I think the below modelling output provides a useful illustration of how to evaluate forecasts. A short thread... 1/
https://twitter.com/globalhlthtwit/status/1303011885348990976?s=20
First, let's be clear about difference between a 'scenario' and 'forecast'. Scenarios explore specific 'what if' questions, e.g. 'What if we don't introduce any control measures?' - Below are some examples from the March Imperial UK modelling report (imperial.ac.uk/mrc-global-inf…). 2/ 

In contrast, epidemic forecasts provide an answer to the question 'What do we think is most likely to happen?' More on scenarios vs forecasts here: washingtonpost.com/outlook/2020/0… 3/
The authors of the above '24-37 deaths at peak' model have previous referred to it having predictive accuracy (blogs.bmj.com/bmj/2020/09/24…), so I think it's fair to judge it accordingly. There are three main metrics we can use to do so... 4/

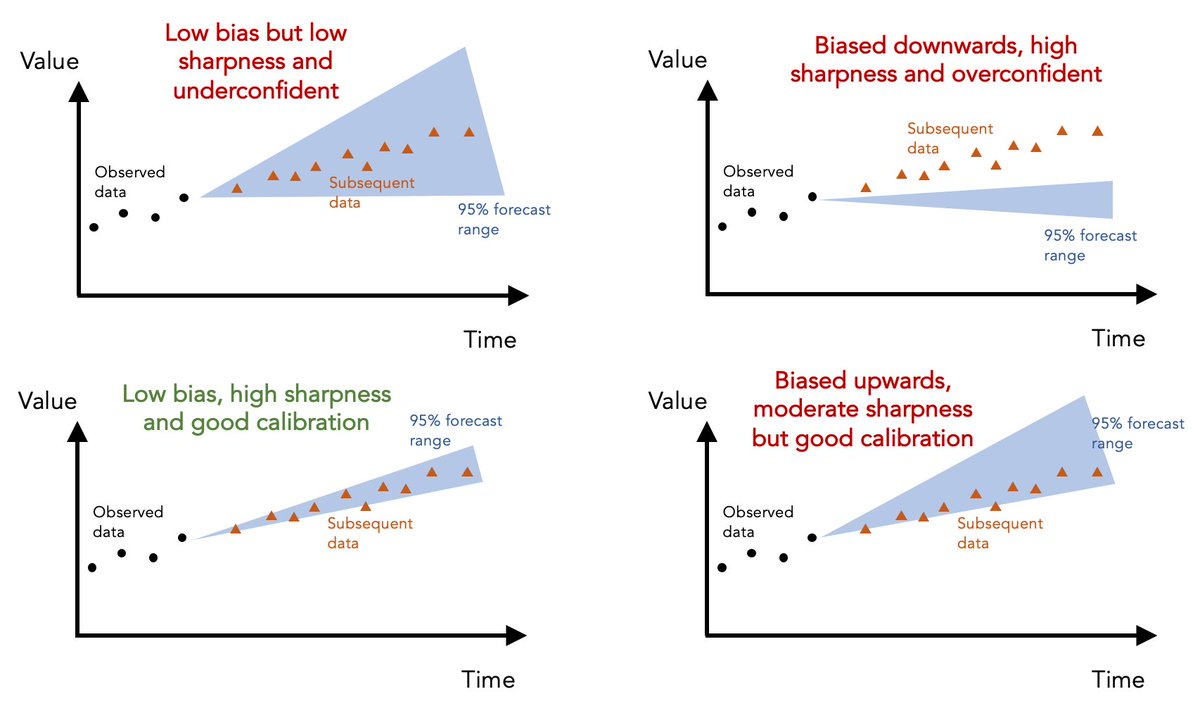
First, 'calibration' measures ability of model to correctly identify its own uncertainty in making predictions. Basically, is it under- or overconfident? E.g. if model says particular range of values is '95% likely', we'd expect 95% of subsequent data to fall within this range 5/
Given 7 day average for daily deaths in UK has fallen outside above model's 95% prediction range of 24-37 for several weeks, it's clear that the above model was overconfident in its predictions... 6/
The second metric is 'sharpness', i.e. the ability of model to generate predictions within narrow range of possible outcomes. Basically, a model that says 'value will be between 0 and 10000' isn't as useful as a well-calibrated model that can generate more precise predictions. 7/
The above model makes 'sharp' predictions (i.e. within a narrow range) but the lack of calibration suggests this sharpness is coming at the expense of insufficient uncertainty. 8/
The third metric is 'bias' - is the model systematically over- or underpredicting the true values? In this case, above model seems biased downwards, generating predictions that routinely fall below the subsequent data. 9/
Although I've used above model as an illustrative example, the same ideas can be applied to any epidemic forecast. Here are some examples of different hypothetical forecasts and how they perform on these different metrics... 10/
If you're interested in reading more about forecast evaluation, here's a paper we published on these issues last year: journals.plos.org/ploscompbiol/a…. And a nice review with more technical details: annualreviews.org/doi/10.1146/an… 11/11
• • •
Missing some Tweet in this thread? You can try to
force a refresh