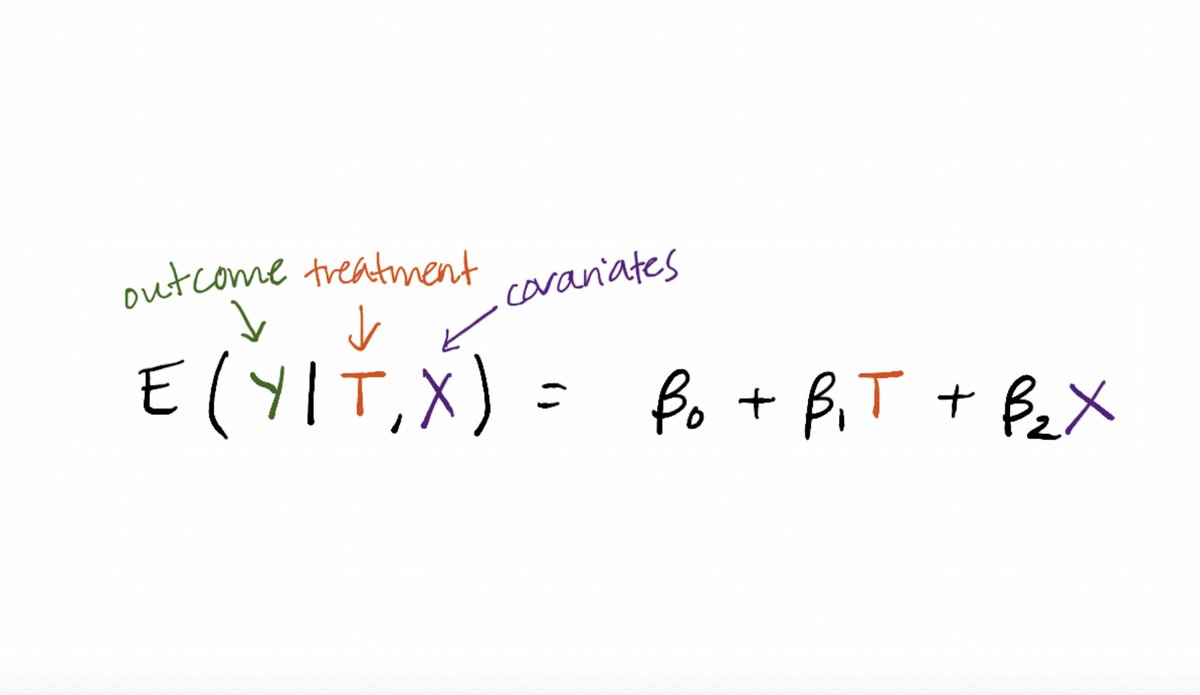What do professors do day-to-day (in a pandemic)?
This varies *a lot* by type of role, seniority, and institution.
I’m tenured at a research-intensive institution and I am not teaching this term.
This varies *a lot* by type of role, seniority, and institution.
I’m tenured at a research-intensive institution and I am not teaching this term.
I spend a fair amount of time meeting with students and collaborators. Today, Monday, I have 5 such meetings.
There are also lots of emails and administrative tasks all the time.
There are also lots of emails and administrative tasks all the time.
Each day this week I’ll drop a tweet in this thread to add in unique things I haven’t mentioned yet to demystify the life of this particular professor.
I just finished up my meetings for the day and there has been a lot of news in the world...
What I'll add to this thread is that today my cat Tobias joined 3 of my zooms.
What I'll add to this thread is that today my cat Tobias joined 3 of my zooms.

Tuesday’s unique things: Conducting interviews and meeting with colleagues about our new summer diversity initiative!
(non-unique: Cat joining more research zooms…)
(non-unique: Cat joining more research zooms…)

Wednesday's unique thing: Discussed the academic job market with a colleague and some senior graduate students! 🤓🧑💻🧑🏫
• • •
Missing some Tweet in this thread? You can try to
force a refresh