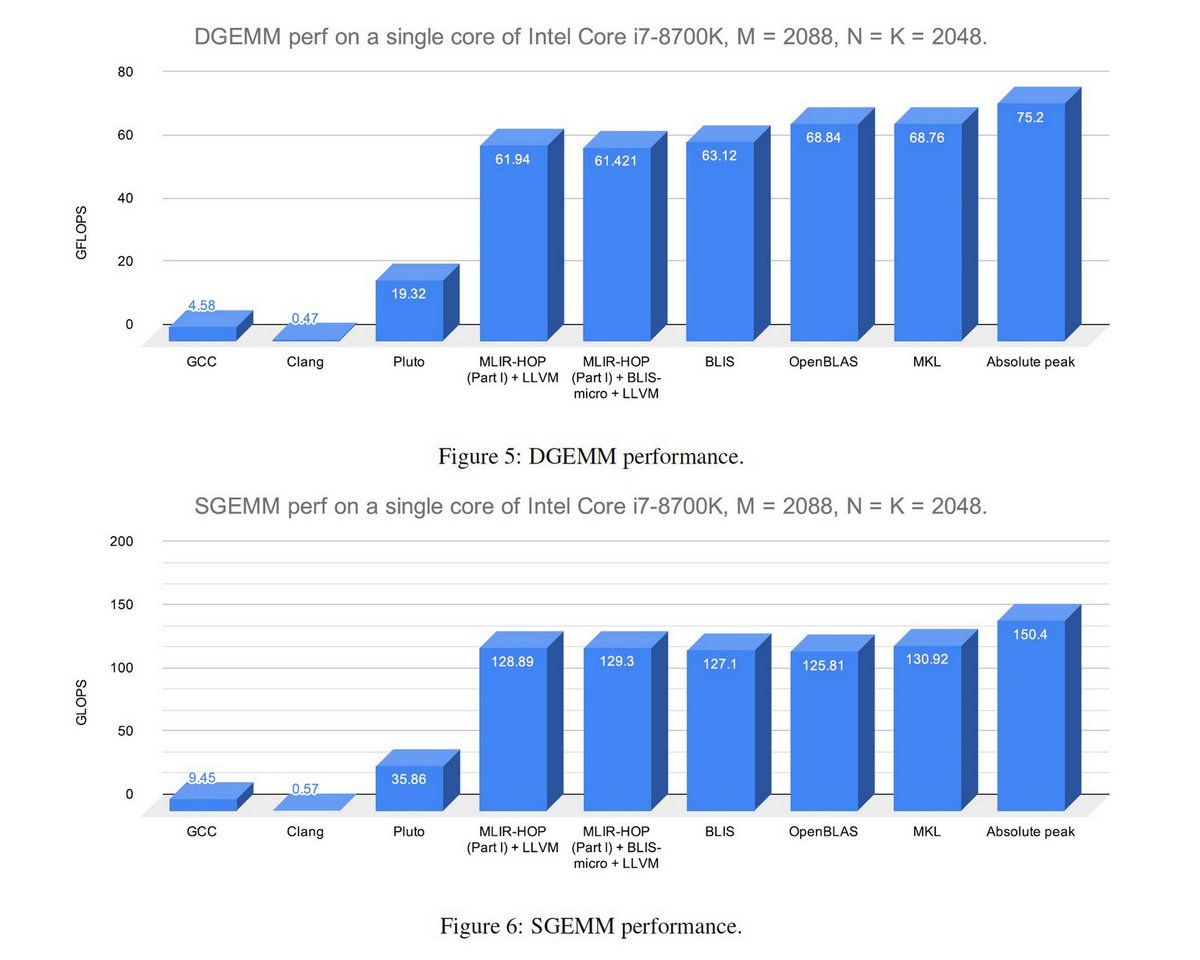
"High Performance Code Generation in MLIR: An Early Case Study with GEMM", Uday Bondhugula, arXiv, Mar 1, 2020 arxiv.org/abs/2003.00532
polymagelabs.com/index.html
IMPACT 2020
Polyhedral
A New Golden Age for .
"High Performance Code Generation in MLIR: An Early Case Study with GEMM", Uday Bondhugula, arXiv, Mar 1, 2020 arxiv.org/abs/2003.00532
polymagelabs.com/index.html
IMPACT 2020
Polyhedral
A New Golden Age for .