There are different categories of Machine Learning problems:
▫️Supervised Learning
▫️Unsupervised Learning
▫️Semi-supervised Learning
▫️Reinforcement Learning
This is a quick introduction to each one of them: 🧵👇
▫️Supervised Learning
▫️Unsupervised Learning
▫️Semi-supervised Learning
▫️Reinforcement Learning
This is a quick introduction to each one of them: 🧵👇

1⃣ Supervised Learning
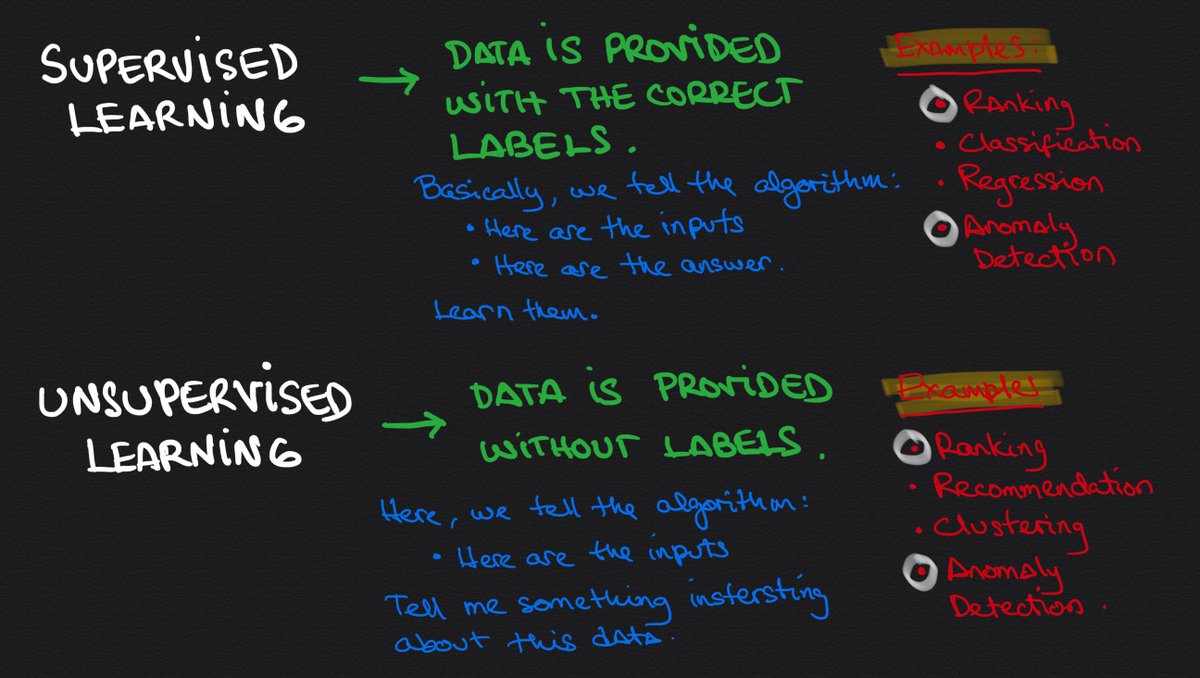
🔹We train an algorithm using labeled data. This means that we give it the "questions" and the correct "answers."
The goal is for the algorithm to learn the concepts, so it can later answer similar questions.
👇
🔹We train an algorithm using labeled data. This means that we give it the "questions" and the correct "answers."
The goal is for the algorithm to learn the concepts, so it can later answer similar questions.
👇
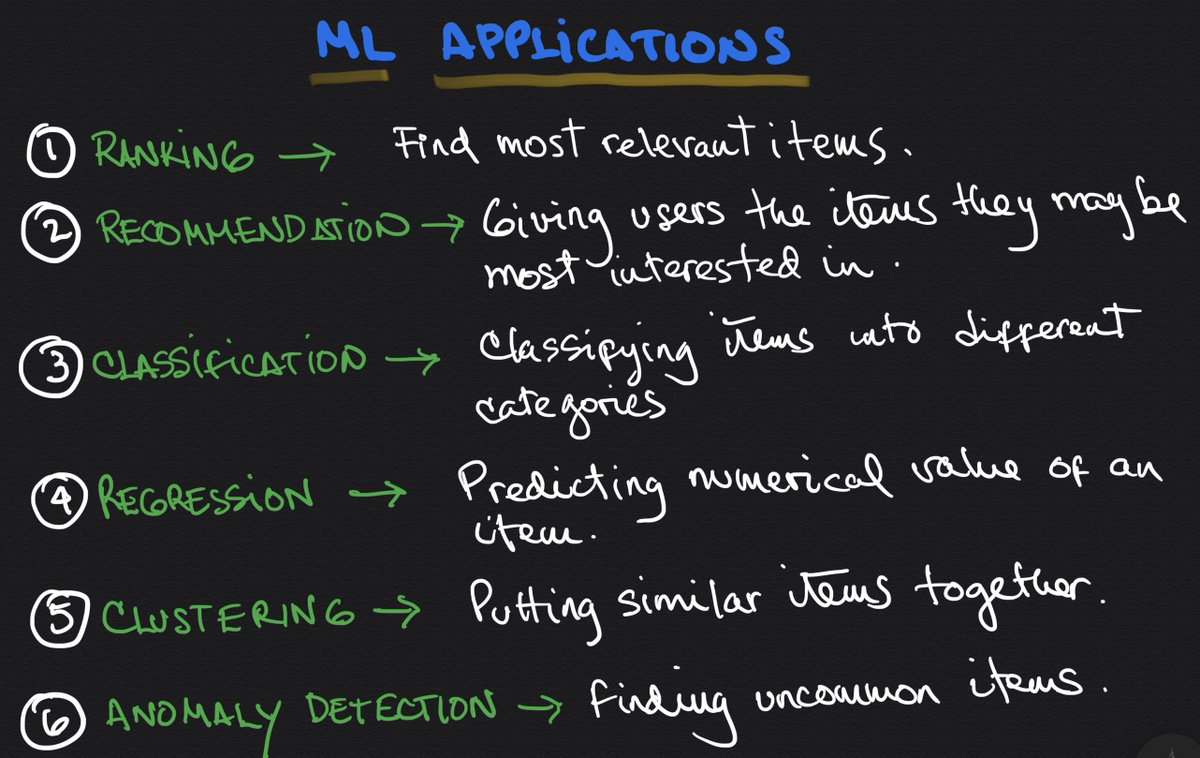
An example of Supervised Learning:
Given a dataset with pictures of different dogs and their breed, we can use a classification algorithm to determine the breed of new pictures of dogs.
Noticed how here we are getting labeled data (picture + breed.)
👇
Given a dataset with pictures of different dogs and their breed, we can use a classification algorithm to determine the breed of new pictures of dogs.
Noticed how here we are getting labeled data (picture + breed.)
👇
Supervised Learning is, without doubt, the most popular category of Machine Learning problems.
Every day you probably interact with several systems that give you results based on Supervised Learning methods.
👇
Every day you probably interact with several systems that give you results based on Supervised Learning methods.
👇
2⃣ Unsupervised Learning
🔹We give the algorithm unlabeled data so it tries to find patterns in it.
Notice that we aren't teaching the algorithm (there are no questions + answers like in Supervised Learning.) We are expecting the algorithm to learn from the data itself.
👇
🔹We give the algorithm unlabeled data so it tries to find patterns in it.
Notice that we aren't teaching the algorithm (there are no questions + answers like in Supervised Learning.) We are expecting the algorithm to learn from the data itself.
👇
An example of Unsupervised Learning:
Given a dataset of prospective customers, cluster them in groups to target your marketing strategy.
Here the algorithm will determine different classification groups for your customers. Notice that it will do so without any labeled data.
👇
Given a dataset of prospective customers, cluster them in groups to target your marketing strategy.
Here the algorithm will determine different classification groups for your customers. Notice that it will do so without any labeled data.
👇
Clustering is the most common example of Unsupervised Learning, but Anomaly Detection is very popular and used in practice.
Anomaly Detection: the algorithm learns what "normal" is and signals anything that deviates from that.
👇
Anomaly Detection: the algorithm learns what "normal" is and signals anything that deviates from that.
👇
3⃣ Semi-supervised Learning
🔹We train the algorithm with some labels but mostly unlabeled data.
The algorithm will exploit the existing relationships in the data to determine the labels for the unlabeled portion of the dataset.
👇
🔹We train the algorithm with some labels but mostly unlabeled data.
The algorithm will exploit the existing relationships in the data to determine the labels for the unlabeled portion of the dataset.
👇
An example of Semi-supervised Learning:
Given a partially-labeled dataset of emails, determine which are spam.
In this case, most of the input dataset is unlabeled. The algorithm will then determine the labels of all the data and learn to recognize spam emails.
👇
Given a partially-labeled dataset of emails, determine which are spam.
In this case, most of the input dataset is unlabeled. The algorithm will then determine the labels of all the data and learn to recognize spam emails.
👇
Semi-supervised Learning methods are extremely useful in practice because generating labels is sometimes very hard (or even impossible.)
Using them, we can get away with a few labels, assuming there are patterns to exploit to properly determine the rest of the labels.
👇
Using them, we can get away with a few labels, assuming there are patterns to exploit to properly determine the rest of the labels.
👇
4⃣ Reinforcement Learning
🔹An agent interacts with the environment collecting rewards. Based on those observations, the agent learns which actions will optimize the outcome (either maximizing rewards, or minimizing penalties.)
👇
🔹An agent interacts with the environment collecting rewards. Based on those observations, the agent learns which actions will optimize the outcome (either maximizing rewards, or minimizing penalties.)
👇
An example of Reinforcement Learning:
A robot learning the optimal path to get from point A to point B of a warehouse by repeatedly walking and exploring the different paths between the two locations.
👇
A robot learning the optimal path to get from point A to point B of a warehouse by repeatedly walking and exploring the different paths between the two locations.
👇
You have heard about AlphaZero, right?
It plays chess, shogi, and Go. And it wins all the time.
It uses Reinforcement Learning.
I felt in love with Reinforcement Learning the minute I learned about it. Unfortunately, I haven't been able to use it in practice yet.
👇
It plays chess, shogi, and Go. And it wins all the time.
It uses Reinforcement Learning.
I felt in love with Reinforcement Learning the minute I learned about it. Unfortunately, I haven't been able to use it in practice yet.
👇
Day 4 of #MLU goes over Supervised and Unsupervised learning in a 5-minute video.
(As a reminder, I'm going through the 27-lesson, quick, Computer Vision course published by Amazon.)
(As a reminder, I'm going through the 27-lesson, quick, Computer Vision course published by Amazon.)
https://twitter.com/svpino/status/1312250578123345921?s=20
• • •
Missing some Tweet in this thread? You can try to
force a refresh