How robust are cross-population signatures of polygenic adaptation in humans?
These selection tests are difficult to get right. My guess is that we will have to wait a few years for trans-ethnic sequence based polygenic models ('GWAS') to get it right.
researchgate.net/publication/34…
These selection tests are difficult to get right. My guess is that we will have to wait a few years for trans-ethnic sequence based polygenic models ('GWAS') to get it right.
researchgate.net/publication/34…
'Beware the hate groups! [proceeds to cite the most important hate group of all, journalists]' 

Curiously, did not include the most important trait: intelligence or its social correlates (education, income etc.). Not that I think these conditions would likely reveal much if they can't even find clear evidence for obvious case of height.

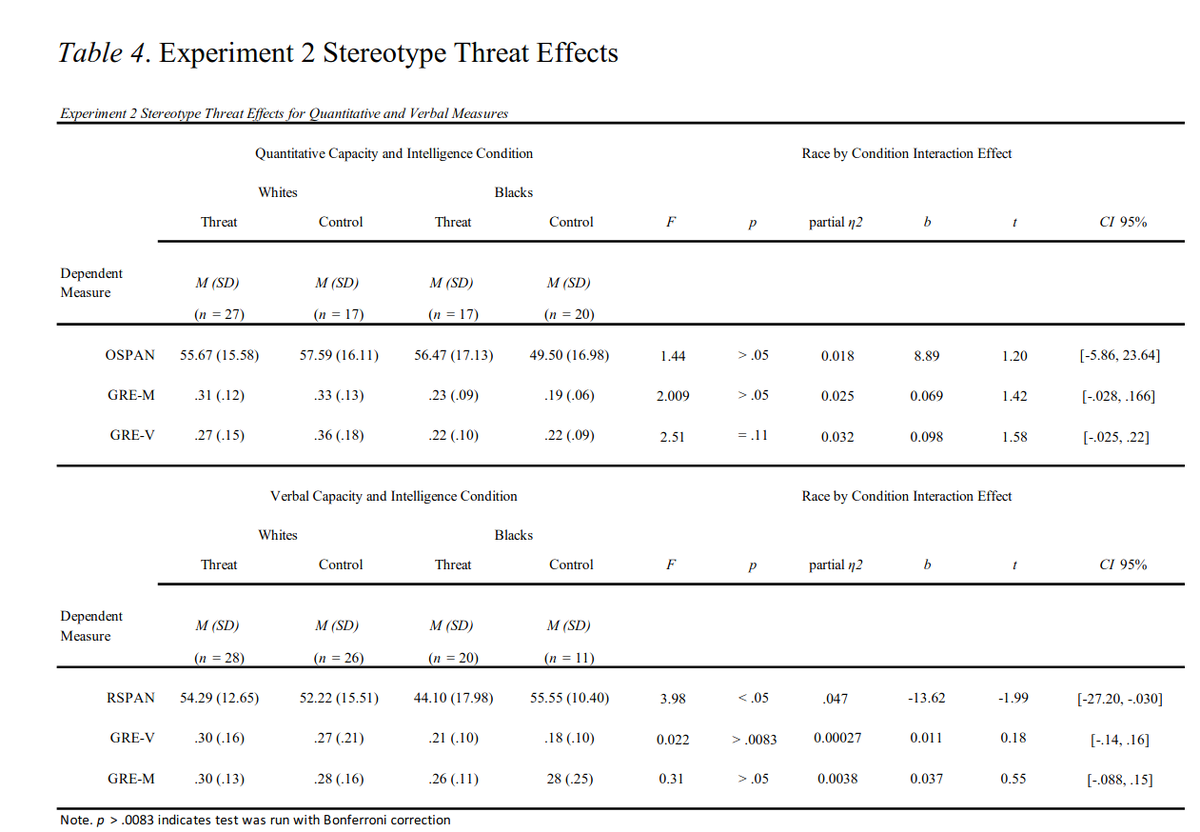
It is very interesting that doing the GWAS on different discovery populations changes the population rank orderings. Considering that the current (European-derived ones) correlate so well with the phenotypes, this is hard to believe.
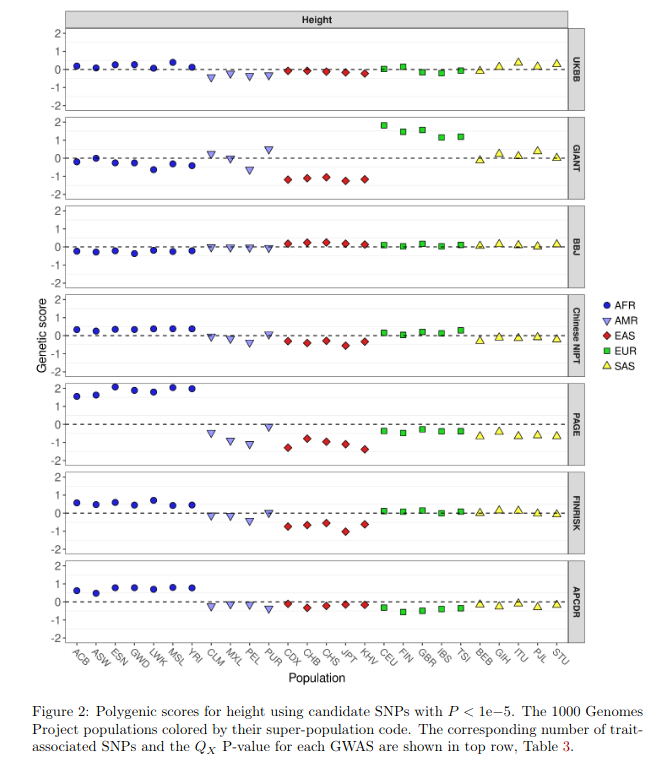
It gets worse. Even within a single dataset, the way to build the genetic model matters a lot for this specific polygenic selection test. It's very brittle in other words.
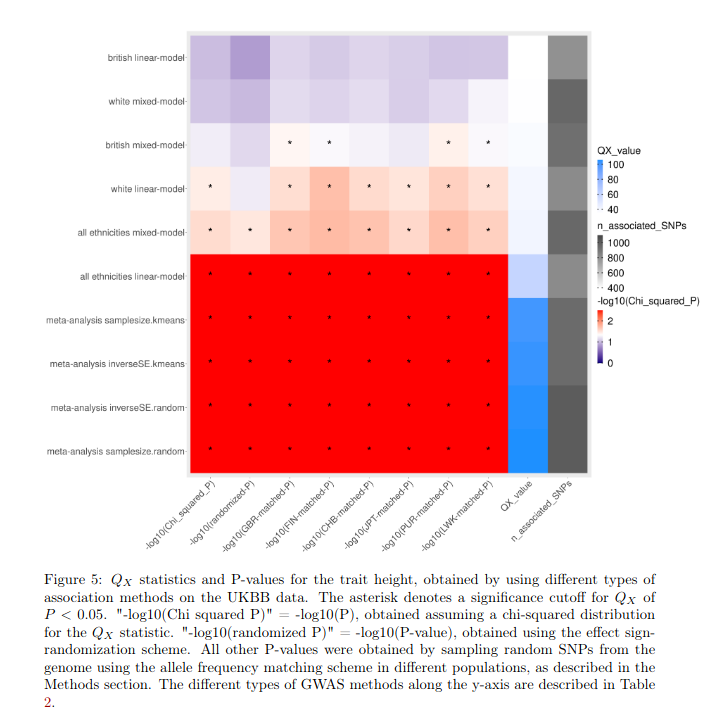
The results across datasets are quite a lot less damning when one considers the sample sizes are too small to produce much signal. Odd the authors did not take the chance to downsample the larger datasets to match the smaller ones. This could clarify the sample size issue.

The Japanese dataset looks like it contains some outliers, There are some SNPs here with absolute effect sizes > 2! Not mentioned by the authors (I think) but these might obviously cause a big problem.
Overall, this paper is a neat contribution to the debate. We need more of this. I think it also goes to show the extreme potential for method hacking results of interest in this research space. Way too many decisions to make and large effects on results!
• • •
Missing some Tweet in this thread? You can try to
force a refresh