0/ This is a thread about *Logging* and how – for decades – it’s been a needlessly “selfish” technology.
And how that should change.
I promise this eventually gets concrete and involves real examples from production. :)
👇
And how that should change.
I promise this eventually gets concrete and involves real examples from production. :)
👇

1/ First off, a crucial clarification: I don’t mean that the “loggers” – that is, the human operators – are selfish, of course! The problem has been that their (IMO primitive) toolchain needlessly localizes and *constrains* the value of the logging telemetry data.
2/ How? Well, traditional logging tech encourages the code-owner to add logs *in order to explain what’s happening with their code, in production, to themself.* Or, maybe, to other/future owners of that particular patch of code.
Useful? Sometimes. But both limited and limiting.
Useful? Sometimes. But both limited and limiting.
3/ It’s a paradox… the logging data itself seems so rich, and surely relevant to countless “unsolved mysteries” in production.
And yet: during any particular incident or investigation, the narrow sliver of relevant logging data can’t be separated from the rest of the firehose.
And yet: during any particular incident or investigation, the narrow sliver of relevant logging data can’t be separated from the rest of the firehose.
4/ So how do we realize the *actual* value of our logs? How do we rank and filter them in the context of an actual incident or investigation? How do we “multiply their value,” and make logging a “generous” discipline rather than a “selfish” one?
5/ Like this:
I) Automatically attach the logs to the trace context
II) Collect *everything*
III) Use tracing data and AI/ML to correlate critical symptoms in one service with the relevant logs from others
… and now the logs help *everyone,* not just the logger. ✨
I) Automatically attach the logs to the trace context
II) Collect *everything*
III) Use tracing data and AI/ML to correlate critical symptoms in one service with the relevant logs from others
… and now the logs help *everyone,* not just the logger. ✨
6/ These sorts of things are much easier to explain with a real-world example, so let’s make this more concrete. I’ll pick a recent issue from @LightstepHQ’s own live, multi-tenant SaaS in order to illustrate the concepts here.
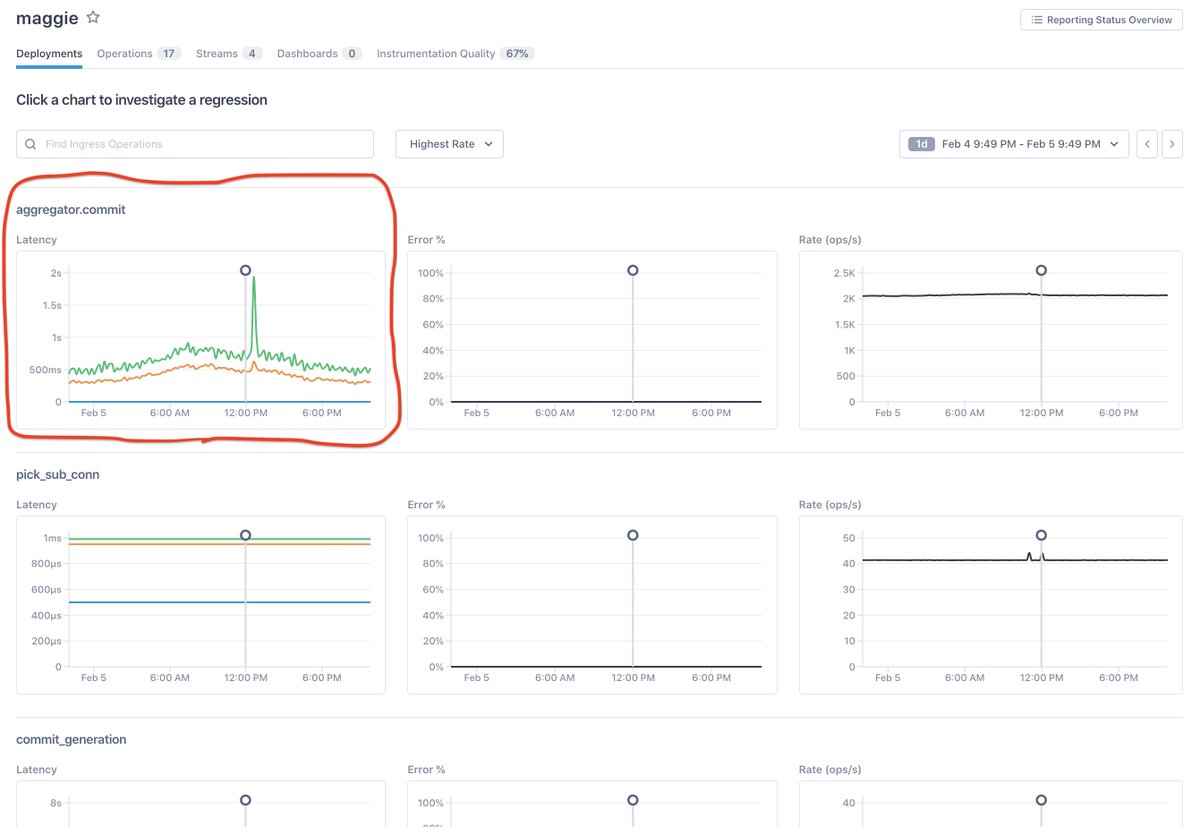
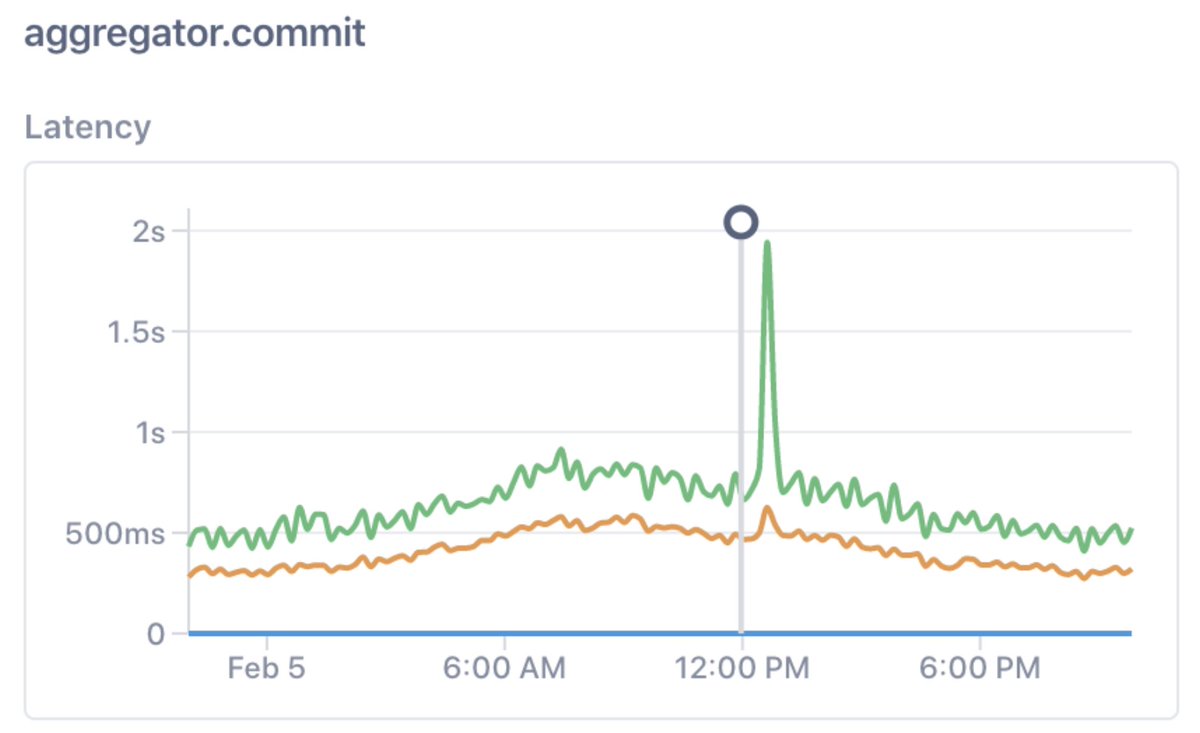
7/ I heard that we had an elevated error ratio for HTTP POST in a central service – code-named “crouton” – a few nights ago. Here’s how it looked:
(PS: “crouton” is the oldest service in our system, and the name is my fault. It was a dad-joke about “breadcrumbs.”)
(PS: “crouton” is the oldest service in our system, and the name is my fault. It was a dad-joke about “breadcrumbs.”)

8/ In a conventional metrics or monitoring tool, this is when you’d start guessing and checking – very basic, and in a bad way.
What you’d rather do is just click on the spike and understand what’s changed. Here, you can:
What you’d rather do is just click on the spike and understand what’s changed. Here, you can:

9/ We need to understand “what changed.” To help with that, this view color-codes regression state (red) and baseline state (blue) and uses the root-cause-analysis engine to examine all of its upstream and downstream dependencies – including logs from those distant services!

10/ Here’s why this would be so painful without 1000s of traces to power the analysis. This is the dependency diagram *just for this HTTP POST regression*. No human has time to figure this out manually, much less analyze the relevant snippets of log data along the way.

11/ Thankfully, that sort of strenuous manual effort is no longer needed. An observability solution should be able to do that work for us, and should also provide quantitative impact data. Here’s what this view has to say about correlated logs:

12/ This is interesting!
We now have concrete evidence of an actual data integrity issue, including some specifics (“byte 22”, etc) – and we can follow up by looking at *many* distributed traces.
We now have concrete evidence of an actual data integrity issue, including some specifics (“byte 22”, etc) – and we can follow up by looking at *many* distributed traces.

13/ Here’s the first one of those, for example – this trace shows the connection between this deeply-nested log message and the HTTP POST that concerned us at the outset, and gives us enough detail to reproduce and resolve outside of production.

14/ So, logging tech *used* to be “selfish” – service logs only really helped that service’s owners. Enriched with context from tracing data, though, logs can help the entire org resolve mysteries across the stack.
This is what unified observability can – and should – deliver.
This is what unified observability can – and should – deliver.